
 GitHub에서소스 보기 GitHub에서소스 보기 |
참고: 이 colab은 tensorflow_federated pip 패키지의 최신 릴리즈 버전에서 동작하는 것으로 확인되었지만, Tensorflow Federated 프로젝트는 아직 릴리즈 전 개발 중이며 master에서 동작하지 않을 수 있습니다.
이 튜토리얼에서는 고전적인 MNIST 훈련 예제를 사용하여 TFF의 Federated Learning(FL) API 레이어(tff.learning - TensorFlow에서 구현된 사용자 제공 모델에 대해 페더레이션 훈련과 같은 일반적인 유형의 페더레이션 학습 작업을 수행하는 데 사용할 수 있는 상위 수준의 인터페이스 세트)를 소개합니다.
이 튜토리얼과 Federated Learning API는 주로 자신의 TensorFlow 모델을 TFF에 연결하여 후자를 대부분 블랙 박스로 취급하려는 사용자를 대상으로 합니다. TFF에 대한 심층적인 이해와 자신의 페더레이션 학습 알고리즘을 구현하는 방법은 FC Core API 튜토리얼 - 사용자 정의 페더레이션 알고리즘 1부 및 2부를 참조하세요.
tff.learning에 대한 자세한 내용은 Text Generation용 Federated Learning 튜토리얼에서 계속하세요. 반복 모델을 다루는 것 외에도 Keras를 사용한 평가와 결합된 페더레이션 학습을 통해 구체화를 위한 사전 훈련되고 직렬화된 Keras 모델을 로드하는 방법을 보여줍니다.
시작하기 전에
시작하기 전에 다음을 실행하여 환경이 올바르게 설정되었는지 확인합니다. 인사말이 표시되지 않으면 설치 가이드에서 지침을 참조하세요.
!pip install --quiet --upgrade tensorflow_federated_nightly
!pip install --quiet --upgrade nest_asyncio
import nest_asyncio
nest_asyncio.apply()
%load_ext tensorboard
import collections
import numpy as np
import tensorflow as tf
import tensorflow_federated as tff
np.random.seed(0)
tff.federated_computation(lambda: 'Hello, World!')()
b'Hello, World!'
입력 데이터 준비하기
데이터부터 시작하겠습니다. 페더레이션 학습에는 페더레이션 데이터세트, 즉 여러 사용자의 데이터 모음이 필요합니다. 페더레이션 데이터는 일반적으로 고유한 문제를 제기하는 비 i.i.d.입니다.
실험을 용이하게 하기 위해 Leaf를 사용하여 재처리된 원래 NIST 데이터세트의 버전이 포함된 MNIST의 페더레이션 버전을 포함하여 몇 개의 데이터세트로 TFF 리포지토리를 시드하여 데이터가 원래 숫자 작성자에 의해 입력되도록 합니다. 작성자마다 고유한 스타일이 있기 때문에 이 데이터세트는 페더레이션 데이터세트에서 예상되는 non-i.i.d. 동작의 종류를 보여줍니다.
로드하는 방법은 다음과 같습니다.
emnist_train, emnist_test = tff.simulation.datasets.emnist.load_data()
load_data()가 반환하는 데이터세트는 사용자 세트를 열거하고 특정 사용자의 데이터를 나타내는 tf.data.Dataset를 구성하고 개별 요소의 구조를 쿼리할 수 있는 인터페이스인 tff.simulation.ClientData의 인스턴스입니다. 이 인터페이스를 사용하여 데이터세트의 내용을 탐색하는 방법은 다음과 같습니다. 이 인터페이스를 사용하면 클라이언트 ID를 반복할 수 있지만, 이는 시뮬레이션 데이터의 특성일 뿐입니다. 곧 살펴보겠지만, 클라이언트 ID는 페더레이션 학습 프레임워크에서 사용되지 않습니다. 클라이언트 ID의 유일한 목적은 시뮬레이션을 위해 데이터의 하위 집합을 선택할 수 있도록 하는 것입니다.
len(emnist_train.client_ids)
3383
emnist_train.element_type_structure
OrderedDict([('pixels', TensorSpec(shape=(28, 28), dtype=tf.float32, name=None)), ('label', TensorSpec(shape=(), dtype=tf.int32, name=None))])
example_dataset = emnist_train.create_tf_dataset_for_client(
emnist_train.client_ids[0])
example_element = next(iter(example_dataset))
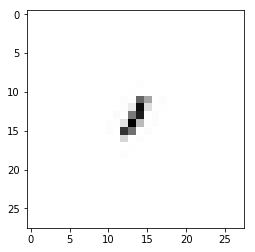
example_element['label'].numpy()
1
from matplotlib import pyplot as plt
plt.imshow(example_element['pixels'].numpy(), cmap='gray', aspect='equal')
plt.grid(False)
_ = plt.show()
페더레이션 데이터의 이질성 탐색하기
페더레이션 데이터는 일반적으로 비 i.i.d.이며, 사용자는 일반적으로 사용 패턴에 따라 데이터 분포가 다릅니다. 일부 클라이언트는 기기에 훈련 예제가 적어 로컬에서 데이터가 부족할 수 있지만, 일부 클라이언트는 충분한 훈련 예제를 가지고 있습니다. 사용 가능한 EMNIST 데이터를 사용하여 페더레이션 시스템의 일반적인 데이터 이질성 개념을 살펴보겠습니다. 고객 데이터에 대한 이 심층 분석은 모든 데이터를 로컬에서 사용할 수 있는 시뮬레이션 환경이기 때문에 당사만 사용할 수 있다는 점에 유의하는 것이 중요합니다. 실제 운영 페더레이션 환경에서는 단일 클라이언트의 데이터를 검사할 수 없습니다.
먼저, 하나의 시뮬레이션 기기에서 예제에 대한 느낌을 얻기 위해 한 클라이언트의 데이터를 샘플링해 보겠습니다. 당사가 사용하는 데이터세트는 고유한 작성자가 입력했기 때문에 한 클라이언트의 데이터는 한 사용자의 고유한 "사용 패턴"을 시뮬레이션하여 0부터 9까지의 숫자 샘플에 대한 한 사람의 손글씨를 나타냅니다.
## Example MNIST digits for one client
figure = plt.figure(figsize=(20, 4))
j = 0
for example in example_dataset.take(40):
plt.subplot(4, 10, j+1)
plt.imshow(example['pixels'].numpy(), cmap='gray', aspect='equal')
plt.axis('off')
j += 1

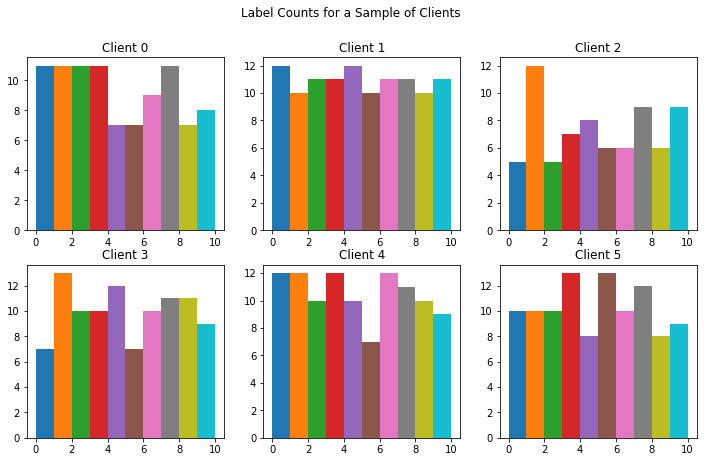
이제 각 MNIST 숫자 레이블에 대한 각 클라이언트의 예제 수를 시각화해 보겠습니다. 페더레이션 환경에서 각 클라이언트의 예제 수는 사용자 동작에 따라 상당히 다를 수 있습니다.
# Number of examples per layer for a sample of clients
f = plt.figure(figsize=(12, 7))
f.suptitle('Label Counts for a Sample of Clients')
for i in range(6):
client_dataset = emnist_train.create_tf_dataset_for_client(
emnist_train.client_ids[i])
plot_data = collections.defaultdict(list)
for example in client_dataset:
# Append counts individually per label to make plots
# more colorful instead of one color per plot.
label = example['label'].numpy()
plot_data[label].append(label)
plt.subplot(2, 3, i+1)
plt.title('Client {}'.format(i))
for j in range(10):
plt.hist(
plot_data[j],
density=False,
bins=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
이제 각 MNIST 레이블에 대한 클라이언트별 평균 이미지를 시각화해 보겠습니다. 이 코드는 하나의 레이블에 대한 사용자의 모든 예제에 대한 각 픽셀 값의 평균을 생성합니다. 한 고객의 숫자에 대한 평균 이미지는 각 개인의 고유한 필기 스타일로 인해 같은 숫자에 대한 다른 고객의 평균 이미지와 다르게 보일 것입니다. 해당 로컬 라운드에서 해당 사용자의 고유 한 데이터에서 학습하므로 각 로컬 훈련 라운드가 각 클라이언트에서 다른 방향으로 모델을 어떻게 움직일지 뮤즈할 수 있습니다. 튜토리얼의 뒷부분에서 모든 클라이언트의 모델에 대한 각 업데이트를 가져와서 각 클라이언트의 고유한 데이터에서 학습한 새로운 글로벌 모델로 통합하는 방법을 살펴보겠습니다.
# Each client has different mean images, meaning each client will be nudging
# the model in their own directions locally.
for i in range(5):
client_dataset = emnist_train.create_tf_dataset_for_client(
emnist_train.client_ids[i])
plot_data = collections.defaultdict(list)
for example in client_dataset:
plot_data[example['label'].numpy()].append(example['pixels'].numpy())
f = plt.figure(i, figsize=(12, 5))
f.suptitle("Client #{}'s Mean Image Per Label".format(i))
for j in range(10):
mean_img = np.mean(plot_data[j], 0)
plt.subplot(2, 5, j+1)
plt.imshow(mean_img.reshape((28, 28)))
plt.axis('off')


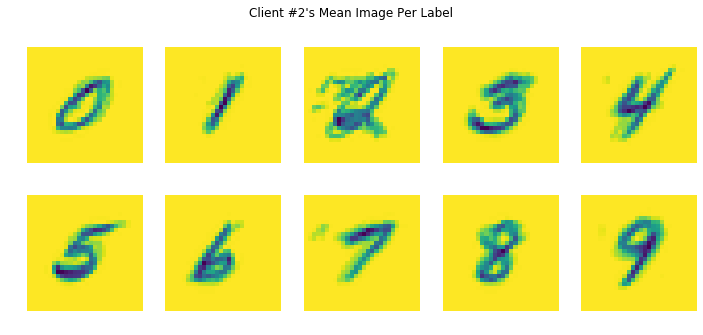


사용자 데이터는 노이즈가 많고 레이블이 안정적이지 않을 수 있습니다. 예를 들어, 위의 클라이언트 #2의 데이터를 살펴보면 레이블 2의 경우, 노이즈가 더 많은 평균 이미지를 생성하는 레이블이 잘못 지정된 예가 있을 수 있습니다.
입력 데이터 전처리
데이터가 이미 tf.data.Dataset이므로 데이터세트 변환을 사용하여 전처리를 수행할 수 있습니다. 여기에서는 28x28 이미지를 784개 요소 배열로 병합하고, 개별 예를 셔플하고, 배치로 구성하고, Keras와 함께 사용할 수 있도록 특성의 이름을 pixels 및 label에서 x 및 y로 바꿉니다. 또한, 데이터세트를 repeat하여 여러 epoch를 실행합니다.
NUM_CLIENTS = 10
NUM_EPOCHS = 5
BATCH_SIZE = 20
SHUFFLE_BUFFER = 100
PREFETCH_BUFFER=10
def preprocess(dataset):
def batch_format_fn(element):
"""Flatten a batch `pixels` and return the features as an `OrderedDict`."""
return collections.OrderedDict(
x=tf.reshape(element['pixels'], [-1, 784]),
y=tf.reshape(element['label'], [-1, 1]))
return dataset.repeat(NUM_EPOCHS).shuffle(SHUFFLE_BUFFER).batch(
BATCH_SIZE).map(batch_format_fn).prefetch(PREFETCH_BUFFER)
이것이 동작하는지 확인합니다.
preprocessed_example_dataset = preprocess(example_dataset)
sample_batch = tf.nest.map_structure(lambda x: x.numpy(),
next(iter(preprocessed_example_dataset)))
sample_batch
OrderedDict([('x', array([[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
...,
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.]], dtype=float32)), ('y', array([[2],
[1],
[2],
[3],
[6],
[0],
[1],
[4],
[1],
[0],
[6],
[9],
[9],
[3],
[6],
[1],
[4],
[8],
[0],
[2]], dtype=int32))])
당사는 페더레이션 데이터세트를 구성하기 위한 거의 모든 구성 요소를 갖추고 있습니다.
시뮬레이션에서 페더레이션 데이터를 TFF에 공급하는 방법 중 하나는 목록의 각 요소가 목록이든 tf.data.Dataset이든 상관없이 개별 사용자의 데이터를 보유하는 목록의 각 요소를 사용하여 간단히 Python 목록으로 만드는 것입니다. 후자를 제공하는 인터페이스가 이미 있으므로 사용해 보겠습니다.
다음은 훈련 또는 평가 라운드에 대한 입력으로 주어진 사용자 세트의 데이터세트 목록을 구성하는 간단한 도우미 함수입니다.
def make_federated_data(client_data, client_ids):
return [
preprocess(client_data.create_tf_dataset_for_client(x))
for x in client_ids
]
이제 클라이언트를 어떻게 선택할까요?
일반적인 페더레이션 훈련 시나리오에서는 잠재적으로 매우 많은 수의 사용자 기기를 다루고 있으며, 이 중 일부만 주어진 시점에서 훈련에 사용할 수 있습니다. 예를 들어, 클라이언트 기기가 전원에 연결되어 있고 데이터 통신 연결 네트워크가 꺼져 있거나 유휴 상태일 때만 훈련에 참여하는 휴대폰인 경우입니다.
물론, 시뮬레이션 환경에서는 모든 데이터를 로컬에서 사용할 수 있습니다. 통상적으로, 시뮬레이션을 실행할 때 일반적으로 각 라운드마다 다른 각 훈련 라운드에 참여할 클라이언트의 무작위 하위 집합을 샘플링합니다.
즉, Federated Averaging 알고리즘에 대한 논문을 연구하면 알 수 있듯이, 각 라운드에 무작위로 샘플링된 클라이언트 하위 집합이 있는 시스템에서 수렴을 달성하는 데는 시간이 걸릴 수 있으며, 이 대화형 튜토리얼에서 수백 번의 라운드를 실행해야 하는 것은 비현실적입니다.
대신 클라이언트 세트를 한 번 샘플링하고 수렴 속도를 높이기 위해 라운드에서 같은 세트를 재사용할 것입니다(의도적으로 이들 소수의 사용자 데이터에 과대적합임). 독자가 이 튜토리얼을 수정하여 무작위 샘플링을 시뮬레이션하는 것은 연습으로 남겨 둡니다. 매우 쉽습니다(한 번 수행하면 모델을 수렴하는 데 시간이 걸릴 수 있음을 명심하세요).
sample_clients = emnist_train.client_ids[0:NUM_CLIENTS]
federated_train_data = make_federated_data(emnist_train, sample_clients)
print('Number of client datasets: {l}'.format(l=len(federated_train_data)))
print('First dataset: {d}'.format(d=federated_train_data[0]))
Number of client datasets: 10 First dataset: <DatasetV1Adapter shapes: OrderedDict([(x, (None, 784)), (y, (None, 1))]), types: OrderedDict([(x, tf.float32), (y, tf.int32)])>
Keras로 모델 만들기
Keras를 사용하는 경우, Keras 모델을 구성하는 코드가 이미 있을 수 있습니다. 다음은 요구 사항에 맞는 간단한 모델의 예제입니다.
def create_keras_model():
return tf.keras.models.Sequential([
tf.keras.layers.Input(shape=(784,)),
tf.keras.layers.Dense(10, kernel_initializer='zeros'),
tf.keras.layers.Softmax(),
])
참고: 아직 모델을 컴파일하지 않습니다. 손실, 메트릭 및 옵티마이저는 나중에 소개됩니다.
TFF와 함께 모델을 사용하려면, Keras와 유사하게 모델의 순방향 전달, 메타데이터 속성 등을 스탬핑하는 메서드를 노출하는 tff.learning.Model 인터페이스의 인스턴스로 모델을 래핑해야 하지만, 페더레이션 메트릭의 계산 프로세스를 제어하는 방법과 같은 추가 요소도 도입합니다. 지금은 이것에 대해 걱정하지 마세요. 위에서 정의한 것과 같은 Keras 모델이 있는 경우, 아래와 같이 tff.learning.from_keras_model를 호출하고 모델과 샘플 데이터 배치를 인수로 전달하여 TFF를 래핑할 수 있습니다.
def model_fn():
# We _must_ create a new model here, and _not_ capture it from an external
# scope. TFF will call this within different graph contexts.
keras_model = create_keras_model()
return tff.learning.from_keras_model(
keras_model,
input_spec=preprocessed_example_dataset.element_spec,
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])
페더레이션 데이터에 대해 모델 훈련하기
TFF와 함께 사용하기 위해 tff.learning.Model로 래핑한 모델이 있으므로 다음과 같이 도우미 함수 tff.learning.build_federated_averaging_process를 호출하여 TFF에서 Federated Averaging 알고리즘을 구성하도록 할 수 있습니다.
인수는 이미 생성된 인스턴스가 아닌 생성자(예: 위의 model_fn)여야 하므로 모델 생성은 TFF에 의해 제어되는 컨텍스트에서 발생할 수 있습니다(그 이유가 궁금하다면, 사용자 정의 알고리즘에 대한 후속 튜토리얼을 읽어 보시기 바랍니다).
아래의 Federated Averaging 알고리즘에 대한 중요한 참고 사항 중 하나는 client_optimizer 및 server_optimizer의 두 가지 옵티마이저입니다. client_optimizer는 각 클라이언트에서 로컬 모델 업데이트를 계산하는 데만 사용됩니다. server_optimizer는 평균 업데이트를 서버의 글로벌 모델에 적용합니다. 특히, 이는 사용되는 옵티마이저 및 학습률의 선택이 표준 iid 데이터세트에 대해 모델을 훈련하는 데 사용한 것과 달라야 할 수 있음을 의미합니다. 정규 SGD부터 시작하는 것이 좋습니다. 학습률이 평소보다 낮을 수 있습니다. 여기서 사용하는 학습률은 신중하게 조정되지 않았으므로 자유롭게 실험해 보세요.
iterative_process = tff.learning.build_federated_averaging_process(
model_fn,
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=0.02),
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=1.0))
방금 무슨 일이 있었나요? TFF에서 한 쌍의 페더레이션 계산을 구성하고 tff.templates.IterativeProcess로 패키징하여 이들 계산을 한 쌍의 속성 initialize 및 next로 사용할 수 있습니다.
간단히 말해서, 페더레이션 계산은 다양한 페더레이션 알고리즘을 표현할 수 있는 TFF의 내부 언어로 된 프로그램입니다(사용자 정의 알고리즘 튜토리얼에서 자세한 내용을 찾을 수 있음). 이 경우, 생성되고 iterative_process로 패키징된 두 가지 계산은 Federated Averaging을 구현합니다.
실제 페더레이션 학습 설정에서 실행될 수 있는 방식으로 계산을 정의하는 것이 TFF의 목표이지만, 현재는 로컬 실행 시뮬레이션 런타임만 구현됩니다. 시뮬레이터에서 계산을 실행하려면 Python 함수처럼 간단히 호출하면 됩니다. 이 기본 해석 환경은 고성능을 위해 설계되지 않았지만, 이 튜토리얼에는 충분합니다. 향후 릴리스에서 대규모 연구를 용이하게 하기 위해 고성능 시뮬레이션 런타임을 제공할 것으로 기대합니다.
initialize 계산부터 시작하겠습니다. 모든 페더레이션 계산의 경우와 마찬가지로 이를 함수로 생각할 수 있습니다. 계산은 인수를 사용하지 않고 하나의 결과를 반환합니다. 즉, 서버에서 Federated Averaging 프로세스의 상태를 나타냅니다. TFF의 세부 사항에 대해 자세히 알아보고 싶지는 않지만, 이 상태가 어떻게 생겼는지 확인하는 것이 도움이 될 수 있습니다. 다음과 같이 시각화할 수 있습니다.
str(iterative_process.initialize.type_signature)
'( -> <model=<trainable=<float32[784,10],float32[10]>,non_trainable=<>>,optimizer_state=<int64>,delta_aggregate_state=<>,model_broadcast_state=<>>@SERVER)'
위의 형식 서명이 처음에는 다소 모호해 보일 수 있지만, 서버 상태는 model(모든 기기에 배포될 MNIST의 초기 모델 매개변수)과 optimizer_state(서버에서 유지 관리하는 추가 정보, 하이퍼 매개변수 일정 등에 사용할 라운드 수 등)로 구성됩니다..
initialize 계산을 호출하여 서버 상태를 구성해 보겠습니다.
state = iterative_process.initialize()
두 번째 페더레이션 계산 쌍인 next는 서버 상태(모델 매개변수 포함)를 클라이언트에 푸시, 로컬 데이터에 대한 기기 내 훈련, 모델 업데이트 수집 및 평균화로 구성된 단일 라운드의 페더레이션 평균화를 나타내며, 서버에서 업데이트된 새 모델을 생성합니다.
개념적으로, next과 같은 함수형 형식 서명을 갖는 것으로 생각할 수 있습니다.
SERVER_STATE, FEDERATED_DATA -> SERVER_STATE, TRAINING_METRICS
특히, next()는 서버에서 실행되는 함수가 아니라 전체 분산 계산의 선언적 함수형 표현으로 생각해야 합니다. 일부 입력은 서버( SERVER_STATE)에서 제공하지만, 참여하는 각 기기는 자체 로컬 데이터트를 제공합니다.
라운드 한 번 훈련을 실행하고 결과를 시각화해 보겠습니다. 사용자 샘플을 위해 위에서 이미 생성한 페더레이션 데이터를 사용할 수 있습니다.
state, metrics = iterative_process.next(state, federated_train_data)
print('round 1, metrics={}'.format(metrics))
round 1, metrics=<broadcast=<>,aggregation=<>,train=<sparse_categorical_accuracy=0.12037037312984467,loss=3.0108425617218018>>
몇 라운드를 더 실행해 봅시다. 앞서 언급했듯이, 일반적으로 이 시점에서 사용자가 지속적으로 오고가는 현실적인 배포를 시뮬레이션하기 위해 각 라운드에서 무작위로 선택한 새로운 사용자 샘플에서 시뮬레이션 데이터의 하위 집합을 선택하지만, 이 대화형 노트북에서는 데모를 위해 같은 사용자를 재사용하여 시스템이 빠르게 수렴되도록 합니다.
NUM_ROUNDS = 11
for round_num in range(2, NUM_ROUNDS):
state, metrics = iterative_process.next(state, federated_train_data)
print('round {:2d}, metrics={}'.format(round_num, metrics))
round 2, metrics=<broadcast=<>,aggregation=<>,train=<sparse_categorical_accuracy=0.14814814925193787,loss=2.8865506649017334>> round 3, metrics=<broadcast=<>,aggregation=<>,train=<sparse_categorical_accuracy=0.148765429854393,loss=2.9079062938690186>> round 4, metrics=<broadcast=<>,aggregation=<>,train=<sparse_categorical_accuracy=0.17633745074272156,loss=2.724686622619629>> round 5, metrics=<broadcast=<>,aggregation=<>,train=<sparse_categorical_accuracy=0.20226337015628815,loss=2.6334855556488037>> round 6, metrics=<broadcast=<>,aggregation=<>,train=<sparse_categorical_accuracy=0.22427983582019806,loss=2.5482592582702637>> round 7, metrics=<broadcast=<>,aggregation=<>,train=<sparse_categorical_accuracy=0.24094650149345398,loss=2.4472343921661377>> round 8, metrics=<broadcast=<>,aggregation=<>,train=<sparse_categorical_accuracy=0.259876549243927,loss=2.3809611797332764>> round 9, metrics=<broadcast=<>,aggregation=<>,train=<sparse_categorical_accuracy=0.29814815521240234,loss=2.156442403793335>> round 10, metrics=<broadcast=<>,aggregation=<>,train=<sparse_categorical_accuracy=0.31687241792678833,loss=2.122845411300659>>
페더레이션 훈련의 각 라운드 후에 훈련 손실이 감소하여 모델이 수렴되고 있음을 나타냅니다. 이러한 훈련 메트릭에는 몇 가지 중요한 주의 사항이 있지만, 이 튜토리얼 뒷부분의 평가 섹션을 참조하세요.
TensorBoard에 모델 메트릭 표시, 다음으로 Tensorboard를 사용하여 이들 페더레이션 계산의 메트릭을 시각화해 보겠습니다.
메트릭을 기록할 디렉터리와 해당 요약 작성기를 만드는 것으로 시작하겠습니다.
logdir = "/tmp/logs/scalars/training/"
summary_writer = tf.summary.create_file_writer(logdir)
state = iterative_process.initialize()
같은 요약 작성기를 사용하여 관련 스칼라 메트릭을 플롯합니다.
with summary_writer.as_default():
for round_num in range(1, NUM_ROUNDS):
state, metrics = iterative_process.next(state, federated_train_data)
for name, value in metrics.train._asdict().items():
tf.summary.scalar(name, value, step=round_num)
위에 지정된 루트 로그 디렉터리로 TensorBoard를 시작합니다. 데이터를 로드하는 데 몇 초 정도 걸릴 수 있습니다.
%tensorboard --logdir /tmp/logs/scalars/ --port=0
# Run this this cell to clean your directory of old output for future graphs from this directory.rm -R /tmp/logs/scalars/*
같은 방식으로 평가 메트릭을 보려면 "logs/scalars/eval"과 같은 별도의 eval 폴더를 만들어 TensorBoard에 쓸 수 있습니다.
모델 구현 사용자 정의하기
Keras는 TensorFlow용으로 권장되는 상위 수준 모델 API이며, 가능하면 TFF에서 Keras 모델(tff.learning.from_keras_model를 통해)을 사용하는 것이 좋습니다.
그러나 tff.learning은 페더레이션 학습을 위해 모델을 사용하는 데 필요한 최소한의 기능을 노출하는 하위 수준 모델 인터페이스 인 tff.learning.Model을 제공합니다. 이 인터페이스(아마도 tf.keras.layers와 같은 구성 요소를 계속 사용)를 직접 구현하면 페더레이션 학습 알고리즘의 내부를 수정하지 않고도 최대한으로 사용자 정의가 가능합니다.
처음부터 다시 한번 해봅시다.
모델 변수, 순방향 전달 및 메트릭 정의하기
첫 번째 단계는 작업할 TensorFlow 변수를 식별하는 것입니다. 다음 코드를 더 읽기 쉽게 만들기 위해 전체 집합을 나타내는 데이터 구조를 정의하겠습니다. 여기에는 훈련할 weights와 bias와 같은 변수와 함께 loss_sum, accuracy_sum 및 num_examples와 같은 훈련 중에 업데이트할 다양한 누적 통계 및 카운터를 보유하는 변수도 포함됩니다.
MnistVariables = collections.namedtuple(
'MnistVariables', 'weights bias num_examples loss_sum accuracy_sum')
다음은 변수를 생성하는 메서드입니다. 간단하게 하기 위해 모든 통계를 tf.float32로 표시합니다. 그러면 이후 단계에서 유형 변환이 필요하지 않습니다. 변수 이니셜라이저를 람다로 래핑하는 것은 리소스 변수에서 요구하는 사항입니다.
def create_mnist_variables():
return MnistVariables(
weights=tf.Variable(
lambda: tf.zeros(dtype=tf.float32, shape=(784, 10)),
name='weights',
trainable=True),
bias=tf.Variable(
lambda: tf.zeros(dtype=tf.float32, shape=(10)),
name='bias',
trainable=True),
num_examples=tf.Variable(0.0, name='num_examples', trainable=False),
loss_sum=tf.Variable(0.0, name='loss_sum', trainable=False),
accuracy_sum=tf.Variable(0.0, name='accuracy_sum', trainable=False))
모델 매개변수 및 누적 통계에 대한 변수를 사용하여 다음과 같이 손실을 계산하고, 예측값을 내보내고, 단일 배치의 입력 데이터에 대한 누적 통계를 업데이트하는 순방향 전달 메서드를 정의할 수 있습니다.
def mnist_forward_pass(variables, batch):
y = tf.nn.softmax(tf.matmul(batch['x'], variables.weights) + variables.bias)
predictions = tf.cast(tf.argmax(y, 1), tf.int32)
flat_labels = tf.reshape(batch['y'], [-1])
loss = -tf.reduce_mean(
tf.reduce_sum(tf.one_hot(flat_labels, 10) * tf.math.log(y), axis=[1]))
accuracy = tf.reduce_mean(
tf.cast(tf.equal(predictions, flat_labels), tf.float32))
num_examples = tf.cast(tf.size(batch['y']), tf.float32)
variables.num_examples.assign_add(num_examples)
variables.loss_sum.assign_add(loss * num_examples)
variables.accuracy_sum.assign_add(accuracy * num_examples)
return loss, predictions
다음으로 다시 TensorFlow를 사용하여 로컬 메트릭 세트를 반환하는 함수를 정의합니다. 로컬 메트릭 세트는 페더레이션 학습 또는 평가 프로세스에서 서버로 집계할 수 있는 값(자동으로 처리되는 모델 업데이트에 추가)입니다.
여기서는 단순히 평균 loss 및 accuracy와 num_examples를 반환하며, 페더레이션 집계를 계산할 때 다른 사용자의 기여도에 올바르게 가중치를 적용해야 합니다.
def get_local_mnist_metrics(variables):
return collections.OrderedDict(
num_examples=variables.num_examples,
loss=variables.loss_sum / variables.num_examples,
accuracy=variables.accuracy_sum / variables.num_examples)
마지막으로, get_local_mnist_metrics를 통해 각 기기에서 내보낸 로컬 메트릭을 집계하는 방법을 결정해야 합니다. 이것은 TensorFlow로 작성되지 않은 코드의 유일한 부분입니다. TFF로 표현된 페더레이션 계산입니다. 더 자세히 알고 싶다면, 사용자 정의 알고리즘 튜토리얼을 살펴보지만, 대부분의 애플리케이션에서는 그럴 필요가 없습니다. 아래 표시된 패턴의 변형으로 충분합니다. 다음과 같습니다.
@tff.federated_computation
def aggregate_mnist_metrics_across_clients(metrics):
return collections.OrderedDict(
num_examples=tff.federated_sum(metrics.num_examples),
loss=tff.federated_mean(metrics.loss, metrics.num_examples),
accuracy=tff.federated_mean(metrics.accuracy, metrics.num_examples))
입력 metrics 인수는 위의 get_local_mnist_metrics에서 반환한 OrderedDict에 해당하지만, 결정적으로 해당 값은 더 이상 tf.Tensors가 아닙니다. tff.Value로 "박스화"되어 있으므로 더 이상 TensorFlow를 사용하여 조작할 수 없지만, tff.federated_mean 및 tff.federated_sum과 같은 TFF의 페더레이션 연산자만 사용할 수 있습니다. 반환된 전역 집계 사전은 서버에서 사용할 수 있는 메트릭 세트를 정의합니다.
tff.learning.Model의 인스턴스 생성하기
위의 모든 항목이 준비되었으므로 TFF가 Keras 모델을 수집하도록 할 때 생성되는 것과 유사한 TFF와 함께 사용할 모델 표현을 구성할 준비가 되었습니다.
class MnistModel(tff.learning.Model):
def __init__(self):
self._variables = create_mnist_variables()
@property
def trainable_variables(self):
return [self._variables.weights, self._variables.bias]
@property
def non_trainable_variables(self):
return []
@property
def local_variables(self):
return [
self._variables.num_examples, self._variables.loss_sum,
self._variables.accuracy_sum
]
@property
def input_spec(self):
return collections.OrderedDict(
x=tf.TensorSpec([None, 784], tf.float32),
y=tf.TensorSpec([None, 1], tf.int32))
@tf.function
def forward_pass(self, batch, training=True):
del training
loss, predictions = mnist_forward_pass(self._variables, batch)
num_exmaples = tf.shape(batch['x'])[0]
return tff.learning.BatchOutput(
loss=loss, predictions=predictions, num_examples=num_exmaples)
@tf.function
def report_local_outputs(self):
return get_local_mnist_metrics(self._variables)
@property
def federated_output_computation(self):
return aggregate_mnist_metrics_across_clients
보시다시피, tff.learning.Model에서 정의한 추상 메서드 및 속성은 변수를 도입하고 손실 및 통계를 정의한 이전 섹션의 코드 조각에 해당합니다.
다음은 강조할 만한 몇 가지 사항입니다.
- TFF는 런타임에 Python을 사용하지 않으므로 모델에서 사용할 모든 상태를 TensorFlow 변수로 캡처해야 합니다(코드는 모바일 기기에 배포할 수 있도록 작성되어야 합니다. 그 이유에 대한 자세한 내용은 사용자 정의 알고리즘 튜토리얼을 참조하세요).
- 일반적으로 TFF는 강력한 형식의 환경이며 모든 구성 요소에 대한 형식 서명을 결정하려고 하기 때문에 모델은 허용하는 데이터 형식(
input_spec)을 설명해야 합니다. 모델의 입력 형식을 선언하는 것은 필수입니다. - 기술적으로는 필요하지 않지만, 모든 TensorFlow 로직(순방향 전달, 메트릭 계산 등)을
tf.function로 래핑하는 것이 좋습니다. 이렇게 하면 TensorFlow가 직렬화될 수 있고 명시적인 제어 종속성이 필요하지 않습니다.
위의 내용은 Federated SGD와 같은 평가 및 알고리즘에 충분합니다. 그러나 Federated Averaging의 경우 모델이 각 배치에서 로컬로 훈련하는 방법을 지정해야 합니다. Federated Averaging 알고리즘을 빌드할 때 로컬 옵티마이저를 지정합니다.
새 모델로 페더레이션 훈련 시뮬레이션하기
위의 모든 사항이 준빈되면, 프로세스의 나머지 부분은 이미 본 것과 같이 보입니다. 모델 생성자를 새 모델 클래스의 생성자로 교체하고 생성한 반복 프로세스에서 두 개의 페더레이션 계산을 사용하여 훈련 라운드를 순환합니다.
iterative_process = tff.learning.build_federated_averaging_process(
MnistModel,
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=0.02))
state = iterative_process.initialize()
state, metrics = iterative_process.next(state, federated_train_data)
print('round 1, metrics={}'.format(metrics))
round 1, metrics=<broadcast=<>,aggregation=<>,train=<num_examples=4860.0,loss=2.9713594913482666,accuracy=0.13518518209457397>>
for round_num in range(2, 11):
state, metrics = iterative_process.next(state, federated_train_data)
print('round {:2d}, metrics={}'.format(round_num, metrics))
round 2, metrics=<broadcast=<>,aggregation=<>,train=<num_examples=4860.0,loss=2.975412607192993,accuracy=0.14032921195030212>> round 3, metrics=<broadcast=<>,aggregation=<>,train=<num_examples=4860.0,loss=2.9395227432250977,accuracy=0.1594650149345398>> round 4, metrics=<broadcast=<>,aggregation=<>,train=<num_examples=4860.0,loss=2.710164785385132,accuracy=0.17139917612075806>> round 5, metrics=<broadcast=<>,aggregation=<>,train=<num_examples=4860.0,loss=2.5891618728637695,accuracy=0.20267489552497864>> round 6, metrics=<broadcast=<>,aggregation=<>,train=<num_examples=4860.0,loss=2.5148487091064453,accuracy=0.21666666865348816>> round 7, metrics=<broadcast=<>,aggregation=<>,train=<num_examples=4860.0,loss=2.2816808223724365,accuracy=0.2580246925354004>> round 8, metrics=<broadcast=<>,aggregation=<>,train=<num_examples=4860.0,loss=2.3656885623931885,accuracy=0.25884774327278137>> round 9, metrics=<broadcast=<>,aggregation=<>,train=<num_examples=4860.0,loss=2.23549222946167,accuracy=0.28477364778518677>> round 10, metrics=<broadcast=<>,aggregation=<>,train=<num_examples=4860.0,loss=1.974222183227539,accuracy=0.35329216718673706>>
TensorBoard 내에서 이들 메트릭을 보려면, 위의 "TensorBoard에서 모델 메트릭 표시하기"에 나열된 단계를 참조하세요.
평가
지금까지의 모든 실험은 페더레이션 훈련 메트릭(라운드의 모든 클라이언트에 걸쳐 훈련된 모든 데이터 배치에 대한 평균 메트릭)만 제시했습니다. 이는 특히 단순성을 위해 각 라운드에서 같은 클라이언트 세트를 사용했기 때문에 과대적합에 대한 일반적인 우려가 있지만, Federated Averaging 알고리즘에 특정한 훈련 메트릭에는 과대적합이라는 추가 개념이 있습니다. 이것은 각 클라이언트가 단일 데이터 배치를 가지고 있다고 상상하고 많은 반복(epoch) 동안 해당 배치에 대해 훈련하는 경우 가장 쉽게 확인할 수 있습니다. 이 경우 로컬 모델은 해당 배치 하나에 빠르게 정확히 맞으므로 평균적인 로컬 정확성 메트릭은 1.0에 접근합니다. 따라서 이들 훈련 메트릭은 훈련이 진행되고 있다는 신호로 간주될 수 있지만, 그 이상은 아닙니다.
페더레이션 데이터에 대한 평가를 수행하려면, tff.learning.build_federated_evaluation 함수를 사용하고 모델 생성자에 인수로 전달하는, 이 용도로 설계된 또 다른 페더레이션 계산을 구성할 수 있습니다. MnistTrainableModel를 사용했던 Federated Averaging과는 달리, MnistMode을 전달하면 충분합니다. 평가는 경사 하강을 수행하지 않으며 옵티마이저를 구성할 필요가 없습니다.
실험과 연구를 위해 중앙 집중식 테스트 데이터세트를 사용할 수 있는 경우, 텍스트 생성을 위한 페더레이션 학습은 다른 평가 옵션을 보여줍니다. 페더레이션 학습에서 훈련된 가중치를 가져와 표준 Keras 모델에 적용한 다음 중앙 집중식 데이터세트에서 tf.keras.models.Model.evaluate()를 호출하면 됩니다.
evaluation = tff.learning.build_federated_evaluation(MnistModel)
다음과 같이 평가 함수의 추상 형식 서명을 검사할 수 있습니다.
str(evaluation.type_signature)
'(<<trainable=<float32[784,10],float32[10]>,non_trainable=<>>@SERVER,{<x=float32[?,784],y=int32[?,1]>*}@CLIENTS> -> <num_examples=float32@SERVER,loss=float32@SERVER,accuracy=float32@SERVER>)'
이 시점에서 세부 사항에 대해 걱정할 필요는 없습니다. tff.templates.IterativeProcess.next와 비슷하지만, 두 가지 중요한 차이점이 있는 다음과 같은 일반적인 형식을 취한다는 점만 알아 두십시오. 첫째, 평가에서는 모델이나 상태의 다른 측면을 수정하지 않기 때문에 서버 상태를 반환하지 않습니다. 상태 비저장으로 생각할 수 있습니다. 둘째, 평가에는 모델만 필요하며 옵티마이저 변수와 같이 훈련과 관련될 수 있는 서버 상태의 다른 부분이 필요하지 않습니다.
SERVER_MODEL, FEDERATED_DATA -> TRAINING_METRICS
훈련 중에 도달한 최신 상태에 대한 평가를 호출해 보겠습니다. 서버 상태에서 훈련된 최신 모델을 추출하려면 다음과 같이 .model 멤버에 액세스하기만 하면 됩니다.
train_metrics = evaluation(state.model, federated_train_data)
평가 결과는 다음과 같습니다. 위의 마지막 훈련 라운드에서 보고된 것보다 수치가 약간 더 좋아 보입니다. 일반적으로, 반복 훈련 프로세스에서 보고된 훈련 메트릭은 일반적으로 훈련 라운드 시작 시 모델의 성능을 반영하므로 평가 메트릭은 항상 한 단계 앞서 있습니다.
str(train_metrics)
'<num_examples=4860.0,loss=1.7142657041549683,accuracy=0.38683128356933594>'
이제 페더레이션 데이터의 테스트 샘플을 컴파일하고 테스트 데이터에 대한 평가를 다시 실행해 보겠습니다. 데이터는 실제 사용자의 같은 샘플에서 제공되지만, 별개의 보류된 데이터세트에서 제공됩니다.
federated_test_data = make_federated_data(emnist_test, sample_clients)
len(federated_test_data), federated_test_data[0]
(10, <DatasetV1Adapter shapes: OrderedDict([(x, (None, 784)), (y, (None, 1))]), types: OrderedDict([(x, tf.float32), (y, tf.int32)])>)
test_metrics = evaluation(state.model, federated_test_data)
str(test_metrics)
'<num_examples=580.0,loss=1.861915111541748,accuracy=0.3362068831920624>'
이것으로 튜토리얼을 마칩니다. 매개변수(예: 배치 크기, 사용자 수, epoch, 학습률 등)를 사용하여 위의 코드를 수정하여 각 라운드에서 사용자의 무작위 샘플에 대한 훈련을 시뮬레이션하고 당사의 다른 튜토리얼을 탐색하는 것이 좋습니다.