
Przegląd
Potok analizy modelu TensorFlow (TFMA) przedstawiono w następujący sposób:
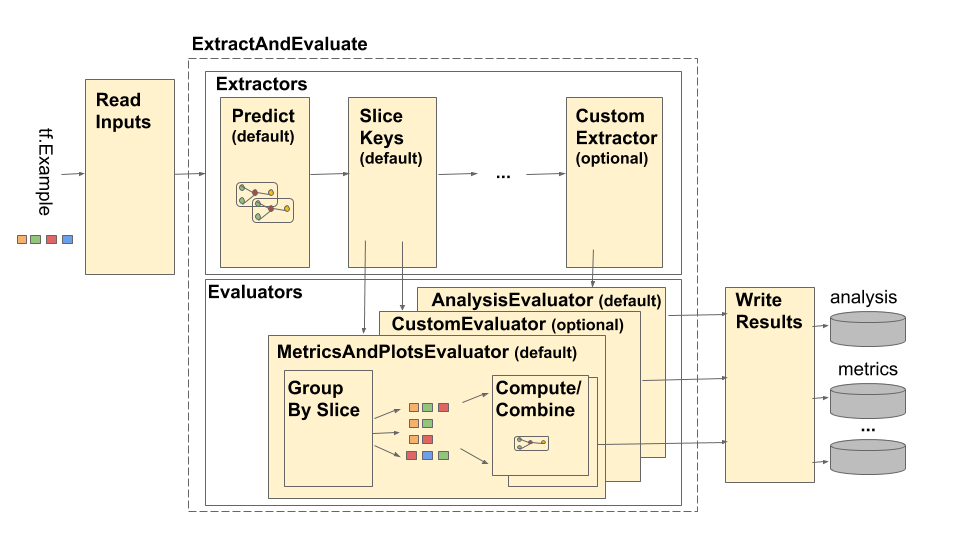
Rurociąg składa się z czterech głównych elementów:
- Przeczytaj dane wejściowe
- Ekstrakcja
- Ocena
- Zapisz wyniki
Komponenty te korzystają z dwóch podstawowych typów: tfma.Extracts i tfma.evaluators.Evaluation . Typ tfma.Extracts reprezentuje dane wyodrębniane podczas przetwarzania potoku i może odpowiadać jednemu lub większej liczbie przykładów modelu. tfma.evaluators.Evaluation reprezentuje wynik oceny ekstraktów na różnych etapach procesu ekstrakcji. Aby zapewnić elastyczne API, typy te są po prostu dyktatorami, w których klucze są zdefiniowane (zarezerwowane do użytku) przez różne implementacje. Typy są zdefiniowane w następujący sposób:
# Extracts represent data extracted during pipeline processing.
# For example, the PredictExtractor stores the data for the
# features, labels, and predictions under the keys "features",
# "labels", and "predictions".
Extracts = Dict[Text, Any]
# Evaluation represents the output from evaluating extracts at
# particular point in the pipeline. The evaluation outputs are
# keyed by their associated output type. For example, the metric / plot
# dictionaries from evaluating metrics and plots will be stored under
# "metrics" and "plots" respectively.
Evaluation = Dict[Text, beam.pvalue.PCollection]
Należy pamiętać, że tfma.Extracts nigdy nie są zapisywane bezpośrednio. Zawsze muszą przejść przez osobę oceniającą, aby wygenerować tfma.evaluators.Evaluation , który następnie jest zapisywany. Należy również zauważyć, że tfma.Extracts to dyktaty przechowywane w beam.pvalue.PCollection (tj. beam.PTransform s przyjmują jako dane wejściowe beam.pvalue.PCollection[tfma.Extracts] ), podczas gdy tfma.evaluators.Evaluation to dyktat, którego wartości są beam.pvalue.PCollection (tzn. beam.PTransform przyjmują sam dyktat jako argument wejścia beam.value.PCollection ). Innymi słowy plik tfma.evaluators.Evaluation jest używany w czasie konstruowania potoku, ale plik tfma.Extracts jest używany w czasie wykonywania potoku.
Przeczytaj dane wejściowe
Etap ReadInputs składa się z transformacji, która pobiera surowe dane wejściowe (tf.train.Example, CSV, ...) i konwertuje je na ekstrakty. Obecnie ekstrakty są reprezentowane jako surowe bajty wejściowe przechowywane w tfma.INPUT_KEY , jednakże ekstrakty mogą mieć dowolną formę zgodną z potokiem ekstrakcji - co oznacza, że tworzy tfma.Extracts jako dane wyjściowe i że te ekstrakty są kompatybilne z dalszym ciągiem ekstraktory. Jasna dokumentacja tego, czego wymagają, zależy od poszczególnych ekstraktorów.
Ekstrakcja
Proces wyodrębniania to lista beam.PTransform uruchamianych szeregowo. Ekstraktory pobierają tfma.Extracts jako dane wejściowe i zwracają tfma.Extracts jako dane wyjściowe. Prototypowym ekstraktorem jest tfma.extractors.PredictExtractor , który wykorzystuje ekstrakt wejściowy wygenerowany przez transformację odczytanych danych wejściowych i przepuszcza go przez model w celu wygenerowania ekstraktów predykcji. Niestandardowe ekstraktory można wstawiać w dowolnym miejscu, pod warunkiem, że ich transformacje są zgodne z interfejsami API tfma.Extracts in i tfma.Extracts out. Ekstraktor definiuje się następująco:
# An Extractor is a PTransform that takes Extracts as input and returns
# Extracts as output. A typical example is a PredictExtractor that receives
# an 'input' placeholder for input and adds additional 'predictions' extracts.
Extractor = NamedTuple('Extractor', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Extracts -> Extracts
Ekstraktor wejściowy
tfma.extractors.InputExtractor służy do wyodrębniania surowych cech, nieprzetworzonych etykiet i nieprzetworzonych przykładowych wag z rekordów tf.train.Example w celu wykorzystania przy dzieleniu metryk i obliczeniach. Domyślnie wartości są przechowywane odpowiednio w kluczach wyodrębniających features , labels i example_weights . Etykiety modeli z jednym wyjściem i przykładowe wagi są przechowywane bezpośrednio jako wartości np.ndarray . Etykiety modeli z wieloma wynikami i przykładowe wagi są przechowywane jako wskazania wartości np.ndarray (wpisane według nazwy wyniku). Jeśli przeprowadzana jest ocena wielu modeli, etykiety i przykładowe wagi zostaną dodatkowo osadzone w innym dyktacie (kluczowanym według nazwy modelu).
Ekstraktor prognoz
tfma.extractors.PredictExtractor uruchamia przewidywania modelu i przechowuje je pod kluczowymi predictions w dyktacie tfma.Extracts . Prognozy modelu pojedynczego wyniku są przechowywane bezpośrednio jako przewidywane wartości wyjściowe. Predykcje modelu z wieloma wynikami są przechowywane jako dyktat wartości wyjściowych (wpisanych według nazwy wyniku). Jeśli zostanie przeprowadzona ocena wielu modeli, prognoza zostanie dodatkowo osadzona w innym dyktacie (wpisanym według nazwy modelu). Rzeczywista używana wartość wyjściowa zależy od modelu (np. wyniki zwracane przez estymator TF w formie dyktatu, podczas gdy keras zwraca wartości np.ndarray ).
Ekstraktor SliceKey
Funkcja tfma.extractors.SliceKeyExtractor wykorzystuje specyfikację krojenia, aby określić, które wycinki mają zastosowanie do każdego przykładowego wejścia w oparciu o wyodrębnione funkcje, i dodaje odpowiednie wartości krojenia do ekstraktów w celu późniejszego wykorzystania przez osoby oceniające.
Ocena
Ocena to proces pobrania ekstraktu i jego oceny. Chociaż powszechne jest przeprowadzanie oceny na końcu rurociągu ekstrakcyjnego, istnieją przypadki użycia, które wymagają oceny na wcześniejszym etapie procesu ekstrakcji. Jako tacy ewaluatorzy są powiązani z ekstraktorami, względem których wyników powinni być oceniani. Ewaluator jest zdefiniowany w następujący sposób:
# An evaluator is a PTransform that takes Extracts as input and
# produces an Evaluation as output. A typical example of an evaluator
# is the MetricsAndPlotsEvaluator that takes the 'features', 'labels',
# and 'predictions' extracts from the PredictExtractor and evaluates
# them using post export metrics to produce metrics and plots dictionaries.
Evaluator = NamedTuple('Evaluator', [
('stage_name', Text),
('run_after', Text), # Extractor.stage_name
('ptransform', beam.PTransform)]) # Extracts -> Evaluation
Zauważ, że ewaluatorem jest beam.PTransform , która jako dane wejściowe pobiera tfma.Extracts . Nic nie stoi na przeszkodzie, aby wdrożenie wykonało dodatkowe przekształcenia na ekstraktach w ramach procesu oceny. W przeciwieństwie do ekstraktorów, które muszą zwracać dyktando tfma.Extracts , nie ma żadnych ograniczeń co do typów wyników, jakie może wygenerować ewaluator, chociaż większość ewaluatorów również zwraca dyktando (np. nazwy i wartości metryk).
MetricsAndPlotsEvaluator
Funkcja tfma.evaluators.MetricsAndPlotsEvaluator pobiera features , labels i predictions jako dane wejściowe, uruchamia je za pomocą tfma.slicer.FanoutSlices , aby pogrupować je według wycinków, a następnie wykonuje obliczenia metryk i wykresów. Generuje dane wyjściowe w postaci słowników metryk oraz kluczy i wartości wykresów (są one później konwertowane na serializowane protosy do celów wyjściowych przez tfma.writers.MetricsAndPlotsWriter ).
Zapisz wyniki
Na etapie WriteResults wyniki oceny są zapisywane na dysku. WriteResults używa modułów zapisujących do zapisywania danych na podstawie kluczy wyjściowych. Na przykład plik tfma.evaluators.Evaluation może zawierać klucze do metrics i plots . Zostałyby one następnie powiązane ze słownikami metryk i wykresów, zwanymi „metrykami” i „wykresami”. Autorzy określają sposób zapisywania każdego pliku:
# A writer is a PTransform that takes evaluation output as input and
# serializes the associated PCollections of data to a sink.
Writer = NamedTuple('Writer', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Evaluation -> PDone
MetricsAndPlotsWriter
Udostępniamy tfma.writers.MetricsAndPlotsWriter , który konwertuje metryki i wykreśla słowniki na serializowane protosy i zapisuje je na dysku.
Jeśli chcesz użyć innego formatu serializacji, możesz utworzyć niestandardowy moduł zapisujący i użyć go zamiast tego. Ponieważ plik tfma.evaluators.Evaluation przekazany modułom piszącym zawiera dane wyjściowe wszystkich modułów oceniających łącznie, dostępna jest transformacja pomocnicza tfma.writers.Write , której moduły piszące mogą używać w swoich implementacjach ptransform w celu wybrania odpowiedniej beam.PCollection s w oparciu o klucz wyjściowy (przykład poniżej).
Personalizacja
Metoda tfma.run_model_analysis przyjmuje argumenty extractors , evaluators i writers w celu dostosowania ekstraktorów, ewaluatorów i zapisów używanych przez potok. Jeśli nie podano żadnych argumentów, domyślnie używane są tfma.default_extractors , tfma.default_evaluators i tfma.default_writers .
Niestandardowe ekstraktory
Aby utworzyć niestandardowy ekstraktor, utwórz typ tfma.extractors.Extractor , który otacza beam.PTransform , przyjmując tfma.Extracts jako dane wejściowe i zwracając tfma.Extracts jako dane wyjściowe. Przykłady ekstraktorów są dostępne w tfma.extractors .
Niestandardowi ewaluatorzy
Aby utworzyć niestandardowy ewaluator, utwórz typ tfma.evaluators.Evaluator , który otacza beam.PTransform , przyjmując tfma.Extracts jako dane wejściowe i zwracając tfma.evaluators.Evaluation jako dane wyjściowe. Bardzo prosty ewaluator może po prostu pobrać przychodzące tfma.Extracts i wyprowadzić je w celu przechowywania w tabeli. Dokładnie to robi tfma.evaluators.AnalysisTableEvaluator . Bardziej skomplikowany ewaluator może przeprowadzić dodatkowe przetwarzanie i agregację danych. Jako przykład zobacz tfma.evaluators.MetricsAndPlotsEvaluator .
Należy zauważyć, że sam tfma.evaluators.MetricsAndPlotsEvaluator można dostosować do obsługi niestandardowych metryk (więcej szczegółów można znaleźć w sekcji metryki ).
Autorzy niestandardowi
Aby utworzyć niestandardowy moduł zapisujący, utwórz typ tfma.writers.Writer , który otacza beam.PTransform , przyjmując tfma.evaluators.Evaluation jako dane wejściowe i zwracając beam.pvalue.PDone jako dane wyjściowe. Poniżej znajduje się podstawowy przykład programu piszącego do zapisywania rekordów TFRecord zawierających metryki:
tfma.writers.Writer(
stage_name='WriteTFRecord(%s)' % tfma.METRICS_KEY,
ptransform=tfma.writers.Write(
key=tfma.METRICS_KEY,
ptransform=beam.io.WriteToTFRecord(file_path_prefix=output_file))
Dane wejściowe autora zależą od wyników powiązanego oceniającego. W powyższym przykładzie wyjściem jest serializowany proto utworzony przez tfma.evaluators.MetricsAndPlotsEvaluator . Osoba pisząca dla tfma.evaluators.AnalysisTableEvaluator byłaby odpowiedzialna za wypisanie beam.pvalue.PCollection tfma.Extracts .
Należy zauważyć, że moduł piszący jest powiązany z wynikami oceniającego poprzez używany klucz wyjściowy (np. tfma.METRICS_KEY , tfma.ANALYSIS_KEY itp.).
Przykład krok po kroku
Poniżej znajduje się przykład kroków występujących w potoku ekstrakcji i oceny, gdy używane są zarówno tfma.evaluators.MetricsAndPlotsEvaluator , jak i tfma.evaluators.AnalysisTableEvaluator :
run_model_analysis(
...
extractors=[
tfma.extractors.InputExtractor(...),
tfma.extractors.PredictExtractor(...),
tfma.extractors.SliceKeyExtrator(...)
],
evaluators=[
tfma.evaluators.MetricsAndPlotsEvaluator(...),
tfma.evaluators.AnalysisTableEvaluator(...)
])
ReadInputs
# Out
Extracts {
'input': bytes # CSV, Proto, ...
}
ExtractAndEvaluate
# In: ReadInputs Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
}
# In: InputExtractor Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
}
# In: PredictExtractor Extracts
# Out:
Extracts {
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
'slice_key': Tuple[bytes...] # Slice
}
tfma.evaluators.MetricsAndPlotsEvaluator(uruchomiony po:SLICE_KEY_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
}
tfma.evaluators.AnalysisTableEvaluator(uruchomiony po:LAST_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'analysis': PCollection[Extracts] # Final Extracts
}
WriteResults
# In:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
'analysis': PCollection[Extracts] # Final Extracts
}
# Out: metrics, plots, and analysis files