
Aperçu
Le pipeline TensorFlow Model Analysis (TFMA) est représenté comme suit :
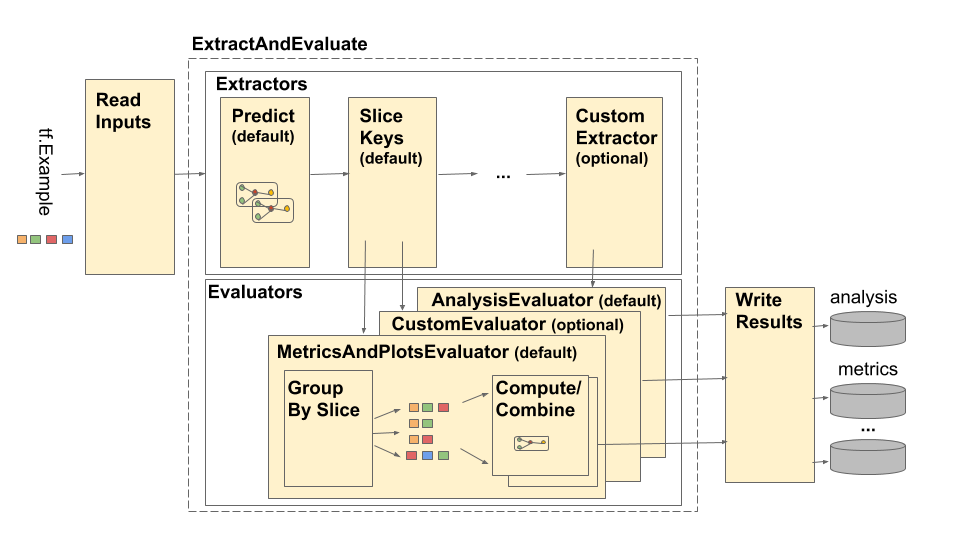
Le pipeline est composé de quatre éléments principaux :
- Lire les entrées
- Extraction
- Évaluation
- Écrire les résultats
Ces composants utilisent deux types principaux : tfma.Extracts et tfma.evaluators.Evaluation . Le type tfma.Extracts représente les données extraites lors du traitement du pipeline et peut correspondre à un ou plusieurs exemples du modèle. tfma.evaluators.Evaluation représente le résultat de l'évaluation des extraits à différents moments du processus d'extraction. Afin de fournir une API flexible, ces types ne sont que des dictées où les clés sont définies (réservées à l'utilisation) par différentes implémentations. Les types sont définis comme suit :
# Extracts represent data extracted during pipeline processing.
# For example, the PredictExtractor stores the data for the
# features, labels, and predictions under the keys "features",
# "labels", and "predictions".
Extracts = Dict[Text, Any]
# Evaluation represents the output from evaluating extracts at
# particular point in the pipeline. The evaluation outputs are
# keyed by their associated output type. For example, the metric / plot
# dictionaries from evaluating metrics and plots will be stored under
# "metrics" and "plots" respectively.
Evaluation = Dict[Text, beam.pvalue.PCollection]
Notez que tfma.Extracts ne sont jamais écrits directement, ils doivent toujours passer par un évaluateur pour produire un tfma.evaluators.Evaluation qui est ensuite écrit. Notez également que tfma.Extracts sont des dicts qui sont stockés dans un beam.pvalue.PCollection (c'est-à-dire que beam.PTransform prennent en entrée beam.pvalue.PCollection[tfma.Extracts] ) alors qu'un tfma.evaluators.Evaluation est un dict dont les valeurs sont beam.pvalue.PCollection s (c'est-à-dire que beam.PTransform prennent le dict lui-même comme argument pour l'entrée beam.value.PCollection ). En d’autres termes, tfma.evaluators.Evaluation est utilisé au moment de la construction du pipeline, mais tfma.Extracts est utilisé lors de l’exécution du pipeline.
Lire les entrées
L'étape ReadInputs est constituée d'une transformation qui prend les entrées brutes (tf.train.Example, CSV, ...) et les convertit en extraits. Aujourd'hui, les extraits sont représentés sous forme d'octets d'entrée bruts stockés sous tfma.INPUT_KEY , mais les extraits peuvent être sous n'importe quelle forme compatible avec le pipeline d'extraction - ce qui signifie qu'il crée tfma.Extracts en sortie et que ces extraits sont compatibles avec les flux en aval. extracteurs. Il appartient aux différents extracteurs de documenter clairement ce dont ils ont besoin.
Extraction
Le processus d'extraction est une liste de beam.PTransform exécutés en série. Les extracteurs prennent tfma.Extracts en entrée et renvoient tfma.Extracts en sortie. L'extracteur proto-typique est le tfma.extractors.PredictExtractor qui utilise l'extrait d'entrée produit par la transformation des entrées de lecture et l'exécute via un modèle pour produire des extraits de prédictions. Des extracteurs personnalisés peuvent être insérés à tout moment à condition que leurs transformations soient conformes aux API tfma.Extracts in et tfma.Extracts out. Un extracteur est défini comme suit :
# An Extractor is a PTransform that takes Extracts as input and returns
# Extracts as output. A typical example is a PredictExtractor that receives
# an 'input' placeholder for input and adds additional 'predictions' extracts.
Extractor = NamedTuple('Extractor', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Extracts -> Extracts
Extracteur d'entrée
tfma.extractors.InputExtractor est utilisé pour extraire des caractéristiques brutes, des étiquettes brutes et des exemples de poids bruts à partir d'enregistrements tf.train.Example à utiliser dans le découpage et les calculs de métriques. Par défaut, les valeurs sont stockées respectivement sous les clés d'extraction features , labels et example_weights . Les étiquettes de modèle à sortie unique et les exemples de poids sont stockés directement sous forme de valeurs np.ndarray . Les étiquettes de modèle à sorties multiples et les exemples de poids sont stockés sous forme de dictionnaires de valeurs np.ndarray (saisies par nom de sortie). Si une évaluation multi-modèle est effectuée, les étiquettes et les exemples de poids seront ensuite intégrés dans un autre dict (saisi par nom de modèle).
PrédireExtracteur
Le tfma.extractors.PredictExtractor exécute les prédictions du modèle et les stocke sous les predictions clés dans le dict tfma.Extracts . Les prédictions du modèle à sortie unique sont stockées directement en tant que valeurs de sortie prédites. Les prédictions du modèle à sorties multiples sont stockées sous forme de dictionnaire de valeurs de sortie (saisies par nom de sortie). Si une évaluation multi-modèle est effectuée, la prédiction sera ensuite intégrée dans un autre dict (saisi par nom de modèle). La valeur de sortie réelle utilisée dépend du modèle (par exemple, les sorties de retour de l'estimateur TF sous la forme d'un dict alors que keras renvoie les valeurs np.ndarray ).
Extracteur de clés Slice
Le tfma.extractors.SliceKeyExtractor utilise la spécification de découpage pour déterminer quelles tranches s'appliquent à chaque exemple d'entrée en fonction des fonctionnalités extraites et ajoute les valeurs de découpage correspondantes aux extraits pour une utilisation ultérieure par les évaluateurs.
Évaluation
L'évaluation est le processus consistant à prendre un extrait et à l'évaluer. Bien qu'il soit courant d'effectuer une évaluation à la fin du pipeline d'extraction, certains cas d'utilisation nécessitent une évaluation plus tôt dans le processus d'extraction. En tant que tels, les évaluateurs sont associés aux extracteurs par rapport auxquels ils doivent être évalués. Un évaluateur est défini comme suit :
# An evaluator is a PTransform that takes Extracts as input and
# produces an Evaluation as output. A typical example of an evaluator
# is the MetricsAndPlotsEvaluator that takes the 'features', 'labels',
# and 'predictions' extracts from the PredictExtractor and evaluates
# them using post export metrics to produce metrics and plots dictionaries.
Evaluator = NamedTuple('Evaluator', [
('stage_name', Text),
('run_after', Text), # Extractor.stage_name
('ptransform', beam.PTransform)]) # Extracts -> Evaluation
Notez qu'un évaluateur est un beam.PTransform qui prend tfma.Extracts comme entrées. Rien n’empêche une implémentation d’effectuer des transformations supplémentaires sur les extraits dans le cadre du processus d’évaluation. Contrairement aux extracteurs qui doivent renvoyer un dict tfma.Extracts , il n'y a aucune restriction sur les types de sorties qu'un évaluateur peut produire, bien que la plupart des évaluateurs renvoient également un dict (par exemple des noms et des valeurs de métriques).
MetricsAndPlotsEvaluateur
Le tfma.evaluators.MetricsAndPlotsEvaluator prend features , labels et predictions en entrée, les exécute via tfma.slicer.FanoutSlices pour les regrouper par tranches, puis effectue des calculs de métriques et de tracés. Il produit des sorties sous la forme de dictionnaires de métriques et de tracés de clés et de valeurs (ceux-ci sont ensuite convertis en protos sérialisés pour la sortie par tfma.writers.MetricsAndPlotsWriter ).
Écrire les résultats
L'étape WriteResults est l'endroit où la sortie de l'évaluation est écrite sur le disque. WriteResults utilise des rédacteurs pour écrire les données en fonction des clés de sortie. Par exemple, un tfma.evaluators.Evaluation peut contenir des clés pour metrics et plots . Ceux-ci seraient ensuite associés aux dictionnaires de métriques et de tracés appelés « métriques » et « tracés ». Les rédacteurs précisent comment écrire chaque fichier :
# A writer is a PTransform that takes evaluation output as input and
# serializes the associated PCollections of data to a sink.
Writer = NamedTuple('Writer', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Evaluation -> PDone
MetricsAndPlotsWriter
Nous fournissons un tfma.writers.MetricsAndPlotsWriter qui convertit les dictionnaires de métriques et de tracés en protos sérialisés et les écrit sur le disque.
Si vous souhaitez utiliser un format de sérialisation différent, vous pouvez créer un rédacteur personnalisé et l'utiliser à la place. Étant donné que le tfma.evaluators.Evaluation transmis aux rédacteurs contient la sortie de tous les évaluateurs combinés, une transformation d'assistance tfma.writers.Write est fournie que les rédacteurs peuvent utiliser dans leurs implémentations ptransform pour sélectionner les beam.PCollection appropriées en fonction d'un touche de sortie (voir ci-dessous pour un exemple).
Personnalisation
La méthode tfma.run_model_analysis prend les arguments extractors , evaluators writers pour personnaliser les extracteurs, les évaluateurs et les écrivains utilisés par le pipeline. Si aucun argument n'est fourni, alors tfma.default_extractors , tfma.default_evaluators et tfma.default_writers sont utilisés par défaut.
Extracteurs personnalisés
Pour créer un extracteur personnalisé, créez un type tfma.extractors.Extractor qui encapsule un beam.PTransform prenant tfma.Extracts en entrée et renvoyant tfma.Extracts en sortie. Des exemples d'extracteurs sont disponibles sous tfma.extractors .
Évaluateurs personnalisés
Pour créer un évaluateur personnalisé, créez un type tfma.evaluators.Evaluator qui encapsule un beam.PTransform prenant tfma.Extracts en entrée et renvoyant tfma.evaluators.Evaluation en sortie. Un évaluateur très basique pourrait simplement prendre les tfma.Extracts entrants et les afficher pour les stocker dans une table. C'est exactement ce que fait tfma.evaluators.AnalysisTableEvaluator . Un évaluateur plus complexe pourrait effectuer un traitement supplémentaire et une agrégation des données. Voir tfma.evaluators.MetricsAndPlotsEvaluator à titre d'exemple.
Notez que le tfma.evaluators.MetricsAndPlotsEvaluator lui-même peut être personnalisé pour prendre en charge des métriques personnalisées (voir métriques pour plus de détails).
Écrivains personnalisés
Pour créer un enregistreur personnalisé, créez un type tfma.writers.Writer qui encapsule un beam.PTransform en prenant tfma.evaluators.Evaluation en entrée et en renvoyant beam.pvalue.PDone en sortie. Ce qui suit est un exemple de base d'un rédacteur permettant d'écrire des TFRecords contenant des métriques :
tfma.writers.Writer(
stage_name='WriteTFRecord(%s)' % tfma.METRICS_KEY,
ptransform=tfma.writers.Write(
key=tfma.METRICS_KEY,
ptransform=beam.io.WriteToTFRecord(file_path_prefix=output_file))
Les contributions d'un écrivain dépendent des résultats de l'évaluateur associé. Pour l'exemple ci-dessus, la sortie est un prototype sérialisé produit par tfma.evaluators.MetricsAndPlotsEvaluator . Un rédacteur pour tfma.evaluators.AnalysisTableEvaluator serait responsable de l'écriture d'un beam.pvalue.PCollection de tfma.Extracts .
Notez qu'un rédacteur est associé à la sortie d'un évaluateur via la clé de sortie utilisée (par exemple tfma.METRICS_KEY , tfma.ANALYSIS_KEY , etc.).
Exemple étape par étape
Voici un exemple des étapes impliquées dans le pipeline d'extraction et d'évaluation lorsque tfma.evaluators.MetricsAndPlotsEvaluator et tfma.evaluators.AnalysisTableEvaluator sont utilisés :
run_model_analysis(
...
extractors=[
tfma.extractors.InputExtractor(...),
tfma.extractors.PredictExtractor(...),
tfma.extractors.SliceKeyExtrator(...)
],
evaluators=[
tfma.evaluators.MetricsAndPlotsEvaluator(...),
tfma.evaluators.AnalysisTableEvaluator(...)
])
ReadInputs
# Out
Extracts {
'input': bytes # CSV, Proto, ...
}
ExtractAndEvaluate
# In: ReadInputs Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
}
# In: InputExtractor Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
}
# In: PredictExtractor Extracts
# Out:
Extracts {
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
'slice_key': Tuple[bytes...] # Slice
}
tfma.evaluators.MetricsAndPlotsEvaluator(run_after :SLICE_KEY_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
}
tfma.evaluators.AnalysisTableEvaluator(run_after :LAST_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'analysis': PCollection[Extracts] # Final Extracts
}
WriteResults
# In:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
'analysis': PCollection[Extracts] # Final Extracts
}
# Out: metrics, plots, and analysis files