
Dopo aver distribuito TensorFlow Serving ed emesso richieste dal tuo client, potresti notare che le richieste richiedono più tempo del previsto o che non stai raggiungendo il throughput che avresti desiderato.
In questa guida utilizzeremo il Profiler di TensorBoard, che potresti già utilizzare per profilare l'addestramento del modello , per tracciare le richieste di inferenza per aiutarci a eseguire il debug e migliorare le prestazioni di inferenza.
Dovresti utilizzare questa guida insieme alle best practice indicate nella Guida alle prestazioni per ottimizzare il modello, le richieste e l'istanza di TensorFlow Serving.
Panoramica
Ad alto livello, indicheremo lo strumento di profilazione di TensorBoard al server gRPC di TensorFlow Serving. Quando inviamo una richiesta di inferenza a Tensorflow Serving, utilizzeremo contemporaneamente anche l'interfaccia utente di TensorBoard per chiedergli di acquisire le tracce di questa richiesta. Dietro le quinte, TensorBoard parlerà con TensorFlow Serving su gRPC e gli chiederà di fornire una traccia dettagliata della durata della richiesta di inferenza. TensorBoard visualizzerà quindi l'attività di ogni thread su ogni dispositivo di elaborazione (codice in esecuzione integrato con profiler::TraceMe ) nel corso della durata della richiesta sull'interfaccia utente di TensorBoard affinché possiamo consumarla.
Prerequisiti
-
Tensorflow>=2.0.0 - TensorBoard (dovrebbe essere installato se TF è stato installato tramite
pip) - Docker (che utilizzeremo per scaricare ed eseguire il servizio TF>=immagine 2.1.0)
Distribuisci il modello con TensorFlow Serving
Per questo esempio, utilizzeremo Docker, il modo consigliato per distribuire Tensorflow Serving, per ospitare un modello giocattolo che calcola f(x) = x / 2 + 2 trovato nel repository Github di Tensorflow Serving .
Scarica il codice sorgente di TensorFlow Serving.
git clone https://github.com/tensorflow/serving /tmp/serving
cd /tmp/serving
Avvia TensorFlow Serving tramite Docker e distribuisci il modello half_plus_two.
docker pull tensorflow/serving
MODELS_DIR="$(pwd)/tensorflow_serving/servables/tensorflow/testdata"
docker run -it --rm -p 8500:8500 -p 8501:8501 \
-v $MODELS_DIR/saved_model_half_plus_two_cpu:/models/half_plus_two \
-v /tmp/tensorboard:/tmp/tensorboard \
-e MODEL_NAME=half_plus_two \
tensorflow/serving
In un altro terminale, interroga il modello per assicurarti che il modello sia distribuito correttamente
curl -d '{"instances": [1.0, 2.0, 5.0]}' \
-X POST http://localhost:8501/v1/models/half_plus_two:predict
# Returns => { "predictions": [2.5, 3.0, 4.5] }
Configura il Profiler di TensorBoard
In un altro terminale, avvia lo strumento TensorBoard sul tuo computer, fornendo una directory in cui salvare gli eventi di traccia dell'inferenza in:
mkdir -p /tmp/tensorboard
tensorboard --logdir /tmp/tensorboard --port 6006
Passare a http://localhost:6006/ per visualizzare l'interfaccia utente di TensorBoard. Utilizza il menu a discesa in alto per accedere alla scheda Profilo. Fai clic su Acquisisci profilo e fornisci l'indirizzo del server gRPC di Tensorflow Serving.
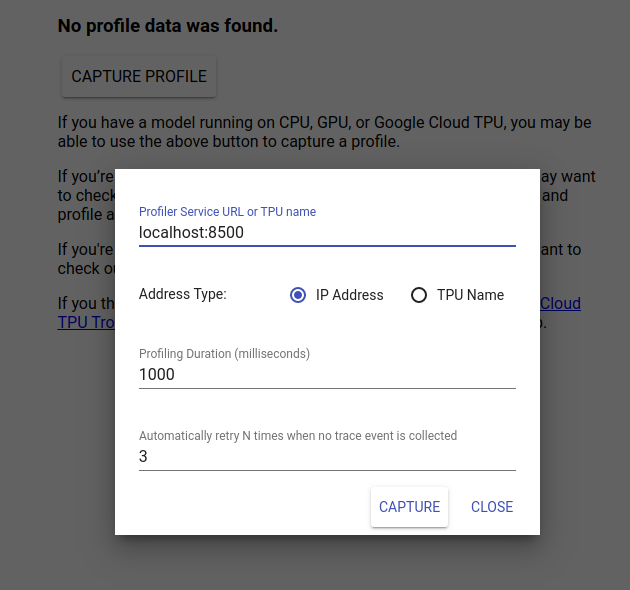
Non appena premi "Cattura", TensorBoard inizierà a inviare richieste di profilo al server del modello. Nella finestra di dialogo in alto, puoi impostare sia la scadenza per ciascuna richiesta sia il numero totale di volte in cui Tensorboard riproverà se non vengono raccolti eventi di traccia. Se stai profilando un modello costoso, potresti voler aumentare la scadenza per garantire che la richiesta del profilo non scada prima del completamento della richiesta di inferenza.
Invia e profila una richiesta di inferenza
Premi Capture sull'interfaccia utente di TensorBoard e invia subito una richiesta di inferenza a TF Serving.
curl -d '{"instances": [1.0, 2.0, 5.0]}' -X POST \
http://localhost:8501/v1/models/half_plus_two:predict
Dovresti vedere il messaggio "Acquisisci profilo con successo. Aggiorna." il toast appare nella parte inferiore dello schermo. Ciò significa che TensorBoard è stato in grado di recuperare eventi di traccia da TensorFlow Serving e salvarli nella tua logdir . Aggiorna la pagina per visualizzare la richiesta di inferenza con il Trace Viewer di The Profiler, come visto nella sezione successiva.
Analizzare la traccia della richiesta di inferenza

Ora puoi vedere facilmente quale calcolo sta avvenendo come risultato della tua richiesta di inferenza. È possibile ingrandire e fare clic su uno qualsiasi dei rettangoli (traccia eventi) per ottenere maggiori informazioni come l'ora esatta di inizio e la durata del muro.
Ad alto livello, vediamo due thread appartenenti al runtime TensorFlow e un terzo che appartiene al server REST, che gestisce la ricezione della richiesta HTTP e la creazione di una sessione TensorFlow.
Possiamo ingrandire per vedere cosa succede all'interno di SessionRun.

Nel secondo thread, vediamo una chiamata ExecutorState::Process iniziale in cui non vengono eseguite operazioni TensorFlow ma vengono eseguiti passaggi di inizializzazione.
Nel primo thread vediamo la chiamata per leggere la prima variabile e, una volta disponibile anche la seconda variabile, esegue la moltiplicazione e aggiunge i kernel in sequenza. Infine, l'Executor segnala che il suo calcolo è stato eseguito chiamando DoneCallback e la Session può essere chiusa.
Passaggi successivi
Sebbene questo sia un semplice esempio, puoi utilizzare lo stesso processo per profilare modelli molto più complessi, consentendoti di identificare operazioni lente o colli di bottiglia nell'architettura del modello per migliorarne le prestazioni.
Consulta la Guida al Profiler di TensorBoard per un tutorial più completo sulle funzionalità del Profiler di TensorBoard e la Guida alle prestazioni di servizio di TensorFlow per ulteriori informazioni sull'ottimizzazione delle prestazioni di inferenza.