
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
এই টিউটোরিয়ালটি টেনসরফ্লো ফেডারেটেড ব্যবহার করে ব্যবহারকারী-স্তরের ডিফারেনশিয়াল প্রাইভেসি সহ প্রশিক্ষণ মডেলের জন্য প্রস্তাবিত সেরা অনুশীলন প্রদর্শন করবে। আমরা ডিপি-SGD অ্যালগরিদম ব্যবহার করবে Abadi, এট আল।, "ডিফারেনশিয়াল গোপনীয়তা সঙ্গে গভীর শিক্ষা" একটি ফেডারেট প্রেক্ষাপটে ব্যবহারকারী লেভেলের ডিপি জন্য পরিবর্তিত McMahan এট আল।, "শিক্ষণ Differentially ব্যক্তিগত পৌনঃপুনিক ভাষা মডেল" ।
ডিফারেনশিয়াল প্রাইভেসি (DP) হল শেখার কাজগুলি সম্পাদন করার সময় সংবেদনশীল ডেটার গোপনীয়তা ফাঁসকে আবদ্ধ করার এবং পরিমাপ করার জন্য একটি বহুল ব্যবহৃত পদ্ধতি। ব্যবহারকারী-স্তরের DP সহ একটি মডেলকে প্রশিক্ষণ দেওয়া গ্যারান্টি দেয় যে মডেলটি কোনও ব্যক্তির ডেটা সম্পর্কে উল্লেখযোগ্য কিছু শিখতে পারে না, তবে এখনও (আশা করি!) অনেক ক্লায়েন্টের ডেটাতে বিদ্যমান প্যাটার্নগুলি শিখতে পারে।
আমরা ফেডারেটেড EMNIST ডেটাসেটে একটি মডেলকে প্রশিক্ষণ দেব। ইউটিলিটি এবং গোপনীয়তার মধ্যে একটি অন্তর্নিহিত ট্রেড-অফ রয়েছে এবং উচ্চ গোপনীয়তা সহ একটি মডেলকে প্রশিক্ষণ দেওয়া কঠিন হতে পারে যা একটি অত্যাধুনিক নন-প্রাইভেট মডেলের পাশাপাশি পারফর্ম করে। এই টিউটোরিয়ালে সুবিধার জন্য, আমরা মাত্র 100 রাউন্ডের জন্য প্রশিক্ষণ দেব, উচ্চ গোপনীয়তার সাথে কীভাবে প্রশিক্ষণ দেওয়া যায় তা প্রদর্শন করার জন্য কিছু গুণমান ত্যাগ করে। যদি আমরা আরও প্রশিক্ষণ রাউন্ড ব্যবহার করি, তাহলে আমাদের অবশ্যই কিছুটা উচ্চ-নির্ভুল ব্যক্তিগত মডেল থাকতে পারে, তবে ডিপি ছাড়া প্রশিক্ষিত মডেলের মতো উচ্চ নয়।
আমরা শুরু করার আগে
প্রথমে, আমরা নিশ্চিত করি যে নোটবুকটি এমন একটি ব্যাকএন্ডের সাথে সংযুক্ত রয়েছে যাতে প্রাসঙ্গিক উপাদানগুলি সংকলিত রয়েছে।
!pip install --quiet --upgrade tensorflow_federated_nightly
!pip install --quiet --upgrade nest-asyncio
import nest_asyncio
nest_asyncio.apply()
টিউটোরিয়ালের জন্য কিছু আমদানি আমাদের প্রয়োজন হবে। আমরা ব্যবহার করবে tensorflow_federated , মেশিন লার্নিং এবং বিকেন্দ্রীভূত ডেটার উপর অন্যান্য কম্পিউটেশন, সেইসাথে জন্য ওপেন সোর্স ফ্রেমওয়ার্ক tensorflow_privacy , বাস্তবায়ন এবং tensorflow মধ্যে differentially ব্যক্তিগত আলগোরিদিম বিশ্লেষণের জন্য ওপেন সোর্স লাইব্রেরি।
import collections
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_federated as tff
import tensorflow_privacy as tfp
TFF পরিবেশ সঠিকভাবে সেটআপ করা হয়েছে তা নিশ্চিত করতে নিম্নলিখিত "হ্যালো ওয়ার্ল্ড" উদাহরণটি চালান। এটা কাজ করে না, তাহলে পড়ুন দয়া ইনস্টলেশন নির্দেশাবলীর জন্য গাইড।
@tff.federated_computation
def hello_world():
return 'Hello, World!'
hello_world()
b'Hello, World!'
ফেডারেটেড EMNIST ডেটাসেট ডাউনলোড এবং প্রিপ্রসেস করুন।
def get_emnist_dataset():
emnist_train, emnist_test = tff.simulation.datasets.emnist.load_data(
only_digits=True)
def element_fn(element):
return collections.OrderedDict(
x=tf.expand_dims(element['pixels'], -1), y=element['label'])
def preprocess_train_dataset(dataset):
# Use buffer_size same as the maximum client dataset size,
# 418 for Federated EMNIST
return (dataset.map(element_fn)
.shuffle(buffer_size=418)
.repeat(1)
.batch(32, drop_remainder=False))
def preprocess_test_dataset(dataset):
return dataset.map(element_fn).batch(128, drop_remainder=False)
emnist_train = emnist_train.preprocess(preprocess_train_dataset)
emnist_test = preprocess_test_dataset(
emnist_test.create_tf_dataset_from_all_clients())
return emnist_train, emnist_test
train_data, test_data = get_emnist_dataset()
আমাদের মডেল সংজ্ঞায়িত করুন.
def my_model_fn():
model = tf.keras.models.Sequential([
tf.keras.layers.Reshape(input_shape=(28, 28, 1), target_shape=(28 * 28,)),
tf.keras.layers.Dense(200, activation=tf.nn.relu),
tf.keras.layers.Dense(200, activation=tf.nn.relu),
tf.keras.layers.Dense(10)])
return tff.learning.from_keras_model(
keras_model=model,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
input_spec=test_data.element_spec,
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])
মডেলের শব্দ সংবেদনশীলতা নির্ধারণ করুন।
ব্যবহারকারী-স্তরের ডিপি গ্যারান্টি পেতে, আমাদের অবশ্যই দুটি উপায়ে মৌলিক ফেডারেটেড এভারেজিং অ্যালগরিদম পরিবর্তন করতে হবে। প্রথমত, ক্লায়েন্টদের মডেল আপডেটগুলি সার্ভারে ট্রান্সমিশনের আগে ক্লিপ করা আবশ্যক, যে কোনও একটি ক্লায়েন্টের সর্বাধিক প্রভাবকে আবদ্ধ করে। দ্বিতীয়ত, সবচেয়ে খারাপ ক্ষেত্রে ক্লায়েন্টের প্রভাবকে অস্পষ্ট করার জন্য গড় করার আগে সার্ভারটিকে ব্যবহারকারীর আপডেটের যোগফলের জন্য যথেষ্ট শব্দ যোগ করতে হবে।
ক্লিপিং জন্য, আমরা এর অভিযোজিত ক্লিপিং পদ্ধতি ব্যবহার অ্যান্ড্রু এট অল। 2021, অভিযোজিত ক্লিপিং সঙ্গে Differentially ব্যক্তিগত শিক্ষণ স্পষ্টভাবে সেট হওয়ার কোন ক্লিপিং আদর্শ প্রয়োজন তাই।
গোলমাল যোগ করা হলে সাধারণভাবে মডেলের উপযোগিতা হ্রাস পাবে, কিন্তু আমরা প্রতিটি রাউন্ডে গড় আপডেটে গোলমালের পরিমাণ নিয়ন্ত্রণ করতে পারি দুটি নব দিয়ে: গাউসিয়ান শব্দের মানক বিচ্যুতি যোগফলের সাথে যোগ করা হয়েছে এবং ক্লায়েন্টের সংখ্যা গড় আমাদের কৌশলটি প্রথমে মডেল ইউটিলিটির গ্রহণযোগ্য ক্ষতির সাথে প্রতি রাউন্ডে অপেক্ষাকৃত কম সংখ্যক ক্লায়েন্টের সাথে মডেলটি কতটা শব্দ সহ্য করতে পারে তা নির্ধারণ করা হবে। তারপরে চূড়ান্ত মডেলটি প্রশিক্ষণের জন্য, আমরা সমষ্টিতে শব্দের পরিমাণ বাড়াতে পারি, আনুপাতিকভাবে প্রতি রাউন্ডে ক্লায়েন্টের সংখ্যা বাড়াতে পারি (ধরে নেওয়া যায় যে ডেটাসেটটি প্রতি রাউন্ডে অনেক ক্লায়েন্টকে সমর্থন করার জন্য যথেষ্ট বড়)। এটি মডেলের গুণমানকে উল্লেখযোগ্যভাবে প্রভাবিত করার সম্ভাবনা কম, কারণ একমাত্র প্রভাব হল ক্লায়েন্ট স্যাম্পলিং এর কারণে বৈচিত্র্য হ্রাস করা (আসলে আমরা যাচাই করব যে এটি আমাদের ক্ষেত্রে নয়)।
সেই লক্ষ্যে, আমরা প্রথমে ক্রমবর্ধমান শব্দের সাথে প্রতি রাউন্ডে 50 জন ক্লায়েন্টের সাথে মডেলের একটি সিরিজ প্রশিক্ষণ দিই। বিশেষত, আমরা "noise_multiplier" বাড়াই যা ক্লিপিং আদর্শের সাথে নয়েজ স্ট্যান্ডার্ড বিচ্যুতির অনুপাত। যেহেতু আমরা অভিযোজিত ক্লিপিং ব্যবহার করছি, এর মানে হল শব্দের প্রকৃত মাত্রা বৃত্তাকার থেকে বৃত্তাকারে পরিবর্তিত হয়।
# Run five clients per thread. Increase this if your runtime is running out of
# memory. Decrease it if you have the resources and want to speed up execution.
tff.backends.native.set_local_python_execution_context(clients_per_thread=5)
total_clients = len(train_data.client_ids)
def train(rounds, noise_multiplier, clients_per_round, data_frame):
# Using the `dp_aggregator` here turns on differential privacy with adaptive
# clipping.
aggregation_factory = tff.learning.model_update_aggregator.dp_aggregator(
noise_multiplier, clients_per_round)
# We use Poisson subsampling which gives slightly tighter privacy guarantees
# compared to having a fixed number of clients per round. The actual number of
# clients per round is stochastic with mean clients_per_round.
sampling_prob = clients_per_round / total_clients
# Build a federated averaging process.
# Typically a non-adaptive server optimizer is used because the noise in the
# updates can cause the second moment accumulators to become very large
# prematurely.
learning_process = tff.learning.build_federated_averaging_process(
my_model_fn,
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.01),
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(1.0, momentum=0.9),
model_update_aggregation_factory=aggregation_factory)
eval_process = tff.learning.build_federated_evaluation(my_model_fn)
# Training loop.
state = learning_process.initialize()
for round in range(rounds):
if round % 5 == 0:
metrics = eval_process(state.model, [test_data])['eval']
if round < 25 or round % 25 == 0:
print(f'Round {round:3d}: {metrics}')
data_frame = data_frame.append({'Round': round,
'NoiseMultiplier': noise_multiplier,
**metrics}, ignore_index=True)
# Sample clients for a round. Note that if your dataset is large and
# sampling_prob is small, it would be faster to use gap sampling.
x = np.random.uniform(size=total_clients)
sampled_clients = [
train_data.client_ids[i] for i in range(total_clients)
if x[i] < sampling_prob]
sampled_train_data = [
train_data.create_tf_dataset_for_client(client)
for client in sampled_clients]
# Use selected clients for update.
state, metrics = learning_process.next(state, sampled_train_data)
metrics = eval_process(state.model, [test_data])['eval']
print(f'Round {rounds:3d}: {metrics}')
data_frame = data_frame.append({'Round': rounds,
'NoiseMultiplier': noise_multiplier,
**metrics}, ignore_index=True)
return data_frame
data_frame = pd.DataFrame()
rounds = 100
clients_per_round = 50
for noise_multiplier in [0.0, 0.5, 0.75, 1.0]:
print(f'Starting training with noise multiplier: {noise_multiplier}')
data_frame = train(rounds, noise_multiplier, clients_per_round, data_frame)
print()
Starting training with noise multiplier: 0.0
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.112289384), ('loss', 2.5190482)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.19075724), ('loss', 2.2449977)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.18115693), ('loss', 2.163907)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.49970612), ('loss', 2.01017)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.5333317), ('loss', 1.8350543)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.5828517), ('loss', 1.6551636)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.7352077), ('loss', 0.8700141)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.7769152), ('loss', 0.6992781)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.8049814), ('loss', 0.62453026)])
Starting training with noise multiplier: 0.5
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.09526841), ('loss', 2.4332638)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.20128821), ('loss', 2.2664592)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.35472178), ('loss', 2.130336)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.5480995), ('loss', 1.9713942)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.42246276), ('loss', 1.8045483)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.624902), ('loss', 1.4785467)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.7265625), ('loss', 0.85801566)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.77720904), ('loss', 0.70615387)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.7702537), ('loss', 0.72331005)])
Starting training with noise multiplier: 0.75
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.098672606), ('loss', 2.422002)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.11794671), ('loss', 2.2227976)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.3208513), ('loss', 2.083766)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.49752644), ('loss', 1.8728142)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.5816761), ('loss', 1.6084186)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.62896746), ('loss', 1.378527)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.73153406), ('loss', 0.8705139)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.7789724), ('loss', 0.7113147)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.70944357), ('loss', 0.89495045)])
Starting training with noise multiplier: 1.0
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.12002841), ('loss', 2.60482)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.104574844), ('loss', 2.3388205)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.29966694), ('loss', 2.089262)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.4067398), ('loss', 1.9109797)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.5123677), ('loss', 1.6472703)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.56416535), ('loss', 1.4362282)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.62323666), ('loss', 1.1682972)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.55968356), ('loss', 1.4779186)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.382837), ('loss', 1.9680436)])
এখন আমরা মূল্যায়ন সেটের নির্ভুলতা এবং সেই রানের ক্ষতি কল্পনা করতে পারি।
import matplotlib.pyplot as plt
import seaborn as sns
def make_plot(data_frame):
plt.figure(figsize=(15, 5))
dff = data_frame.rename(
columns={'sparse_categorical_accuracy': 'Accuracy', 'loss': 'Loss'})
plt.subplot(121)
sns.lineplot(data=dff, x='Round', y='Accuracy', hue='NoiseMultiplier', palette='dark')
plt.subplot(122)
sns.lineplot(data=dff, x='Round', y='Loss', hue='NoiseMultiplier', palette='dark')
make_plot(data_frame)
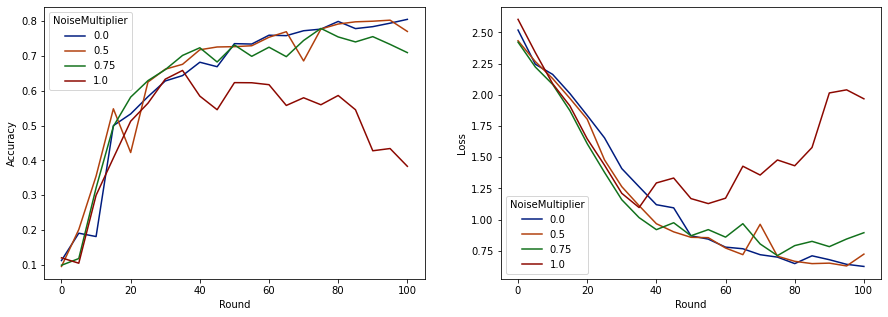
দেখা যাচ্ছে যে প্রতি রাউন্ডে 50 জন প্রত্যাশিত ক্লায়েন্টের সাথে, এই মডেলটি মডেলের গুণমানকে অবনমিত না করে 0.5 পর্যন্ত একটি শব্দ গুণক সহ্য করতে পারে। 0.75 এর একটি শব্দ গুণক মডেলের কিছুটা অবনতির কারণ বলে মনে হয় এবং 1.0 মডেলটিকে বিচ্ছিন্ন করে দেয়।
মডেলের গুণমান এবং গোপনীয়তার মধ্যে সাধারণত একটি ট্রেডঅফ থাকে। আমরা যত বেশি শব্দ ব্যবহার করি, আমরা একই পরিমাণ প্রশিক্ষণের সময় এবং ক্লায়েন্ট সংখ্যার জন্য তত বেশি গোপনীয়তা পেতে পারি। বিপরীতভাবে, কম শব্দের সাথে, আমাদের আরও সঠিক মডেল থাকতে পারে, কিন্তু আমাদের লক্ষ্য গোপনীয়তার স্তরে পৌঁছানোর জন্য প্রতি রাউন্ডে আরও বেশি ক্লায়েন্টের সাথে প্রশিক্ষণ নিতে হবে।
উপরের পরীক্ষার মাধ্যমে, আমরা সিদ্ধান্ত নিতে পারি যে চূড়ান্ত মডেলটিকে দ্রুত প্রশিক্ষণ দেওয়ার জন্য 0.75-এ ছোট পরিমাণ মডেলের অবনতি গ্রহণযোগ্য, কিন্তু ধরা যাক আমরা 0.5 নয়েজ-মাল্টিপ্লায়ার মডেলের পারফরম্যান্সের সাথে মেলাতে চাই।
এখন আমরা tensorflow_privacy ফাংশন ব্যবহার করে নির্ধারণ করতে পারি যে প্রতি রাউন্ডে কতজন প্রত্যাশিত ক্লায়েন্ট আমাদের গ্রহণযোগ্য গোপনীয়তা পেতে হবে। স্ট্যান্ডার্ড অনুশীলন হল ডেটাসেটে রেকর্ডের সংখ্যার চেয়ে একের চেয়ে কিছুটা ছোট ডেল্টা বেছে নেওয়া। এই ডেটাসেটের মোট 3383 জন প্রশিক্ষণ ব্যবহারকারী রয়েছে, তাই আসুন লক্ষ্য করা যাক (2, 1e-5)-DP-এর জন্য।
আমরা প্রতি রাউন্ডে ক্লায়েন্টের সংখ্যার উপর একটি সাধারণ বাইনারি অনুসন্ধান ব্যবহার করি। Tensorflow_privacy ফাংশন আমরা Epsilon অনুমান করার জন্য ব্যবহার করেন তার উপর ভিত্তি করে তৈরি ওয়াং এট অল। (2018) এবং Mironov এট অল। (2019) ।
rdp_orders = ([1.25, 1.5, 1.75, 2., 2.25, 2.5, 3., 3.5, 4., 4.5] +
list(range(5, 64)) + [128, 256, 512])
total_clients = 3383
base_noise_multiplier = 0.5
base_clients_per_round = 50
target_delta = 1e-5
target_eps = 2
def get_epsilon(clients_per_round):
# If we use this number of clients per round and proportionally
# scale up the noise multiplier, what epsilon do we achieve?
q = clients_per_round / total_clients
noise_multiplier = base_noise_multiplier
noise_multiplier *= clients_per_round / base_clients_per_round
rdp = tfp.compute_rdp(
q, noise_multiplier=noise_multiplier, steps=rounds, orders=rdp_orders)
eps, _, _ = tfp.get_privacy_spent(rdp_orders, rdp, target_delta=target_delta)
return clients_per_round, eps, noise_multiplier
def find_needed_clients_per_round():
hi = get_epsilon(base_clients_per_round)
if hi[1] < target_eps:
return hi
# Grow interval exponentially until target_eps is exceeded.
while True:
lo = hi
hi = get_epsilon(2 * lo[0])
if hi[1] < target_eps:
break
# Binary search.
while hi[0] - lo[0] > 1:
mid = get_epsilon((lo[0] + hi[0]) // 2)
if mid[1] > target_eps:
lo = mid
else:
hi = mid
return hi
clients_per_round, _, noise_multiplier = find_needed_clients_per_round()
print(f'To get ({target_eps}, {target_delta})-DP, use {clients_per_round} '
f'clients with noise multiplier {noise_multiplier}.')
To get (2, 1e-05)-DP, use 120 clients with noise multiplier 1.2.
এখন আমরা মুক্তির জন্য আমাদের চূড়ান্ত ব্যক্তিগত মডেলকে প্রশিক্ষণ দিতে পারি।
rounds = 100
noise_multiplier = 1.2
clients_per_round = 120
data_frame = pd.DataFrame()
data_frame = train(rounds, noise_multiplier, clients_per_round, data_frame)
make_plot(data_frame)
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.08260678), ('loss', 2.6334999)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.1492212), ('loss', 2.259542)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.28847474), ('loss', 2.155699)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.3989518), ('loss', 2.0156953)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.5086697), ('loss', 1.8261365)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.6204692), ('loss', 1.5602393)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.70008814), ('loss', 0.91155165)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.78421336), ('loss', 0.6820159)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.7955525), ('loss', 0.6585961)])
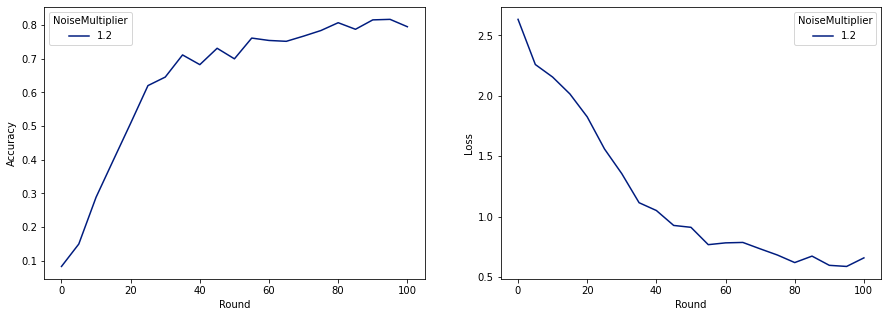
যেমনটি আমরা দেখতে পাচ্ছি, চূড়ান্ত মডেলের একই রকম ক্ষতি এবং নির্ভুলতা আছে যা গোলমাল ছাড়াই প্রশিক্ষিত মডেলের মতো, কিন্তু এটি (2, 1e-5)-DP-কে সন্তুষ্ট করে।