
Performa TensorFlow Serving sangat bergantung pada aplikasi yang dijalankannya, lingkungan penerapannya, dan perangkat lunak lain yang berbagi akses ke resource perangkat keras yang mendasarinya. Oleh karena itu, penyetelan performanya bergantung pada kasus dan hanya ada sedikit aturan universal yang menjamin menghasilkan performa optimal di semua pengaturan. Oleh karena itu, dokumen ini bertujuan untuk merangkum beberapa prinsip umum dan praktik terbaik untuk menjalankan TensorFlow Serving.
Harap gunakan panduan Permintaan Inferensi Profil dengan TensorBoard untuk memahami perilaku mendasar komputasi model Anda pada permintaan inferensi, dan gunakan panduan ini untuk meningkatkan performanya secara berulang.
Tip Cepat
- Latensi permintaan pertama terlalu tinggi? Aktifkan pemanasan model .
- Tertarik pada pemanfaatan sumber daya atau throughput yang lebih tinggi? Konfigurasikan pengelompokan
Penyetelan Kinerja: Tujuan dan Parameter
Saat menyempurnakan performa TensorFlow Serving, biasanya ada 2 jenis tujuan yang mungkin Anda miliki dan 3 grup parameter yang perlu disesuaikan untuk meningkatkan tujuan tersebut.
Tujuan
TensorFlow Serving adalah sistem penyajian online untuk model yang dipelajari mesin. Seperti banyak sistem penyajian online lainnya, tujuan kinerja utamanya adalah memaksimalkan throughput sekaligus menjaga latensi ekor di bawah batas tertentu . Bergantung pada detail dan kematangan aplikasi Anda, Anda mungkin lebih mementingkan latensi rata-rata daripada latensi ekor , namun beberapa gagasan tentang latensi dan throughput biasanya merupakan metrik yang menjadi dasar penetapan tujuan kinerja Anda. Perlu diperhatikan bahwa kami tidak membahas ketersediaan dalam panduan ini karena hal tersebut lebih merupakan fungsi lingkungan penerapan.
Parameter
Secara kasar kita dapat memikirkan 3 kelompok parameter yang konfigurasinya menentukan performa yang diamati: 1) model TensorFlow 2) permintaan inferensi dan 3) server (perangkat keras & biner).
1) Model TensorFlow
Model ini mendefinisikan komputasi yang akan dilakukan TensorFlow Serving setelah menerima setiap permintaan masuk.
Di balik terpalnya, TensorFlow Serving menggunakan runtime TensorFlow untuk melakukan inferensi aktual atas permintaan Anda. Artinya, latensi rata-rata dalam melayani permintaan dengan TensorFlow Serving biasanya setidaknya setara dengan melakukan inferensi secara langsung dengan TensorFlow. Artinya, jika pada mesin tertentu, inferensi pada satu contoh membutuhkan waktu 2 detik, dan Anda memiliki target latensi subdetik, Anda perlu membuat profil permintaan inferensi, memahami operasi TensorFlow dan sub-grafik model Anda yang berkontribusi paling besar terhadap latensi tersebut , dan desain ulang model Anda dengan mempertimbangkan latensi inferensi sebagai batasan desain.
Perlu diperhatikan, meskipun latensi rata-rata dalam melakukan inferensi dengan TensorFlow Serving biasanya tidak lebih rendah dibandingkan menggunakan TensorFlow secara langsung, keunggulan TensorFlow Serving adalah menjaga latensi ekor tetap rendah bagi banyak klien yang menanyakan banyak model berbeda, sekaligus memanfaatkan perangkat keras yang mendasarinya secara efisien untuk memaksimalkan throughput .
2) Permintaan Inferensi
Permukaan API
TensorFlow Serving memiliki dua permukaan API (HTTP dan gRPC), keduanya mengimplementasikan PredictionService API (dengan pengecualian Server HTTP yang tidak menampilkan titik akhir MultiInference ). Kedua permukaan API telah disesuaikan dengan baik dan menambahkan latensi minimal, namun dalam praktiknya, permukaan gRPC dianggap memiliki performa yang sedikit lebih baik.
Metode API
Secara umum, disarankan untuk menggunakan titik akhir Klasifikasi dan Regres karena keduanya menerima tf.Example , yang merupakan abstraksi tingkat lebih tinggi; namun, dalam kasus permintaan terstruktur berukuran besar (O(Mb)) yang jarang terjadi, pengguna yang paham mungkin menemukan penggunaan PredictRequest dan secara langsung mengkodekan pesan Protobuf mereka ke dalam TensorProto, dan melewatkan serialisasi ke dalam dan deserialisasi dari tf.Contoh sumber peningkatan kinerja yang kecil.
Ukuran Batch
Ada dua cara utama pengelompokan dapat membantu kinerja Anda. Anda dapat mengonfigurasi klien Anda untuk mengirim permintaan batch ke TensorFlow Serving, atau Anda dapat mengirim permintaan individual dan mengonfigurasi TensorFlow Serving untuk menunggu hingga jangka waktu yang telah ditentukan, dan melakukan inferensi pada semua permintaan yang masuk dalam periode tersebut dalam satu batch. Mengonfigurasi batching jenis terakhir memungkinkan Anda mencapai TensorFlow Serving pada QPS yang sangat tinggi, sekaligus memungkinkannya menskalakan sumber daya komputasi yang diperlukan untuk mengimbanginya secara sub-linear. Hal ini dibahas lebih lanjut dalam panduan konfigurasi dan batching README .
3) Server (Perangkat Keras & Biner)
Biner TensorFlow Serving melakukan perhitungan yang cukup tepat terhadap perangkat keras yang menjalankannya. Oleh karena itu, Anda harus menghindari menjalankan aplikasi intensif komputasi atau memori lainnya pada mesin yang sama, terutama aplikasi dengan penggunaan sumber daya dinamis.
Seperti banyak jenis beban kerja lainnya, TensorFlow Serving lebih efisien ketika diterapkan pada mesin yang lebih kecil, lebih besar (lebih banyak CPU dan RAM) (yaitu Deployment dengan replicas yang lebih rendah dalam istilah Kubernetes). Hal ini disebabkan oleh potensi penerapan multi-penyewa yang lebih baik untuk memanfaatkan perangkat keras dan biaya tetap yang lebih rendah (server RPC, runtime TensorFlow, dll.).
Akselerator
Jika host Anda memiliki akses ke akselerator, pastikan Anda telah mengimplementasikan model Anda untuk melakukan komputasi padat pada akselerator - hal ini akan dilakukan secara otomatis jika Anda telah menggunakan TensorFlow API tingkat tinggi, namun jika Anda telah membuat grafik khusus, atau ingin memasang pin bagian grafik tertentu pada akselerator tertentu, Anda mungkin perlu menempatkan subgraf tertentu pada akselerator secara manual (yaitu menggunakan with tf.device('/device:GPU:0'): ... ).
CPU modern
CPU modern terus memperluas arsitektur set instruksi x86 untuk meningkatkan dukungan untuk SIMD (Single instruction Multiple Data) dan fitur-fitur lain yang penting untuk komputasi padat (misalnya perkalian dan penambahan dalam satu siklus clock). Namun, agar dapat berjalan pada mesin yang sedikit lebih tua, TensorFlow dan TensorFlow Serving dibuat dengan asumsi sederhana bahwa fitur terbaru ini tidak didukung oleh CPU host.
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Jika Anda melihat entri log ini (mungkin ekstensi berbeda dari 2 ekstensi yang tercantum) di permulaan TensorFlow Serving, itu berarti Anda dapat membangun kembali TensorFlow Serving dan menargetkan platform host khusus Anda dan menikmati performa yang lebih baik. Membangun Pelayanan TensorFlow dari sumber relatif mudah menggunakan Docker dan didokumentasikan di sini .
Konfigurasi Biner
TensorFlow Serving menawarkan sejumlah tombol konfigurasi yang mengatur perilaku runtime, sebagian besar diatur melalui tanda baris perintah . Beberapa di antaranya (terutama tensorflow_intra_op_parallelism dan tensorflow_inter_op_parallelism ) diturunkan untuk mengonfigurasi runtime TensorFlow dan dikonfigurasi secara otomatis, yang dapat diganti oleh pengguna yang paham dengan melakukan banyak eksperimen dan menemukan konfigurasi yang tepat untuk beban kerja dan lingkungan spesifik mereka.
Kehidupan permintaan inferensi TensorFlow Serving
Mari kita lihat secara singkat contoh prototipikal permintaan inferensi TensorFlow Serving untuk melihat perjalanan yang dilalui oleh permintaan pada umumnya. Sebagai contoh, kita akan mendalami Permintaan Prediksi yang diterima oleh platform gRPC API Penyajian TensorFlow 2.0.0.
Pertama-tama mari kita lihat diagram urutan tingkat komponen, lalu beralih ke kode yang mengimplementasikan rangkaian interaksi ini.
Diagram Urutan
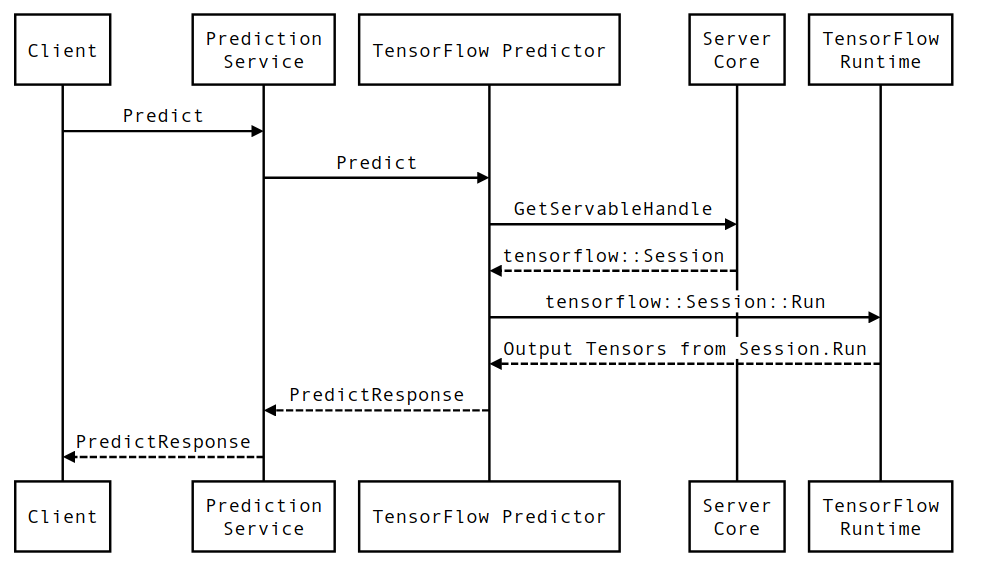
Perhatikan bahwa Klien adalah komponen yang dimiliki oleh pengguna, Layanan Prediksi, Servable, dan Server Core dimiliki oleh TensorFlow Serving, dan TensorFlow Runtime dimiliki oleh Core TensorFlow .
Detail Urutan
-
PredictionServiceImpl::PredictmenerimaPredictRequest - Kami memanggil
TensorflowPredictor::Predict, menyebarkan batas waktu permintaan dari permintaan gRPC (jika sudah ditetapkan). - Di dalam
TensorflowPredictor::Predict, kami mencari Servable (model) yang permintaannya ingin dilakukan inferensi, dari situ kami mengambil informasi tentang SavedModel dan yang lebih penting, pegangan ke objekSessiontempat grafik model berada (mungkin sebagian) sarat. Objek Servable ini dibuat dan diterapkan di memori saat model dimuat oleh TensorFlow Serving. Kami kemudian memanggil internal::RunPredict untuk melaksanakan prediksi. - Di
internal::RunPredict, setelah memvalidasi dan memproses permintaan terlebih dahulu, kita menggunakan objekSessionuntuk melakukan inferensi menggunakan panggilan pemblokiran ke Session::Run , yang kemudian kita masukkan basis kode inti TensorFlow. SetelahSession::Runkembali dan tensoroutputskami telah diisi, kami mengonversi keluaran menjadiPredictionResponsedan mengembalikan hasilnya ke tumpukan panggilan.