
بعد نشر خدمة TensorFlow وإصدار الطلبات من العميل الخاص بك، قد تلاحظ أن الطلبات تستغرق وقتًا أطول مما كنت تتوقع، أو أنك لا تحقق الإنتاجية التي كنت ترغب فيها.
في هذا الدليل، سنستخدم ملف التعريف الخاص بـ TensorBoard، والذي قد تستخدمه بالفعل لتدريب نموذج الملف الشخصي ، لتتبع طلبات الاستدلال لمساعدتنا في تصحيح الأخطاء وتحسين أداء الاستدلال.
يجب عليك استخدام هذا الدليل جنبًا إلى جنب مع أفضل الممارسات الموضحة في دليل الأداء لتحسين النموذج والطلبات ومثيل TensorFlow Serving.
ملخص
على مستوى عالٍ، سنوجه أداة التوصيف الخاصة بـ TensorBoard إلى خادم gRPC الخاص بـ TensorFlow Serving. عندما نرسل طلب استدلال إلى Tensorflow Serving، سنستخدم أيضًا واجهة مستخدم TensorBoard في نفس الوقت لنطلب منه التقاط آثار هذا الطلب. خلف الكواليس، سيتحدث TensorBoard مع TensorFlow Serving عبر gRPC ويطلب منه تقديم تتبع مفصل لعمر طلب الاستدلال. سيقوم TensorBoard بعد ذلك بتصور نشاط كل مؤشر ترابط على كل جهاز حوسبة (تشغيل التعليمات البرمجية المدمجة مع profiler::TraceMe ) على مدار عمر الطلب على واجهة مستخدم TensorBoard لكي نستهلكه.
المتطلبات الأساسية
-
Tensorflow>=2.0.0 - TensorBoard (يجب تثبيته إذا تم تثبيت TF عبر
pip) - Docker (الذي سنستخدمه لتنزيل وتشغيل خدمة TF>=2.1.0 صورة)
نشر النموذج باستخدام خدمة TensorFlow
في هذا المثال، سنستخدم Docker، الطريقة الموصى بها لنشر Tensorflow Serving، لاستضافة نموذج لعبة يحسب f(x) = x / 2 + 2 الموجود في مستودع Tensorflow Serving Github .
قم بتنزيل مصدر خدمة TensorFlow.
git clone https://github.com/tensorflow/serving /tmp/serving
cd /tmp/serving
قم بتشغيل TensorFlow Serving عبر Docker وانشر نموذج half_plus_two.
docker pull tensorflow/serving
MODELS_DIR="$(pwd)/tensorflow_serving/servables/tensorflow/testdata"
docker run -it --rm -p 8500:8500 -p 8501:8501 \
-v $MODELS_DIR/saved_model_half_plus_two_cpu:/models/half_plus_two \
-v /tmp/tensorboard:/tmp/tensorboard \
-e MODEL_NAME=half_plus_two \
tensorflow/serving
في محطة طرفية أخرى، استعلم عن النموذج للتأكد من نشر النموذج بشكل صحيح
curl -d '{"instances": [1.0, 2.0, 5.0]}' \
-X POST http://localhost:8501/v1/models/half_plus_two:predict
# Returns => { "predictions": [2.5, 3.0, 4.5] }
قم بإعداد ملف تعريف TensorBoard
في محطة طرفية أخرى، قم بتشغيل أداة TensorBoard على جهازك، مع توفير دليل لحفظ أحداث تتبع الاستدلال إلى:
mkdir -p /tmp/tensorboard
tensorboard --logdir /tmp/tensorboard --port 6006
انتقل إلى http://localhost:6006/ لعرض واجهة مستخدم TensorBoard. استخدم القائمة المنسدلة في الجزء العلوي للانتقال إلى علامة التبويب الملف الشخصي. انقر فوق التقاط الملف الشخصي وقم بتوفير عنوان خادم gRPC الخاص بـ Tensorflow Serving.
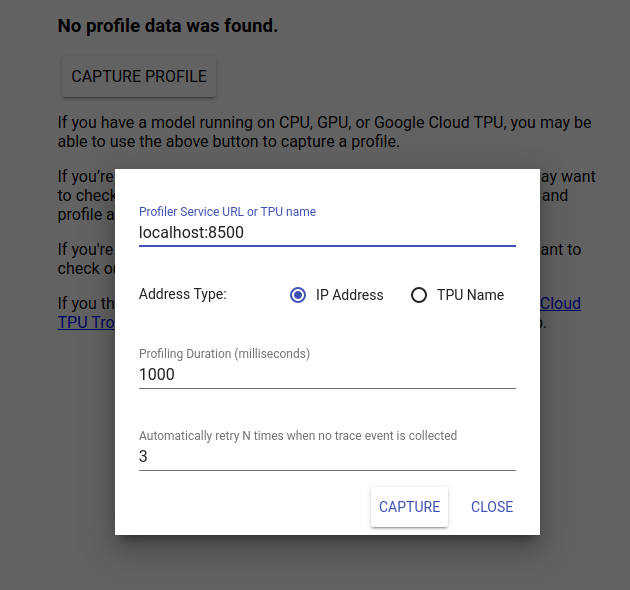
بمجرد الضغط على "Capture"، سيبدأ TensorBoard في إرسال طلبات الملف الشخصي إلى الخادم النموذجي. في مربع الحوار أعلاه، يمكنك تعيين الموعد النهائي لكل طلب والعدد الإجمالي للمرات التي سيعيد فيها Tensorboard المحاولة إذا لم يتم جمع أي أحداث تتبع. إذا كنت تقوم بإنشاء ملف تعريف لنموذج باهظ الثمن، فقد ترغب في زيادة الموعد النهائي لضمان عدم انتهاء مهلة طلب ملف التعريف قبل اكتمال طلب الاستدلال.
إرسال وملف طلب الاستدلال
اضغط على Capture على TensorBoard UI وأرسل طلب استنتاج إلى TF Serving بسرعة بعد ذلك.
curl -d '{"instances": [1.0, 2.0, 5.0]}' -X POST \
http://localhost:8501/v1/models/half_plus_two:predict
من المفترض أن تشاهد رسالة "تم التقاط الملف التعريفي بنجاح. يرجى التحديث." يظهر الخبز المحمص في أسفل الشاشة. وهذا يعني أن TensorBoard كان قادرًا على استرداد أحداث التتبع من خدمة TensorFlow وحفظها في logdir الخاص بك. قم بتحديث الصفحة لتصور طلب الاستدلال باستخدام عارض التتبع الخاص بملف التعريف، كما هو موضح في القسم التالي.
تحليل تتبع طلب الاستدلال

يمكنك الآن بسهولة معرفة العمليات الحسابية التي تتم نتيجة لطلب الاستدلال الخاص بك. يمكنك تكبير/تصغير أي من المستطيلات والنقر عليها (تتبع الأحداث) للحصول على مزيد من المعلومات مثل وقت البدء الدقيق ومدة الجدار.
على مستوى عالٍ، نرى خيطين ينتميان إلى وقت تشغيل TensorFlow وخيطًا ثالثًا ينتمي إلى خادم REST، يتعاملان مع تلقي طلب HTTP وإنشاء جلسة TensorFlow.
يمكننا التكبير لرؤية ما يحدث داخل SessionRun.

في الموضوع الثاني، نرى استدعاء ExecutorState::Process أولي لا يتم فيه تشغيل عمليات TensorFlow ولكن يتم تنفيذ خطوات التهيئة.
في الموضوع الأول، نرى استدعاء لقراءة المتغير الأول، وبمجرد توفر المتغير الثاني أيضًا، يتم تنفيذ الضرب وإضافة النوى بالتسلسل. أخيرًا، يشير المنفذ إلى أن حسابه قد تم عن طريق استدعاء DoneCallback ويمكن إغلاق الجلسة.
الخطوات التالية
على الرغم من أن هذا مثال بسيط، إلا أنه يمكنك استخدام نفس العملية لتكوين نماذج أكثر تعقيدًا، مما يسمح لك بتحديد العمليات البطيئة أو الاختناقات في بنية النموذج الخاص بك لتحسين أدائه.
يرجى الرجوع إلى دليل ملف تعريف TensorBoard للحصول على برنامج تعليمي أكثر اكتمالاً حول ميزات ملف تعريف TensorBoard ودليل أداء خدمة TensorFlow لمعرفة المزيد حول تحسين أداء الاستدلال.