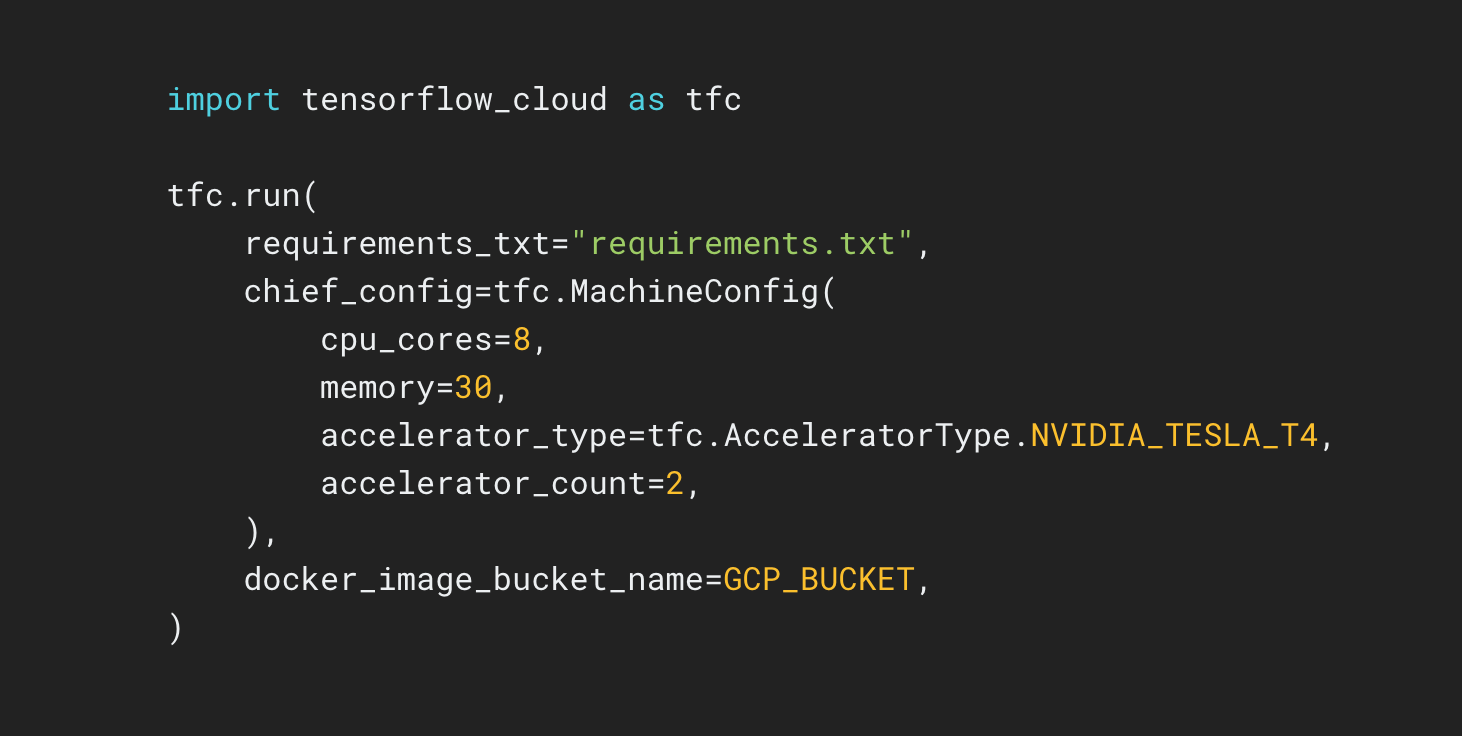
TensorFlow Cloud یک کتابخانه برای اتصال محیط محلی شما به Google Cloud است.
import tensorflow_cloud as tfc TF_GPU_IMAGE = "tensorflow/tensorflow:latest-gpu" run_parameters = { distribution_strategy='auto', requirements_txt='requirements.txt', docker_config=tfc.DockerConfig( parent_image=TF_GPU_IMAGE, image_build_bucket=GCS_BUCKET ), chief_config=tfc.COMMON_MACHINE_CONFIGS['K80_1X'], worker_config=tfc.COMMON_MACHINE_CONFIGS['K80_1X'], worker_count=3, job_labels={'job': "my_job"} } tfc.run(**run_parameters) # Runs your training on Google Cloud!
مخزن TensorFlow Cloud API هایی را ارائه می دهد که انتقال از ساخت مدل محلی و اشکال زدایی به آموزش توزیع شده و تنظیم هایپرپارامتر در Google Cloud را آسان می کند. از داخل یک نوت بوک Colab یا Kaggle یا یک فایل اسکریپت محلی، می توانید مدل خود را برای تنظیم یا آموزش در Cloud مستقیماً بدون نیاز به استفاده از Cloud Console ارسال کنید.