
Copyright 2021 TF 에이전트 작성자.
| | |  GitHub에서 소스 보기 GitHub에서 소스 보기 | |
소개
이 예제 프로그램은 어떻게 훈련하는 소프트 배우 평론가 온 에이전트를 Minitaur의 환경을 제공합니다.
당신은을 통해 작업 한 경우 DQN Colab 이 매우 익숙해야한다. 주목할만한 변경 사항은 다음과 같습니다.
- 에이전트를 DQN에서 SAC로 변경합니다.
- CartPole보다 훨씬 복잡한 환경인 Minitaur에 대한 교육. Minitaur 환경은 4족 보행 로봇을 훈련시켜 앞으로 나아가는 것을 목표로 합니다.
- 분산 강화 학습을 위한 TF-Agents Actor-Learner API 사용.
API는 경험 재생 버퍼와 가변 컨테이너(매개변수 서버)를 사용한 분산 데이터 수집과 여러 장치에 걸친 분산 교육을 모두 지원합니다. API는 매우 간단하고 모듈식으로 설계되었습니다. 우리는 활용 잔향을 재생 버퍼와 변수 컨테이너와 모두 TF DistributionStrategy의 API 의 GPU와 TPU를에 분산 훈련.
다음 종속성을 설치하지 않은 경우 다음을 실행합니다.
sudo apt-get updatesudo apt-get install -y xvfb ffmpegpip install 'imageio==2.4.0'pip install matplotlibpip install tf-agents[reverb]pip install pybullet
설정
먼저 필요한 다양한 도구를 가져옵니다.
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import os
import reverb
import tempfile
import PIL.Image
import tensorflow as tf
from tf_agents.agents.ddpg import critic_network
from tf_agents.agents.sac import sac_agent
from tf_agents.agents.sac import tanh_normal_projection_network
from tf_agents.environments import suite_pybullet
from tf_agents.metrics import py_metrics
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import greedy_policy
from tf_agents.policies import py_tf_eager_policy
from tf_agents.policies import random_py_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.train import actor
from tf_agents.train import learner
from tf_agents.train import triggers
from tf_agents.train.utils import spec_utils
from tf_agents.train.utils import strategy_utils
from tf_agents.train.utils import train_utils
tempdir = tempfile.gettempdir()
초매개변수
env_name = "MinitaurBulletEnv-v0" # @param {type:"string"}
# Use "num_iterations = 1e6" for better results (2 hrs)
# 1e5 is just so this doesn't take too long (1 hr)
num_iterations = 100000 # @param {type:"integer"}
initial_collect_steps = 10000 # @param {type:"integer"}
collect_steps_per_iteration = 1 # @param {type:"integer"}
replay_buffer_capacity = 10000 # @param {type:"integer"}
batch_size = 256 # @param {type:"integer"}
critic_learning_rate = 3e-4 # @param {type:"number"}
actor_learning_rate = 3e-4 # @param {type:"number"}
alpha_learning_rate = 3e-4 # @param {type:"number"}
target_update_tau = 0.005 # @param {type:"number"}
target_update_period = 1 # @param {type:"number"}
gamma = 0.99 # @param {type:"number"}
reward_scale_factor = 1.0 # @param {type:"number"}
actor_fc_layer_params = (256, 256)
critic_joint_fc_layer_params = (256, 256)
log_interval = 5000 # @param {type:"integer"}
num_eval_episodes = 20 # @param {type:"integer"}
eval_interval = 10000 # @param {type:"integer"}
policy_save_interval = 5000 # @param {type:"integer"}
환경
RL의 환경은 우리가 해결하려는 작업이나 문제를 나타냅니다. 표준 환경을 사용하여 쉽게 TF-에이전트에서 생성 될 수있다 suites . 우리는 서로 다른이 suites 문자열 환경 이름 부여, 등 등 OpenAI 체육관, 아타리, DM 제어, 같은 소스에서 환경을 로딩한다.
이제 Pybullet 제품군에서 Minituar 환경을 로드해 보겠습니다.
env = suite_pybullet.load(env_name)
env.reset()
PIL.Image.fromarray(env.render())
pybullet build time: Oct 11 2021 20:59:00
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/gym/spaces/box.py:74: UserWarning: WARN: Box bound precision lowered by casting to float32
"Box bound precision lowered by casting to {}".format(self.dtype)
current_dir=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_envs/bullet
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data

이 환경에서 목표는 에이전트가 Minitaur 로봇을 제어하고 가능한 한 빨리 앞으로 나아가도록 하는 정책을 훈련하는 것입니다. 에피소드는 1000단계로 진행되며 반환 금액은 에피소드 전체의 보상 합계입니다.
정보에서 살펴 보자 환경은로 제공 observation 정책을 생성하는 데 사용할 actions .
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(28,), dtype=dtype('float32'), name='observation', minimum=[ -3.1515927 -3.1515927 -3.1515927 -3.1515927 -3.1515927
-3.1515927 -3.1515927 -3.1515927 -167.72488 -167.72488
-167.72488 -167.72488 -167.72488 -167.72488 -167.72488
-167.72488 -5.71 -5.71 -5.71 -5.71
-5.71 -5.71 -5.71 -5.71 -1.01
-1.01 -1.01 -1.01 ], maximum=[ 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927
3.1515927 3.1515927 167.72488 167.72488 167.72488 167.72488
167.72488 167.72488 167.72488 167.72488 5.71 5.71
5.71 5.71 5.71 5.71 5.71 5.71
1.01 1.01 1.01 1.01 ])
Action Spec:
BoundedArraySpec(shape=(8,), dtype=dtype('float32'), name='action', minimum=-1.0, maximum=1.0)
관찰은 상당히 복잡합니다. 모든 모터에 대한 각도, 속도 및 토크를 나타내는 28개의 값을 받습니다. 창에서 환경의 작업 8 개 기대 값 [-1, 1] . 이것은 원하는 모터 각도입니다.
일반적으로 교육 중 데이터 수집을 위한 환경과 평가를 위한 환경의 두 가지 환경을 만듭니다. 환경은 순수 파이썬으로 작성되었으며 Actor Learner API가 직접 사용하는 numpy 배열을 사용합니다.
collect_env = suite_pybullet.load(env_name)
eval_env = suite_pybullet.load(env_name)
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data
유통전략
우리는 DistributionStrategy API를 사용하여 데이터 병렬 처리를 사용하는 여러 GPU 또는 TPU와 같은 여러 장치에서 기차 단계 계산을 실행할 수 있습니다. 기차 단계:
- 훈련 데이터 일괄 수신
- 장치 간에 분할
- 전진 단계를 계산합니다.
- 손실의 평균을 집계하고 계산합니다.
- 후진 단계를 계산하고 기울기 변수 업데이트를 수행합니다.
TF-Agents Learner API 및 DistributionStrategy API를 사용하면 아래 훈련 로직을 변경하지 않고도 GPU에서 훈련 단계 실행(MirroredStrategy 사용)에서 TPU(TPUStrategy 사용)로 전환하는 것이 매우 쉽습니다.
GPU 활성화
GPU에서 실행을 시도하려면 먼저 노트북에 GPU를 활성화해야 합니다.
- 편집→노트북 설정으로 이동합니다.
- 하드웨어 가속기 드롭다운에서 GPU 선택
전략 선택
사용 strategy_utils 전략을 생성 할 수 있습니다. 후드 아래에서 매개변수를 전달합니다.
-
use_gpu = False반환tf.distribute.get_strategy()CPU를 사용, -
use_gpu = True반환을tf.distribute.MirroredStrategy()하나 개의 시스템에 TensorFlow에 보이는 모든 GPU를 사용,
use_gpu = True
strategy = strategy_utils.get_strategy(tpu=False, use_gpu=use_gpu)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
모든 변수와 에이전트에서 생성해야 strategy.scope() 아래 살펴 보 겠지만,.
에이전트
SAC 에이전트를 생성하려면 먼저 훈련할 네트워크를 생성해야 합니다. SAC는 행위자 비평가 에이전트이므로 두 개의 네트워크가 필요합니다.
비평가는 우리에게 가치 추정치를 줄 것이다 Q(s,a) . 즉, 입력으로 관찰 및 조치를 수신하고 해당 조치가 주어진 상태에 대해 얼마나 좋은지에 대한 추정치를 제공합니다.
observation_spec, action_spec, time_step_spec = (
spec_utils.get_tensor_specs(collect_env))
with strategy.scope():
critic_net = critic_network.CriticNetwork(
(observation_spec, action_spec),
observation_fc_layer_params=None,
action_fc_layer_params=None,
joint_fc_layer_params=critic_joint_fc_layer_params,
kernel_initializer='glorot_uniform',
last_kernel_initializer='glorot_uniform')
우리는 훈련이 비평가를 사용 actor 우리가 관찰을 주어진 작업을 생성 할 수 있도록 네트워크를.
ActorNetwork TANH - 숙청에 대한 매개 변수를 예측합니다 MultivariateNormalDiag의 유통. 그런 다음 이 분포는 작업을 생성해야 할 때마다 현재 관찰에 따라 샘플링됩니다.
with strategy.scope():
actor_net = actor_distribution_network.ActorDistributionNetwork(
observation_spec,
action_spec,
fc_layer_params=actor_fc_layer_params,
continuous_projection_net=(
tanh_normal_projection_network.TanhNormalProjectionNetwork))
이러한 네트워크를 사용하여 이제 에이전트를 인스턴스화할 수 있습니다.
with strategy.scope():
train_step = train_utils.create_train_step()
tf_agent = sac_agent.SacAgent(
time_step_spec,
action_spec,
actor_network=actor_net,
critic_network=critic_net,
actor_optimizer=tf.keras.optimizers.Adam(
learning_rate=actor_learning_rate),
critic_optimizer=tf.keras.optimizers.Adam(
learning_rate=critic_learning_rate),
alpha_optimizer=tf.keras.optimizers.Adam(
learning_rate=alpha_learning_rate),
target_update_tau=target_update_tau,
target_update_period=target_update_period,
td_errors_loss_fn=tf.math.squared_difference,
gamma=gamma,
reward_scale_factor=reward_scale_factor,
train_step_counter=train_step)
tf_agent.initialize()
재생 버퍼
환경에서 수집 된 데이터를 추적하기 위해, 우리는 사용하는 리버브 (Reverb) , Deepmind하여, 효율적으로 확장, 사용하기 쉬운 재생 시스템. Actor가 수집하고 학습 중에 학습자가 소비하는 경험 데이터를 저장합니다.
이 튜토리얼에서는,이보다 중요 max_size -하지만 비동기 수집 및 훈련 분산 환경에서, 당신은 아마 실험 할 것 rate_limiters.SampleToInsertRatio 예를 들어 2와 1000 사이 samples_per_insert의 어딘가를 사용하여 :
rate_limiter=reverb.rate_limiters.SampleToInsertRatio(samples_per_insert=3.0, min_size_to_sample=3, error_buffer=3.0)
table_name = 'uniform_table'
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1))
reverb_server = reverb.Server([table])
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpl579aohk. [reverb/cc/platform/tfrecord_checkpointer.cc:386] Loading latest checkpoint from /tmp/tmpl579aohk [reverb/cc/platform/default/server.cc:71] Started replay server on port 15652
재생 버퍼를 사용하여 에이전트로부터 얻어 질 수 저장할 수있는 텐서, 기술 사양하여 구성된다 tf_agent.collect_data_spec .
SAC를 에이전트가 현재와 손실을 계산하기 위해 다음 관찰 모두를 필요로하기 때문에, 우리는 설정 sequence_length=2 .
reverb_replay = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
sequence_length=2,
table_name=table_name,
local_server=reverb_server)
이제 Reverb 재생 버퍼에서 TensorFlow 데이터 세트를 생성합니다. 우리는 이것을 학습자에게 전달하여 훈련을 위한 샘플 경험을 할 것입니다.
dataset = reverb_replay.as_dataset(
sample_batch_size=batch_size, num_steps=2).prefetch(50)
experience_dataset_fn = lambda: dataset
정책
TF-에이전트에서 정책 RL에 정책의 기본 개념을 나타냅니다 : 주어진 time_step 동작이나 행동에 걸쳐 분포를 생산하고 있습니다. 주요 방법은 policy_step = policy.step(time_step) policy_step 명명 튜플이다 PolicyStep(action, state, info) . policy_step.action 는 IS action 환경에 적용되는, state 상태 (RNN) 정책에 대한 나타내는 상태 info 예를 들면 작업 로그 확률로 보조 정보를 포함 할 수있다.
에이전트에는 두 가지 정책이 포함됩니다.
-
agent.policy- 평가 및 배포에 사용되는 주요 정책. -
agent.collect_policy- 데이터 수집에 사용되는 제 2 정책.
tf_eval_policy = tf_agent.policy
eval_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_eval_policy, use_tf_function=True)
tf_collect_policy = tf_agent.collect_policy
collect_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_collect_policy, use_tf_function=True)
정책은 에이전트와 독립적으로 생성할 수 있습니다. 예를 들어, 사용 tf_agents.policies.random_py_policy 무작위로 각 time_step에 대한 작업을 선택하는 정책을 만들 수 있습니다.
random_policy = random_py_policy.RandomPyPolicy(
collect_env.time_step_spec(), collect_env.action_spec())
배우
행위자는 정책과 환경 간의 상호 작용을 관리합니다.
- 액터 성분 (로 환경의 예를 포함
py_environment) 및 정책 변수 사본. - 각 Actor 작업자는 정책 변수의 로컬 값이 주어지면 일련의 데이터 수집 단계를 실행합니다.
- 변수 업데이트를 호출하기 전에 명시 적으로 훈련 스크립트에서 변수 컨테이너 클라이언트 인스턴스를 사용하여 수행하는
actor.run(). - 관찰된 경험은 각 데이터 수집 단계에서 재생 버퍼에 기록됩니다.
액터는 데이터 수집 단계를 실행할 때 (상태, 행동, 보상)의 궤적을 관찰자에게 전달하고 관찰자는 이를 Reverb 재생 시스템에 캐시하고 기록합니다.
우리는 프레임에 대해 궤도를 저장하고 [(T0, T1) (T1, T2) (T2, T3), ...] 때문에 stride_length=1 .
rb_observer = reverb_utils.ReverbAddTrajectoryObserver(
reverb_replay.py_client,
table_name,
sequence_length=2,
stride_length=1)
무작위 정책으로 Actor를 만들고 리플레이 버퍼를 시드할 경험을 수집합니다.
initial_collect_actor = actor.Actor(
collect_env,
random_policy,
train_step,
steps_per_run=initial_collect_steps,
observers=[rb_observer])
initial_collect_actor.run()
학습 중에 더 많은 경험을 수집하기 위해 수집 정책으로 액터를 인스턴스화합니다.
env_step_metric = py_metrics.EnvironmentSteps()
collect_actor = actor.Actor(
collect_env,
collect_policy,
train_step,
steps_per_run=1,
metrics=actor.collect_metrics(10),
summary_dir=os.path.join(tempdir, learner.TRAIN_DIR),
observers=[rb_observer, env_step_metric])
훈련 중에 정책을 평가하는 데 사용할 액터를 만듭니다. 우리는 전달 actor.eval_metrics(num_eval_episodes) 나중에 통계를 기록 할 수 있습니다.
eval_actor = actor.Actor(
eval_env,
eval_policy,
train_step,
episodes_per_run=num_eval_episodes,
metrics=actor.eval_metrics(num_eval_episodes),
summary_dir=os.path.join(tempdir, 'eval'),
)
학습자
학습자 구성 요소는 에이전트를 포함하고 재생 버퍼의 경험 데이터를 사용하여 정책 변수에 대한 기울기 단계 업데이트를 수행합니다. 하나 이상의 훈련 단계 후에 학습자는 새로운 변수 값 세트를 변수 컨테이너에 푸시할 수 있습니다.
saved_model_dir = os.path.join(tempdir, learner.POLICY_SAVED_MODEL_DIR)
# Triggers to save the agent's policy checkpoints.
learning_triggers = [
triggers.PolicySavedModelTrigger(
saved_model_dir,
tf_agent,
train_step,
interval=policy_save_interval),
triggers.StepPerSecondLogTrigger(train_step, interval=1000),
]
agent_learner = learner.Learner(
tempdir,
train_step,
tf_agent,
experience_dataset_fn,
triggers=learning_triggers,
strategy=strategy)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' 2021-12-01 12:19:19.139118: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/policy/assets INFO:tensorflow:Assets written to: /tmp/policies/policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:561: UserWarning: Encoding a StructuredValue with type tf_agents.policies.greedy_policy.DeterministicWithLogProb_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered. "imported and registered." % type_spec_class_name) INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function
측정항목 및 평가
우리는 함께 평가 배우 인스턴스화 actor.eval_metrics 정책 평가 중에 가장 일반적으로 사용되는 지표를 만들어 위를 :
- 평균 수익. 수익은 에피소드에 대한 환경에서 정책을 실행하는 동안 얻은 보상의 합계이며 일반적으로 몇 에피소드에 걸쳐 이를 평균화합니다.
- 평균 에피소드 길이.
액터를 실행하여 이러한 메트릭을 생성합니다.
def get_eval_metrics():
eval_actor.run()
results = {}
for metric in eval_actor.metrics:
results[metric.name] = metric.result()
return results
metrics = get_eval_metrics()
def log_eval_metrics(step, metrics):
eval_results = (', ').join(
'{} = {:.6f}'.format(name, result) for name, result in metrics.items())
print('step = {0}: {1}'.format(step, eval_results))
log_eval_metrics(0, metrics)
step = 0: AverageReturn = -0.963870, AverageEpisodeLength = 204.100006
아웃 확인 측정 모듈 다른 메트릭의 다른 표준 구현을.
에이전트 교육
훈련 루프에는 환경에서 데이터를 수집하고 에이전트의 네트워크를 최적화하는 작업이 모두 포함됩니다. 그 과정에서 때때로 에이전트의 정책을 평가하여 우리가 어떻게 하고 있는지 확인할 것입니다.
try:
%%time
except:
pass
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = get_eval_metrics()["AverageReturn"]
returns = [avg_return]
for _ in range(num_iterations):
# Training.
collect_actor.run()
loss_info = agent_learner.run(iterations=1)
# Evaluating.
step = agent_learner.train_step_numpy
if eval_interval and step % eval_interval == 0:
metrics = get_eval_metrics()
log_eval_metrics(step, metrics)
returns.append(metrics["AverageReturn"])
if log_interval and step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, loss_info.loss.numpy()))
rb_observer.close()
reverb_server.stop()
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. step = 5000: loss = -50.77360153198242 step = 10000: AverageReturn = -0.734191, AverageEpisodeLength = 299.399994 step = 10000: loss = -57.17308044433594 step = 15000: loss = -31.02552032470703 step = 20000: AverageReturn = -1.243302, AverageEpisodeLength = 432.200012 step = 20000: loss = -20.673084259033203 step = 25000: loss = -12.919441223144531 step = 30000: AverageReturn = -0.205654, AverageEpisodeLength = 280.049988 step = 30000: loss = -5.420497417449951 step = 35000: loss = -4.320608139038086 step = 40000: AverageReturn = -1.193502, AverageEpisodeLength = 378.000000 step = 40000: loss = -4.375732421875 step = 45000: loss = -3.0430049896240234 step = 50000: AverageReturn = -1.299686, AverageEpisodeLength = 482.549988 step = 50000: loss = -0.8907612562179565 step = 55000: loss = 1.2096503973007202 step = 60000: AverageReturn = -0.949927, AverageEpisodeLength = 365.899994 step = 60000: loss = 1.8157628774642944 step = 65000: loss = -4.9070353507995605 step = 70000: AverageReturn = -0.644635, AverageEpisodeLength = 506.399994 step = 70000: loss = -0.33166465163230896 step = 75000: loss = -0.41273507475852966 step = 80000: AverageReturn = 0.331935, AverageEpisodeLength = 604.299988 step = 80000: loss = 1.5354682207107544 step = 85000: loss = -2.058459997177124 step = 90000: AverageReturn = 0.292840, AverageEpisodeLength = 520.450012 step = 90000: loss = 1.2136361598968506 step = 95000: loss = -1.810737133026123 step = 100000: AverageReturn = 0.835265, AverageEpisodeLength = 515.349976 step = 100000: loss = -2.6997461318969727 [reverb/cc/platform/default/server.cc:84] Shutting down replay server
심상
플롯
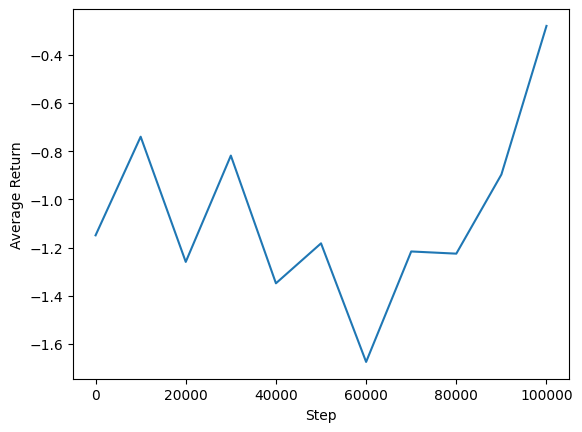
에이전트의 성과를 보기 위해 평균 수익 대 글로벌 단계를 플롯할 수 있습니다. 에서 Minitaur , 보상 기능은 minitaur 1000 단계에서 산책과 에너지 소비를 처벌 얼마나을 기반으로합니다.
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim()
(-1.4064332604408265, 0.9420127034187317)
비디오
각 단계에서 환경을 렌더링하여 에이전트의 성능을 시각화하는 데 도움이 됩니다. 그 전에 먼저 이 colab에 동영상을 삽입하는 함수를 만들어 보겠습니다.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
다음 코드는 몇 가지 에피소드에 대한 에이전트의 정책을 시각화합니다.
num_episodes = 3
video_filename = 'sac_minitaur.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_env.render())
while not time_step.is_last():
action_step = eval_actor.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_env.render())
embed_mp4(video_filename)