
Introduzione
TFX è una piattaforma di machine learning (ML) su scala di produzione di Google basata su TensorFlow. Fornisce un framework di configurazione e librerie condivise per integrare i componenti comuni necessari per definire, avviare e monitorare il sistema di machine learning.
TFX 1.0
Siamo lieti di annunciare la disponibilità di TFX 1.0.0 . Questa è la versione iniziale post-beta di TFX, che fornisce API e artefatti pubblici stabili. Puoi essere certo che le tue future pipeline TFX continueranno a funzionare dopo un aggiornamento nell'ambito di compatibilità definito in questa RFC .
Installazione

![]()
pip install tfx
Pacchetti notturni
TFX ospita anche pacchetti notturni su https://pypi-nightly.tensorflow.org su Google Cloud. Per installare l'ultimo pacchetto notturno, utilizzare il seguente comando:
pip install --extra-index-url https://pypi-nightly.tensorflow.org/simple --pre tfx
Verranno installati i pacchetti notturni per le principali dipendenze di TFX come TensorFlow Model Analysis (TFMA), TensorFlow Data Validation (TFDV), TensorFlow Transform (TFT), TFX Basic Shared Libraries (TFX-BSL), ML Metadata (MLMD).
Informazioni su TFX
TFX è una piattaforma per la creazione e la gestione di flussi di lavoro ML in un ambiente di produzione. TFX fornisce quanto segue:
Un toolkit per la creazione di pipeline ML. Le pipeline TFX ti consentono di orchestrare il tuo flusso di lavoro ML su diverse piattaforme, come: Apache Airflow, Apache Beam e Kubeflow Pipelines.
Un set di componenti standard che puoi utilizzare come parte di una pipeline o come parte dello script di formazione ML. I componenti standard TFX forniscono funzionalità comprovate per aiutarti a iniziare facilmente a creare un processo ML.
Librerie che forniscono le funzionalità di base per molti dei componenti standard. Puoi utilizzare le librerie TFX per aggiungere questa funzionalità ai tuoi componenti personalizzati o utilizzarle separatamente.
TFX è un toolkit di machine learning su scala di produzione di Google basato su TensorFlow. Fornisce un framework di configurazione e librerie condivise per integrare i componenti comuni necessari per definire, avviare e monitorare il sistema di machine learning.
Componenti standard TFX
Una pipeline TFX è una sequenza di componenti che implementano una pipeline ML progettata specificamente per attività di machine learning scalabili e ad alte prestazioni. Ciò include la modellazione, la formazione, l'inferenza di servizio e la gestione delle distribuzioni su target online, mobili nativi e JavaScript.
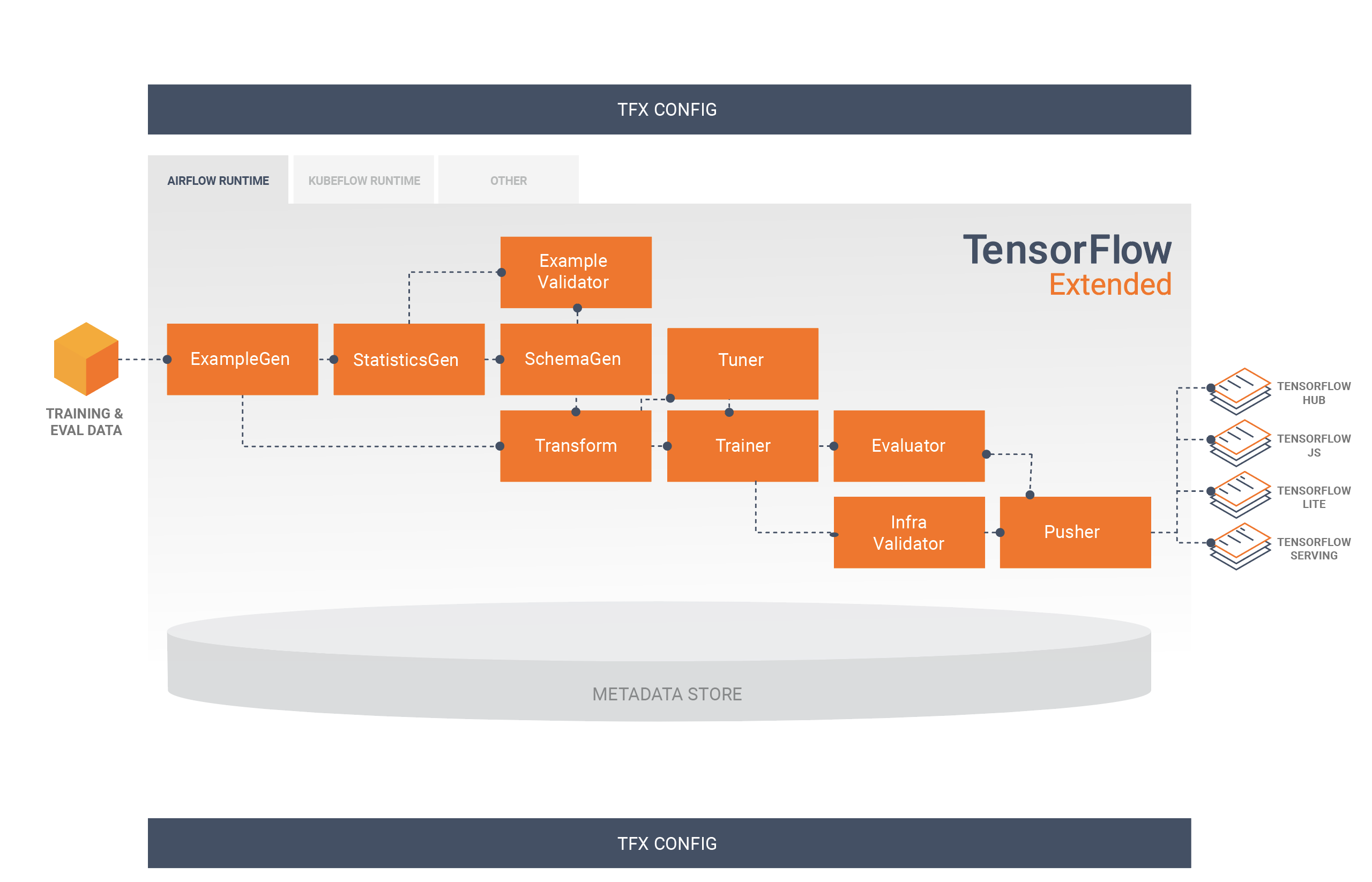
Una pipeline TFX include in genere i seguenti componenti:
EsempioGen è il componente di input iniziale di una pipeline che inserisce e facoltativamente divide il set di dati di input.
StatisticsGen calcola le statistiche per il set di dati.
SchemaGen esamina le statistiche e crea uno schema di dati.
EsempioValidator cerca anomalie e valori mancanti nel set di dati.
Transform esegue la progettazione delle funzionalità sul set di dati.
Il formatore addestra il modello.
Il sintonizzatore ottimizza gli iperparametri del modello.
Evaluator esegue un'analisi approfondita dei risultati della formazione e ti aiuta a convalidare i modelli esportati, assicurando che siano "abbastanza buoni" per essere messi in produzione.
InfraValidator verifica che il modello sia effettivamente utilizzabile dall'infrastruttura e impedisce l'invio di modelli non validi.
Pusher distribuisce il modello su un'infrastruttura di servizio.
BulkInferrer esegue l'elaborazione batch su un modello con richieste di inferenza senza etichetta.
Questo diagramma illustra il flusso di dati tra questi componenti:
Librerie TFX
TFX include sia librerie che componenti della pipeline. Questo diagramma illustra le relazioni tra le librerie TFX e i componenti della pipeline:
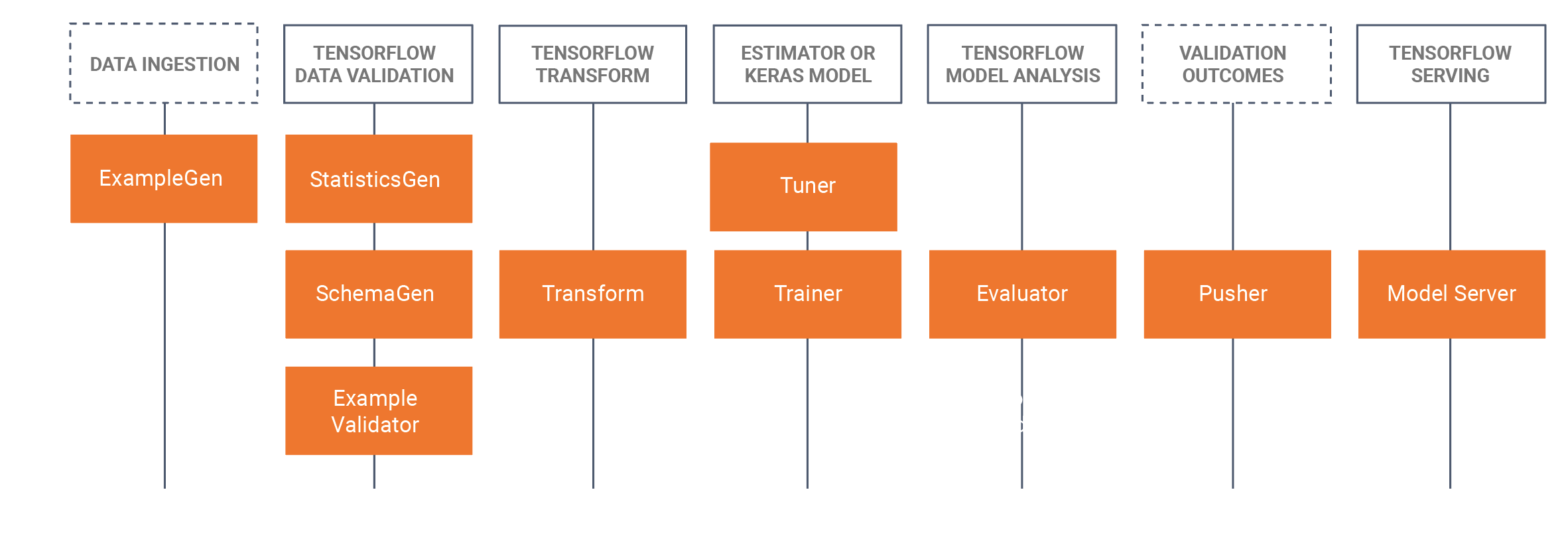
TFX fornisce diversi pacchetti Python che sono le librerie utilizzate per creare componenti della pipeline. Utilizzerai queste librerie per creare i componenti delle tue pipeline in modo che il tuo codice possa concentrarsi sugli aspetti univoci della tua pipeline.
Le librerie TFX includono:
TensorFlow Data Validation (TFDV) è una libreria per l'analisi e la convalida dei dati di machine learning. È progettato per essere altamente scalabile e per funzionare bene con TensorFlow e TFX. TFDV include:
- Calcolo scalabile delle statistiche riassuntive dei dati di allenamento e test.
- Integrazione con un visualizzatore per distribuzioni di dati e statistiche, nonché confronto sfaccettato di coppie di set di dati (Facets).
- Generazione automatizzata di schemi di dati per descrivere le aspettative sui dati come valori, intervalli e vocabolari richiesti.
- Un visualizzatore di schemi per aiutarti a ispezionare lo schema.
- Rilevamento delle anomalie per identificare anomalie, come funzionalità mancanti, valori fuori intervallo o tipi di funzionalità errati, solo per citarne alcuni.
- Un visualizzatore di anomalie in modo da poter vedere quali funzionalità presentano anomalie e saperne di più per correggerle.
TensorFlow Transform (TFT) è una libreria per la preelaborazione dei dati con TensorFlow. TensorFlow Transform è utile per i dati che richiedono un passaggio completo, come:
- Normalizzare un valore di input mediante media e deviazione standard.
- Converti stringhe in numeri interi generando un vocabolario su tutti i valori di input.
- Converti i float in numeri interi assegnandoli ai bucket in base alla distribuzione dei dati osservata.
TensorFlow viene utilizzato per addestrare modelli con TFX. Importa dati di training e codice di modellazione e crea un risultato SavedModel. Integra inoltre una pipeline di progettazione delle funzionalità creata da TensorFlow Transform per la preelaborazione dei dati di input.
KerasTuner viene utilizzato per ottimizzare gli iperparametri per il modello.
TensorFlow Model Analysis (TFMA) è una libreria per la valutazione dei modelli TensorFlow. Viene utilizzato insieme a TensorFlow per creare un EvalSavedModel, che diventa la base per la sua analisi. Consente agli utenti di valutare i propri modelli su grandi quantità di dati in modo distribuito, utilizzando le stesse metriche definite nel loro trainer. Queste metriche possono essere calcolate su diverse sezioni di dati e visualizzate nei notebook Jupyter.
TensorFlow Metadata (TFMD) fornisce rappresentazioni standard per i metadati utili durante il training di modelli di machine learning con TensorFlow. I metadati possono essere prodotti manualmente o automaticamente durante l'analisi dei dati di input e possono essere utilizzati per la convalida, l'esplorazione e la trasformazione dei dati. I formati di serializzazione dei metadati includono:
- Uno schema che descrive dati tabulari (ad esempio, tf.Examples).
- Una raccolta di statistiche riassuntive su tali set di dati.
ML Metadata (MLMD) è una libreria per la registrazione e il recupero dei metadati associati ai flussi di lavoro degli sviluppatori ML e dei data scientist. Molto spesso i metadati utilizzano rappresentazioni TFMD. MLMD gestisce la persistenza utilizzando SQL-Lite , MySQL e altri archivi dati simili.
Tecnologie di supporto
Necessario
- Apache Beam è un modello unificato e open source per la definizione di pipeline di elaborazione parallela dei dati sia in batch che in streaming. TFX utilizza Apache Beam per implementare pipeline parallele di dati. La pipeline viene quindi eseguita da uno dei backend di elaborazione distribuita supportati da Beam, che includono Apache Flink, Apache Spark, Google Cloud Dataflow e altri.
Opzionale
Gli orchestratori come Apache Airflow e Kubeflow semplificano la configurazione, il funzionamento, il monitoraggio e la manutenzione di una pipeline ML.
Apache Airflow è una piattaforma per creare, pianificare e monitorare i flussi di lavoro in modo programmatico. TFX utilizza Airflow per creare flussi di lavoro come grafici aciclici diretti (DAG) di attività. Lo scheduler Airflow esegue attività su una serie di lavoratori seguendo le dipendenze specificate. Le ricche utilità della riga di comando semplificano l'esecuzione di interventi chirurgici complessi sui DAG. La ricca interfaccia utente semplifica la visualizzazione delle pipeline in esecuzione in produzione, il monitoraggio dei progressi e la risoluzione dei problemi quando necessario. Quando i flussi di lavoro vengono definiti come codice, diventano più gestibili, modificabili, testabili e collaborativi.
Kubeflow si impegna a rendere le distribuzioni di flussi di lavoro di machine learning (ML) su Kubernetes semplici, portatili e scalabili. L'obiettivo di Kubeflow non è quello di ricreare altri servizi, ma di fornire un modo semplice per distribuire i migliori sistemi open source per il machine learning su diverse infrastrutture. Le pipeline Kubeflow consentono la composizione e l'esecuzione di flussi di lavoro riproducibili su Kubeflow, integrati con la sperimentazione e le esperienze basate su notebook. I servizi Kubeflow Pipelines su Kubernetes includono l'archivio metadati ospitato, il motore di orchestrazione basato su contenitori, il server notebook e l'interfaccia utente per aiutare gli utenti a sviluppare, eseguire e gestire pipeline ML complesse su larga scala. Kubeflow Pipelines SDK consente la creazione e la condivisione di componenti e la composizione di pipeline a livello di codice.
Portabilità e interoperabilità
TFX è progettato per essere portabile su più ambienti e framework di orchestrazione, tra cui Apache Airflow , Apache Beam e Kubeflow . È anche portabile su diverse piattaforme informatiche, comprese quelle on-premise, e su piattaforme cloud come Google Cloud Platform (GCP) . In particolare, TFX interagisce con diversi servizi GCP gestiti, come Cloud AI Platform for Training and Prediction e Cloud Dataflow per l'elaborazione distribuita dei dati per molti altri aspetti del ciclo di vita ML.
Modello e modello salvato
Modello
Un modello è il risultato del processo di formazione. È la registrazione serializzata dei pesi appresi durante il processo di allenamento. Questi pesi possono essere successivamente utilizzati per calcolare previsioni per nuovi esempi di input. Per TFX e TensorFlow, il "modello" si riferisce ai checkpoint contenenti i pesi appresi fino a quel momento.
Tieni presente che "modello" potrebbe anche riferirsi alla definizione del grafico di calcolo di TensorFlow (ovvero un file Python) che esprime come verrà calcolata una previsione. I due sensi possono essere usati in modo intercambiabile in base al contesto.
Modello salvato
- Cos'è un SavedModel : una serializzazione universale, indipendente dal linguaggio, ermetica e recuperabile di un modello TensorFlow.
- Perché è importante : consente ai sistemi di livello superiore di produrre, trasformare e consumare modelli TensorFlow utilizzando un'unica astrazione.
SavedModel è il formato di serializzazione consigliato per servire un modello TensorFlow in produzione o esportare un modello addestrato per un'applicazione mobile o JavaScript nativa. Ad esempio, per trasformare un modello in un servizio REST per effettuare previsioni, puoi serializzare il modello come SavedModel e servirlo utilizzando TensorFlow Serving. Per ulteriori informazioni, consulta Servire un modello TensorFlow .
Schema
Alcuni componenti TFX utilizzano una descrizione dei dati di input denominata schema . Lo schema è un'istanza di schema.proto . Gli schemi sono un tipo di buffer di protocollo , più generalmente noto come "protobuf". Lo schema può specificare i tipi di dati per i valori delle caratteristiche, se una caratteristica deve essere presente in tutti gli esempi, gli intervalli di valori consentiti e altre proprietà. Uno dei vantaggi derivanti dall'utilizzo di TensorFlow Data Validation (TFDV) è che genererà automaticamente uno schema deducendo tipi, categorie e intervalli dai dati di training.
Ecco un estratto da uno schema protobuf:
...
feature {
name: "age"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
feature {
name: "capital-gain"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
...
I seguenti componenti utilizzano lo schema:
- Convalida dei dati TensorFlow
- Trasformata TensorFlow
In una tipica pipeline TFX, TensorFlow Data Validation genera uno schema, che viene utilizzato dagli altri componenti.
Sviluppare con TFX
TFX fornisce una potente piattaforma per ogni fase di un progetto di machine learning, dalla ricerca, sperimentazione e sviluppo sul tuo computer locale, fino alla distribuzione. Per evitare la duplicazione del codice ed eliminare il potenziale di distorsione dell'addestramento/servizio, si consiglia vivamente di implementare la pipeline TFX sia per l'addestramento del modello che per la distribuzione di modelli addestrati e utilizzare i componenti Transform che sfruttano la libreria TensorFlow Transform sia per l'addestramento che per l'inferenza. In questo modo utilizzerai lo stesso codice di preelaborazione e analisi in modo coerente ed eviterai differenze tra i dati utilizzati per l'addestramento e i dati forniti ai modelli addestrati in produzione, oltre a trarre vantaggio dalla scrittura di quel codice una volta.
Esplorazione, visualizzazione e pulizia dei dati
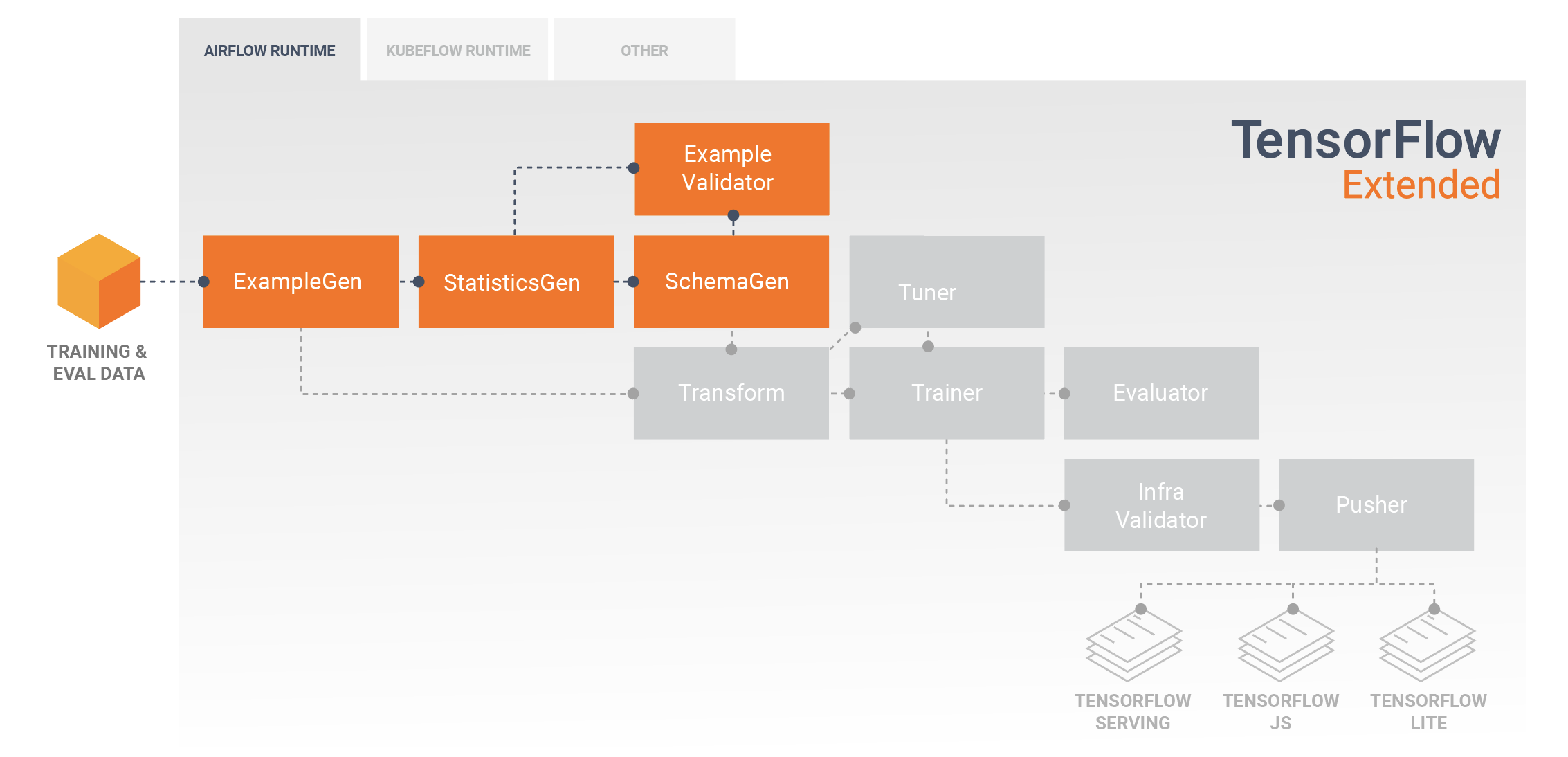
Le pipeline TFX in genere iniziano con un componente EsempioGen , che accetta dati di input e li formatta come tf.Examples. Spesso questo viene fatto dopo che i dati sono stati suddivisi in set di dati di addestramento e valutazione in modo che ci siano effettivamente due copie dei componenti di EsempioGen, una ciascuna per l'addestramento e una per la valutazione. Questo è in genere seguito da un componente StatisticsGen e da un componente SchemaGen , che esaminerà i tuoi dati e dedurrà uno schema di dati e statistiche. Lo schema e le statistiche verranno utilizzati da un componente EsempioValidator , che cercherà anomalie, valori mancanti e tipi di dati errati nei tuoi dati. Tutti questi componenti sfruttano le funzionalità della libreria TensorFlow Data Validation .
TensorFlow Data Validation (TFDV) è uno strumento prezioso durante l'esplorazione iniziale, la visualizzazione e la pulizia del set di dati. TFDV esamina i tuoi dati e deduce i tipi di dati, le categorie e gli intervalli, quindi aiuta automaticamente a identificare anomalie e valori mancanti. Fornisce inoltre strumenti di visualizzazione che possono aiutarti a esaminare e comprendere il tuo set di dati. Una volta completata la pipeline, puoi leggere i metadati da MLMD e utilizzare gli strumenti di visualizzazione di TFDV in un notebook Jupyter per analizzare i tuoi dati.
Dopo l'addestramento e l'implementazione iniziali del modello, TFDV può essere utilizzato per monitorare i nuovi dati dalle richieste di inferenza ai modelli distribuiti e cercare anomalie e/o derive. Ciò è particolarmente utile per i dati di serie temporali che cambiano nel tempo a causa di tendenze o stagionalità e può aiutare a informare quando si verificano problemi con i dati o quando i modelli devono essere riqualificati su nuovi dati.
Visualizzazione dei dati
Dopo aver completato la prima esecuzione dei dati attraverso la sezione della pipeline che utilizza TFDV (in genere StatisticsGen, SchemaGen ed EsempioValidator) puoi visualizzare i risultati in un notebook in stile Jupyter. Per esecuzioni aggiuntive è possibile confrontare questi risultati mentre si apportano modifiche, fino a quando i dati non saranno ottimali per il modello e l'applicazione.
Per prima cosa eseguirai una query su ML Metadata (MLMD) per individuare i risultati di queste esecuzioni di questi componenti, quindi utilizzerai l'API di supporto della visualizzazione in TFDV per creare le visualizzazioni nel tuo notebook. Ciò include tfdv.load_statistics() e tfdv.visualize_statistics() Utilizzando questa visualizzazione puoi comprendere meglio le caratteristiche del tuo set di dati e, se necessario, modificarle come richiesto.
Modelli di sviluppo e formazione
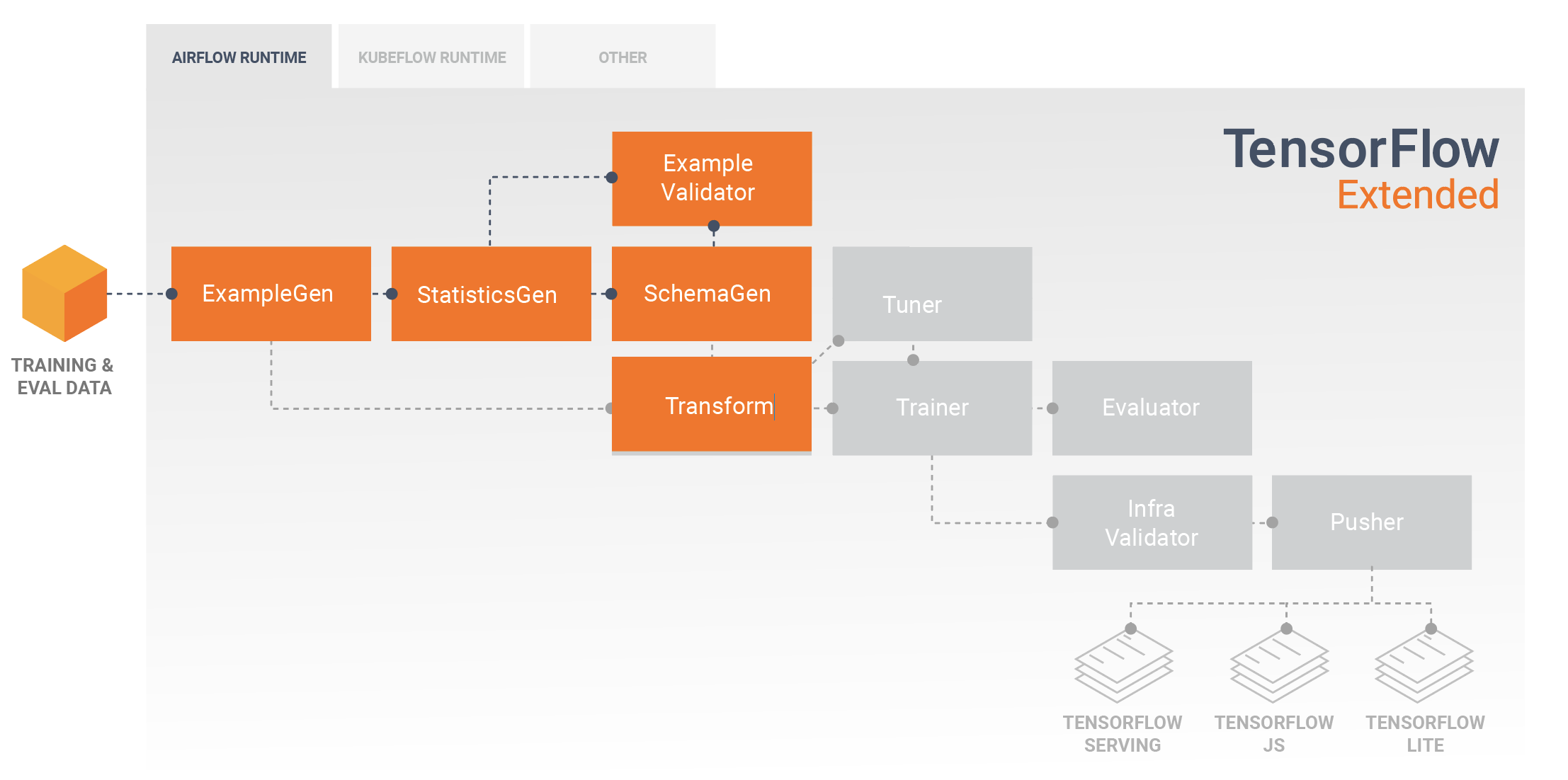
Una tipica pipeline TFX includerà un componente Transform , che eseguirà l'ingegneria delle funzionalità sfruttando le capacità della libreria TensorFlow Transform (TFT) . Un componente Transform utilizza lo schema creato da un componente SchemaGen e applica trasformazioni di dati per creare, combinare e trasformare le funzionalità che verranno utilizzate per addestrare il modello. La pulizia dei valori mancanti e la conversione dei tipi dovrebbero essere eseguite anche nel componente Trasformazione se esiste la possibilità che questi siano presenti anche nei dati inviati per le richieste di inferenza. Esistono alcune considerazioni importanti durante la progettazione del codice TensorFlow per l'addestramento in TFX.
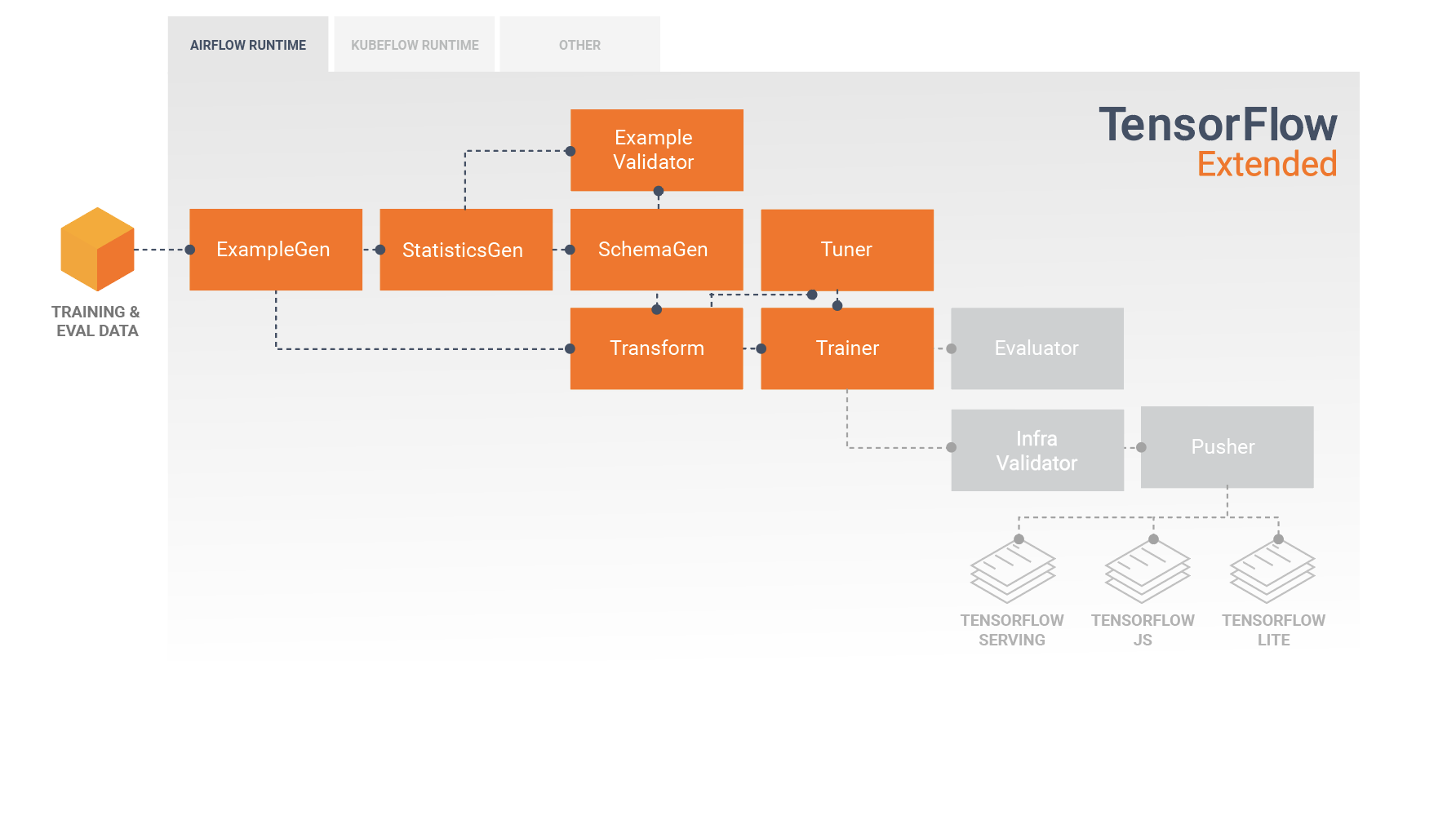
Il risultato di un componente Transform è un SavedModel che verrà importato e utilizzato nel codice di modellazione in TensorFlow, durante un componente Trainer . Questo SavedModel include tutte le trasformazioni di ingegneria dei dati create nel componente Transform, in modo che le trasformazioni identiche vengano eseguite utilizzando esattamente lo stesso codice sia durante l'addestramento che durante l'inferenza. Utilizzando il codice di modellazione, incluso SavedModel dal componente Transform, puoi utilizzare i dati di addestramento e valutazione e addestrare il tuo modello.
Quando lavori con modelli basati su Estimator, l'ultima sezione del codice di modellazione dovrebbe salvare il tuo modello sia come SavedModel che come EvalSavedModel. Il salvataggio come EvalSavedModel garantisce che le metriche utilizzate al momento del training siano disponibili anche durante la valutazione (si noti che ciò non è richiesto per i modelli basati su Keras). Il salvataggio di un EvalSavedModel richiede l'importazione della libreria TensorFlow Model Analysis (TFMA) nel componente Trainer.
import tensorflow_model_analysis as tfma
...
tfma.export.export_eval_savedmodel(
estimator=estimator,
export_dir_base=eval_model_dir,
eval_input_receiver_fn=receiver_fn)
È possibile aggiungere un componente Tuner opzionale prima del Trainer per ottimizzare gli iperparametri (ad esempio, il numero di livelli) per il modello. Con il modello fornito e lo spazio di ricerca degli iperparametri, l'algoritmo di ottimizzazione troverà i migliori iperparametri in base all'obiettivo.
Analisi e comprensione delle prestazioni del modello
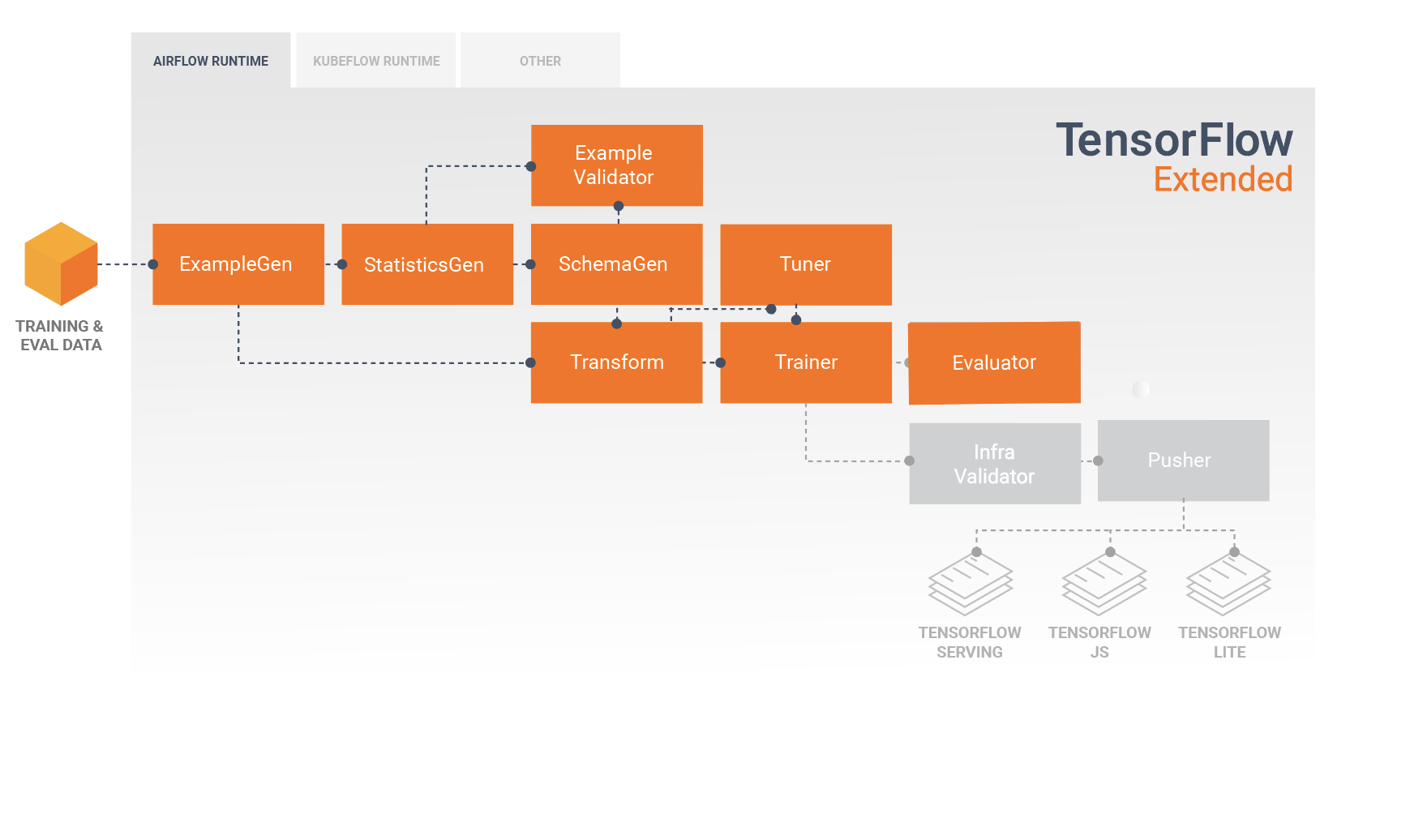
Dopo lo sviluppo e la formazione iniziali del modello, è importante analizzare e comprendere realmente le prestazioni del modello. Una tipica pipeline TFX includerà un componente Evaluator , che sfrutta le funzionalità della libreria TensorFlow Model Analysis (TFMA) , che fornisce un potente set di strumenti per questa fase di sviluppo. Un componente Evaluator utilizza il modello che hai esportato in precedenza e ti consente di specificare un elenco di tfma.SlicingSpec che puoi utilizzare durante la visualizzazione e l'analisi delle prestazioni del modello. Ogni SlicingSpec definisce una sezione dei dati di addestramento che desideri esaminare, ad esempio categorie particolari per caratteristiche categoriche o intervalli particolari per caratteristiche numeriche.
Ad esempio, questo sarebbe importante per provare a comprendere le prestazioni del tuo modello per diversi segmenti di clienti, che potrebbero essere segmentati in base ad acquisti annuali, dati geografici, fascia di età o sesso. Ciò può essere particolarmente importante per i set di dati con code lunghe, dove la performance di un gruppo dominante può mascherare prestazioni inaccettabili per gruppi importanti, ma più piccoli. Ad esempio, il tuo modello potrebbe funzionare bene per i dipendenti medi ma fallire miseramente per il personale dirigente, e potrebbe essere importante per te saperlo.
Analisi e visualizzazione del modello
Dopo aver completato la prima esecuzione dei dati attraverso l'addestramento del modello e l'esecuzione del componente Evaluator (che sfrutta TFMA ) sui risultati dell'addestramento, è possibile visualizzare i risultati in un notebook in stile Jupyter. Per esecuzioni aggiuntive è possibile confrontare questi risultati mentre si apportano modifiche, fino a quando i risultati non saranno ottimali per il modello e l'applicazione.
Per prima cosa eseguirai una query su ML Metadata (MLMD) per individuare i risultati di queste esecuzioni di questi componenti, quindi utilizzerai l'API di supporto della visualizzazione in TFMA per creare le visualizzazioni nel tuo notebook. Ciò include tfma.load_eval_results e tfma.view.render_slicing_metrics Utilizzando questa visualizzazione puoi comprendere meglio le caratteristiche del tuo modello e, se necessario, modificarle come richiesto.
Convalida delle prestazioni del modello
Nell'ambito dell'analisi delle prestazioni di un modello potresti voler convalidare le prestazioni rispetto a una base di riferimento (come il modello attualmente in servizio). La convalida del modello viene eseguita passando sia il modello candidato che quello di base al componente Evaluator . Il Valutatore calcola le metriche (ad esempio AUC, perdita) sia per il candidato che per la baseline insieme a un insieme corrispondente di metriche di differenza. Le soglie possono quindi essere applicate e utilizzate per spingere i modelli alla produzione.
Convalidare che un modello può essere servito
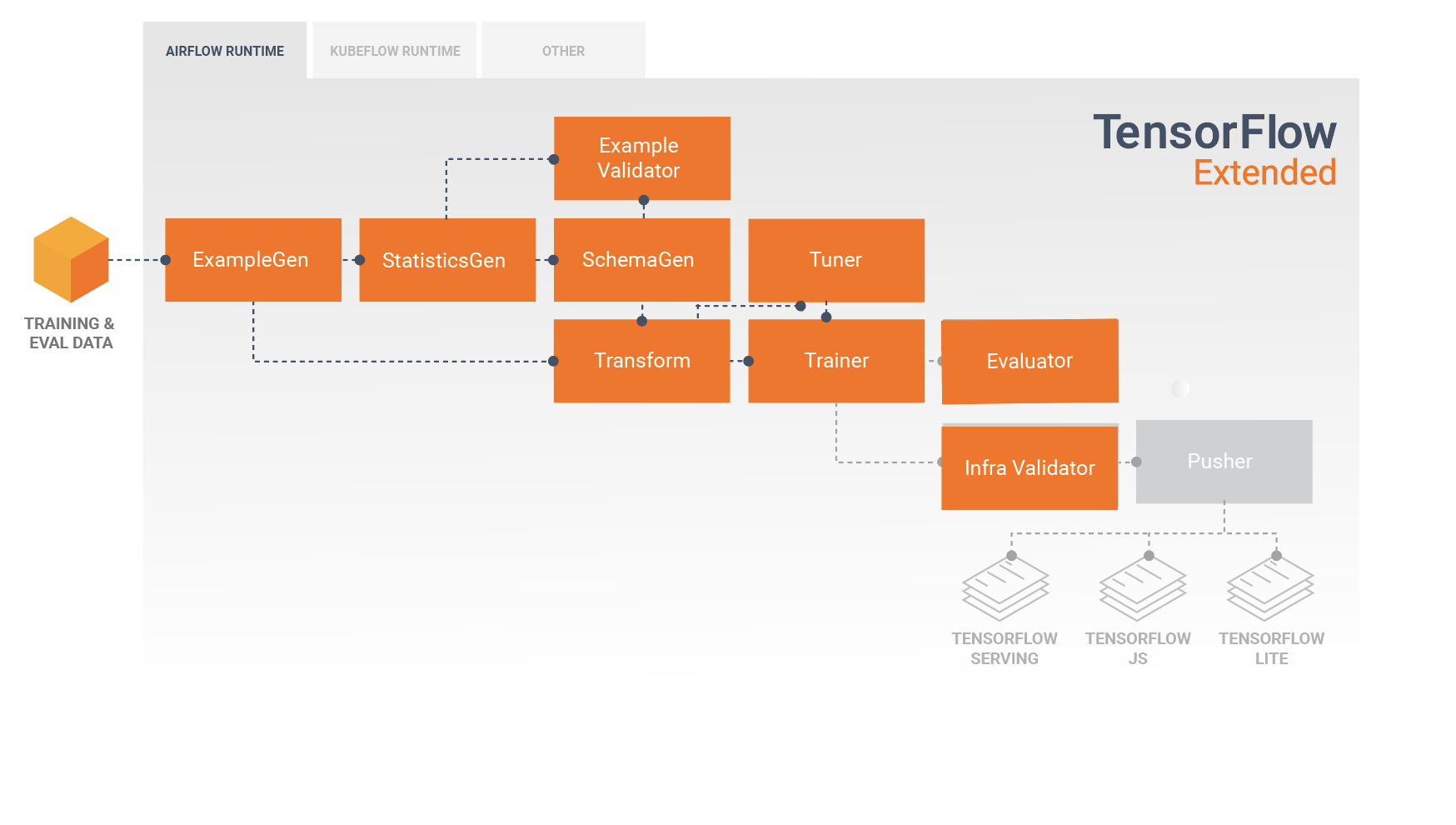
Prima di distribuire il modello addestrato, potresti voler verificare se il modello è realmente utilizzabile nell'infrastruttura di servizio. Ciò è particolarmente importante negli ambienti di produzione per garantire che il modello appena pubblicato non impedisca al sistema di fornire previsioni. Il componente InfraValidator eseguirà una distribuzione canary del tuo modello in un ambiente sandbox e, facoltativamente, invierà richieste reali per verificare che il tuo modello funzioni correttamente.
Obiettivi di distribuzione
Dopo aver sviluppato e addestrato un modello di cui sei soddisfatto, è ora il momento di distribuirlo su uno o più target di distribuzione dove riceverà richieste di inferenza. TFX supporta la distribuzione in tre classi di destinazioni di distribuzione. I modelli addestrati che sono stati esportati come SavedModels possono essere distribuiti a una o tutte queste destinazioni di distribuzione.
Inferenza: servizio TensorFlow
TensorFlow Serving (TFS) è un sistema di servizio flessibile e ad alte prestazioni per modelli di machine learning, progettato per ambienti di produzione. Utilizza un SavedModel e accetterà richieste di inferenza su interfacce REST o gRPC. Funziona come un insieme di processi su uno o più server di rete, utilizzando una delle numerose architetture avanzate per gestire la sincronizzazione e il calcolo distribuito. Consulta la documentazione di TFS per ulteriori informazioni sullo sviluppo e la distribuzione di soluzioni TFS.
In una pipeline tipica, un SavedModel che è stato addestrato in un componente Trainer verrebbe prima infraconvalidato in un componente InfraValidator . InfraValidator avvia un server modello TFS canary per servire effettivamente SavedModel. Se la convalida è stata superata, un componente Pusher distribuirà finalmente SavedModel nella tua infrastruttura TFS. Ciò include la gestione di più versioni e aggiornamenti del modello.
Inferenza in applicazioni mobili e IoT native: TensorFlow Lite
TensorFlow Lite è una suite di strumenti dedicata ad aiutare gli sviluppatori a utilizzare i propri modelli TensorFlow addestrati in applicazioni mobili e IoT native. Utilizza gli stessi SavedModels di TensorFlow Serving e applica ottimizzazioni come la quantizzazione e l'eliminazione per ottimizzare le dimensioni e le prestazioni dei modelli risultanti per le sfide dell'esecuzione su dispositivi mobili e IoT. Consulta la documentazione di TensorFlow Lite per ulteriori informazioni sull'utilizzo di TensorFlow Lite.
Inferenza in JavaScript: TensorFlow JS
TensorFlow JS è una libreria JavaScript per l'addestramento e la distribuzione di modelli ML nel browser e su Node.js. Utilizza gli stessi SavedModels di TensorFlow Serving e TensorFlow Lite e li converte nel formato Web TensorFlow.js. Consulta la documentazione di TensorFlow JS per ulteriori dettagli sull'utilizzo di TensorFlow JS.
Creazione di una pipeline TFX con flusso d'aria
Per i dettagli, consultare l'officina sul flusso d'aria
Creazione di una pipeline TFX con Kubeflow
Impostare
Kubeflow richiede un cluster Kubernetes per eseguire le pipeline su larga scala. Consulta le linee guida di distribuzione Kubeflow che illustrano le opzioni per la distribuzione del cluster Kubeflow.
Configura ed esegui la pipeline TFX
Segui il tutorial sulla pipeline TFX on Cloud AI Platform per eseguire la pipeline di esempio TFX su Kubeflow. I componenti TFX sono stati inseriti in contenitori per comporre la pipeline Kubeflow e l'esempio illustra la capacità di configurare la pipeline per leggere set di dati pubblici di grandi dimensioni ed eseguire passaggi di training ed elaborazione dei dati su larga scala nel cloud.
Interfaccia della riga di comando per le azioni della pipeline
TFX fornisce una CLI unificata che aiuta a eseguire una gamma completa di azioni sulla pipeline come creare, aggiornare, eseguire, elencare ed eliminare pipeline su vari orchestratori tra cui Apache Airflow, Apache Beam e Kubeflow. Per i dettagli, seguire queste istruzioni .