
Bản quyền 2020 Các tác giả TF-Agents.
Bắt đầu
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Cài đặt
Nếu bạn chưa cài đặt các phần phụ thuộc sau, hãy chạy:
pip install tf-agents
Nhập khẩu
import abc
import numpy as np
import tensorflow as tf
from tf_agents.agents import tf_agent
from tf_agents.drivers import driver
from tf_agents.environments import py_environment
from tf_agents.environments import tf_environment
from tf_agents.environments import tf_py_environment
from tf_agents.policies import tf_policy
from tf_agents.specs import array_spec
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
from tf_agents.trajectories import trajectory
from tf_agents.trajectories import policy_step
nest = tf.nest
Giới thiệu
Bài toán Kẻ cướp đa vũ trang (MAB) là một trường hợp đặc biệt của Học tăng cường: một tác nhân thu thập phần thưởng trong một môi trường bằng cách thực hiện một số hành động sau khi quan sát một số trạng thái của môi trường. Sự khác biệt chính giữa RL nói chung và MAB là trong MAB, chúng tôi giả định rằng hành động được thực hiện bởi tác nhân không ảnh hưởng đến trạng thái tiếp theo của môi trường. Do đó, các đại lý không lập mô hình chuyển đổi trạng thái, phần thưởng tín dụng cho các hành động trong quá khứ, hoặc "lập kế hoạch trước" để đến các trạng thái giàu phần thưởng.
Như trong lĩnh vực RL khác, mục tiêu của một đại lý MAB là để tìm một chính sách thu thập như phần thưởng nhiều càng tốt. Tuy nhiên, sẽ là sai lầm nếu luôn cố gắng khai thác hành động hứa hẹn phần thưởng cao nhất, bởi vì sau đó có khả năng chúng ta bỏ lỡ những hành động tốt hơn nếu chúng ta không khám phá đủ. Đây là vấn đề chính để được giải quyết trong (MAB), thường được gọi là tiến thoái lưỡng nan thăm dò khai thác.
Môi trường Bandit, chính sách và đại lý cho MAB có thể được tìm thấy trong thư mục con của tf_agents / kẻ cướp .
Môi trường
Trong TF-Đại lý, lớp môi trường phục vụ vai trò của cung cấp thông tin về tình trạng hiện tại (điều này được gọi là quan sát hoặc ngữ cảnh), nhận một hành động như là đầu vào, thực hiện một chuyển trạng thái, và xuất một phần thưởng. Lớp này cũng đảm nhiệm việc đặt lại khi một tập kết thúc, để một tập mới có thể bắt đầu. Này được thực hiện bằng cách gọi một reset chức năng khi một nhà nước được dán nhãn là "cuối cùng" của tập phim.
Để biết thêm chi tiết, xem TF-Đại lý môi trường hướng dẫn .
Như đã đề cập ở trên, MAB khác với RL nói chung ở chỗ các hành động không ảnh hưởng đến quan sát tiếp theo. Một điểm khác biệt nữa là trong Bandits, không có "tập": mỗi bước thời gian bắt đầu với một quan sát mới, độc lập với các bước thời gian trước đó.
Để đảm bảo quan sát độc lập và đi trừu tượng khái niệm về tập RL, chúng tôi giới thiệu các lớp con của PyEnvironment và TFEnvironment : BanditPyEnvironment và BanditTFEnvironment . Các lớp này hiển thị hai hàm thành viên riêng tư vẫn được người dùng triển khai:
@abc.abstractmethod
def _observe(self):
và
@abc.abstractmethod
def _apply_action(self, action):
Các _observe hàm trả về một quan sát. Sau đó, chính sách chọn một hành động dựa trên quan sát này. Các _apply_action nhận rằng hành động như một đầu vào, và trả về phần thưởng tương ứng. Những chức năng thành viên tin được gọi bởi các chức năng reset và step , tương ứng.
class BanditPyEnvironment(py_environment.PyEnvironment):
def __init__(self, observation_spec, action_spec):
self._observation_spec = observation_spec
self._action_spec = action_spec
super(BanditPyEnvironment, self).__init__()
# Helper functions.
def action_spec(self):
return self._action_spec
def observation_spec(self):
return self._observation_spec
def _empty_observation(self):
return tf.nest.map_structure(lambda x: np.zeros(x.shape, x.dtype),
self.observation_spec())
# These two functions below should not be overridden by subclasses.
def _reset(self):
"""Returns a time step containing an observation."""
return ts.restart(self._observe(), batch_size=self.batch_size)
def _step(self, action):
"""Returns a time step containing the reward for the action taken."""
reward = self._apply_action(action)
return ts.termination(self._observe(), reward)
# These two functions below are to be implemented in subclasses.
@abc.abstractmethod
def _observe(self):
"""Returns an observation."""
@abc.abstractmethod
def _apply_action(self, action):
"""Applies `action` to the Environment and returns the corresponding reward.
"""
Trên dụng cụ lớp trừu tượng tạm PyEnvironment 's _reset và _step chức năng, cho thấy nhiều chức năng trừu tượng _observe và _apply_action được thực hiện bởi lớp con.
Một lớp môi trường ví dụ đơn giản
Lớp sau đưa ra một môi trường rất đơn giản trong đó quan sát là một số nguyên ngẫu nhiên giữa -2 và 2, có 3 hành động có thể xảy ra (0, 1, 2) và phần thưởng là sản phẩm của hành động và quan sát.
class SimplePyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
super(SimplePyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return action * self._observation
Giờ đây, chúng ta có thể sử dụng môi trường này để quan sát và nhận phần thưởng cho các hành động của mình.
environment = SimplePyEnvironment()
observation = environment.reset().observation
print("observation: %d" % observation)
action = 2
print("action: %d" % action)
reward = environment.step(action).reward
print("reward: %f" % reward)
observation: -1 action: 2 reward: -2.000000
Môi trường TF
Người ta có thể định nghĩa một môi trường bandit bởi subclassing BanditTFEnvironment , hoặc, tương tự như môi trường RL, người ta có thể xác định một BanditPyEnvironment và quấn nó với TFPyEnvironment . Để đơn giản hơn, chúng tôi đi với tùy chọn thứ hai trong hướng dẫn này.
tf_environment = tf_py_environment.TFPyEnvironment(environment)
Chính sách
Một chính sách trong một vấn đề chia nhánh hoạt động theo cách tương tự như trong một vấn đề RL: nó cung cấp một hành động (hoặc một bản phân phối của các hành động), đưa ra một quan sát như là đầu vào.
Để biết thêm chi tiết, vui lòng xem hướng dẫn TF-Đại lý chính sách .
Như với môi trường, có hai cách để xây dựng một chính sách: Người ta có thể tạo ra một PyPolicy và quấn nó với TFPyPolicy , hoặc trực tiếp tạo ra một TFPolicy . Ở đây chúng tôi chọn đi với phương pháp trực tiếp.
Vì ví dụ này khá đơn giản, chúng ta có thể xác định chính sách tối ưu theo cách thủ công. Hành động chỉ phụ thuộc vào dấu hiệu của sự quan sát, 0 khi nào là tiêu cực và 2 khi là dương.
class SignPolicy(tf_policy.TFPolicy):
def __init__(self):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
super(SignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return ()
def _action(self, time_step, policy_state, seed):
observation_sign = tf.cast(tf.sign(time_step.observation[0]), dtype=tf.int32)
action = observation_sign + 1
return policy_step.PolicyStep(action, policy_state)
Bây giờ chúng ta có thể yêu cầu một quan sát từ môi trường, gọi chính sách để chọn một hành động, sau đó môi trường sẽ xuất ra phần thưởng:
sign_policy = SignPolicy()
current_time_step = tf_environment.reset()
print('Observation:')
print (current_time_step.observation)
action = sign_policy.action(current_time_step).action
print('Action:')
print (action)
reward = tf_environment.step(action).reward
print('Reward:')
print(reward)
Observation: tf.Tensor([[2]], shape=(1, 1), dtype=int32) Action: tf.Tensor([2], shape=(1,), dtype=int32) Reward: tf.Tensor([[4.]], shape=(1, 1), dtype=float32)
Cách môi trường kẻ cướp được thực hiện đảm bảo rằng mỗi khi chúng ta thực hiện một bước, chúng ta không chỉ nhận được phần thưởng cho hành động mà chúng ta đã thực hiện mà còn cả những lần quan sát tiếp theo.
step = tf_environment.reset()
action = 1
next_step = tf_environment.step(action)
reward = next_step.reward
next_observation = next_step.observation
print("Reward: ")
print(reward)
print("Next observation:")
print(next_observation)
Reward: tf.Tensor([[-2.]], shape=(1, 1), dtype=float32) Next observation: tf.Tensor([[0]], shape=(1, 1), dtype=int32)
Đại lý
Bây giờ chúng ta đã có môi trường cướp và các chính sách về băng cướp, đã đến lúc cần phải xác định các tác nhân cướp, đảm nhận việc thay đổi chính sách dựa trên các mẫu đào tạo.
API cho các đại lý tên cướp không khác với các đại lý RL: các đại lý chỉ cần thực hiện các _initialize và _train phương pháp, và xác định một policy và một collect_policy .
Một môi trường phức tạp hơn
Trước khi chúng tôi viết đặc vụ kẻ cướp của mình, chúng tôi cần có một môi trường khó tìm ra hơn một chút. Thêm gia vị cho những thứ chỉ là một chút, môi trường tiếp theo hoặc sẽ luôn luôn cung cấp cho reward = observation * action hoặc reward = -observation * action . Điều này sẽ được quyết định khi môi trường được khởi tạo.
class TwoWayPyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
# Flipping the sign with probability 1/2.
self._reward_sign = 2 * np.random.randint(2) - 1
print("reward sign:")
print(self._reward_sign)
super(TwoWayPyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return self._reward_sign * action * self._observation[0]
two_way_tf_environment = tf_py_environment.TFPyEnvironment(TwoWayPyEnvironment())
reward sign: -1
Chính sách phức tạp hơn
Một môi trường phức tạp hơn đòi hỏi một chính sách phức tạp hơn. Chúng tôi cần một chính sách phát hiện hành vi của môi trường bên dưới. Có ba tình huống mà chính sách cần xử lý:
- Tác nhân vẫn chưa phát hiện biết phiên bản môi trường đang chạy.
- Tác nhân phát hiện rằng phiên bản gốc của môi trường đang chạy.
- Tác nhân phát hiện rằng phiên bản bị lật của môi trường đang chạy.
Chúng ta định nghĩa một tf_variable tên _situation để lưu trữ thông tin này được mã hóa như các giá trị trong [0, 2] , sau đó tạo một hành vi chính sách cho phù hợp.
class TwoWaySignPolicy(tf_policy.TFPolicy):
def __init__(self, situation):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
self._situation = situation
super(TwoWaySignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return [self._situation]
def _action(self, time_step, policy_state, seed):
sign = tf.cast(tf.sign(time_step.observation[0, 0]), dtype=tf.int32)
def case_unknown_fn():
# Choose 1 so that we get information on the sign.
return tf.constant(1, shape=(1,))
# Choose 0 or 2, depending on the situation and the sign of the observation.
def case_normal_fn():
return tf.constant(sign + 1, shape=(1,))
def case_flipped_fn():
return tf.constant(1 - sign, shape=(1,))
cases = [(tf.equal(self._situation, 0), case_unknown_fn),
(tf.equal(self._situation, 1), case_normal_fn),
(tf.equal(self._situation, 2), case_flipped_fn)]
action = tf.case(cases, exclusive=True)
return policy_step.PolicyStep(action, policy_state)
Đại lý
Bây giờ đã đến lúc xác định tác nhân phát hiện dấu hiệu của môi trường và thiết lập chính sách một cách thích hợp.
class SignAgent(tf_agent.TFAgent):
def __init__(self):
self._situation = tf.Variable(0, dtype=tf.int32)
policy = TwoWaySignPolicy(self._situation)
time_step_spec = policy.time_step_spec
action_spec = policy.action_spec
super(SignAgent, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec,
policy=policy,
collect_policy=policy,
train_sequence_length=None)
def _initialize(self):
return tf.compat.v1.variables_initializer(self.variables)
def _train(self, experience, weights=None):
observation = experience.observation
action = experience.action
reward = experience.reward
# We only need to change the value of the situation variable if it is
# unknown (0) right now, and we can infer the situation only if the
# observation is not 0.
needs_action = tf.logical_and(tf.equal(self._situation, 0),
tf.not_equal(reward, 0))
def new_situation_fn():
"""This returns either 1 or 2, depending on the signs."""
return (3 - tf.sign(tf.cast(observation[0, 0, 0], dtype=tf.int32) *
tf.cast(action[0, 0], dtype=tf.int32) *
tf.cast(reward[0, 0], dtype=tf.int32))) / 2
new_situation = tf.cond(needs_action,
new_situation_fn,
lambda: self._situation)
new_situation = tf.cast(new_situation, tf.int32)
tf.compat.v1.assign(self._situation, new_situation)
return tf_agent.LossInfo((), ())
sign_agent = SignAgent()
Trong đoạn mã trên, các đại lý xác định chính sách, và biến situation được chia sẻ bởi các đại lý và chính sách.
Ngoài ra, các thông số experience của _train chức năng là một quỹ đạo:
Quỹ đạo
Trong TF-Đại lý, trajectories được đặt tên các tuple chứa mẫu từ bước trước đó thực hiện. Các mẫu này sau đó được đại lý sử dụng để đào tạo và cập nhật chính sách. Trong RL, quỹ đạo phải chứa thông tin về trạng thái hiện tại, trạng thái tiếp theo và liệu tập hiện tại đã kết thúc hay chưa. Vì trong thế giới Bandit, chúng tôi không cần những thứ này, chúng tôi thiết lập một chức năng trợ giúp để tạo quỹ đạo:
# We need to add another dimension here because the agent expects the
# trajectory of shape [batch_size, time, ...], but in this tutorial we assume
# that both batch size and time are 1. Hence all the expand_dims.
def trajectory_for_bandit(initial_step, action_step, final_step):
return trajectory.Trajectory(observation=tf.expand_dims(initial_step.observation, 0),
action=tf.expand_dims(action_step.action, 0),
policy_info=action_step.info,
reward=tf.expand_dims(final_step.reward, 0),
discount=tf.expand_dims(final_step.discount, 0),
step_type=tf.expand_dims(initial_step.step_type, 0),
next_step_type=tf.expand_dims(final_step.step_type, 0))
Đào tạo một đại lý
Bây giờ tất cả các phần đã sẵn sàng để đào tạo đặc vụ cướp của chúng tôi.
step = two_way_tf_environment.reset()
for _ in range(10):
action_step = sign_agent.collect_policy.action(step)
next_step = two_way_tf_environment.step(action_step.action)
experience = trajectory_for_bandit(step, action_step, next_step)
print(experience)
sign_agent.train(experience)
step = next_step
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[0]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[1.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[2.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[4.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Từ kết quả đầu ra, người ta có thể thấy rằng sau bước thứ hai (trừ khi quan sát là 0 ở bước đầu tiên), chính sách chọn hành động theo đúng cách và do đó phần thưởng thu được luôn không âm.
Một ví dụ về kẻ cướp theo ngữ cảnh thực tế
Trong phần còn lại của hướng dẫn này, chúng tôi sử dụng trước thực hiện môi trường và các đại lý của thư viện TF-Đại lý Bandits.
# Imports for example.
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_py_environment as sspe
from tf_agents.bandits.metrics import tf_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.replay_buffers import tf_uniform_replay_buffer
import matplotlib.pyplot as plt
Môi trường Stochastic tĩnh với các chức năng hoàn trả tuyến tính
Môi trường được sử dụng trong ví dụ này là StationaryStochasticPyEnvironment . Môi trường này nhận tham số a (thường là hàm ồn ào) để đưa ra các quan sát (ngữ cảnh) và đối với mọi nhánh nhận một hàm (cũng ồn ào) để tính toán phần thưởng dựa trên quan sát đã cho. Trong ví dụ của chúng tôi, chúng tôi lấy mẫu ngữ cảnh một cách thống nhất từ một khối lập phương d chiều và các hàm phần thưởng là các hàm tuyến tính của ngữ cảnh, cộng với một số nhiễu Gaussian.
batch_size = 2 # @param
arm0_param = [-3, 0, 1, -2] # @param
arm1_param = [1, -2, 3, 0] # @param
arm2_param = [0, 0, 1, 1] # @param
def context_sampling_fn(batch_size):
"""Contexts from [-10, 10]^4."""
def _context_sampling_fn():
return np.random.randint(-10, 10, [batch_size, 4]).astype(np.float32)
return _context_sampling_fn
class LinearNormalReward(object):
"""A class that acts as linear reward function when called."""
def __init__(self, theta, sigma):
self.theta = theta
self.sigma = sigma
def __call__(self, x):
mu = np.dot(x, self.theta)
return np.random.normal(mu, self.sigma)
arm0_reward_fn = LinearNormalReward(arm0_param, 1)
arm1_reward_fn = LinearNormalReward(arm1_param, 1)
arm2_reward_fn = LinearNormalReward(arm2_param, 1)
environment = tf_py_environment.TFPyEnvironment(
sspe.StationaryStochasticPyEnvironment(
context_sampling_fn(batch_size),
[arm0_reward_fn, arm1_reward_fn, arm2_reward_fn],
batch_size=batch_size))
Đại lý LinUCB
Các đại lý dưới đây thực hiện các LinUCB thuật toán.
observation_spec = tensor_spec.TensorSpec([4], tf.float32)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=2)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec)
Chỉ số tiếc nuối
Số liệu quan trọng nhất kẻ cướp là hối tiếc, tính bằng chênh lệch giữa phần thưởng được thu thập bởi các đại lý và phần thưởng dự kiến của một chính sách oracle có quyền truy cập vào các chức năng phần thưởng của môi trường. Các RegretMetric do đó cần có một chức năng baseline_reward_fn cho phép tính thưởng dự kiến có thể đạt được tốt nhất cho một quan sát. Đối với ví dụ của chúng tôi, chúng tôi cần lấy tối đa các hàm tương đương không nhiễu của các hàm phần thưởng mà chúng tôi đã xác định cho môi trường.
def compute_optimal_reward(observation):
expected_reward_for_arms = [
tf.linalg.matvec(observation, tf.cast(arm0_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm1_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm2_param, dtype=tf.float32))]
optimal_action_reward = tf.reduce_max(expected_reward_for_arms, axis=0)
return optimal_action_reward
regret_metric = tf_metrics.RegretMetric(compute_optimal_reward)
Đào tạo
Bây giờ chúng ta tập hợp tất cả các thành phần mà chúng ta đã giới thiệu ở trên: môi trường, chính sách và tác nhân. Chúng tôi chạy chính sách trên các dữ liệu môi trường và đào tạo ra với sự giúp đỡ của một tài xế, và đào tạo đại lý trên dữ liệu.
Lưu ý rằng có hai tham số cùng xác định số bước được thực hiện. num_iterations quy định cụ thể bao nhiêu lần chúng tôi chạy vòng lặp huấn luyện viên, trong khi người lái xe sẽ mất steps_per_loop bước mỗi lần lặp. Lý do chính đằng sau việc giữ cả hai tham số này là một số hoạt động được thực hiện mỗi lần lặp, trong khi một số hoạt động được thực hiện bởi trình điều khiển trong mỗi bước. Ví dụ, đại lý train chức năng chỉ được gọi một lần mỗi lần lặp. Sự cân bằng ở đây là nếu chúng tôi đào tạo thường xuyên hơn thì chính sách của chúng tôi sẽ "mới mẻ hơn", mặt khác, đào tạo theo đợt lớn hơn có thể hiệu quả hơn về thời gian.
num_iterations = 90 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=batch_size,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=environment,
policy=agent.collect_policy,
num_steps=steps_per_loop * batch_size,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
plt.plot(regret_values)
plt.ylabel('Average Regret')
plt.xlabel('Number of Iterations')
WARNING:tensorflow:From /tmp/ipykernel_11392/3138849230.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead. Text(0.5, 0, 'Number of Iterations')
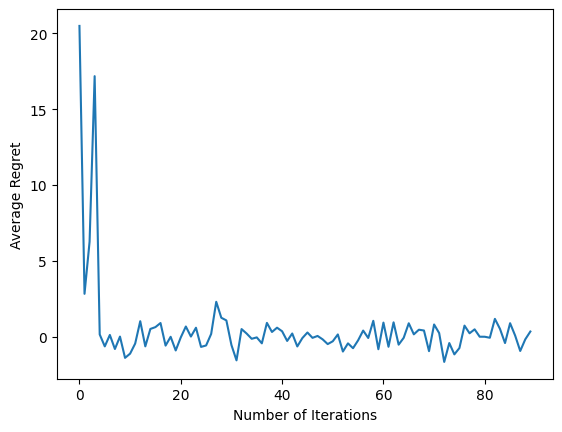
Sau khi chạy đoạn mã cuối cùng, biểu đồ kết quả (hy vọng) cho thấy rằng sự hối tiếc trung bình sẽ giảm xuống khi nhân viên được đào tạo và chính sách trở nên tốt hơn trong việc tìm ra hành động phù hợp, dựa trên quan sát.
Cái gì tiếp theo?
Để xem các ví dụ làm việc nhiều hơn, vui lòng xem kẻ cướp / đại lý / ví dụ thư mục đó có các ví dụ sẵn sàng để chạy cho các đại lý và môi trường khác nhau.
Thư viện TF-Agents cũng có khả năng xử lý Kẻ cướp đa vũ trang với các tính năng trên mỗi cánh tay. Cuối cùng, chúng tôi đề cập người đọc đến tên cướp mỗi cánh tay hướng dẫn .