
यह ट्यूटोरियल आपको दिखाता है कि मशीन लर्निंग (एमएल) के लिए डेटा प्रीप्रोसेसिंग को लागू करने के लिए टेन्सरफ्लो ट्रांसफॉर्म ( tf.Transform लाइब्रेरी) का उपयोग कैसे करें। TensorFlow के लिए tf.Transform लाइब्रेरी आपको डेटा प्रीप्रोसेसिंग पाइपलाइनों के माध्यम से इंस्टेंस-स्तर और पूर्ण-पास डेटा परिवर्तनों दोनों को परिभाषित करने देती है। इन पाइपलाइनों को अपाचे बीम के साथ कुशलतापूर्वक निष्पादित किया जाता है और वे भविष्यवाणी के दौरान समान परिवर्तनों को लागू करने के लिए उप-उत्पादों के रूप में एक टेन्सरफ्लो ग्राफ बनाते हैं जब मॉडल परोसा जाता है।
यह ट्यूटोरियल अपाचे बीम के लिए रनर के रूप में डेटाफ़्लो का उपयोग करके एक एंड-टू-एंड उदाहरण प्रदान करता है। यह माना जाता है कि आप BigQuery , Dataflow, Vertex AI और TensorFlow Keras API से परिचित हैं। यह भी मानता है कि आपके पास ज्यूपिटर नोटबुक का उपयोग करने का कुछ अनुभव है, जैसे कि वर्टेक्स एआई वर्कबेंच ।
यह ट्यूटोरियल यह भी मानता है कि आप Google क्लाउड पर प्रीप्रोसेसिंग प्रकारों, चुनौतियों और विकल्पों की अवधारणाओं से परिचित हैं, जैसा कि एमएल के लिए डेटा प्रीप्रोसेसिंग: विकल्प और अनुशंसाओं में वर्णित है।
उद्देश्य
-
tf.Transformलाइब्रेरी का उपयोग करके अपाचे बीम पाइपलाइन को कार्यान्वित करें। - डेटाफ़्लो में पाइपलाइन चलाएँ।
-
tf.Transformलाइब्रेरी का उपयोग करके TensorFlow मॉडल लागू करें। - पूर्वानुमानों के लिए मॉडल को प्रशिक्षित करें और उसका उपयोग करें।
लागत
यह ट्यूटोरियल Google क्लाउड के निम्नलिखित बिल योग्य घटकों का उपयोग करता है:
इस ट्यूटोरियल को चलाने की लागत का अनुमान लगाने के लिए, यह मानते हुए कि आप पूरे दिन के लिए प्रत्येक संसाधन का उपयोग करते हैं, पूर्व-कॉन्फ़िगर मूल्य निर्धारण कैलकुलेटर का उपयोग करें।
शुरू करने से पहले
Google क्लाउड कंसोल में, प्रोजेक्ट चयनकर्ता पृष्ठ पर, Google क्लाउड प्रोजेक्ट चुनें या बनाएं ।
सुनिश्चित करें कि आपके क्लाउड प्रोजेक्ट के लिए बिलिंग सक्षम है। जानें कि कैसे जांचें कि किसी प्रोजेक्ट पर बिलिंग सक्षम है या नहीं ।
डेटाफ्लो, वर्टेक्स एआई और नोटबुक एपीआई सक्षम करें। एपीआई सक्षम करें
इस समाधान के लिए ज्यूपिटर नोटबुक
निम्नलिखित ज्यूपिटर नोटबुक कार्यान्वयन उदाहरण दिखाते हैं:
- नोटबुक 1 डेटा प्रीप्रोसेसिंग को कवर करता है। विवरण बाद में अपाचे बीम पाइपलाइन के कार्यान्वयन अनुभाग में प्रदान किए गए हैं।
- नोटबुक 2 में मॉडल प्रशिक्षण शामिल है। विवरण बाद में TensorFlow मॉडल को लागू करने वाले अनुभाग में प्रदान किया गया है।
निम्नलिखित अनुभागों में, आप इन नोटबुक्स को क्लोन करते हैं, और फिर कार्यान्वयन उदाहरण कैसे काम करता है यह जानने के लिए नोटबुक्स को निष्पादित करते हैं।
उपयोगकर्ता-प्रबंधित नोटबुक इंस्टेंस लॉन्च करें
Google क्लाउड कंसोल में, वर्टेक्स एआई वर्कबेंच पेज पर जाएं।
उपयोगकर्ता-प्रबंधित नोटबुक टैब पर, +नई नोटबुक पर क्लिक करें।
उदाहरण प्रकार के लिए GPU के बिना TensorFlow Enterprise 2.8 (LTS के साथ) का चयन करें।
बनाएं पर क्लिक करें.
नोटबुक बनाने के बाद, JupyterLab पर प्रॉक्सी के प्रारंभ होने तक प्रतीक्षा करें। जब यह तैयार हो जाए, तो नोटबुक नाम के आगे ओपन ज्यूपिटरलैब प्रदर्शित होता है।
नोटबुक को क्लोन करें
उपयोगकर्ता-प्रबंधित नोटबुक टैब पर, नोटबुक नाम के आगे, JupyterLab खोलें पर क्लिक करें। JupyterLab इंटरफ़ेस एक नए टैब में खुलता है।
यदि JupyterLab बिल्ड अनुशंसित संवाद प्रदर्शित करता है, तो सुझाए गए बिल्ड को अस्वीकार करने के लिए रद्द करें पर क्लिक करें।
लॉन्चर टैब पर, टर्मिनल पर क्लिक करें।
टर्मिनल विंडो में, नोटबुक को क्लोन करें:
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
अपाचे बीम पाइपलाइन लागू करें
यह अनुभाग और अगला अनुभाग डेटाफ़्लो में पाइपलाइन चलाएँ नोटबुक 1 के लिए एक सिंहावलोकन और संदर्भ प्रदान करता है। नोटबुक डेटा को प्रीप्रोसेस करने के लिए tf.Transform लाइब्रेरी का उपयोग करने के तरीके का वर्णन करने के लिए एक व्यावहारिक उदाहरण प्रदान करता है। यह उदाहरण नेटैलिटी डेटासेट का उपयोग करता है, जिसका उपयोग विभिन्न इनपुट के आधार पर बच्चे के वजन की भविष्यवाणी करने के लिए किया जाता है। डेटा को BigQuery में सार्वजनिक जन्म तालिका में संग्रहीत किया जाता है।
नोटबुक 1 चलाएँ
JupyterLab इंटरफ़ेस में, फ़ाइल > पथ से खोलें पर क्लिक करें, और फिर निम्न पथ दर्ज करें:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_01.ipynbसंपादित करें > सभी आउटपुट साफ़ करें पर क्लिक करें।
आवश्यक पैकेज स्थापित करें अनुभाग में,
pip install apache-beamकमांड चलाने के लिए पहले सेल को निष्पादित करें।आउटपुट का अंतिम भाग निम्नलिखित है:
Successfully installed ...आप आउटपुट में निर्भरता त्रुटियों को अनदेखा कर सकते हैं। आपको अभी तक कर्नेल को पुनरारंभ करने की आवश्यकता नहीं है।
pip install tensorflow-transformकमांड चलाने के लिए दूसरी सेल निष्पादित करें। आउटपुट का अंतिम भाग निम्नलिखित है:Successfully installed ... Note: you may need to restart the kernel to use updated packages.आप आउटपुट में निर्भरता त्रुटियों को अनदेखा कर सकते हैं।
कर्नेल > कर्नेल पुनरारंभ करें पर क्लिक करें.
स्थापित पैकेजों की पुष्टि करें और डेटाफ्लो कंटेनर अनुभागों में पैकेज स्थापित करने के लिए setup.py बनाएं में कक्षों को निष्पादित करें।
वैश्विक झंडे सेट करें अनुभाग में,
PROJECTऔरBUCKETके बगल में,your-projectअपने क्लाउड प्रोजेक्ट आईडी से बदलें, और फिर सेल निष्पादित करें।नोटबुक में अंतिम सेल के माध्यम से शेष सभी सेल निष्पादित करें। प्रत्येक सेल में क्या करना है, इसकी जानकारी के लिए नोटबुक में दिए गए निर्देश देखें।
पाइपलाइन का अवलोकन
नोटबुक उदाहरण में, डेटाफ्लो डेटा तैयार करने और परिवर्तन कलाकृतियों का उत्पादन करने के लिए बड़े पैमाने पर tf.Transform पाइपलाइन चलाता है। इस दस्तावेज़ के बाद के अनुभाग उन कार्यों का वर्णन करते हैं जो पाइपलाइन में प्रत्येक चरण को निष्पादित करते हैं। समग्र पाइपलाइन चरण इस प्रकार हैं:
- BigQuery से प्रशिक्षण डेटा पढ़ें.
-
tf.Transformलाइब्रेरी का उपयोग करके प्रशिक्षण डेटा का विश्लेषण और परिवर्तन करें। - परिवर्तित प्रशिक्षण डेटा को TFRecord प्रारूप में क्लाउड स्टोरेज में लिखें।
- BigQuery से मूल्यांकन डेटा पढ़ें.
- चरण 2 द्वारा निर्मित
transform_fnग्राफ़ का उपयोग करके मूल्यांकन डेटा को रूपांतरित करें। - परिवर्तित प्रशिक्षण डेटा को TFRecord प्रारूप में क्लाउड स्टोरेज में लिखें।
- क्लाउड स्टोरेज में रूपांतरण कलाकृतियाँ लिखें जिनका उपयोग बाद में मॉडल बनाने और निर्यात करने के लिए किया जाएगा।
निम्नलिखित उदाहरण समग्र पाइपलाइन के लिए पायथन कोड दिखाता है। निम्नलिखित अनुभाग प्रत्येक चरण के लिए स्पष्टीकरण और कोड सूची प्रदान करते हैं।
def run_transformation_pipeline(args):
pipeline_options = beam.pipeline.PipelineOptions(flags=[], **args)
runner = args['runner']
data_size = args['data_size']
transformed_data_location = args['transformed_data_location']
transform_artefact_location = args['transform_artefact_location']
temporary_dir = args['temporary_dir']
debug = args['debug']
# Instantiate the pipeline
with beam.Pipeline(runner, options=pipeline_options) as pipeline:
with impl.Context(temporary_dir):
# Preprocess train data
step = 'train'
# Read raw train data from BigQuery
raw_train_dataset = read_from_bq(pipeline, step, data_size)
# Analyze and transform raw_train_dataset
transformed_train_dataset, transform_fn = analyze_and_transform(raw_train_dataset, step)
# Write transformed train data to sink as tfrecords
write_tfrecords(transformed_train_dataset, transformed_data_location, step)
# Preprocess evaluation data
step = 'eval'
# Read raw eval data from BigQuery
raw_eval_dataset = read_from_bq(pipeline, step, data_size)
# Transform eval data based on produced transform_fn
transformed_eval_dataset = transform(raw_eval_dataset, transform_fn, step)
# Write transformed eval data to sink as tfrecords
write_tfrecords(transformed_eval_dataset, transformed_data_location, step)
# Write transformation artefacts
write_transform_artefacts(transform_fn, transform_artefact_location)
# (Optional) for debugging, write transformed data as text
step = 'debug'
# Write transformed train data as text if debug enabled
if debug == True:
write_text(transformed_train_dataset, transformed_data_location, step)
BigQuery से कच्चा प्रशिक्षण डेटा पढ़ें
पहला कदम read_from_bq फ़ंक्शन का उपयोग करके BigQuery से कच्चे प्रशिक्षण डेटा को पढ़ना है। यह फ़ंक्शन एक raw_dataset ऑब्जेक्ट लौटाता है जिसे BigQuery से निकाला जाता है। आप data_size मान पास करते हैं और train या eval का step मान पास करते हैं। BigQuery स्रोत क्वेरी का निर्माण get_source_query फ़ंक्शन का उपयोग करके किया गया है, जैसा कि निम्नलिखित उदाहरण में दिखाया गया है:
def read_from_bq(pipeline, step, data_size):
source_query = get_source_query(step, data_size)
raw_data = (
pipeline
| '{} - Read Data from BigQuery'.format(step) >> beam.io.Read(
beam.io.BigQuerySource(query=source_query, use_standard_sql=True))
| '{} - Clean up Data'.format(step) >> beam.Map(prep_bq_row)
)
raw_metadata = create_raw_metadata()
raw_dataset = (raw_data, raw_metadata)
return raw_dataset
इससे पहले कि आप tf.Transform प्रीप्रोसेसिंग करें, आपको मैप, फ़िल्टर, ग्रुप और विंडो प्रोसेसिंग सहित विशिष्ट अपाचे बीम-आधारित प्रोसेसिंग करने की आवश्यकता हो सकती है। उदाहरण में, कोड beam.Map(prep_bq_row) विधि का उपयोग करके BigQuery से पढ़े गए रिकॉर्ड को साफ़ करता है, जहां prep_bq_row एक कस्टम फ़ंक्शन है। यह कस्टम फ़ंक्शन किसी श्रेणीगत सुविधा के लिए संख्यात्मक कोड को मानव-पठनीय लेबल में परिवर्तित करता है।
इसके अलावा, BigQuery से निकाले गए raw_data ऑब्जेक्ट का विश्लेषण और परिवर्तन करने के लिए tf.Transform लाइब्रेरी का उपयोग करने के लिए, आपको एक raw_dataset ऑब्जेक्ट बनाने की आवश्यकता है, जो raw_data और raw_metadata ऑब्जेक्ट का एक टुपल है। raw_metadata ऑब्जेक्ट create_raw_metadata फ़ंक्शन का उपयोग करके निम्नानुसार बनाया गया है:
CATEGORICAL_FEATURE_NAMES = ['is_male', 'mother_race']
NUMERIC_FEATURE_NAMES = ['mother_age', 'plurality', 'gestation_weeks']
TARGET_FEATURE_NAME = 'weight_pounds'
def create_raw_metadata():
feature_spec = dict(
[(name, tf.io.FixedLenFeature([], tf.string)) for name in CATEGORICAL_FEATURE_NAMES] +
[(name, tf.io.FixedLenFeature([], tf.float32)) for name in NUMERIC_FEATURE_NAMES] +
[(TARGET_FEATURE_NAME, tf.io.FixedLenFeature([], tf.float32))])
raw_metadata = dataset_metadata.DatasetMetadata(
schema_utils.schema_from_feature_spec(feature_spec))
return raw_metadata
जब आप नोटबुक में उस सेल को निष्पादित करते हैं जो इस विधि को परिभाषित करने वाले सेल का तुरंत अनुसरण करता है, तो raw_metadata.schema ऑब्जेक्ट की सामग्री प्रदर्शित होती है। इसमें निम्नलिखित कॉलम शामिल हैं:
-
gestation_weeks(प्रकार:FLOAT) -
is_male(प्रकार:BYTES) -
mother_age(प्रकार:FLOAT) -
mother_race(प्रकार:BYTES) -
plurality(प्रकार:FLOAT) -
weight_pounds(प्रकार:FLOAT)
कच्चे प्रशिक्षण डेटा को परिवर्तित करें
कल्पना करें कि आप इसे एमएल के लिए तैयार करने के लिए प्रशिक्षण डेटा की इनपुट कच्ची सुविधाओं में विशिष्ट प्रीप्रोसेसिंग परिवर्तन लागू करना चाहते हैं। इन परिवर्तनों में पूर्ण-पास और इंस्टेंस-स्तरीय संचालन दोनों शामिल हैं, जैसा कि निम्नलिखित तालिका में दिखाया गया है:
| इनपुट सुविधा | परिवर्तन | आँकड़े आवश्यक | प्रकार | आउटपुट सुविधा |
|---|---|---|---|---|
weight_pound | कोई नहीं | कोई नहीं | ना | weight_pound |
mother_age | सामान्य | मतलब, वर | फुल-पास | mother_age_normalized |
mother_age | समान आकार का बकेटाइजेशन | मात्राएँ | फुल-पास | mother_age_bucketized |
mother_age | लॉग की गणना करें | कोई नहीं | उदाहरण-स्तर | mother_age_log |
plurality | बताएं कि क्या यह एकल या एकाधिक बच्चे हैं | कोई नहीं | उदाहरण-स्तर | is_multiple |
is_multiple | नाममात्र मानों को संख्यात्मक सूचकांक में बदलें | शब्दावली | फुल-पास | is_multiple_index |
gestation_weeks | 0 और 1 के बीच स्केल | न्यूनतम अधिकतम | फुल-पास | gestation_weeks_scaled |
mother_race | नाममात्र मानों को संख्यात्मक सूचकांक में बदलें | शब्दावली | फुल-पास | mother_race_index |
is_male | नाममात्र मानों को संख्यात्मक सूचकांक में बदलें | शब्दावली | फुल-पास | is_male_index |
इन परिवर्तनों को preprocess_fn फ़ंक्शन में कार्यान्वित किया जाता है, जो टेंसर ( input_features ) के शब्दकोश की अपेक्षा करता है और संसाधित सुविधाओं ( output_features ) का शब्दकोश लौटाता है।
निम्नलिखित कोड tf.Transform फुल-पास ट्रांसफ़ॉर्मेशन API ( tft. के साथ उपसर्ग), और TensorFlow ( tf. के साथ उपसर्ग) उदाहरण-स्तरीय संचालन का उपयोग करके preprocess_fn फ़ंक्शन के कार्यान्वयन को दिखाता है:
def preprocess_fn(input_features):
output_features = {}
# target feature
output_features['weight_pounds'] = input_features['weight_pounds']
# normalization
output_features['mother_age_normalized'] = tft.scale_to_z_score(input_features['mother_age'])
# scaling
output_features['gestation_weeks_scaled'] = tft.scale_to_0_1(input_features['gestation_weeks'])
# bucketization based on quantiles
output_features['mother_age_bucketized'] = tft.bucketize(input_features['mother_age'], num_buckets=5)
# you can compute new features based on custom formulas
output_features['mother_age_log'] = tf.math.log(input_features['mother_age'])
# or create flags/indicators
is_multiple = tf.as_string(input_features['plurality'] > tf.constant(1.0))
# convert categorical features to indexed vocab
output_features['mother_race_index'] = tft.compute_and_apply_vocabulary(input_features['mother_race'], vocab_filename='mother_race')
output_features['is_male_index'] = tft.compute_and_apply_vocabulary(input_features['is_male'], vocab_filename='is_male')
output_features['is_multiple_index'] = tft.compute_and_apply_vocabulary(is_multiple, vocab_filename='is_multiple')
return output_features
tf.Transform फ्रेमवर्क में पिछले उदाहरण के अलावा कई अन्य परिवर्तन भी हैं, जिनमें निम्न तालिका में सूचीबद्ध परिवर्तन भी शामिल हैं:
| परिवर्तन | पर लागू होता है | विवरण |
|---|---|---|
scale_by_min_max | संख्यात्मक विशेषताएँ | एक संख्यात्मक कॉलम को श्रेणी में स्केल करता है [ output_min , output_max ] |
scale_to_0_1 | संख्यात्मक विशेषताएँ | एक कॉलम लौटाता है जो कि रेंज के लिए स्केल किया गया इनपुट कॉलम है [ 0 , 1 ] |
scale_to_z_score | संख्यात्मक विशेषताएँ | माध्य 0 और विचरण 1 के साथ एक मानकीकृत कॉलम लौटाता है |
tfidf | टेक्स्ट की विशेषताएं | x में शब्दों को उनकी पद आवृत्ति * व्युत्क्रम दस्तावेज़ आवृत्ति में मैप करता है |
compute_and_apply_vocabulary | श्रेणीबद्ध विशेषताएं | एक श्रेणीगत विशेषता के लिए एक शब्दावली तैयार करता है और इसे इस शब्दावली के साथ एक पूर्णांक में मैप करता है |
ngrams | टेक्स्ट की विशेषताएं | एन-ग्राम का एक SparseTensor बनाता है |
hash_strings | श्रेणीबद्ध विशेषताएं | हैश को बाल्टियों में पिरोया जाता है |
pca | संख्यात्मक विशेषताएँ | पक्षपातपूर्ण सहप्रसरण का उपयोग करके डेटासेट पर पीसीए की गणना करता है |
bucketize | संख्यात्मक विशेषताएँ | एक समान आकार (मात्रा-आधारित) बकेटाइज्ड कॉलम लौटाता है, जिसमें प्रत्येक इनपुट को एक बकेट इंडेक्स सौंपा जाता है |
preprocess_fn फ़ंक्शन में कार्यान्वित परिवर्तनों को पाइपलाइन के पिछले चरण में उत्पादित raw_train_dataset ऑब्जेक्ट पर लागू करने के लिए, आप AnalyzeAndTransformDataset विधि का उपयोग करते हैं। यह विधि इनपुट के रूप में raw_dataset ऑब्जेक्ट की अपेक्षा करती है, preprocess_fn फ़ंक्शन को लागू करती है, और यह transformed_dataset ऑब्जेक्ट और transform_fn ग्राफ़ उत्पन्न करती है। निम्नलिखित कोड इस प्रसंस्करण को दर्शाता है:
def analyze_and_transform(raw_dataset, step):
transformed_dataset, transform_fn = (
raw_dataset
| '{} - Analyze & Transform'.format(step) >> tft_beam.AnalyzeAndTransformDataset(
preprocess_fn, output_record_batches=True)
)
return transformed_dataset, transform_fn
परिवर्तनों को कच्चे डेटा पर दो चरणों में लागू किया जाता है: विश्लेषण चरण और परिवर्तन चरण। इस दस्तावेज़ में बाद में चित्र 3 दिखाता है कि कैसे AnalyzeAndTransformDataset विधि को AnalyzeDataset विधि और TransformDataset विधि में विघटित किया जाता है।
विश्लेषण चरण
विश्लेषण चरण में, परिवर्तनों के लिए आवश्यक आंकड़ों की गणना करने के लिए कच्चे प्रशिक्षण डेटा का पूर्ण-पास प्रक्रिया में विश्लेषण किया जाता है। इसमें माध्य, विचरण, न्यूनतम, अधिकतम, मात्राएँ और शब्दावली की गणना शामिल है। विश्लेषण प्रक्रिया एक कच्चे डेटासेट (कच्चे डेटा और कच्चे मेटाडेटा) की अपेक्षा करती है, और यह दो आउटपुट उत्पन्न करती है:
-
transform_fn: एक टेन्सरफ़्लो ग्राफ़ जिसमें विश्लेषण चरण से गणना किए गए आँकड़े और उदाहरण-स्तरीय संचालन के रूप में परिवर्तन तर्क (जो आँकड़ों का उपयोग करता है) शामिल हैं। जैसा कि ग्राफ़ सहेजें में बाद में चर्चा की गई है,transform_fnग्राफ़ को मॉडलserving_fnफ़ंक्शन से संलग्न करने के लिए सहेजा गया है। इससे ऑनलाइन पूर्वानुमान डेटा बिंदुओं पर समान परिवर्तन लागू करना संभव हो जाता है। -
transform_metadata: एक ऑब्जेक्ट जो परिवर्तन के बाद डेटा की अपेक्षित स्कीमा का वर्णन करता है।
विश्लेषण चरण को निम्नलिखित चित्र, चित्र 1 में दर्शाया गया है:

tf.Transform विश्लेषण चरण। tf.Transform विश्लेषक में min , max , sum , size , mean , var , covariance , quantiles , vocabulary और pca शामिल हैं।
परिवर्तन चरण
परिवर्तन चरण में, विश्लेषण चरण द्वारा निर्मित transform_fn ग्राफ का उपयोग परिवर्तित प्रशिक्षण डेटा का उत्पादन करने के लिए कच्चे प्रशिक्षण डेटा को एक उदाहरण-स्तरीय प्रक्रिया में बदलने के लिए किया जाता है। transformed_train_dataset डेटासेट का उत्पादन करने के लिए रूपांतरित प्रशिक्षण डेटा को रूपांतरित मेटाडेटा (विश्लेषण चरण द्वारा उत्पादित) के साथ जोड़ा जाता है।
परिवर्तन चरण को निम्नलिखित चित्र, चित्र 2 में दर्शाया गया है:

tf.Transform परिवर्तन चरण। सुविधाओं को प्रीप्रोसेस करने के लिए, आप preprocess_fn फ़ंक्शन के कार्यान्वयन में आवश्यक tensorflow_transform ट्रांसफॉर्मेशन (कोड में tft के रूप में आयातित) को कॉल करते हैं। उदाहरण के लिए, जब आप tft.scale_to_z_score ऑपरेशंस को कॉल करते हैं, तो tf.Transform लाइब्रेरी इस फ़ंक्शन कॉल को माध्य और विचरण विश्लेषक में अनुवादित करती है, विश्लेषण चरण में आंकड़ों की गणना करती है, और फिर ट्रांसफ़ॉर्म चरण में संख्यात्मक सुविधा को सामान्य करने के लिए इन आंकड़ों को लागू करती है। यह सब AnalyzeAndTransformDataset(preprocess_fn) विधि को कॉल करके स्वचालित रूप से किया जाता है।
इस कॉल द्वारा निर्मित transformed_metadata.schema इकाई में निम्नलिखित कॉलम शामिल हैं:
-
gestation_weeks_scaled(प्रकार:FLOAT) -
is_male_index(प्रकार:INT, is_categorical:True) -
is_multiple_index(प्रकार:INT, is_categorical:True) -
mother_age_bucketized(प्रकार:INT, is_categorical:True) -
mother_age_log(प्रकार:FLOAT) -
mother_age_normalized(प्रकार:FLOAT) -
mother_race_index(प्रकार:INT, is_categorical:True) -
weight_pounds(प्रकार:FLOAT)
जैसा कि इस श्रृंखला के पहले भाग में प्रीप्रोसेसिंग ऑपरेशंस में बताया गया है, फीचर परिवर्तन श्रेणीगत विशेषताओं को संख्यात्मक प्रतिनिधित्व में परिवर्तित करता है। परिवर्तन के बाद, श्रेणीबद्ध विशेषताओं को पूर्णांक मानों द्वारा दर्शाया जाता है। transformed_metadata.schema इकाई में, INT प्रकार के स्तंभों के लिए is_categorical ध्वज इंगित करता है कि क्या स्तंभ एक श्रेणीबद्ध विशेषता या एक वास्तविक संख्यात्मक विशेषता का प्रतिनिधित्व करता है।
रूपांतरित प्रशिक्षण डेटा लिखें
प्रशिक्षण डेटा को विश्लेषण और परिवर्तन चरणों के माध्यम से preprocess_fn फ़ंक्शन के साथ पूर्व-संसाधित करने के बाद, आप टेंसरफ्लो मॉडल के प्रशिक्षण के लिए उपयोग किए जाने वाले सिंक में डेटा लिख सकते हैं। जब आप डेटाफ्लो का उपयोग करके अपाचे बीम पाइपलाइन निष्पादित करते हैं, तो सिंक क्लाउड स्टोरेज होता है। अन्यथा, सिंक स्थानीय डिस्क है. यद्यपि आप डेटा को निश्चित-चौड़ाई वाली स्वरूपित फ़ाइलों की CSV फ़ाइल के रूप में लिख सकते हैं, TensorFlow डेटासेट के लिए अनुशंसित फ़ाइल प्रारूप TFRecord प्रारूप है। यह एक सरल रिकॉर्ड-उन्मुख बाइनरी प्रारूप है जिसमें tf.train.Example प्रोटोकॉल बफ़र संदेश शामिल हैं।
प्रत्येक tf.train.Example रिकॉर्ड में एक या अधिक सुविधाएँ होती हैं। जब इन्हें प्रशिक्षण के लिए मॉडल में डाला जाता है तो ये टेंसर में परिवर्तित हो जाते हैं। निम्नलिखित कोड निर्दिष्ट स्थान पर परिवर्तित डेटासेट को TFRecord फ़ाइलों में लिखता है:
def write_tfrecords(transformed_dataset, location, step):
from tfx_bsl.coders import example_coder
transformed_data, transformed_metadata = transformed_dataset
(
transformed_data
| '{} - Encode Transformed Data'.format(step) >> beam.FlatMapTuple(
lambda batch, _: example_coder.RecordBatchToExamples(batch))
| '{} - Write Transformed Data'.format(step) >> beam.io.WriteToTFRecord(
file_path_prefix=os.path.join(location,'{}'.format(step)),
file_name_suffix='.tfrecords')
)
मूल्यांकन डेटा पढ़ें, रूपांतरित करें और लिखें
प्रशिक्षण डेटा को बदलने और transform_fn ग्राफ़ तैयार करने के बाद, आप इसका उपयोग मूल्यांकन डेटा को बदलने के लिए कर सकते हैं। सबसे पहले, आप BigQuery से कच्चे प्रशिक्षण डेटा पढ़ें में पहले वर्णित read_from_bq फ़ंक्शन का उपयोग करके BigQuery से मूल्यांकन डेटा को पढ़ें और साफ़ करें, और step पैरामीटर के लिए eval का मान पास करें। फिर, आप कच्चे मूल्यांकन डेटासेट ( raw_dataset ) को अपेक्षित रूपांतरित प्रारूप ( transformed_dataset ) में बदलने के लिए निम्नलिखित कोड का उपयोग करते हैं:
def transform(raw_dataset, transform_fn, step):
transformed_dataset = (
(raw_dataset, transform_fn)
| '{} - Transform'.format(step) >> tft_beam.TransformDataset(output_record_batches=True)
)
return transformed_dataset
जब आप मूल्यांकन डेटा को रूपांतरित करते हैं, तो केवल उदाहरण-स्तरीय संचालन लागू होते हैं, जिसमें transform_fn ग्राफ़ में तर्क और प्रशिक्षण डेटा में विश्लेषण चरण से गणना किए गए आँकड़े दोनों का उपयोग किया जाता है। दूसरे शब्दों में, आप मूल्यांकन डेटा में संख्यात्मक विशेषताओं के z-स्कोर सामान्यीकरण के लिए माध्य और भिन्नता जैसे नए आँकड़ों की गणना करने के लिए मूल्यांकन डेटा का पूर्ण-पास विश्लेषण नहीं करते हैं। इसके बजाय, आप मूल्यांकन डेटा को उदाहरण-स्तरीय फैशन में बदलने के लिए प्रशिक्षण डेटा से गणना किए गए आंकड़ों का उपयोग करते हैं।
इसलिए, आप आंकड़ों की गणना करने और डेटा को बदलने के लिए प्रशिक्षण डेटा के संदर्भ में AnalyzeAndTransform विधि का उपयोग करते हैं। साथ ही, आप मूल्यांकन डेटा को बदलने के संदर्भ में TransformDataset विधि का उपयोग केवल प्रशिक्षण डेटा पर गणना किए गए आंकड़ों का उपयोग करके डेटा को बदलने के लिए करते हैं।
फिर आप प्रशिक्षण प्रक्रिया के दौरान TensorFlow मॉडल के मूल्यांकन के लिए TFRecord प्रारूप में एक सिंक (क्लाउड स्टोरेज या स्थानीय डिस्क, रनर के आधार पर) पर डेटा लिखते हैं। ऐसा करने के लिए, आप write_tfrecords फ़ंक्शन का उपयोग करते हैं जिसकी चर्चा परिवर्तित प्रशिक्षण डेटा लिखें में की गई है। निम्नलिखित आरेख, चित्र 3, दिखाता है कि प्रशिक्षण डेटा के विश्लेषण चरण में उत्पन्न transform_fn ग्राफ़ का उपयोग मूल्यांकन डेटा को बदलने के लिए कैसे किया जाता है।

transform_fn ग्राफ़ का उपयोग करके मूल्यांकन डेटा को बदलना।ग्राफ़ सहेजें
tf.Transform प्रीप्रोसेसिंग पाइपलाइन में अंतिम चरण कलाकृतियों को संग्रहीत करना है, जिसमें transform_fn ग्राफ़ शामिल है जो प्रशिक्षण डेटा पर विश्लेषण चरण द्वारा निर्मित होता है। कलाकृतियों को संग्रहीत करने के लिए कोड निम्नलिखित write_transform_artefacts फ़ंक्शन में दिखाया गया है:
def write_transform_artefacts(transform_fn, location):
(
transform_fn
| 'Write Transform Artifacts' >> transform_fn_io.WriteTransformFn(location)
)
इन कलाकृतियों का उपयोग बाद में मॉडल प्रशिक्षण और सेवा हेतु निर्यात के लिए किया जाएगा। निम्नलिखित कलाकृतियाँ भी निर्मित की जाती हैं, जैसा कि अगले भाग में दिखाया गया है:
-
saved_model.pb: TensorFlow ग्राफ़ का प्रतिनिधित्व करता है जिसमें ट्रांसफ़ॉर्मेशन लॉजिक (transform_fnग्राफ़) शामिल है, जिसे कच्चे डेटा बिंदुओं को रूपांतरित प्रारूप में बदलने के लिए मॉडल सर्विंग इंटरफ़ेस से जोड़ा जाना है। -
variables: इसमें प्रशिक्षण डेटा के विश्लेषण चरण के दौरान गणना किए गए आँकड़े शामिल हैं, और इसका उपयोगsaved_model.pbआर्टिफैक्ट में परिवर्तन तर्क में किया जाता है। -
assets: इसमें शब्दावली फ़ाइलें शामिल हैं, प्रत्येक श्रेणीगत सुविधा के लिए एक, जिसेcompute_and_apply_vocabularyविधि के साथ संसाधित किया जाता है, जिसका उपयोग इनपुट कच्चे नाममात्र मूल्य को संख्यात्मक सूचकांक में परिवर्तित करने के लिए सेवा के दौरान किया जाता है। -
transformed_metadata: एक निर्देशिका जिसमेंschema.jsonफ़ाइल होती है जो रूपांतरित डेटा की स्कीमा का वर्णन करती है।
डेटाफ़्लो में पाइपलाइन चलाएँ
tf.Transform पाइपलाइन को परिभाषित करने के बाद, आप डेटाफ्लो का उपयोग करके पाइपलाइन चलाते हैं। निम्नलिखित आरेख, चित्र 4, उदाहरण में वर्णित tf.Transform पाइपलाइन का डेटाफ़्लो निष्पादन ग्राफ़ दिखाता है।
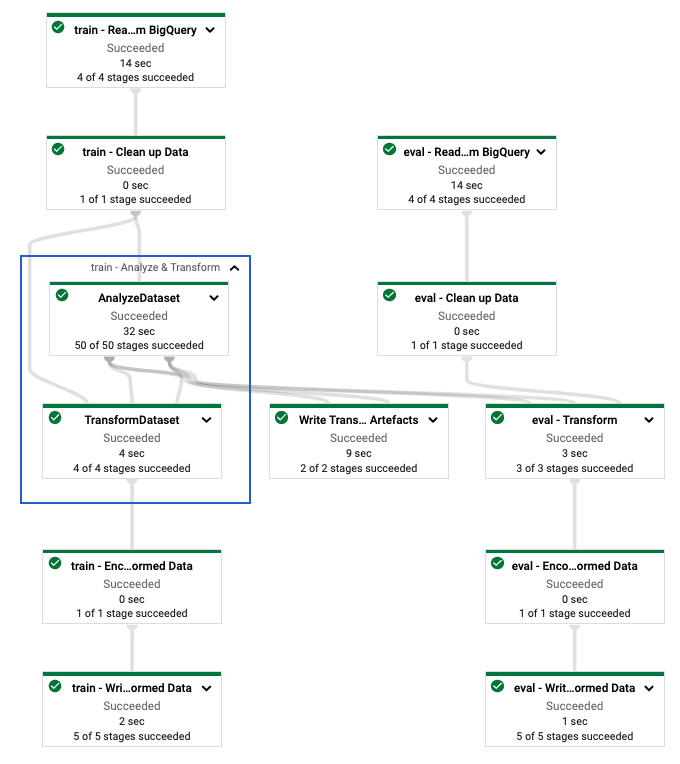
tf.Transform पाइपलाइन का डेटाफ़्लो निष्पादन ग्राफ़। प्रशिक्षण और मूल्यांकन डेटा को प्रीप्रोसेस करने के लिए डेटाफ्लो पाइपलाइन को निष्पादित करने के बाद, आप नोटबुक में अंतिम सेल को निष्पादित करके क्लाउड स्टोरेज में उत्पादित वस्तुओं का पता लगा सकते हैं। इस अनुभाग में कोड स्निपेट परिणाम दिखाते हैं, जहां YOUR_BUCKET_NAME आपके क्लाउड स्टोरेज बकेट का नाम है।
TFRecord प्रारूप में परिवर्तित प्रशिक्षण और मूल्यांकन डेटा निम्नलिखित स्थान पर संग्रहीत किया जाता है:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed
परिवर्तन कलाकृतियाँ निम्नलिखित स्थान पर निर्मित की जाती हैं:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform
निम्नलिखित सूची पाइपलाइन का आउटपुट है, जो उत्पादित डेटा ऑब्जेक्ट और कलाकृतियों को दिखाती है:
transformed data:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/eval-00000-of-00001.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00000-of-00002.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00001-of-00002.tfrecords
transformed metadata:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/asset_map
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/schema.pbtxt
transform artefact:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/saved_model.pb
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/variables/
transform assets:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_male
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_multiple
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/mother_race
TensorFlow मॉडल लागू करें
यह अनुभाग और अगला अनुभाग, भविष्यवाणियों के लिए मॉडल को प्रशिक्षित करें और उसका उपयोग करें , नोटबुक 2 के लिए एक सिंहावलोकन और संदर्भ प्रदान करें। नोटबुक बच्चे के वजन की भविष्यवाणी करने के लिए एक उदाहरण एमएल मॉडल प्रदान करता है। इस उदाहरण में, केरस एपीआई का उपयोग करके एक टेन्सरफ्लो मॉडल लागू किया गया है। मॉडल उस डेटा और कलाकृतियों का उपयोग करता है जो पहले बताए गए tf.Transform प्रीप्रोसेसिंग पाइपलाइन द्वारा उत्पादित होते हैं।
नोटबुक 2 चलाएँ
JupyterLab इंटरफ़ेस में, फ़ाइल > पथ से खोलें पर क्लिक करें, और फिर निम्न पथ दर्ज करें:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_02.ipynbसंपादित करें > सभी आउटपुट साफ़ करें पर क्लिक करें।
आवश्यक पैकेज स्थापित करें अनुभाग में,
pip install tensorflow-transformकमांड चलाने के लिए पहले सेल को निष्पादित करें।आउटपुट का अंतिम भाग निम्नलिखित है:
Successfully installed ... Note: you may need to restart the kernel to use updated packages.आप आउटपुट में निर्भरता त्रुटियों को अनदेखा कर सकते हैं।
कर्नेल मेनू में, कर्नेल को पुनरारंभ करें चुनें।
स्थापित पैकेजों की पुष्टि करें और डेटाफ्लो कंटेनर अनुभागों में पैकेज स्थापित करने के लिए setup.py बनाएं में कक्षों को निष्पादित करें।
वैश्विक झंडे सेट करें अनुभाग में,
PROJECTऔरBUCKETके बगल में,your-projectअपने क्लाउड प्रोजेक्ट आईडी से बदलें, और फिर सेल निष्पादित करें।नोटबुक में अंतिम सेल के माध्यम से शेष सभी सेल निष्पादित करें। प्रत्येक सेल में क्या करना है, इसकी जानकारी के लिए नोटबुक में दिए गए निर्देश देखें।
मॉडल निर्माण का अवलोकन
मॉडल बनाने के चरण इस प्रकार हैं:
-
transformed_metadataनिर्देशिका में संग्रहीत स्कीमा जानकारी का उपयोग करके फीचर कॉलम बनाएं। - मॉडल में इनपुट के रूप में फीचर कॉलम का उपयोग करके केरस एपीआई के साथ विस्तृत और गहरा मॉडल बनाएं।
- ट्रांसफ़ॉर्म कलाकृतियों का उपयोग करके प्रशिक्षण और मूल्यांकन डेटा को पढ़ने और पार्स करने के लिए
tfrecords_input_fnफ़ंक्शन बनाएं। - मॉडल को प्रशिक्षित करें और उसका मूल्यांकन करें।
- एक
serving_fnफ़ंक्शन को परिभाषित करके प्रशिक्षित मॉडल को निर्यात करें जिसमेंtransform_fnग्राफ जुड़ा हुआ है। -
saved_model_cliटूल का उपयोग करके निर्यात किए गए मॉडल का निरीक्षण करें। - भविष्यवाणी के लिए निर्यातित मॉडल का उपयोग करें।
यह दस्तावेज़ यह नहीं बताता कि मॉडल कैसे बनाया जाए, इसलिए यह विस्तार से चर्चा नहीं करता है कि मॉडल कैसे बनाया गया या प्रशिक्षित किया गया। हालाँकि, निम्नलिखित अनुभाग दिखाते हैं कि transform_metadata निर्देशिका में संग्रहीत जानकारी - जो tf.Transform प्रक्रिया द्वारा निर्मित होती है - का उपयोग मॉडल के फीचर कॉलम बनाने के लिए किया जाता है। दस्तावेज़ यह भी दिखाता है कि कैसे transform_fn ग्राफ़ - जो tf.Transform प्रक्रिया द्वारा भी निर्मित होता है - का उपयोग serving_fn फ़ंक्शन में किया जाता है जब मॉडल को सर्विंग के लिए निर्यात किया जाता है।
मॉडल प्रशिक्षण में उत्पन्न परिवर्तन कलाकृतियों का उपयोग करें
जब आप TensorFlow मॉडल को प्रशिक्षित करते हैं, तो आप पिछले डेटा प्रोसेसिंग चरण में उत्पादित रूपांतरित train और eval ऑब्जेक्ट का उपयोग करते हैं। इन ऑब्जेक्ट्स को TFRecord प्रारूप में शार्प फ़ाइलों के रूप में संग्रहीत किया जाता है। पिछले चरण में उत्पन्न transformed_metadata निर्देशिका में स्कीमा जानकारी प्रशिक्षण और मूल्यांकन के लिए मॉडल में फीड करने के लिए डेटा ( tf.train.Example ऑब्जेक्ट) को पार्स करने में उपयोगी हो सकती है।
डेटा पार्स करें
चूँकि आप प्रशिक्षण और मूल्यांकन डेटा के साथ मॉडल को फीड करने के लिए TFRecord प्रारूप में फ़ाइलें पढ़ते हैं, इसलिए आपको सुविधाओं का शब्दकोश (टेंसर्स) बनाने के लिए फ़ाइलों में प्रत्येक tf.train.Example ऑब्जेक्ट को पार्स करने की आवश्यकता होती है। यह सुनिश्चित करता है कि फीचर कॉलम का उपयोग करके सुविधाओं को मॉडल इनपुट परत पर मैप किया जाता है, जो मॉडल प्रशिक्षण और मूल्यांकन इंटरफ़ेस के रूप में कार्य करता है। डेटा को पार्स करने के लिए, आप TFTransformOutput ऑब्जेक्ट का उपयोग करते हैं जो पिछले चरण में उत्पन्न कलाकृतियों से बनाया गया है:
पिछले प्रीप्रोसेसिंग चरण में उत्पन्न और सहेजे गए कलाकृतियों से एक
TFTransformOutputऑब्जेक्ट बनाएं, जैसा कि ग्राफ़ सहेजें अनुभाग में वर्णित है:tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)TFTransformOutputऑब्जेक्ट से एकfeature_specऑब्जेक्ट निकालें:tf_transform_output.transformed_feature_spec()tfrecords_input_fnफ़ंक्शन की तरहtf.train.Exampleऑब्जेक्ट में निहित सुविधाओं को निर्दिष्ट करने के लिएfeature_specऑब्जेक्ट का उपयोग करें:def tfrecords_input_fn(files_name_pattern, batch_size=512): tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR) TARGET_FEATURE_NAME = 'weight_pounds' batched_dataset = tf.data.experimental.make_batched_features_dataset( file_pattern=files_name_pattern, batch_size=batch_size, features=tf_transform_output.transformed_feature_spec(), reader=tf.data.TFRecordDataset, label_key=TARGET_FEATURE_NAME, shuffle=True).prefetch(tf.data.experimental.AUTOTUNE) return batched_dataset
फ़ीचर कॉलम बनाएँ
पाइपलाइन transformed_metadata निर्देशिका में स्कीमा जानकारी उत्पन्न करती है जो प्रशिक्षण और मूल्यांकन के लिए मॉडल द्वारा अपेक्षित रूपांतरित डेटा के स्कीमा का वर्णन करती है। स्कीमा में सुविधा का नाम और डेटा प्रकार शामिल है, जैसे कि निम्नलिखित:
-
gestation_weeks_scaled(प्रकार:FLOAT) -
is_male_index(प्रकार:INT, is_categorical:True) -
is_multiple_index(प्रकार:INT, is_categorical:True) -
mother_age_bucketized(प्रकार:INT, is_categorical:True) -
mother_age_log(प्रकार:FLOAT) -
mother_age_normalized(प्रकार:FLOAT) -
mother_race_index(प्रकार:INT, is_categorical:True) -
weight_pounds(प्रकार:FLOAT)
इस जानकारी को देखने के लिए, निम्नलिखित आदेशों का उपयोग करें:
transformed_metadata = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR).transformed_metadata
transformed_metadata.schema
निम्नलिखित कोड दिखाता है कि आप फीचर कॉलम बनाने के लिए फीचर नाम का उपयोग कैसे करते हैं:
def create_wide_and_deep_feature_columns():
deep_feature_columns = []
wide_feature_columns = []
inputs = {}
categorical_columns = {}
# Select features you've checked from the metadata
# Categorical features are associated with the vocabulary size (starting from 0)
numeric_features = ['mother_age_log', 'mother_age_normalized', 'gestation_weeks_scaled']
categorical_features = [('is_male_index', 1), ('is_multiple_index', 1),
('mother_age_bucketized', 4), ('mother_race_index', 10)]
for feature in numeric_features:
deep_feature_columns.append(tf.feature_column.numeric_column(feature))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='float32')
for feature, vocab_size in categorical_features:
categorical_columns[feature] = (
tf.feature_column.categorical_column_with_identity(feature, num_buckets=vocab_size+1))
wide_feature_columns.append(tf.feature_column.indicator_column(categorical_columns[feature]))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='int64')
mother_race_X_mother_age_bucketized = tf.feature_column.crossed_column(
[categorical_columns['mother_age_bucketized'],
categorical_columns['mother_race_index']], 55)
wide_feature_columns.append(tf.feature_column.indicator_column(mother_race_X_mother_age_bucketized))
mother_race_X_mother_age_bucketized_embedded = tf.feature_column.embedding_column(
mother_race_X_mother_age_bucketized, 5)
deep_feature_columns.append(mother_race_X_mother_age_bucketized_embedded)
return wide_feature_columns, deep_feature_columns, inputs
कोड संख्यात्मक विशेषताओं के लिए एक tf.feature_column.numeric_column कॉलम बनाता है, और श्रेणीबद्ध सुविधाओं के लिए एक tf.feature_column.categorical_column_with_identity कॉलम बनाता है।
आप विस्तारित फ़ीचर कॉलम भी बना सकते हैं, जैसा कि इस श्रृंखला के पहले भाग में विकल्प C: TensorFlow में वर्णित है। इस श्रृंखला के लिए उपयोग किए गए उदाहरण में, tf.feature_column.crossed_column फीचर कॉलम का उपयोग करके mother_race और mother_age_bucketized सुविधाओं को पार करके एक नई सुविधा बनाई गई है, mother_race_X_mother_age_bucketized । इस क्रॉस्ड फीचर का निम्न-आयामी, सघन प्रतिनिधित्व tf.feature_column.embedding_column फीचर कॉलम का उपयोग करके बनाया गया है।
निम्नलिखित आरेख, चित्र 5, रूपांतरित डेटा दिखाता है और कैसे रूपांतरित मेटाडेटा का उपयोग टेन्सरफ्लो मॉडल को परिभाषित और प्रशिक्षित करने के लिए किया जाता है:

भविष्यवाणी प्रस्तुत करने के लिए मॉडल निर्यात करें
केरस एपीआई के साथ टेन्सरफ्लो मॉडल को प्रशिक्षित करने के बाद, आप प्रशिक्षित मॉडल को सेव्डमॉडल ऑब्जेक्ट के रूप में निर्यात करते हैं, ताकि यह भविष्यवाणी के लिए नए डेटा बिंदुओं की सेवा कर सके। जब आप मॉडल निर्यात करते हैं, तो आपको इसके इंटरफ़ेस को परिभाषित करना होगा - यानी, इनपुट फीचर स्कीमा जो सेवा के दौरान अपेक्षित है। इस इनपुट फीचर स्कीमा को serving_fn फ़ंक्शन में परिभाषित किया गया है, जैसा कि निम्नलिखित कोड में दिखाया गया है:
def export_serving_model(model, output_dir):
tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)
# The layer has to be saved to the model for Keras tracking purposes.
model.tft_layer = tf_transform_output.transform_features_layer()
@tf.function
def serveing_fn(uid, is_male, mother_race, mother_age, plurality, gestation_weeks):
features = {
'is_male': is_male,
'mother_race': mother_race,
'mother_age': mother_age,
'plurality': plurality,
'gestation_weeks': gestation_weeks
}
transformed_features = model.tft_layer(features)
outputs = model(transformed_features)
# The prediction results have multiple elements in general.
# But we need only the first element in our case.
outputs = tf.map_fn(lambda item: item[0], outputs)
return {'uid': uid, 'weight': outputs}
concrete_serving_fn = serveing_fn.get_concrete_function(
tf.TensorSpec(shape=[None], dtype=tf.string, name='uid'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='is_male'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='mother_race'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='mother_age'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='plurality'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='gestation_weeks')
)
signatures = {'serving_default': concrete_serving_fn}
model.save(output_dir, save_format='tf', signatures=signatures)
सेवा के दौरान, मॉडल अपने कच्चे रूप में डेटा बिंदुओं की अपेक्षा करता है (अर्थात, परिवर्तनों से पहले कच्ची विशेषताएं)। इसलिए, serving_fn फ़ंक्शन कच्ची सुविधाओं को प्राप्त करता है और उन्हें पायथन डिक्शनरी के रूप में एक features ऑब्जेक्ट में संग्रहीत करता है। हालाँकि, जैसा कि पहले चर्चा की गई है, प्रशिक्षित मॉडल रूपांतरित स्कीमा में डेटा बिंदुओं की अपेक्षा करता है। मॉडल इंटरफ़ेस द्वारा अपेक्षित कच्ची सुविधाओं को transformed_features ऑब्जेक्ट में परिवर्तित करने के लिए, आप सहेजे गए transform_fn ग्राफ़ को निम्न चरणों के साथ features ऑब्जेक्ट पर लागू करते हैं:
पिछले प्रीप्रोसेसिंग चरण में उत्पन्न और सहेजे गए कलाकृतियों से
TFTransformOutputऑब्जेक्ट बनाएं:tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)TFTransformOutputऑब्जेक्ट से एकTransformFeaturesLayerऑब्जेक्ट बनाएं:model.tft_layer = tf_transform_output.transform_features_layer()TransformFeaturesLayerऑब्जेक्ट का उपयोग करकेtransform_fnग्राफ़ लागू करें:transformed_features = model.tft_layer(features)
निम्नलिखित आरेख, चित्र 6, सेवा के लिए एक मॉडल निर्यात करने के अंतिम चरण को दर्शाता है:

transform_fn ग्राफ़ के साथ सेवा के लिए मॉडल निर्यात करना। पूर्वानुमानों के लिए मॉडल को प्रशिक्षित करें और उसका उपयोग करें
आप नोटबुक की कोशिकाओं को निष्पादित करके मॉडल को स्थानीय रूप से प्रशिक्षित कर सकते हैं। वर्टेक्स एआई ट्रेनिंग का उपयोग करके कोड को पैकेज करने और अपने मॉडल को बड़े पैमाने पर प्रशिक्षित करने के उदाहरणों के लिए, Google क्लाउड क्लाउडएमएल-सैंपल्स गिटहब रिपॉजिटरी में नमूने और गाइड देखें।
जब आप saved_model_cli टूल का उपयोग करके निर्यात किए गए SavedModel ऑब्जेक्ट का निरीक्षण करते हैं, तो आप देखते हैं कि हस्ताक्षर परिभाषा signature_def के inputs तत्वों में कच्ची विशेषताएं शामिल हैं, जैसा कि निम्नलिखित उदाहरण में दिखाया गया है:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['gestation_weeks'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_gestation_weeks:0
inputs['is_male'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_is_male:0
inputs['mother_age'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_mother_age:0
inputs['mother_race'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_mother_race:0
inputs['plurality'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_plurality:0
inputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_uid:0
The given SavedModel SignatureDef contains the following output(s):
outputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall_6:0
outputs['weight'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall_6:1
Method name is: tensorflow/serving/predict
नोटबुक की शेष कोशिकाएँ आपको दिखाती हैं कि स्थानीय भविष्यवाणी के लिए निर्यात किए गए मॉडल का उपयोग कैसे करें, और वर्टेक्स एआई भविष्यवाणी का उपयोग करके मॉडल को माइक्रोसर्विस के रूप में कैसे तैनात किया जाए। यह उजागर करना महत्वपूर्ण है कि इनपुट (नमूना) डेटा बिंदु दोनों मामलों में कच्चे स्कीमा में है।
साफ - सफाई
इस ट्यूटोरियल में उपयोग किए गए संसाधनों के लिए अपने Google क्लाउड खाते पर अतिरिक्त शुल्क लगाने से बचने के लिए, उस प्रोजेक्ट को हटा दें जिसमें संसाधन शामिल हैं।
प्रोजेक्ट हटाएँ
Google क्लाउड कंसोल में, संसाधन प्रबंधित करें पृष्ठ पर जाएं।
प्रोजेक्ट सूची में, उस प्रोजेक्ट का चयन करें जिसे आप हटाना चाहते हैं, और फिर हटाएँ पर क्लिक करें।
संवाद में, प्रोजेक्ट आईडी टाइप करें और फिर प्रोजेक्ट को हटाने के लिए शट डाउन पर क्लिक करें।
आगे क्या होगा
- Google क्लाउड पर मशीन लर्निंग के लिए डेटा प्रीप्रोसेसिंग की अवधारणाओं, चुनौतियों और विकल्पों के बारे में जानने के लिए, इस श्रृंखला का पहला लेख, एमएल के लिए डेटा प्रीप्रोसेसिंग: विकल्प और सिफारिशें देखें।
- डेटाफ़्लो पर tf.Transform पाइपलाइन को कैसे कार्यान्वित, पैकेज और चलाने के बारे में अधिक जानकारी के लिए, जनगणना डेटासेट नमूने के साथ आय की भविष्यवाणी देखें।
- Google क्लाउड पर TensorFlow के साथ ML पर कौरसेरा विशेषज्ञता लें।
- एमएल के नियमों में एमएल इंजीनियरिंग के लिए सर्वोत्तम प्रथाओं के बारे में जानें।
- अधिक संदर्भ आर्किटेक्चर, आरेख और सर्वोत्तम प्रथाओं के लिए, क्लाउड आर्किटेक्चर सेंटर देखें।