
ML Metadata (MLMD) è una libreria per la registrazione e il recupero dei metadati associati ai flussi di lavoro degli sviluppatori ML e dei data scientist. MLMD è parte integrante di TensorFlow Extended (TFX) , ma è progettato in modo da poter essere utilizzato in modo indipendente.
Ogni esecuzione di una pipeline ML di produzione genera metadati contenenti informazioni sui vari componenti della pipeline, sulle loro esecuzioni (ad esempio esecuzioni di training) e sugli artefatti risultanti (ad esempio modelli addestrati). In caso di comportamenti o errori imprevisti della pipeline, questi metadati possono essere sfruttati per analizzare la derivazione dei componenti della pipeline ed eseguire il debug dei problemi. Pensa a questi metadati come all'equivalente dell'accesso allo sviluppo del software.
MLMD ti aiuta a comprendere e analizzare tutte le parti interconnesse della tua pipeline ML invece di analizzarle isolatamente e può aiutarti a rispondere a domande sulla tua pipeline ML come:
- Su quale set di dati è stato addestrato il modello?
- Quali sono stati gli iperparametri utilizzati per addestrare il modello?
- Quale esecuzione della pipeline ha creato il modello?
- Quale percorso formativo ha portato a questo modello?
- Quale versione di TensorFlow ha creato questo modello?
- Quando è stato inviato il modello fallito?
Archivio di metadati
MLMD registra i seguenti tipi di metadati in un database chiamato Metadata Store .
- Metadati sugli artefatti generati tramite i componenti/passaggi delle pipeline ML
- Metadati sulle esecuzioni di questi componenti/passaggi
- Metadati sulle condutture e informazioni sulla derivazione associata
L'archivio metadati fornisce API per registrare e recuperare metadati da e verso il backend di archiviazione. Il backend di archiviazione è collegabile e può essere esteso. MLMD fornisce implementazioni di riferimento per SQLite (che supporta in memoria e disco) e MySQL pronte all'uso.
Questo grafico mostra una panoramica di alto livello dei vari componenti che fanno parte di MLMD.
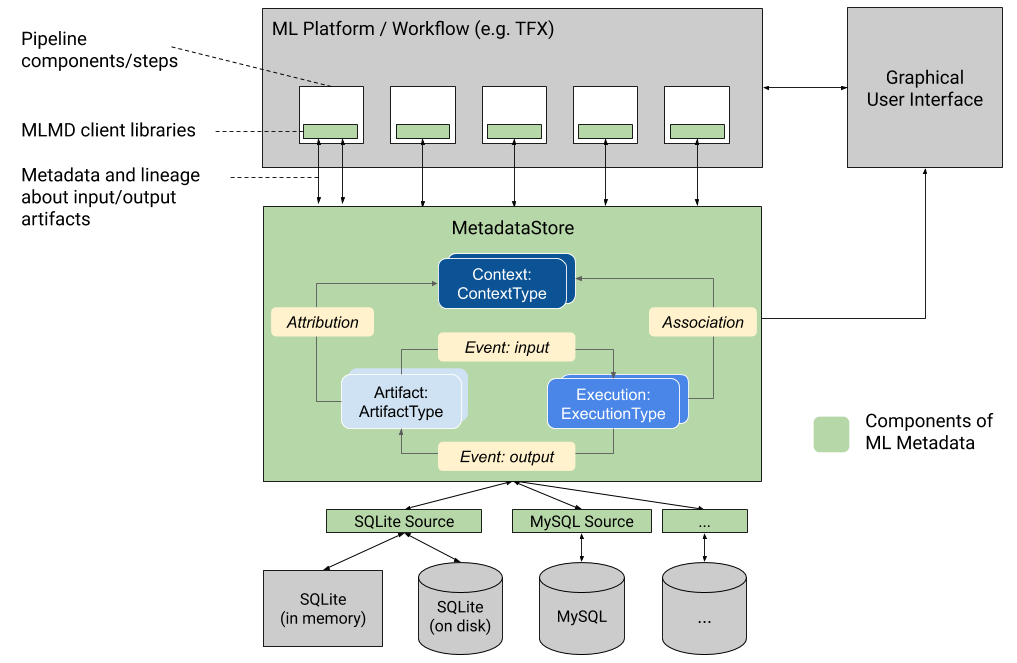
Backend di archiviazione dei metadati e configurazione della connessione dell'archivio
L'oggetto MetadataStore riceve una configurazione di connessione che corrisponde al backend di archiviazione utilizzato.
- Fake Database fornisce un DB in memoria (utilizzando SQLite) per sperimentazioni veloci ed esecuzioni locali. Il database viene eliminato quando l'oggetto dell'archivio viene distrutto.
import ml_metadata as mlmd
from ml_metadata.metadata_store import metadata_store
from ml_metadata.proto import metadata_store_pb2
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.fake_database.SetInParent() # Sets an empty fake database proto.
store = metadata_store.MetadataStore(connection_config)
- SQLite legge e scrive file dal disco.
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.sqlite.filename_uri = '...'
connection_config.sqlite.connection_mode = 3 # READWRITE_OPENCREATE
store = metadata_store.MetadataStore(connection_config)
- MySQL si connette a un server MySQL.
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.mysql.host = '...'
connection_config.mysql.port = '...'
connection_config.mysql.database = '...'
connection_config.mysql.user = '...'
connection_config.mysql.password = '...'
store = metadata_store.MetadataStore(connection_config)
Allo stesso modo, quando si utilizza un'istanza MySQL con Google CloudSQL ( avvio rapido , panoramica della connessione ), è possibile utilizzare anche l'opzione SSL, se applicabile.
connection_config.mysql.ssl_options.key = '...'
connection_config.mysql.ssl_options.cert = '...'
connection_config.mysql.ssl_options.ca = '...'
connection_config.mysql.ssl_options.capath = '...'
connection_config.mysql.ssl_options.cipher = '...'
connection_config.mysql.ssl_options.verify_server_cert = '...'
store = metadata_store.MetadataStore(connection_config)
- PostgreSQL si connette a un server PostgreSQL.
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.postgresql.host = '...'
connection_config.postgresql.port = '...'
connection_config.postgresql.user = '...'
connection_config.postgresql.password = '...'
connection_config.postgresql.dbname = '...'
store = metadata_store.MetadataStore(connection_config)
Allo stesso modo, quando si utilizza un'istanza PostgreSQL con Google CloudSQL ( avvio rapido , panoramica della connessione ), è possibile utilizzare anche l'opzione SSL, se applicabile.
connection_config.postgresql.ssloption.sslmode = '...' # disable, allow, verify-ca, verify-full, etc.
connection_config.postgresql.ssloption.sslcert = '...'
connection_config.postgresql.ssloption.sslkey = '...'
connection_config.postgresql.ssloption.sslpassword = '...'
connection_config.postgresql.ssloption.sslrootcert = '...'
store = metadata_store.MetadataStore(connection_config)
Modello di dati
L'archivio metadati utilizza il seguente modello di dati per registrare e recuperare i metadati dal back-end di archiviazione.
-
ArtifactTypedescrive il tipo di un artefatto e le relative proprietà archiviate nell'archivio dei metadati. È possibile registrare questi tipi al volo con l'archivio dei metadati nel codice oppure caricarli nello store da un formato serializzato. Una volta registrato un tipo, la sua definizione è disponibile per tutta la durata del negozio. - Un
Artifactdescrive un'istanza specifica di unArtifactTypee le sue proprietà scritte nell'archivio dei metadati. - Un
ExecutionTypedescrive un tipo di componente o passaggio in un flusso di lavoro e i relativi parametri di runtime. -
Executionè un record dell'esecuzione di un componente o di un passaggio in un flusso di lavoro ML e dei parametri di runtime. Un'esecuzione può essere considerata come un'istanza diExecutionType. Le esecuzioni vengono registrate quando si esegue una pipeline o un passaggio ML. - Un
Eventè una registrazione della relazione tra artefatti ed esecuzioni. Quando avviene un'esecuzione, gli eventi registrano ogni artefatto utilizzato dall'esecuzione e ogni artefatto prodotto. Questi record consentono il monitoraggio della derivazione durante un flusso di lavoro. Osservando tutti gli eventi, MLMD sa quali esecuzioni sono avvenute e quali artefatti sono stati creati di conseguenza. MLMD può quindi ricorrere da qualsiasi artefatto a tutti i suoi input a monte. - Un
ContextTypedescrive un tipo di gruppo concettuale di artefatti ed esecuzioni in un flusso di lavoro e le relative proprietà strutturali. Ad esempio: progetti, esecuzioni di pipeline, esperimenti, proprietari, ecc. - Un
Contextè un'istanza di unContextType. Cattura le informazioni condivise all'interno del gruppo. Ad esempio: nome del progetto, ID commit dell'elenco modifiche, annotazioni dell'esperimento ecc. Ha un nome univoco definito dall'utente all'interno del suoContextType. -
Attributionè una registrazione della relazione tra artefatti e contesti. -
Associationè una registrazione della relazione tra esecuzioni e contesti.
Funzionalità MLMD
Il monitoraggio degli input e degli output di tutti i componenti/passaggi in un flusso di lavoro ML e la loro derivazione consente alle piattaforme ML di abilitare diverse funzionalità importanti. L'elenco seguente fornisce una panoramica non esaustiva di alcuni dei principali vantaggi.
- Elenca tutti gli artefatti di un tipo specifico. Esempio: tutti i Modelli che sono stati addestrati.
- Carica due artefatti dello stesso tipo per il confronto. Esempio: confrontare i risultati di due esperimenti.
- Mostra un DAG di tutte le esecuzioni correlate e dei relativi artefatti di input e output di un contesto. Esempio: visualizzare il flusso di lavoro di un esperimento per il debug e la scoperta.
- Ripercorri tutti gli eventi per vedere come è stato creato un artefatto. Esempi: vedere quali dati sono stati inseriti in un modello; applicare piani di conservazione dei dati.
- Identificare tutti gli artefatti creati utilizzando un determinato artefatto. Esempi: vedere tutti i modelli addestrati da un set di dati specifico; contrassegnare i modelli basati su dati errati.
- Determina se un'esecuzione è stata eseguita in precedenza sugli stessi input. Esempio: determinare se un componente/passaggio ha già completato lo stesso lavoro e l'output precedente può essere semplicemente riutilizzato.
- Registrare ed eseguire query sul contesto delle esecuzioni del flusso di lavoro. Esempi: tenere traccia del proprietario e dell'elenco modifiche utilizzati per l'esecuzione di un flusso di lavoro; raggruppare il lignaggio mediante esperimenti; gestire gli artefatti per progetti.
- Funzionalità di filtraggio dei nodi dichiarativi su proprietà e nodi di quartiere a 1 hop. Esempi: cercare artefatti di un tipo e in un contesto di pipeline; restituire artefatti digitati in cui il valore di una determinata proprietà rientra in un intervallo; trova esecuzioni precedenti in un contesto con gli stessi input.
Consulta il tutorial MLMD per un esempio che mostra come utilizzare l'API MLMD e l'archivio metadati per recuperare informazioni sulla derivazione.
Integra i metadati ML nei tuoi flussi di lavoro ML
Se sei uno sviluppatore di piattaforme interessato a integrare MLMD nel tuo sistema, utilizza il flusso di lavoro di esempio riportato di seguito per utilizzare le API MLMD di basso livello per monitorare l'esecuzione di un'attività di formazione. Puoi anche utilizzare API Python di livello superiore negli ambienti notebook per registrare i metadati dell'esperimento.
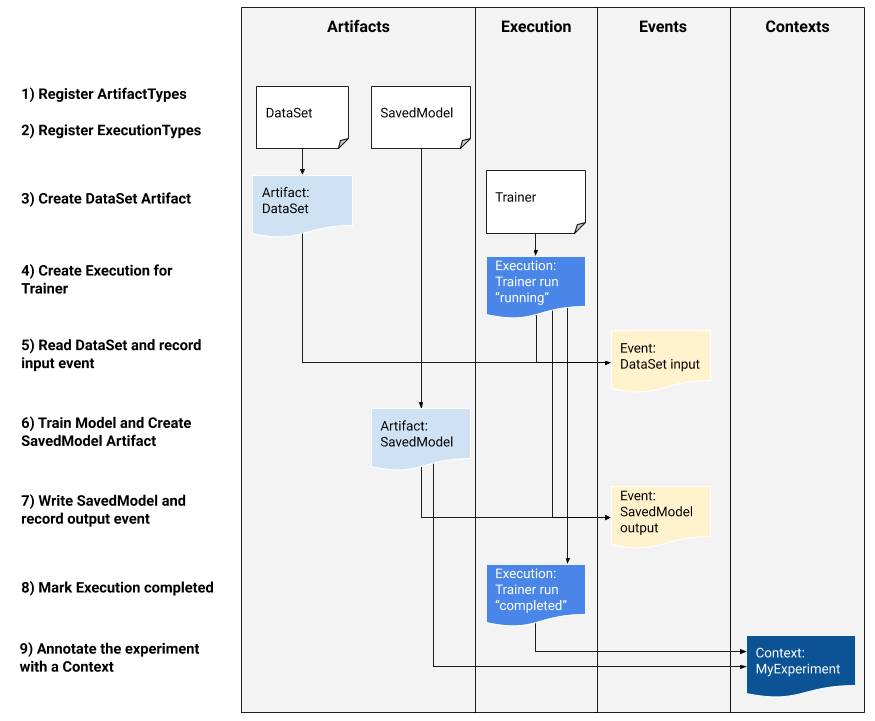
1) Registrare i tipi di artefatto
# Create ArtifactTypes, e.g., Data and Model
data_type = metadata_store_pb2.ArtifactType()
data_type.name = "DataSet"
data_type.properties["day"] = metadata_store_pb2.INT
data_type.properties["split"] = metadata_store_pb2.STRING
data_type_id = store.put_artifact_type(data_type)
model_type = metadata_store_pb2.ArtifactType()
model_type.name = "SavedModel"
model_type.properties["version"] = metadata_store_pb2.INT
model_type.properties["name"] = metadata_store_pb2.STRING
model_type_id = store.put_artifact_type(model_type)
# Query all registered Artifact types.
artifact_types = store.get_artifact_types()
2) Registrare i tipi di esecuzione per tutti i passaggi del flusso di lavoro ML
# Create an ExecutionType, e.g., Trainer
trainer_type = metadata_store_pb2.ExecutionType()
trainer_type.name = "Trainer"
trainer_type.properties["state"] = metadata_store_pb2.STRING
trainer_type_id = store.put_execution_type(trainer_type)
# Query a registered Execution type with the returned id
[registered_type] = store.get_execution_types_by_id([trainer_type_id])
3) Creare un artefatto di DataSet ArtifactType
# Create an input artifact of type DataSet
data_artifact = metadata_store_pb2.Artifact()
data_artifact.uri = 'path/to/data'
data_artifact.properties["day"].int_value = 1
data_artifact.properties["split"].string_value = 'train'
data_artifact.type_id = data_type_id
[data_artifact_id] = store.put_artifacts([data_artifact])
# Query all registered Artifacts
artifacts = store.get_artifacts()
# Plus, there are many ways to query the same Artifact
[stored_data_artifact] = store.get_artifacts_by_id([data_artifact_id])
artifacts_with_uri = store.get_artifacts_by_uri(data_artifact.uri)
artifacts_with_conditions = store.get_artifacts(
list_options=mlmd.ListOptions(
filter_query='uri LIKE "%/data" AND properties.day.int_value > 0'))
4) Creare un'esecuzione della corsa del Trainer
# Register the Execution of a Trainer run
trainer_run = metadata_store_pb2.Execution()
trainer_run.type_id = trainer_type_id
trainer_run.properties["state"].string_value = "RUNNING"
[run_id] = store.put_executions([trainer_run])
# Query all registered Execution
executions = store.get_executions_by_id([run_id])
# Similarly, the same execution can be queried with conditions.
executions_with_conditions = store.get_executions(
list_options = mlmd.ListOptions(
filter_query='type = "Trainer" AND properties.state.string_value IS NOT NULL'))
5) Definire l'evento di input e leggere i dati
# Define the input event
input_event = metadata_store_pb2.Event()
input_event.artifact_id = data_artifact_id
input_event.execution_id = run_id
input_event.type = metadata_store_pb2.Event.DECLARED_INPUT
# Record the input event in the metadata store
store.put_events([input_event])
6) Dichiarare l'artefatto di output
# Declare the output artifact of type SavedModel
model_artifact = metadata_store_pb2.Artifact()
model_artifact.uri = 'path/to/model/file'
model_artifact.properties["version"].int_value = 1
model_artifact.properties["name"].string_value = 'MNIST-v1'
model_artifact.type_id = model_type_id
[model_artifact_id] = store.put_artifacts([model_artifact])
7) Registrare l'evento di uscita
# Declare the output event
output_event = metadata_store_pb2.Event()
output_event.artifact_id = model_artifact_id
output_event.execution_id = run_id
output_event.type = metadata_store_pb2.Event.DECLARED_OUTPUT
# Submit output event to the Metadata Store
store.put_events([output_event])
8) Contrassegnare l'esecuzione come completata
trainer_run.id = run_id
trainer_run.properties["state"].string_value = "COMPLETED"
store.put_executions([trainer_run])
9) Raggruppare artefatti ed esecuzioni in un contesto utilizzando artefatti di attribuzioni e asserzioni
# Create a ContextType, e.g., Experiment with a note property
experiment_type = metadata_store_pb2.ContextType()
experiment_type.name = "Experiment"
experiment_type.properties["note"] = metadata_store_pb2.STRING
experiment_type_id = store.put_context_type(experiment_type)
# Group the model and the trainer run to an experiment.
my_experiment = metadata_store_pb2.Context()
my_experiment.type_id = experiment_type_id
# Give the experiment a name
my_experiment.name = "exp1"
my_experiment.properties["note"].string_value = "My first experiment."
[experiment_id] = store.put_contexts([my_experiment])
attribution = metadata_store_pb2.Attribution()
attribution.artifact_id = model_artifact_id
attribution.context_id = experiment_id
association = metadata_store_pb2.Association()
association.execution_id = run_id
association.context_id = experiment_id
store.put_attributions_and_associations([attribution], [association])
# Query the Artifacts and Executions that are linked to the Context.
experiment_artifacts = store.get_artifacts_by_context(experiment_id)
experiment_executions = store.get_executions_by_context(experiment_id)
# You can also use neighborhood queries to fetch these artifacts and executions
# with conditions.
experiment_artifacts_with_conditions = store.get_artifacts(
list_options = mlmd.ListOptions(
filter_query=('contexts_a.type = "Experiment" AND contexts_a.name = "exp1"')))
experiment_executions_with_conditions = store.get_executions(
list_options = mlmd.ListOptions(
filter_query=('contexts_a.id = {}'.format(experiment_id))))
Utilizza MLMD con un server gRPC remoto
Puoi utilizzare MLMD con server gRPC remoti come mostrato di seguito:
- Avvia un server
bazel run -c opt --define grpc_no_ares=true //ml_metadata/metadata_store:metadata_store_server
Per impostazione predefinita, il server utilizza un falso database in memoria per richiesta e non mantiene i metadati tra le chiamate. Può anche essere configurato con MLMD MetadataStoreServerConfig per utilizzare file SQLite o istanze MySQL. La configurazione può essere archiviata in un file protobuf di testo e passata al binario con --metadata_store_server_config_file=path_to_the_config_file .
Un esempio di file MetadataStoreServerConfig in formato protobuf di testo:
connection_config {
sqlite {
filename_uri: '/tmp/test_db'
connection_mode: READWRITE_OPENCREATE
}
}
- Crea lo stub del client e usalo in Python
from grpc import insecure_channel
from ml_metadata.proto import metadata_store_pb2
from ml_metadata.proto import metadata_store_service_pb2
from ml_metadata.proto import metadata_store_service_pb2_grpc
channel = insecure_channel('localhost:8080')
stub = metadata_store_service_pb2_grpc.MetadataStoreServiceStub(channel)
- Utilizza MLMD con le chiamate RPC
# Create ArtifactTypes, e.g., Data and Model
data_type = metadata_store_pb2.ArtifactType()
data_type.name = "DataSet"
data_type.properties["day"] = metadata_store_pb2.INT
data_type.properties["split"] = metadata_store_pb2.STRING
request = metadata_store_service_pb2.PutArtifactTypeRequest()
request.all_fields_match = True
request.artifact_type.CopyFrom(data_type)
stub.PutArtifactType(request)
model_type = metadata_store_pb2.ArtifactType()
model_type.name = "SavedModel"
model_type.properties["version"] = metadata_store_pb2.INT
model_type.properties["name"] = metadata_store_pb2.STRING
request.artifact_type.CopyFrom(model_type)
stub.PutArtifactType(request)
Risorse
La libreria MLMD dispone di un'API di alto livello che puoi utilizzare facilmente con le tue pipeline ML. Consulta la documentazione dell'API MLMD per ulteriori dettagli.
Scopri Filtraggio dei nodi dichiarativi MLMD per scoprire come utilizzare le funzionalità di filtro dei nodi dichiarativi MLMD sulle proprietà e sui nodi di quartiere a 1 hop.
Consulta anche il tutorial MLMD per scoprire come utilizzare MLMD per tracciare la discendenza dei componenti della pipeline.
MLMD fornisce utilità per gestire le migrazioni di schemi e dati tra le versioni. Consulta la Guida MLMD per maggiori dettagli.