
Copyright 2020 TF-Agents 작성자.
시작하다
| | |  GitHub에서 소스 보기 GitHub에서 소스 보기 | |
설정
다음 종속성을 설치하지 않은 경우 다음을 실행합니다.
pip install tf-agents
수입품
import abc
import numpy as np
import tensorflow as tf
from tf_agents.agents import tf_agent
from tf_agents.drivers import driver
from tf_agents.environments import py_environment
from tf_agents.environments import tf_environment
from tf_agents.environments import tf_py_environment
from tf_agents.policies import tf_policy
from tf_agents.specs import array_spec
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
from tf_agents.trajectories import trajectory
from tf_agents.trajectories import policy_step
nest = tf.nest
소개
MAB(Multi-Armed Bandit problem)는 강화 학습의 특별한 경우입니다. 에이전트는 환경의 일부 상태를 관찰한 후 몇 가지 조치를 취하여 환경에서 보상을 수집합니다. 일반 RL과 MAB의 주요 차이점은 MAB에서 에이전트가 취한 조치가 환경의 다음 상태에 영향을 미치지 않는다고 가정한다는 것입니다. 따라서 에이전트는 상태 전환을 모델링하거나 과거 작업에 대한 보상을 제공하거나 보상이 풍부한 상태에 도달하기 위해 "미리 계획"하지 않습니다.
다른 RL 도메인에서 같이, MAB 에이전트의 목표는 정책을 발견하는 것입니다를 수집 가능한 한 많은 보상의 의미로. 그러나 항상 가장 높은 보상을 약속하는 행동을 이용하려고 하는 것은 실수일 것입니다. 왜냐하면 충분히 탐색하지 않으면 더 나은 행동을 놓칠 가능성이 있기 때문입니다. 이것은 종종 탐사 개발의 딜레마라고 (MAB)에서 해결해야 할 주요 문제입니다.
MAB에 대한 도적 환경, 정책 및 에이전트는의 하위 디렉토리에서 찾을 수 있습니다 tf_agents / 산적 .
환경
TF 에이전트에서, 환경 클래스는 입력으로서 동작을 수신하는 상태 전이를 수행하고, 보상을 출력한다 (이것은 관찰 또는 컨텍스트라고 함)의 현재 상태에 대한 정보를 제공하는 역할을 제공. 이 클래스는 또한 에피소드가 끝날 때 재설정을 처리하여 새 에피소드를 시작할 수 있습니다. 이것은 호출에 의해 실현된다 reset 상태가 에피소드의 "마지막"으로 표시 될 때 기능.
자세한 내용은 참조 TF-에이전트 환경 튜토리얼 .
위에서 언급했듯이 MAB는 행동이 다음 관찰에 영향을 미치지 않는다는 점에서 일반 RL과 다릅니다. 또 다른 차이점은 Bandits에는 "에피소드"가 없다는 것입니다. 모든 시간 단계는 이전 시간 단계와 관계없이 새로운 관찰로 시작됩니다.
반드시 관찰 독립적이고 추상적 멀리 RL 에피소드의 개념에 꼭 확인하기 위해, 우리는의 서브 클래스 소개 PyEnvironment 및 TFEnvironment : BanditPyEnvironment 및 BanditTFEnvironment을 . 이러한 클래스는 사용자가 구현해야 하는 두 개의 비공개 멤버 함수를 노출합니다.
@abc.abstractmethod
def _observe(self):
그리고
@abc.abstractmethod
def _apply_action(self, action):
_observe 기능은 관측을 반환합니다. 그런 다음 정책은 이 관찰을 기반으로 작업을 선택합니다. _apply_action 입력으로서 그 동작을 수신하고, 상응하는 보상을 반환한다. 이 개인 멤버 함수는 함수가 호출하는 reset 및 step 각각.
class BanditPyEnvironment(py_environment.PyEnvironment):
def __init__(self, observation_spec, action_spec):
self._observation_spec = observation_spec
self._action_spec = action_spec
super(BanditPyEnvironment, self).__init__()
# Helper functions.
def action_spec(self):
return self._action_spec
def observation_spec(self):
return self._observation_spec
def _empty_observation(self):
return tf.nest.map_structure(lambda x: np.zeros(x.shape, x.dtype),
self.observation_spec())
# These two functions below should not be overridden by subclasses.
def _reset(self):
"""Returns a time step containing an observation."""
return ts.restart(self._observe(), batch_size=self.batch_size)
def _step(self, action):
"""Returns a time step containing the reward for the action taken."""
reward = self._apply_action(action)
return ts.termination(self._observe(), reward)
# These two functions below are to be implemented in subclasses.
@abc.abstractmethod
def _observe(self):
"""Returns an observation."""
@abc.abstractmethod
def _apply_action(self, action):
"""Applies `action` to the Environment and returns the corresponding reward.
"""
중간 추상 클래스를 구현 위 PyEnvironment 의 _reset 및 _step 기능과 추상적 인 기능을 노출 _observe 및 _apply_action 서브 클래스에 의해 구현된다.
간단한 예제 환경 클래스
다음 클래스는 관찰이 -2와 2 사이의 임의의 정수이고 3가지 가능한 행동(0, 1, 2)이 있고 보상이 행동과 관찰의 곱인 매우 간단한 환경을 제공합니다.
class SimplePyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
super(SimplePyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return action * self._observation
이제 우리는 이 환경을 사용하여 관찰을 받고 우리의 행동에 대한 보상을 받을 수 있습니다.
environment = SimplePyEnvironment()
observation = environment.reset().observation
print("observation: %d" % observation)
action = 2
print("action: %d" % action)
reward = environment.step(action).reward
print("reward: %f" % reward)
observation: -1 action: 2 reward: -2.000000
TF 환경
하나는 서브 클래스 산적 환경을 정의 할 수 있습니다 BanditTFEnvironment 하거나, 유사 RL 환경에, 하나는 정의 할 수 있습니다 BanditPyEnvironment 과 함께 포장 TFPyEnvironment . 간단하게 하기 위해 이 튜토리얼에서는 후자 옵션을 사용합니다.
tf_environment = tf_py_environment.TFPyEnvironment(environment)
정책
산적 문제의 정책은 RL 문제에서와 동일한 방식으로 작동합니다 : 그것은 입력으로 관찰 주어진 행동 (또는 행동의 분포를) 제공합니다.
자세한 내용은 참조 TF-에이전트 정책 튜토리얼 .
하나는 만들 수 있습니다 환경과 마찬가지로, 정책을 구성하는 두 가지 방법이 있습니다 PyPolicy 하고 그것을 포장 TFPyPolicy , 또는 직접 만들 TFPolicy . 여기서는 직접 방법을 선택합니다.
이 예는 매우 간단하기 때문에 최적의 정책을 수동으로 정의할 수 있습니다. 동작은 관측값의 부호에만 의존하며, 0이 음수이고 2이면 양수입니다.
class SignPolicy(tf_policy.TFPolicy):
def __init__(self):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
super(SignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return ()
def _action(self, time_step, policy_state, seed):
observation_sign = tf.cast(tf.sign(time_step.observation[0]), dtype=tf.int32)
action = observation_sign + 1
return policy_step.PolicyStep(action, policy_state)
이제 환경에서 관찰을 요청하고 정책을 호출하여 작업을 선택하면 환경에서 보상을 출력할 수 있습니다.
sign_policy = SignPolicy()
current_time_step = tf_environment.reset()
print('Observation:')
print (current_time_step.observation)
action = sign_policy.action(current_time_step).action
print('Action:')
print (action)
reward = tf_environment.step(action).reward
print('Reward:')
print(reward)
Observation: tf.Tensor([[2]], shape=(1, 1), dtype=int32) Action: tf.Tensor([2], shape=(1,), dtype=int32) Reward: tf.Tensor([[4.]], shape=(1, 1), dtype=float32)
bandit 환경이 구현되는 방식은 우리가 한 걸음 내디딜 때마다 우리가 취한 행동에 대한 보상뿐만 아니라 다음 관찰도 받을 수 있도록 합니다.
step = tf_environment.reset()
action = 1
next_step = tf_environment.step(action)
reward = next_step.reward
next_observation = next_step.observation
print("Reward: ")
print(reward)
print("Next observation:")
print(next_observation)
Reward: tf.Tensor([[-2.]], shape=(1, 1), dtype=float32) Next observation: tf.Tensor([[0]], shape=(1, 1), dtype=int32)
자치령 대표
이제 bandit 환경과 bandit 정책이 있으므로 훈련 샘플을 기반으로 정책 변경을 처리하는 bandit 에이전트도 정의해야 합니다.
산적 에이전트에 대한 API는 RL 에이전트의 그것과 다르지 않다 : 에이전트는 단지 구현해야 _initialize 및 _train 방법 및 정의 policy 과 collect_policy .
더 복잡한 환경
적기 에이전트를 작성하기 전에 파악하기 조금 더 어려운 환경이 필요합니다. 일을 조금 양념하려면 다음 환경 중 하나를 항상 줄 것이다 reward = observation * action 또는 reward = -observation * action . 이는 환경이 초기화될 때 결정됩니다.
class TwoWayPyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
# Flipping the sign with probability 1/2.
self._reward_sign = 2 * np.random.randint(2) - 1
print("reward sign:")
print(self._reward_sign)
super(TwoWayPyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return self._reward_sign * action * self._observation[0]
two_way_tf_environment = tf_py_environment.TFPyEnvironment(TwoWayPyEnvironment())
reward sign: -1
더 복잡한 정책
더 복잡한 환경은 더 복잡한 정책을 요구합니다. 기본 환경의 동작을 감지하는 정책이 필요합니다. 정책에서 처리해야 하는 세 가지 상황이 있습니다.
- 에이전트는 실행 중인 환경 버전을 아직 감지하지 못했습니다.
- 에이전트가 환경의 원래 버전이 실행되고 있음을 감지했습니다.
- 에이전트가 반전된 버전의 환경이 실행되고 있음을 감지했습니다.
우리는 정의 tf_variable 라는 _situation 있는 값으로 인코딩 된 정보를 저장하기 위해 [0, 2] 다음에, 이에 따라 정책을 동작합니다.
class TwoWaySignPolicy(tf_policy.TFPolicy):
def __init__(self, situation):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
self._situation = situation
super(TwoWaySignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return [self._situation]
def _action(self, time_step, policy_state, seed):
sign = tf.cast(tf.sign(time_step.observation[0, 0]), dtype=tf.int32)
def case_unknown_fn():
# Choose 1 so that we get information on the sign.
return tf.constant(1, shape=(1,))
# Choose 0 or 2, depending on the situation and the sign of the observation.
def case_normal_fn():
return tf.constant(sign + 1, shape=(1,))
def case_flipped_fn():
return tf.constant(1 - sign, shape=(1,))
cases = [(tf.equal(self._situation, 0), case_unknown_fn),
(tf.equal(self._situation, 1), case_normal_fn),
(tf.equal(self._situation, 2), case_flipped_fn)]
action = tf.case(cases, exclusive=True)
return policy_step.PolicyStep(action, policy_state)
에이전트
이제 환경의 징후를 감지하고 정책을 적절하게 설정하는 에이전트를 정의할 차례입니다.
class SignAgent(tf_agent.TFAgent):
def __init__(self):
self._situation = tf.Variable(0, dtype=tf.int32)
policy = TwoWaySignPolicy(self._situation)
time_step_spec = policy.time_step_spec
action_spec = policy.action_spec
super(SignAgent, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec,
policy=policy,
collect_policy=policy,
train_sequence_length=None)
def _initialize(self):
return tf.compat.v1.variables_initializer(self.variables)
def _train(self, experience, weights=None):
observation = experience.observation
action = experience.action
reward = experience.reward
# We only need to change the value of the situation variable if it is
# unknown (0) right now, and we can infer the situation only if the
# observation is not 0.
needs_action = tf.logical_and(tf.equal(self._situation, 0),
tf.not_equal(reward, 0))
def new_situation_fn():
"""This returns either 1 or 2, depending on the signs."""
return (3 - tf.sign(tf.cast(observation[0, 0, 0], dtype=tf.int32) *
tf.cast(action[0, 0], dtype=tf.int32) *
tf.cast(reward[0, 0], dtype=tf.int32))) / 2
new_situation = tf.cond(needs_action,
new_situation_fn,
lambda: self._situation)
new_situation = tf.cast(new_situation, tf.int32)
tf.compat.v1.assign(self._situation, new_situation)
return tf_agent.LossInfo((), ())
sign_agent = SignAgent()
위의 코드에서, 에이전트는 정책을 정의하고, 변수 situation 에이전트와 정책에 의해 공유됩니다.
또한, 매개 변수 experience 의 _train 기능은 궤도이다 :
궤적
TF-에이전트에서 trajectories 촬영 이전 단계에서 샘플을 포함하는 튜플을 지정됩니다. 그런 다음 에이전트는 이러한 샘플을 사용하여 정책을 훈련하고 업데이트합니다. RL에서 궤적은 현재 상태, 다음 상태 및 현재 에피소드가 종료되었는지 여부에 대한 정보를 포함해야 합니다. Bandit 세계에서는 이러한 것들이 필요하지 않기 때문에 궤적을 생성하는 도우미 함수를 설정합니다.
# We need to add another dimension here because the agent expects the
# trajectory of shape [batch_size, time, ...], but in this tutorial we assume
# that both batch size and time are 1. Hence all the expand_dims.
def trajectory_for_bandit(initial_step, action_step, final_step):
return trajectory.Trajectory(observation=tf.expand_dims(initial_step.observation, 0),
action=tf.expand_dims(action_step.action, 0),
policy_info=action_step.info,
reward=tf.expand_dims(final_step.reward, 0),
discount=tf.expand_dims(final_step.discount, 0),
step_type=tf.expand_dims(initial_step.step_type, 0),
next_step_type=tf.expand_dims(final_step.step_type, 0))
에이전트 교육
이제 모든 조각이 적기 요원을 훈련할 준비가 되었습니다.
step = two_way_tf_environment.reset()
for _ in range(10):
action_step = sign_agent.collect_policy.action(step)
next_step = two_way_tf_environment.step(action_step.action)
experience = trajectory_for_bandit(step, action_step, next_step)
print(experience)
sign_agent.train(experience)
step = next_step
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[0]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[1.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[2.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[4.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
출력에서 두 번째 단계 이후(첫 번째 단계에서 관찰이 0이 아닌 한) 정책이 올바른 방식으로 작업을 선택하므로 수집된 보상이 항상 음수가 아님을 알 수 있습니다.
실제 상황에 맞는 밴딧의 예
이 튜토리얼의 나머지 부분에서, 우리는 사전 구현 사용 환경 및 에이전트 TF-에이전트 도둑 라이브러리를.
# Imports for example.
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_py_environment as sspe
from tf_agents.bandits.metrics import tf_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.replay_buffers import tf_uniform_replay_buffer
import matplotlib.pyplot as plt
선형 보수 함수가 있는 고정 확률적 환경
이 예에서 사용되는 환경은이다 StationaryStochasticPyEnvironment . 이 환경은 매개변수로 관찰(컨텍스트)을 제공하는 함수(보통 잡음이 있음)를 취하고, 모든 팔에 대해 주어진 관찰을 기반으로 보상을 계산하는 (또한 잡음이 있는) 함수를 취합니다. 이 예에서는 d차원 큐브에서 컨텍스트를 균일하게 샘플링하고 보상 함수는 컨텍스트의 선형 함수에 가우시안 노이즈를 더한 것입니다.
batch_size = 2 # @param
arm0_param = [-3, 0, 1, -2] # @param
arm1_param = [1, -2, 3, 0] # @param
arm2_param = [0, 0, 1, 1] # @param
def context_sampling_fn(batch_size):
"""Contexts from [-10, 10]^4."""
def _context_sampling_fn():
return np.random.randint(-10, 10, [batch_size, 4]).astype(np.float32)
return _context_sampling_fn
class LinearNormalReward(object):
"""A class that acts as linear reward function when called."""
def __init__(self, theta, sigma):
self.theta = theta
self.sigma = sigma
def __call__(self, x):
mu = np.dot(x, self.theta)
return np.random.normal(mu, self.sigma)
arm0_reward_fn = LinearNormalReward(arm0_param, 1)
arm1_reward_fn = LinearNormalReward(arm1_param, 1)
arm2_reward_fn = LinearNormalReward(arm2_param, 1)
environment = tf_py_environment.TFPyEnvironment(
sspe.StationaryStochasticPyEnvironment(
context_sampling_fn(batch_size),
[arm0_reward_fn, arm1_reward_fn, arm2_reward_fn],
batch_size=batch_size))
LinUCB 에이전트
구현 아래의 에이전트 LinUCB의 알고리즘입니다.
observation_spec = tensor_spec.TensorSpec([4], tf.float32)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=2)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec)
후회 지표
도둑의 가장 중요한 통계는 에이전트에 의해 수집 된 보상과 환경의 보상 기능에 액세스 할 수있는 오라클 정책의 예상 보상의 차이로 계산 유감이다. RegretMetric는 따라서 관찰 중에서 가장 달성 예상 보상을 계산하는 baseline_reward_fn 기능을 필요로한다. 우리의 예에서는 환경에 대해 이미 정의한 보상 기능의 무잡음 등가물 중 최대값을 취해야 합니다.
def compute_optimal_reward(observation):
expected_reward_for_arms = [
tf.linalg.matvec(observation, tf.cast(arm0_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm1_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm2_param, dtype=tf.float32))]
optimal_action_reward = tf.reduce_max(expected_reward_for_arms, axis=0)
return optimal_action_reward
regret_metric = tf_metrics.RegretMetric(compute_optimal_reward)
훈련
이제 위에서 소개한 모든 구성 요소(환경, 정책 및 에이전트)를 모았습니다. 우리는 드라이버의 도움으로 환경과 출력 훈련 데이터에 대한 정책을 실행하고 데이터에 에이전트를 훈련.
수행한 단계 수를 함께 지정하는 두 개의 매개변수가 있습니다. num_iterations 드라이버가 소요됩니다 동안 우리가, 트레이너 루프를 실행 횟수를 지정 steps_per_loop 반복 당 단계를. 이 두 매개변수를 모두 유지하는 주된 이유는 일부 작업은 반복마다 수행되는 반면 일부는 모든 단계에서 드라이버가 수행하기 때문입니다. 예를 들어, 에이전트의 train 기능은 반복에 한 번이라고합니다. 여기서 절충안은 우리가 더 자주 훈련하면 정책이 "신선한" 반면에 더 큰 배치로 훈련하는 것이 더 시간 효율적일 수 있다는 것입니다.
num_iterations = 90 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=batch_size,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=environment,
policy=agent.collect_policy,
num_steps=steps_per_loop * batch_size,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
plt.plot(regret_values)
plt.ylabel('Average Regret')
plt.xlabel('Number of Iterations')
WARNING:tensorflow:From /tmp/ipykernel_11392/3138849230.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead. Text(0.5, 0, 'Number of Iterations')
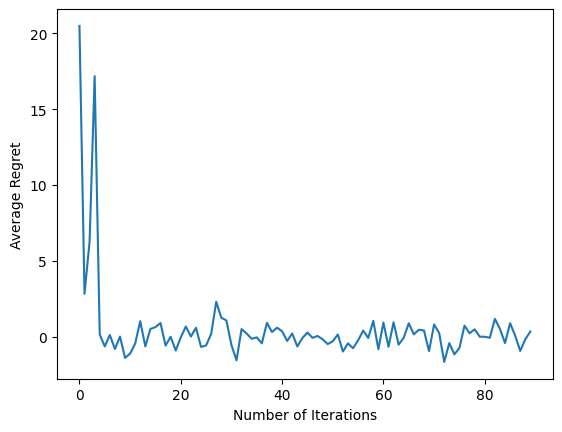
마지막 코드 조각을 실행한 후 결과 플롯은 에이전트가 훈련됨에 따라 평균 후회가 줄어들고 관찰이 주어진 경우 올바른 조치가 무엇인지 파악하는 데 정책이 향상됨을 보여줍니다.
무엇 향후 계획?
더 작업 예를 보려면 참조하십시오 도적 / 에이전트 / 예제 다른 에이전트와 환경에 바로 실행 가능한 예제가 디렉토리를.
TF-Agents 라이브러리는 팔당 기능이 있는 Multi-Armed Bandits도 처리할 수 있습니다. 이를 위해, 우리는 당 팔을 적기에 독자를 참조 자습서 .