
TensorFlow Extended의 핵심 구성 요소의 예
 GitHub에서 소스 보기
GitHub에서 소스 보기이 예제 colab 노트북은 TFDV(TensorFlow Data Validation)를 사용하여 데이터세트를 조사하고 시각화하는 방법을 보여줍니다. 여기에는 기술 통계 보기, 스키마 추론, 비정상 검사 및 수정, 데이터 세트의 드리프트 및 왜곡 검사가 포함됩니다. 프로덕션 파이프라인에서 시간이 지남에 따라 어떻게 변경될 수 있는지를 포함하여 데이터 세트의 특성을 이해하는 것이 중요합니다. 데이터에서 이상을 찾고 훈련, 평가 및 제공 데이터 세트를 비교하여 일관성이 있는지 확인하는 것도 중요합니다.
시카고 시에서 발표한 Taxi Trips 데이터 세트 의 데이터를 사용합니다.
Google BigQuery 의 데이터세트에 대해 자세히 알아보세요. BigQuery UI 에서 전체 데이터세트를 살펴보세요.
데이터세트의 열은 다음과 같습니다.
| 픽업_커뮤니티_영역 | 요금 | trip_start_month |
| trip_start_hour | trip_start_day | trip_start_timestamp |
| 픽업 위도 | 픽업_경도 | dropoff_latitude |
| dropoff_longitude | trip_miles | 픽업_센서스_트랙 |
| dropoff_census_tract | 지불 유형 | 회사 |
| trip_seconds | dropoff_community_area | 팁 |
패키지 설치 및 가져오기
TensorFlow 데이터 유효성 검사용 패키지를 설치합니다.
핍 업그레이드
로컬에서 실행할 때 시스템에서 Pip를 업그레이드하지 않으려면 Colab에서 실행 중인지 확인하세요. 물론 로컬 시스템은 별도로 업그레이드할 수 있습니다.
try:
import colab
!pip install --upgrade pip
except:
pass
데이터 유효성 검사 패키지 설치
TensorFlow Data Validation 패키지 및 종속 항목을 설치하는 데 몇 분 정도 걸립니다. 다음 섹션에서 해결할 호환되지 않는 종속성 버전에 대한 경고 및 오류가 표시될 수 있습니다.
print('Installing TensorFlow Data Validation')
!pip install --upgrade 'tensorflow_data_validation[visualization]<2'
TensorFlow 가져오기 및 업데이트된 패키지 다시 로드
이전 단계에서는 Gooogle Colab 환경의 기본 패키지를 업데이트하므로 패키지 리소스를 다시 로드하여 새 종속성을 해결해야 합니다.
import pkg_resources
import importlib
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
계속하기 전에 TensorFlow 버전과 데이터 유효성 검사를 확인하세요.
import tensorflow as tf
import tensorflow_data_validation as tfdv
print('TF version:', tf.__version__)
print('TFDV version:', tfdv.version.__version__)
TF version: 2.7.0 TFDV version: 1.5.0
데이터세트 로드
Google Cloud Storage에서 데이터세트를 다운로드합니다.
import os
import tempfile, urllib, zipfile
# Set up some globals for our file paths
BASE_DIR = tempfile.mkdtemp()
DATA_DIR = os.path.join(BASE_DIR, 'data')
OUTPUT_DIR = os.path.join(BASE_DIR, 'chicago_taxi_output')
TRAIN_DATA = os.path.join(DATA_DIR, 'train', 'data.csv')
EVAL_DATA = os.path.join(DATA_DIR, 'eval', 'data.csv')
SERVING_DATA = os.path.join(DATA_DIR, 'serving', 'data.csv')
# Download the zip file from GCP and unzip it
zip, headers = urllib.request.urlretrieve('https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/chicago_data.zip')
zipfile.ZipFile(zip).extractall(BASE_DIR)
zipfile.ZipFile(zip).close()
print("Here's what we downloaded:")
!ls -R {os.path.join(BASE_DIR, 'data')}
Here's what we downloaded: /tmp/tmp_waiqx43/data: eval serving train /tmp/tmp_waiqx43/data/eval: data.csv /tmp/tmp_waiqx43/data/serving: data.csv /tmp/tmp_waiqx43/data/train: data.csv
통계 계산 및 시각화
먼저 tfdv.generate_statistics_from_csv 를 사용하여 훈련 데이터에 대한 통계를 계산합니다. (빠른 경고 무시)
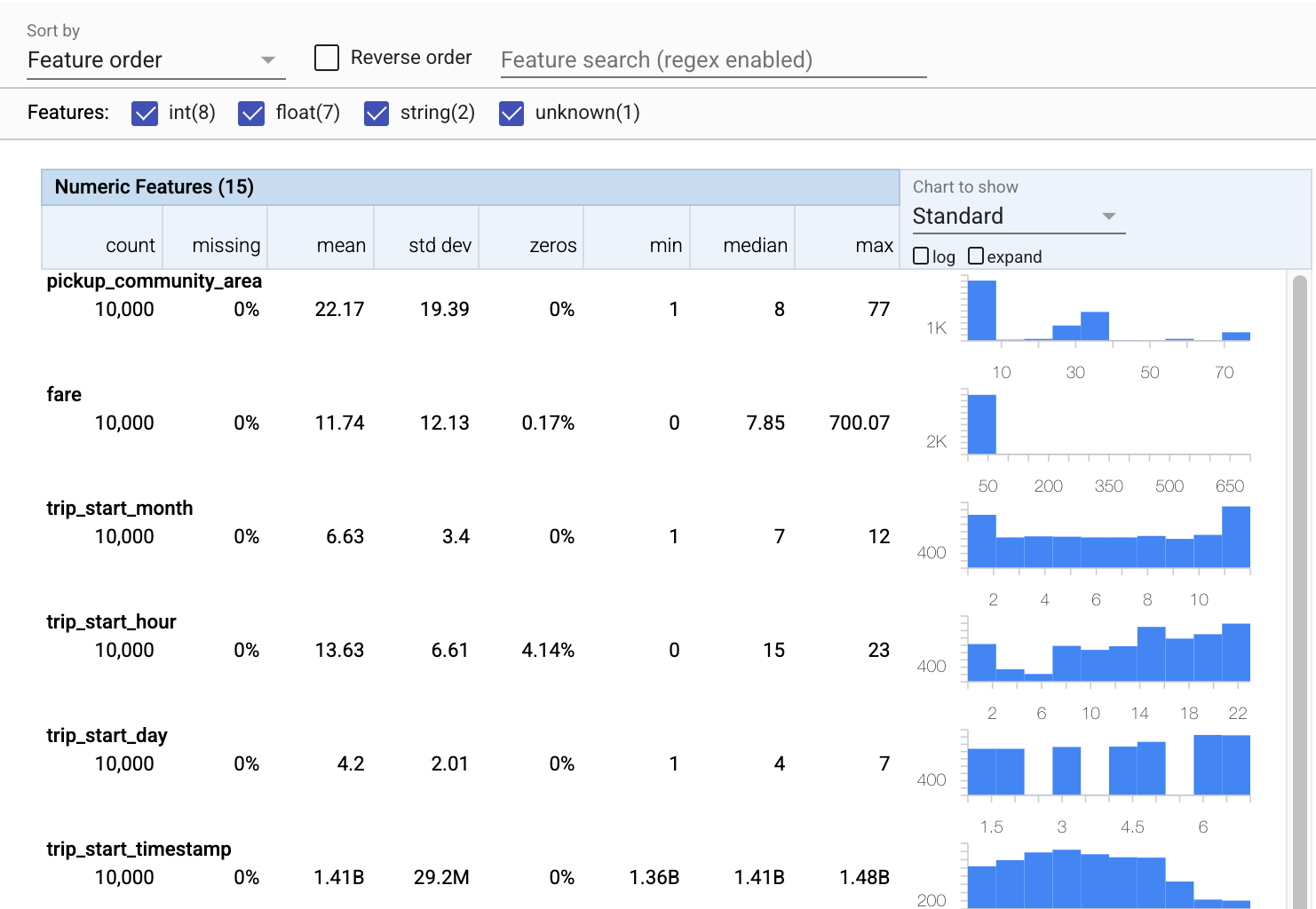
TFDV는 존재하는 기능과 가치 분포의 형태 측면에서 데이터에 대한 빠른 개요를 제공하는 기술 통계 를 계산할 수 있습니다.
내부적으로 TFDV는 Apache Beam 의 데이터 병렬 처리 프레임워크를 사용하여 대규모 데이터 세트에 대한 통계 계산을 확장합니다. TFDV와 더 깊이 통합하려는 애플리케이션(예: 데이터 생성 파이프라인 끝에 통계 생성 첨부)을 위해 API는 통계 생성을 위한 Beam PTransform도 노출합니다.
train_stats = tfdv.generate_statistics_from_csv(data_location=TRAIN_DATA)
WARNING:apache_beam.runners.interactive.interactive_environment:Dependencies required for Interactive Beam PCollection visualization are not available, please use: `pip install apache-beam[interactive]` to install necessary dependencies to enable all data visualization features. WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter. WARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)` WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)`
이제 패싯 을 사용하여 훈련 데이터의 간결한 시각화를 만드는 tfdv.visualize_statistics 를 사용하겠습니다.
- 숫자 기능과 범주형 기능은 별도로 시각화되며 각 기능에 대한 분포를 보여주는 차트가 표시됩니다.
- 값이 누락되거나 0인 기능은 해당 기능의 예에 문제가 있을 수 있음을 시각적 표시기로 빨간색으로 백분율을 표시합니다. 백분율은 해당 기능에 대한 값이 없거나 0인 예제의 백분율입니다.
-
pickup_census_tract에 대한 값이 있는 예가 없습니다. 차원 축소의 기회입니다! - 차트 위의 "확장"을 클릭하여 표시를 변경해 보세요.
- 버킷 범위 및 개수를 표시하려면 차트의 막대 위로 마우스를 가져갑니다.
- 로그 척도와 선형 척도 간 전환을 시도하고 로그 척도가
payment_type범주형 기능에 대해 훨씬 더 자세한 정보를 표시하는 방법을 확인하십시오. - "표시할 차트" 메뉴에서 "분위수"를 선택하고 마커 위로 마우스를 가져가면 분위수 백분율이 표시됩니다.
# docs-infra: no-execute
tfdv.visualize_statistics(train_stats)
스키마 추론
이제 tfdv.infer_schema 를 사용하여 데이터에 대한 스키마를 생성해 보겠습니다. 스키마는 ML과 관련된 데이터에 대한 제약 조건을 정의합니다. 제약 조건의 예로는 수치적이든 범주적이든 각 기능의 데이터 유형 또는 데이터에 존재하는 빈도가 있습니다. 범주형 기능의 경우 스키마는 허용 가능한 값 목록인 도메인도 정의합니다. 스키마 작성은 특히 기능이 많은 데이터 세트의 경우 지루한 작업이 될 수 있으므로 TFDV는 기술 통계를 기반으로 스키마의 초기 버전을 생성하는 방법을 제공합니다.
나머지 프로덕션 파이프라인은 TFDV가 생성하는 스키마가 정확하기 때문에 올바른 스키마를 얻는 것이 중요합니다. 스키마는 데이터에 대한 문서도 제공하므로 여러 개발자가 동일한 데이터에 대해 작업할 때 유용합니다. 검토할 수 있도록 tfdv.display_schema 를 사용하여 추론된 스키마를 표시해 보겠습니다.
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
평가 데이터 오류 확인
지금까지는 훈련 데이터만 살펴보았습니다. 동일한 스키마를 사용하는 것을 포함하여 평가 데이터가 교육 데이터와 일치하는 것이 중요합니다. 평가 데이터에 훈련 데이터와 대략적으로 동일한 수치적 특성 값 범위의 예가 포함되어 평가 중 손실 표면의 적용 범위가 훈련 중과 거의 동일하도록 하는 것도 중요합니다. 범주형 기능도 마찬가지입니다. 그렇지 않으면 손실 표면의 일부를 평가하지 않았기 때문에 평가 중에 식별되지 않은 교육 문제가 있을 수 있습니다.
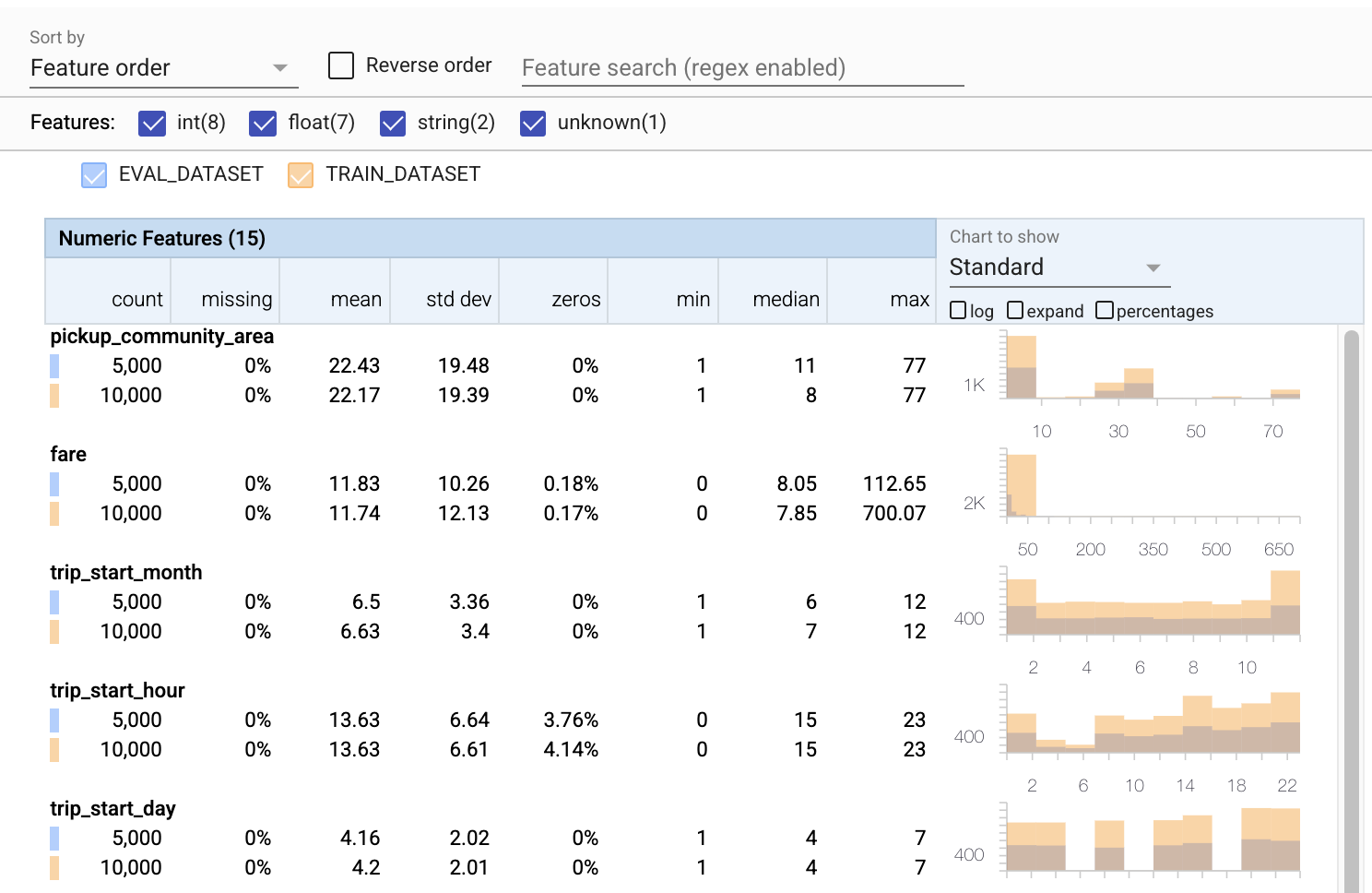
- 이제 각 기능에는 훈련 및 평가 데이터 세트에 대한 통계가 포함됩니다.
- 이제 차트에 학습 데이터 세트와 평가 데이터 세트가 모두 오버레이되어 있어 쉽게 비교할 수 있습니다.
- 이제 차트에 백분율 보기가 포함되어 로그 또는 기본 선형 척도와 결합할 수 있습니다.
-
trip_miles의 평균과 중앙값은 교육 데이터 세트와 평가 데이터 세트에서 다릅니다. 문제가 발생합니까? - 와우, 최대
tips은 훈련과 평가 데이터 세트에 대해 매우 다릅니다. 문제가 발생합니까? - 숫자 기능 차트에서 확장을 클릭하고 로그 척도를 선택합니다.
trip_seconds기능을 검토하고 최대값의 차이를 확인합니다. 평가가 손실 표면의 일부를 놓칠까요?
# Compute stats for evaluation data
eval_stats = tfdv.generate_statistics_from_csv(data_location=EVAL_DATA)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
# docs-infra: no-execute
# Compare evaluation data with training data
tfdv.visualize_statistics(lhs_statistics=eval_stats, rhs_statistics=train_stats,
lhs_name='EVAL_DATASET', rhs_name='TRAIN_DATASET')
평가 이상 여부 확인
평가 데이터 세트가 교육 데이터 세트의 스키마와 일치합니까? 이는 허용 가능한 값의 범위를 식별하려는 범주형 기능에 특히 중요합니다.
# Check eval data for errors by validating the eval data stats using the previously inferred schema.
anomalies = tfdv.validate_statistics(statistics=eval_stats, schema=schema)
tfdv.display_anomalies(anomalies)
스키마의 평가 이상 수정
앗! 평가 데이터에는 교육 데이터에 없는 company 에 대한 새로운 가치가 있는 것 같습니다. 또한 payment_type 에 대한 새 값이 있습니다. 이는 변칙으로 간주되어야 하지만 이에 대해 결정하는 것은 데이터에 대한 도메인 지식에 따라 다릅니다. 이상이 실제로 데이터 오류를 나타내는 경우 기본 데이터를 수정해야 합니다. 그렇지 않으면 평가 데이터 세트에 값을 포함하도록 스키마를 간단히 업데이트할 수 있습니다.
평가 데이터 세트를 변경하지 않는 한 모든 것을 고칠 수는 없지만 스키마에서 우리가 편안하게 수용할 수 있는 것은 고칠 수 있습니다. 여기에는 특정 기능의 이상 여부에 대한 관점을 완화하고 범주형 기능에 대한 결측값을 포함하도록 스키마를 업데이트하는 것이 포함됩니다. TFDV를 통해 수정해야 할 사항을 찾을 수 있었습니다.
지금 수정한 다음 다시 한 번 검토해 보겠습니다.
# Relax the minimum fraction of values that must come from the domain for feature company.
company = tfdv.get_feature(schema, 'company')
company.distribution_constraints.min_domain_mass = 0.9
# Add new value to the domain of feature payment_type.
payment_type_domain = tfdv.get_domain(schema, 'payment_type')
payment_type_domain.value.append('Prcard')
# Validate eval stats after updating the schema
updated_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(updated_anomalies)
야, 그거 봐! 이제 훈련 및 평가 데이터가 일치함을 확인했습니다! 감사합니다 TFDV ;)
스키마 환경
또한 이 예에서는 '서빙' 데이터세트를 분리했으므로 이것도 확인해야 합니다. 기본적으로 파이프라인의 모든 데이터 세트는 동일한 스키마를 사용해야 하지만 종종 예외가 있습니다. 예를 들어 지도 학습에서는 데이터 세트에 레이블을 포함해야 하지만 추론을 위해 모델을 제공할 때 레이블은 포함되지 않습니다. 어떤 경우에는 약간의 스키마 변형을 도입해야 합니다.
환경 은 이러한 요구 사항을 표현하는 데 사용할 수 있습니다. 특히 schema의 기능은 default_environment , in_environment 및 not_in_environment 를 사용하여 환경 세트와 연관될 수 있습니다.
예를 들어, 이 데이터세트에서 tips 기능은 교육용 레이블로 포함되지만 제공 데이터에는 없습니다. 환경을 지정하지 않으면 이상으로 표시됩니다.
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
아래에서 tips 기능을 다룰 것입니다. 또한 스키마가 FLOAT를 예상한 여행 초에 INT 값이 있습니다. TFDV는 그 차이를 인식함으로써 교육 및 제공을 위해 데이터가 생성되는 방식의 불일치를 발견하는 데 도움이 됩니다. 모델 성능이 저하되거나 때로는 치명적일 때까지 그러한 문제를 인식하지 못하는 것은 매우 쉽습니다. 중요한 문제일 수도 있고 아닐 수도 있지만 어쨌든 이것은 추가 조사의 원인이 되어야 합니다.
이 경우 INT 값을 FLOAT로 안전하게 변환할 수 있으므로 TFDV가 스키마를 사용하여 유형을 유추하도록 지시합니다. 이제 해보자.
options = tfdv.StatsOptions(schema=schema, infer_type_from_schema=True)
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA, stats_options=options)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
이제 tips 기능(레이블)이 이상('열 삭제됨')으로 표시됩니다. 물론 우리는 서빙 데이터에 레이블이 있을 것으로 기대하지 않으므로 TFDV가 이를 무시하도록 합시다.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
tfdv.display_anomalies(serving_anomalies_with_env)
드리프트 및 스큐 확인
데이터 세트가 스키마에 설정된 기대치를 준수하는지 확인하는 것 외에도 TFDV는 드리프트 및 스큐를 감지하는 기능도 제공합니다. TFDV는 스키마에 지정된 드리프트/스큐 비교기를 기반으로 다양한 데이터 세트의 통계를 비교하여 이 검사를 수행합니다.
경향
드리프트 감지는 범주형 기능에 대해 지원되며 데이터의 연속 범위(즉, 범위 N과 범위 N+1 사이)(예: 다른 훈련 데이터 날짜 사이)입니다. 드리프트를 L-무한대 거리로 표현하며 드리프트가 허용 가능한 것보다 높을 때 경고를 받도록 임계값 거리를 설정할 수 있습니다. 정확한 거리를 설정하는 것은 일반적으로 영역 지식과 실험이 필요한 반복적인 프로세스입니다.
비스듬한
TFDV는 스키마 스큐, 기능 스큐 및 분포 스큐의 세 가지 데이터 스큐를 감지할 수 있습니다.
스키마 스큐
스키마 스큐는 훈련 데이터와 제공 데이터가 동일한 스키마를 따르지 않을 때 발생합니다. 학습 데이터와 제공 데이터는 모두 동일한 스키마를 준수해야 합니다. 둘 사이의 예상되는 편차(예: 레이블 기능은 학습 데이터에만 있고 제공에는 존재하지 않음)는 스키마의 환경 필드를 통해 지정해야 합니다.
특징 왜곡
특성 왜곡은 모델이 학습하는 특성 값이 제공 시 표시되는 특성 값과 다를 때 발생합니다. 예를 들어 다음과 같은 경우에 발생할 수 있습니다.
- 일부 특성 값을 제공하는 데이터 소스는 학습 및 제공 시간 사이에 수정됩니다.
- 학습과 제공 간에 기능을 생성하는 논리가 다릅니다. 예를 들어 두 코드 경로 중 하나에만 일부 변환을 적용하는 경우입니다.
분포 스큐
분포 스큐는 훈련 데이터 세트의 분포가 제공 데이터 세트의 분포와 크게 다를 때 발생합니다. 분포 스큐의 주요 원인 중 하나는 다른 코드 또는 다른 데이터 소스를 사용하여 훈련 데이터 세트를 생성하는 것입니다. 또 다른 이유는 훈련할 제공 데이터의 비대표적인 하위 샘플을 선택하는 잘못된 샘플링 메커니즘입니다.
# Add skew comparator for 'payment_type' feature.
payment_type = tfdv.get_feature(schema, 'payment_type')
payment_type.skew_comparator.infinity_norm.threshold = 0.01
# Add drift comparator for 'company' feature.
company=tfdv.get_feature(schema, 'company')
company.drift_comparator.infinity_norm.threshold = 0.001
skew_anomalies = tfdv.validate_statistics(train_stats, schema,
previous_statistics=eval_stats,
serving_statistics=serving_stats)
tfdv.display_anomalies(skew_anomalies)
이 예에서 약간의 드리프트를 볼 수 있지만 이는 우리가 설정한 임계값보다 훨씬 낮습니다.
스키마 고정
스키마가 검토되고 선별되었으므로 "고정" 상태를 반영하기 위해 파일에 저장합니다.
from tensorflow.python.lib.io import file_io
from google.protobuf import text_format
file_io.recursive_create_dir(OUTPUT_DIR)
schema_file = os.path.join(OUTPUT_DIR, 'schema.pbtxt')
tfdv.write_schema_text(schema, schema_file)
!cat {schema_file}
feature {
name: "pickup_community_area"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "fare"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_month"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_hour"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_day"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_timestamp"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_latitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_longitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_latitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "dropoff_longitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "trip_miles"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_census_tract"
type: BYTES
presence {
min_count: 0
}
}
feature {
name: "dropoff_census_tract"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "payment_type"
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
skew_comparator {
infinity_norm {
threshold: 0.01
}
}
shape {
dim {
size: 1
}
}
}
feature {
name: "company"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "company"
presence {
min_count: 1
}
distribution_constraints {
min_domain_mass: 0.9
}
drift_comparator {
infinity_norm {
threshold: 0.001
}
}
}
feature {
name: "trip_seconds"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_community_area"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "tips"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
not_in_environment: "SERVING"
shape {
dim {
size: 1
}
}
}
string_domain {
name: "payment_type"
value: "Cash"
value: "Credit Card"
value: "Dispute"
value: "No Charge"
value: "Pcard"
value: "Unknown"
value: "Prcard"
}
string_domain {
name: "company"
value: "0118 - 42111 Godfrey S.Awir"
value: "0694 - 59280 Chinesco Trans Inc"
value: "1085 - 72312 N and W Cab Co"
value: "2733 - 74600 Benny Jona"
value: "2809 - 95474 C & D Cab Co Inc."
value: "3011 - 66308 JBL Cab Inc."
value: "3152 - 97284 Crystal Abernathy"
value: "3201 - C&D Cab Co Inc"
value: "3201 - CID Cab Co Inc"
value: "3253 - 91138 Gaither Cab Co."
value: "3385 - 23210 Eman Cab"
value: "3623 - 72222 Arrington Enterprises"
value: "3897 - Ilie Malec"
value: "4053 - Adwar H. Nikola"
value: "4197 - 41842 Royal Star"
value: "4615 - 83503 Tyrone Henderson"
value: "4615 - Tyrone Henderson"
value: "4623 - Jay Kim"
value: "5006 - 39261 Salifu Bawa"
value: "5006 - Salifu Bawa"
value: "5074 - 54002 Ahzmi Inc"
value: "5074 - Ahzmi Inc"
value: "5129 - 87128"
value: "5129 - 98755 Mengisti Taxi"
value: "5129 - Mengisti Taxi"
value: "5724 - KYVI Cab Inc"
value: "585 - Valley Cab Co"
value: "5864 - 73614 Thomas Owusu"
value: "5864 - Thomas Owusu"
value: "5874 - 73628 Sergey Cab Corp."
value: "5997 - 65283 AW Services Inc."
value: "5997 - AW Services Inc."
value: "6488 - 83287 Zuha Taxi"
value: "6743 - Luhak Corp"
value: "Blue Ribbon Taxi Association Inc."
value: "C & D Cab Co Inc"
value: "Chicago Elite Cab Corp."
value: "Chicago Elite Cab Corp. (Chicago Carriag"
value: "Chicago Medallion Leasing INC"
value: "Chicago Medallion Management"
value: "Choice Taxi Association"
value: "Dispatch Taxi Affiliation"
value: "KOAM Taxi Association"
value: "Northwest Management LLC"
value: "Taxi Affiliation Services"
value: "Top Cab Affiliation"
}
default_environment: "TRAINING"
default_environment: "SERVING"
TFDV를 사용하는 경우
TFDV는 여기에서와 같이 교육 파이프라인의 시작 부분에만 적용되는 것으로 생각하기 쉽지만 실제로는 많은 용도가 있습니다. 다음은 몇 가지 더 있습니다.
- 갑자기 나쁜 기능을 받기 시작하지 않았는지 확인하기 위해 추론을 위해 새 데이터의 유효성을 검사합니다.
- 모델이 결정 표면의 일부에서 훈련되었는지 확인하기 위해 추론을 위해 새 데이터를 검증합니다.
- 데이터를 변환하고 기능 엔지니어링( TensorFlow Transform 사용)을 수행한 후 데이터 유효성 검사를 수행하여 잘못된 작업을 수행하지 않았는지 확인합니다.