
Copyright 2021 TF 에이전트 작성자.
| | |  GitHub에서 소스 보기 GitHub에서 소스 보기 | |
소개
이 예제 프로그램은 어떻게 훈련하는 강화 받는 유사한 TF-에이전트 라이브러리를 사용하여 Cartpole 환경에 에이전트를 DQN 자습서를 .
교육, 평가 및 데이터 수집을 위한 강화 학습(RL) 파이프라인의 모든 구성 요소를 안내합니다.
설정
다음 종속성을 설치하지 않은 경우 다음을 실행합니다.
sudo apt-get updatesudo apt-get install -y xvfb ffmpeg freeglut3-devpip install 'imageio==2.4.0'pip install pyvirtualdisplaypip install tf-agents[reverb]pip install pyglet xvfbwrapper
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import numpy as np
import PIL.Image
import pyvirtualdisplay
import reverb
import tensorflow as tf
from tf_agents.agents.reinforce import reinforce_agent
from tf_agents.drivers import py_driver
from tf_agents.environments import suite_gym
from tf_agents.environments import tf_py_environment
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import py_tf_eager_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import trajectory
from tf_agents.utils import common
# Set up a virtual display for rendering OpenAI gym environments.
display = pyvirtualdisplay.Display(visible=0, size=(1400, 900)).start()
초매개변수
env_name = "CartPole-v0" # @param {type:"string"}
num_iterations = 250 # @param {type:"integer"}
collect_episodes_per_iteration = 2 # @param {type:"integer"}
replay_buffer_capacity = 2000 # @param {type:"integer"}
fc_layer_params = (100,)
learning_rate = 1e-3 # @param {type:"number"}
log_interval = 25 # @param {type:"integer"}
num_eval_episodes = 10 # @param {type:"integer"}
eval_interval = 50 # @param {type:"integer"}
환경
RL의 환경은 우리가 해결하려는 작업이나 문제를 나타냅니다. 표준 환경을 사용하여 쉽게 TF-에이전트에서 생성 될 수있다 suites . 우리는 서로 다른이 suites 문자열 환경 이름 부여, 등 등 OpenAI 체육관, 아타리, DM 제어, 같은 소스에서 환경을 로딩한다.
이제 OpenAI 체육관 제품군에서 CartPole 환경을 로드해 보겠습니다.
env = suite_gym.load(env_name)
이 환경을 렌더링하여 어떻게 보이는지 확인할 수 있습니다. 자유롭게 흔들리는 기둥이 카트에 부착되어 있습니다. 목표는 막대가 위를 향하도록 카트를 오른쪽이나 왼쪽으로 움직이는 것입니다.
env.reset()
PIL.Image.fromarray(env.render())
time_step = environment.step(action) 문은 필요 action 환경에. TimeStep 반환 튜플 해당 작업에 대한 환경의 다음 관찰과 보상이 포함되어 있습니다. time_step_spec() 및 action_spec() 환경에서의 방법의 사양 (종류, 형태, 경계)를 호출 time_step 및 action 각각.
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(4,), dtype=dtype('float32'), name='observation', minimum=[-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38], maximum=[4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38])
Action Spec:
BoundedArraySpec(shape=(), dtype=dtype('int64'), name='action', minimum=0, maximum=1)
따라서 관찰은 수레의 위치와 속도, 기둥의 각 위치와 속도인 4개의 수레로 구성된 배열임을 알 수 있습니다. 두 조치 (이동이 왼쪽 또는 오른쪽으로 이동) 가능하기 때문에, action_spec 0 수단은 "이동 왼쪽", 1 개 수단 스칼라 "이동 권리."
time_step = env.reset()
print('Time step:')
print(time_step)
action = np.array(1, dtype=np.int32)
next_time_step = env.step(action)
print('Next time step:')
print(next_time_step)
Time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([ 0.02284177, -0.04785635, 0.04171623, 0.04942273], dtype=float32),
'reward': array(0., dtype=float32),
'step_type': array(0, dtype=int32)})
Next time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([ 0.02188464, 0.14664337, 0.04270469, -0.22981201], dtype=float32),
'reward': array(1., dtype=float32),
'step_type': array(1, dtype=int32)})
일반적으로 교육용 환경과 평가 환경의 두 가지 환경을 만듭니다. 대부분의 환경은 순수한 파이썬으로 작성되어 있지만, 쉽게 사용 TensorFlow로 변환 할 수 있습니다 TFPyEnvironment 래퍼. 원래 환경의 API는 NumPy와 배열을 사용의 TFPyEnvironment 에서 / 이러한 변환 Tensors TensorFlow 정책 및 에이전트와 더 쉽게 상호 작용하는 당신을 위해.
train_py_env = suite_gym.load(env_name)
eval_py_env = suite_gym.load(env_name)
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
에이전트
우리가 RL 문제를 해결하는 데 사용하는 알고리즘은으로 표시됩니다 Agent . 강화 절연 제에 더하여, TF 에이전트는 다양한 표준 구현 제공 Agents 같은 DQN , DDPG , TD3 , PPO 와 SAC를 .
A는 에이전트를 강화 만들려면 우리가 먼저 필요 Actor Network 환경에서 관찰 주어진 행동을 예측하기 위해 배울 수 있습니다.
우리는 쉽게 만들 수 있습니다 Actor Network 관찰 및 행동의 사양을 사용합니다. 이번 예에서,이고, 네트워크 계층 지정 fc_layer_params 1 조의 인수 세트 ints 각 은닉층의 크기 (상기 하이퍼 파라미터 절 참조)를 나타내는.
actor_net = actor_distribution_network.ActorDistributionNetwork(
train_env.observation_spec(),
train_env.action_spec(),
fc_layer_params=fc_layer_params)
우리는 또한 필요 optimizer 우리가 방금 만든 네트워크를 훈련하고, train_step_counter 네트워크가 업데이트 된 횟수를 추적하기 위해 변수를.
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
train_step_counter = tf.Variable(0)
tf_agent = reinforce_agent.ReinforceAgent(
train_env.time_step_spec(),
train_env.action_spec(),
actor_network=actor_net,
optimizer=optimizer,
normalize_returns=True,
train_step_counter=train_step_counter)
tf_agent.initialize()
정책
TF-에이전트에서 정책 RL에 정책의 기본 개념을 나타냅니다 : 주어진 time_step 동작이나 행동에 걸쳐 분포를 생산하고 있습니다. 주요 방법은 policy_step = policy.action(time_step) policy_step 명명 튜플이다 PolicyStep(action, state, info) . policy_step.action 는 IS action 환경에 적용되는, state 상태 (RNN) 정책에 대한 나타내는 상태 info 예를 들면 작업 로그 확률로 보조 정보를 포함 할 수있다.
에이전트에는 평가/배포에 사용되는 기본 정책(agent.policy)과 데이터 수집에 사용되는 또 다른 정책(agent.collect_policy)의 두 가지 정책이 있습니다.
eval_policy = tf_agent.policy
collect_policy = tf_agent.collect_policy
측정항목 및 평가
정책을 평가하는 데 사용되는 가장 일반적인 지표는 평균 수익률입니다. 수익은 에피소드에 대한 환경에서 정책을 실행하는 동안 얻은 보상의 합계이며 일반적으로 몇 에피소드에 걸쳐 이를 평균화합니다. 평균 수익 측정항목은 다음과 같이 계산할 수 있습니다.
def compute_avg_return(environment, policy, num_episodes=10):
total_return = 0.0
for _ in range(num_episodes):
time_step = environment.reset()
episode_return = 0.0
while not time_step.is_last():
action_step = policy.action(time_step)
time_step = environment.step(action_step.action)
episode_return += time_step.reward
total_return += episode_return
avg_return = total_return / num_episodes
return avg_return.numpy()[0]
# Please also see the metrics module for standard implementations of different
# metrics.
재생 버퍼
환경에서 수집 된 데이터를 추적하기 위해, 우리는 사용하는 리버브 (Reverb) , Deepmind하여, 효율적으로 확장, 사용하기 쉬운 재생 시스템. 궤적을 수집할 때 경험 데이터를 저장하고 훈련 중에 소비합니다.
이 재생 버퍼를 사용하여 에이전트로부터 얻어 질 수 저장할 수있는 텐서, 기술 사양하여 구성된다 tf_agent.collect_data_spec .
table_name = 'uniform_table'
replay_buffer_signature = tensor_spec.from_spec(
tf_agent.collect_data_spec)
replay_buffer_signature = tensor_spec.add_outer_dim(
replay_buffer_signature)
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1),
signature=replay_buffer_signature)
reverb_server = reverb.Server([table])
replay_buffer = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
table_name=table_name,
sequence_length=None,
local_server=reverb_server)
rb_observer = reverb_utils.ReverbAddEpisodeObserver(
replay_buffer.py_client,
table_name,
replay_buffer_capacity
)
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpem6la471. [reverb/cc/platform/tfrecord_checkpointer.cc:385] Loading latest checkpoint from /tmp/tmpem6la471 [reverb/cc/platform/default/server.cc:71] Started replay server on port 19822
대부분의 에이전트를 들어, collect_data_spec A는 Trajectory 관찰, 행동을 포함하는 튜플의 이름 등, 보상
데이터 수집
REINFORCE는 전체 에피소드에서 학습하므로 주어진 데이터 수집 정책을 사용하여 에피소드를 수집하고 데이터(관찰, 액션, 보상 등)를 재생 버퍼의 궤적으로 저장하는 함수를 정의합니다. 여기서 우리는 경험 수집 루프를 실행하기 위해 'PyDriver'를 사용하고 있습니다. 당신은 우리의 더 많은 TF 에이전트 드라이버에 대한 배울 수있는 드라이버 튜토리얼 .
def collect_episode(environment, policy, num_episodes):
driver = py_driver.PyDriver(
environment,
py_tf_eager_policy.PyTFEagerPolicy(
policy, use_tf_function=True),
[rb_observer],
max_episodes=num_episodes)
initial_time_step = environment.reset()
driver.run(initial_time_step)
에이전트 교육
훈련 루프에는 환경에서 데이터를 수집하고 에이전트의 네트워크를 최적화하는 작업이 모두 포함됩니다. 그 과정에서 때때로 에이전트의 정책을 평가하여 우리가 어떻게 하고 있는지 확인할 것입니다.
다음은 실행하는 데 ~3분 정도 걸립니다.
try:
%%time
except:
pass
# (Optional) Optimize by wrapping some of the code in a graph using TF function.
tf_agent.train = common.function(tf_agent.train)
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = compute_avg_return(eval_env, tf_agent.policy, num_eval_episodes)
returns = [avg_return]
for _ in range(num_iterations):
# Collect a few episodes using collect_policy and save to the replay buffer.
collect_episode(
train_py_env, tf_agent.collect_policy, collect_episodes_per_iteration)
# Use data from the buffer and update the agent's network.
iterator = iter(replay_buffer.as_dataset(sample_batch_size=1))
trajectories, _ = next(iterator)
train_loss = tf_agent.train(experience=trajectories)
replay_buffer.clear()
step = tf_agent.train_step_counter.numpy()
if step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, train_loss.loss))
if step % eval_interval == 0:
avg_return = compute_avg_return(eval_env, tf_agent.policy, num_eval_episodes)
print('step = {0}: Average Return = {1}'.format(step, avg_return))
returns.append(avg_return)
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 25: loss = 0.8549901247024536 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 50: loss = 1.0025296211242676 step = 50: Average Return = 23.200000762939453 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 75: loss = 1.1377763748168945 step = 100: loss = 1.318871021270752 step = 100: Average Return = 159.89999389648438 step = 125: loss = 1.5053682327270508 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 150: loss = 0.8051948547363281 step = 150: Average Return = 184.89999389648438 step = 175: loss = 0.6872963905334473 step = 200: loss = 2.7238712310791016 step = 200: Average Return = 186.8000030517578 step = 225: loss = 0.7495002746582031 step = 250: loss = -0.3333401679992676 step = 250: Average Return = 200.0
심상
플롯
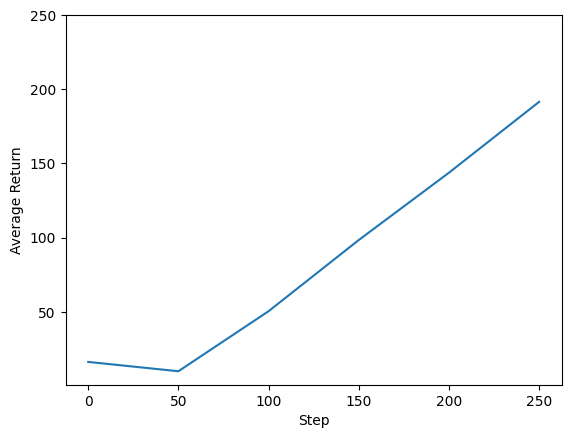
에이전트의 성능을 보기 위해 반환 대 글로벌 단계를 플롯할 수 있습니다. 에서는 Cartpole-v0 , 환경마다 단계에 극 체류를 +1의 보상을 제공하고, 단계의 최대 수가 200이기 때문에, 최대 가능도 창 (200)이다.
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim(top=250)
(-0.2349997997283939, 250.0)
비디오
각 단계에서 환경을 렌더링하여 에이전트의 성능을 시각화하는 데 도움이 됩니다. 그 전에 먼저 이 colab에 동영상을 삽입하는 함수를 만들어 보겠습니다.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
다음 코드는 몇 가지 에피소드에 대한 에이전트의 정책을 시각화합니다.
num_episodes = 3
video_filename = 'imageio.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_py_env.render())
while not time_step.is_last():
action_step = tf_agent.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_py_env.render())
embed_mp4(video_filename)
WARNING:root:IMAGEIO FFMPEG_WRITER WARNING: input image is not divisible by macro_block_size=16, resizing from (400, 600) to (400, 608) to ensure video compatibility with most codecs and players. To prevent resizing, make your input image divisible by the macro_block_size or set the macro_block_size to None (risking incompatibility). You may also see a FFMPEG warning concerning speedloss due to data not being aligned. [swscaler @ 0x5604d224f3c0] Warning: data is not aligned! This can lead to a speed loss