
| | |  Ver fuente en GitHub Ver fuente en GitHub |
Documentación API: tf.RaggedTensor tf.ragged
Configuración
import math
import tensorflow as tf
Descripción general
Sus datos vienen en muchas formas; sus tensores también deberían hacerlo. Los tensores irregulares son el equivalente de TensorFlow de las listas anidadas de longitud variable. Facilitan el almacenamiento y el procesamiento de datos con formas no uniformes, que incluyen:
- Características de duración variable, como el conjunto de actores en una película.
- Lotes de entradas secuenciales de longitud variable, como oraciones o videoclips.
- Entradas jerárquicas, como documentos de texto que se subdividen en secciones, párrafos, oraciones y palabras.
- Campos individuales en entradas estructuradas, como búferes de protocolo.
Lo que puedes hacer con un tensor irregular
Los tensores irregulares son compatibles con más de cien operaciones de TensorFlow, incluidas operaciones matemáticas (como tf.add y tf.reduce_mean ), operaciones de matrices (como tf.concat y tf.tile ), operaciones de manipulación de cadenas (como tf.substr ), operaciones de flujo de control (como tf.while_loop y tf.map_fn ), y muchas otras:
digits = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
words = tf.ragged.constant([["So", "long"], ["thanks", "for", "all", "the", "fish"]])
print(tf.add(digits, 3))
print(tf.reduce_mean(digits, axis=1))
print(tf.concat([digits, [[5, 3]]], axis=0))
print(tf.tile(digits, [1, 2]))
print(tf.strings.substr(words, 0, 2))
print(tf.map_fn(tf.math.square, digits))
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]> tf.Tensor([2.25 nan 5.33333333 6. nan], shape=(5,), dtype=float64) <tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], [], [5, 3]]> <tf.RaggedTensor [[3, 1, 4, 1, 3, 1, 4, 1], [], [5, 9, 2, 5, 9, 2], [6, 6], []]> <tf.RaggedTensor [[b'So', b'lo'], [b'th', b'fo', b'al', b'th', b'fi']]> <tf.RaggedTensor [[9, 1, 16, 1], [], [25, 81, 4], [36], []]>
También hay una serie de métodos y operaciones que son específicos de los tensores irregulares, incluidos los métodos de fábrica, los métodos de conversión y las operaciones de mapeo de valores. Para obtener una lista de las operaciones admitidas, consulte la documentación del paquete tf.ragged .
Los tensores irregulares son compatibles con muchas API de TensorFlow, incluidas Keras , Datasets , tf.function , SavedModels y tf.Example . Para obtener más información, consulte la sección sobre las API de TensorFlow a continuación.
Al igual que con los tensores normales, puede usar la indexación al estilo de Python para acceder a segmentos específicos de un tensor irregular. Para obtener más información, consulte la sección sobre indexación a continuación.
print(digits[0]) # First row
tf.Tensor([3 1 4 1], shape=(4,), dtype=int32)de posición5
print(digits[:, :2]) # First two values in each row.
<tf.RaggedTensor [[3, 1], [], [5, 9], [6], []]>
print(digits[:, -2:]) # Last two values in each row.
<tf.RaggedTensor [[4, 1], [], [9, 2], [6], []]>
Y al igual que los tensores normales, puede usar operadores aritméticos y de comparación de Python para realizar operaciones por elementos. Para obtener más información, consulte la sección sobre operadores sobrecargados a continuación.
print(digits + 3)
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]>
print(digits + tf.ragged.constant([[1, 2, 3, 4], [], [5, 6, 7], [8], []]))
<tf.RaggedTensor [[4, 3, 7, 5], [], [10, 15, 9], [14], []]>
Si necesita realizar una transformación de elementos a los valores de RaggedTensor , puede usar tf.ragged.map_flat_values , que toma una función más uno o más argumentos y aplica la función para transformar los valores de RaggedTensor .
times_two_plus_one = lambda x: x * 2 + 1
print(tf.ragged.map_flat_values(times_two_plus_one, digits))
<tf.RaggedTensor [[7, 3, 9, 3], [], [11, 19, 5], [13], []]>
Los tensores irregulares se pueden convertir en list Python anidadas y array NumPy:
digits.to_list()
[[3, 1, 4, 1], [], [5, 9, 2], [6], []]
digits.numpy()
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
return np.array(rows)
array([array([3, 1, 4, 1], dtype=int32), array([], dtype=int32),
array([5, 9, 2], dtype=int32), array([6], dtype=int32),
array([], dtype=int32)], dtype=object)
Construcción de un tensor irregular
La forma más sencilla de construir un tensor irregular es usar tf.ragged.constant , que construye el RaggedTensor correspondiente a una list anidada de Python o array NumPy:
sentences = tf.ragged.constant([
["Let's", "build", "some", "ragged", "tensors", "!"],
["We", "can", "use", "tf.ragged.constant", "."]])
print(sentences)
<tf.RaggedTensor [[b"Let's", b'build', b'some', b'ragged', b'tensors', b'!'], [b'We', b'can', b'use', b'tf.ragged.constant', b'.']]>
paragraphs = tf.ragged.constant([
[['I', 'have', 'a', 'cat'], ['His', 'name', 'is', 'Mat']],
[['Do', 'you', 'want', 'to', 'come', 'visit'], ["I'm", 'free', 'tomorrow']],
])
print(paragraphs)
<tf.RaggedTensor [[[b'I', b'have', b'a', b'cat'], [b'His', b'name', b'is', b'Mat']], [[b'Do', b'you', b'want', b'to', b'come', b'visit'], [b"I'm", b'free', b'tomorrow']]]>
Los tensores irregulares también se pueden construir emparejando tensores de valores planos con tensores de partición de filas que indican cómo se deben dividir esos valores en filas, utilizando métodos de clase de fábrica como tf.RaggedTensor.from_value_rowids , tf.RaggedTensor.from_row_lengths y tf.RaggedTensor.from_row_splits .
tf.RaggedTensor.from_value_rowids
Si sabe a qué fila pertenece cada valor, entonces puede construir un RaggedTensor usando un tensor de partición de fila value_rowids :
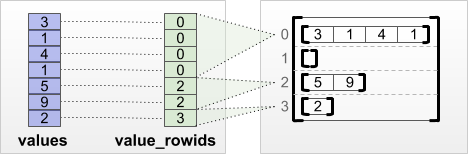
print(tf.RaggedTensor.from_value_rowids(
values=[3, 1, 4, 1, 5, 9, 2],
value_rowids=[0, 0, 0, 0, 2, 2, 3]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_lengths
Si sabe cuánto mide cada fila, entonces puede usar un row_lengths de partición de filas de longitudes de fila:
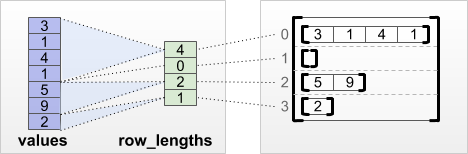
print(tf.RaggedTensor.from_row_lengths(
values=[3, 1, 4, 1, 5, 9, 2],
row_lengths=[4, 0, 2, 1]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_splits
Si conoce el índice donde comienza y termina cada fila, entonces puede usar un tensor de partición de filas row_splits :
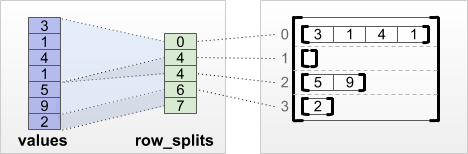
print(tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
Consulte la documentación de la clase tf.RaggedTensor para obtener una lista completa de los métodos de fábrica.
Lo que puedes almacenar en un tensor irregular
Al igual que con los Tensor normales, los valores en un RaggedTensor deben tener todos el mismo tipo; y todos los valores deben estar a la misma profundidad de anidamiento (el rango del tensor):
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]])) # ok: type=string, rank=2
<tf.RaggedTensor [[b'Hi'], [b'How', b'are', b'you']]>
print(tf.ragged.constant([[[1, 2], [3]], [[4, 5]]])) # ok: type=int32, rank=3
<tf.RaggedTensor [[[1, 2], [3]], [[4, 5]]]>
try:
tf.ragged.constant([["one", "two"], [3, 4]]) # bad: multiple types
except ValueError as exception:
print(exception)
Can't convert Python sequence with mixed types to Tensor.
try:
tf.ragged.constant(["A", ["B", "C"]]) # bad: multiple nesting depths
except ValueError as exception:
print(exception)
all scalar values must have the same nesting depth
Ejemplo de caso de uso
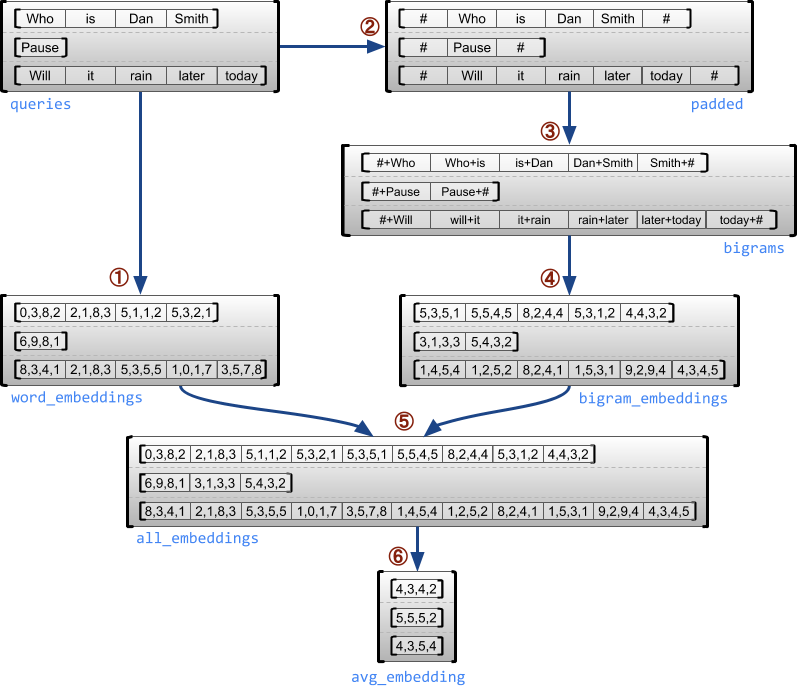
El siguiente ejemplo demuestra cómo se pueden usar RaggedTensor s para construir y combinar incrustaciones de unigramas y bigramas para un lote de consultas de longitud variable, usando marcadores especiales para el principio y el final de cada oración. Para obtener más detalles sobre las operaciones utilizadas en este ejemplo, consulte la documentación del paquete tf.ragged .
queries = tf.ragged.constant([['Who', 'is', 'Dan', 'Smith'],
['Pause'],
['Will', 'it', 'rain', 'later', 'today']])
# Create an embedding table.
num_buckets = 1024
embedding_size = 4
embedding_table = tf.Variable(
tf.random.truncated_normal([num_buckets, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
# Look up the embedding for each word.
word_buckets = tf.strings.to_hash_bucket_fast(queries, num_buckets)
word_embeddings = tf.nn.embedding_lookup(embedding_table, word_buckets) # ①
# Add markers to the beginning and end of each sentence.
marker = tf.fill([queries.nrows(), 1], '#')
padded = tf.concat([marker, queries, marker], axis=1) # ②
# Build word bigrams and look up embeddings.
bigrams = tf.strings.join([padded[:, :-1], padded[:, 1:]], separator='+') # ③
bigram_buckets = tf.strings.to_hash_bucket_fast(bigrams, num_buckets)
bigram_embeddings = tf.nn.embedding_lookup(embedding_table, bigram_buckets) # ④
# Find the average embedding for each sentence
all_embeddings = tf.concat([word_embeddings, bigram_embeddings], axis=1) # ⑤
avg_embedding = tf.reduce_mean(all_embeddings, axis=1) # ⑥
print(avg_embedding)
tf.Tensor( [[-0.14285272 0.02908629 -0.16327512 -0.14529026] [-0.4479212 -0.35615516 0.17110227 0.2522229 ] [-0.1987868 -0.13152348 -0.0325102 0.02125177]], shape=(3, 4), dtype=float32)
Dimensiones irregulares y uniformes
Una dimensión irregular es una dimensión cuyos cortes pueden tener diferentes longitudes. Por ejemplo, la dimensión interna (columna) de rt=[[3, 1, 4, 1], [], [5, 9, 2], [6], []] es irregular, ya que la columna divide ( rt[0, :] , ..., rt[4, :] ) tienen diferentes longitudes. Las dimensiones cuyas rebanadas tienen todas la misma longitud se denominan dimensiones uniformes .
La dimensión más externa de un tensor irregular siempre es uniforme, ya que consiste en un solo corte (y, por lo tanto, no hay posibilidad de diferentes longitudes de corte). Las dimensiones restantes pueden ser irregulares o uniformes. Por ejemplo, puede almacenar las incrustaciones de palabras para cada palabra en un lote de oraciones usando un tensor irregular con forma [num_sentences, (num_words), embedding_size] , donde los paréntesis alrededor (num_words) indican que la dimensión es irregular.
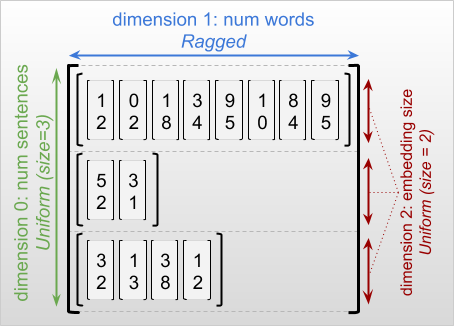
Los tensores irregulares pueden tener varias dimensiones irregulares. Por ejemplo, podría almacenar un lote de documentos de texto estructurado usando un tensor con forma [num_documents, (num_paragraphs), (num_sentences), (num_words)] (donde nuevamente se usan paréntesis para indicar dimensiones irregulares).
Al igual que con tf.Tensor , el rango de un tensor irregular es su número total de dimensiones (incluidas las dimensiones irregulares y uniformes). Un tensor potencialmente irregular es un valor que podría ser un tf.Tensor o un tf.RaggedTensor .
Al describir la forma de un RaggedTensor, las dimensiones irregulares se indican convencionalmente encerrándolas entre paréntesis. Por ejemplo, como vio anteriormente, la forma de un RaggedTensor 3D que almacena incrustaciones de palabras para cada palabra en un lote de oraciones se puede escribir como [num_sentences, (num_words), embedding_size] .
El atributo RaggedTensor.shape devuelve un tf.TensorShape para un tensor irregular donde las dimensiones irregulares tienen un tamaño None :
tf.ragged.constant([["Hi"], ["How", "are", "you"]]).shape
TensorShape([2, None])
El método tf.RaggedTensor.bounding_shape se puede usar para encontrar una forma de límite estrecho para un RaggedTensor dado:
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]]).bounding_shape())
tf.Tensor([2 3], shape=(2,), dtype=int64)
Irregular vs escaso
Un tensor irregular no debe considerarse como un tipo de tensor disperso. En particular, los tensores dispersos son codificaciones eficientes para tf.Tensor que modelan los mismos datos en un formato compacto; pero el tensor irregular es una extensión de tf.Tensor que modela una clase de datos ampliada. Esta diferencia es crucial a la hora de definir operaciones:
- Aplicar un op a un tensor disperso o denso siempre debería dar el mismo resultado.
- La aplicación de una op a un tensor irregular o disperso puede dar resultados diferentes.
Como ejemplo ilustrativo, considere cómo se definen las operaciones de matriz como concat , stack y tile para tensores irregulares frente a dispersos. La concatenación de tensores irregulares une cada fila para formar una sola fila con la longitud combinada:

ragged_x = tf.ragged.constant([["John"], ["a", "big", "dog"], ["my", "cat"]])
ragged_y = tf.ragged.constant([["fell", "asleep"], ["barked"], ["is", "fuzzy"]])
print(tf.concat([ragged_x, ragged_y], axis=1))
<tf.RaggedTensor [[b'John', b'fell', b'asleep'], [b'a', b'big', b'dog', b'barked'], [b'my', b'cat', b'is', b'fuzzy']]>
Sin embargo, concatenar tensores dispersos es equivalente a concatenar los tensores densos correspondientes, como se ilustra en el siguiente ejemplo (donde Ø indica valores faltantes):
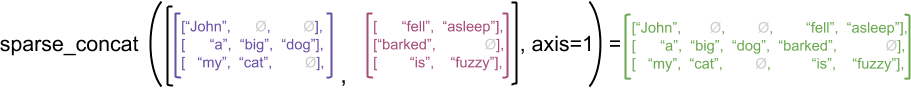
sparse_x = ragged_x.to_sparse()
sparse_y = ragged_y.to_sparse()
sparse_result = tf.sparse.concat(sp_inputs=[sparse_x, sparse_y], axis=1)
print(tf.sparse.to_dense(sparse_result, ''))
tf.Tensor( [[b'John' b'' b'' b'fell' b'asleep'] [b'a' b'big' b'dog' b'barked' b''] [b'my' b'cat' b'' b'is' b'fuzzy']], shape=(3, 5), dtype=string)
Para ver otro ejemplo de por qué esta distinción es importante, considere la definición de "el valor medio de cada fila" para una operación como tf.reduce_mean . Para un tensor irregular, el valor medio de una fila es la suma de los valores de la fila dividida por el ancho de la fila. Pero para un tensor disperso, el valor medio de una fila es la suma de los valores de la fila dividida por el ancho total del tensor disperso (que es mayor o igual que el ancho de la fila más larga).
API de TensorFlow
Keras
tf.keras es la API de alto nivel de TensorFlow para crear y entrenar modelos de aprendizaje profundo. Los tensores irregulares se pueden pasar como entradas a un modelo de Keras configurando ragged=True en tf.keras.Input o tf.keras.layers.InputLayer . Los tensores irregulares también se pueden pasar entre las capas de Keras y los modelos de Keras los devuelven. El siguiente ejemplo muestra un modelo LSTM de juguete que se entrena con tensores irregulares.
# Task: predict whether each sentence is a question or not.
sentences = tf.constant(
['What makes you think she is a witch?',
'She turned me into a newt.',
'A newt?',
'Well, I got better.'])
is_question = tf.constant([True, False, True, False])
# Preprocess the input strings.
hash_buckets = 1000
words = tf.strings.split(sentences, ' ')
hashed_words = tf.strings.to_hash_bucket_fast(words, hash_buckets)
# Build the Keras model.
keras_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[None], dtype=tf.int64, ragged=True),
tf.keras.layers.Embedding(hash_buckets, 16),
tf.keras.layers.LSTM(32, use_bias=False),
tf.keras.layers.Dense(32),
tf.keras.layers.Activation(tf.nn.relu),
tf.keras.layers.Dense(1)
])
keras_model.compile(loss='binary_crossentropy', optimizer='rmsprop')
keras_model.fit(hashed_words, is_question, epochs=5)
print(keras_model.predict(hashed_words))
WARNING:tensorflow:Layer lstm will not use cuDNN kernels since it doesn't meet the criteria. It will use a generic GPU kernel as fallback when running on GPU.
Epoch 1/5
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:449: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask_1/GatherV2:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask/GatherV2:0", shape=(None, 16), dtype=float32), dense_shape=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/Shape:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
1/1 [==============================] - 2s 2s/step - loss: 3.1269
Epoch 2/5
1/1 [==============================] - 0s 18ms/step - loss: 2.1197
Epoch 3/5
1/1 [==============================] - 0s 19ms/step - loss: 2.0196
Epoch 4/5
1/1 [==============================] - 0s 20ms/step - loss: 1.9371
Epoch 5/5
1/1 [==============================] - 0s 18ms/step - loss: 1.8857
[[0.02800461]
[0.00945962]
[0.02283431]
[0.00252927]]
tf.Ejemplo
tf.Example es una codificación protobuf estándar para datos de TensorFlow. Los datos codificados con tf.Example s a menudo incluyen características de longitud variable. Por ejemplo, el siguiente código define un lote de cuatro mensajes tf.Example con diferentes longitudes de características:
import google.protobuf.text_format as pbtext
def build_tf_example(s):
return pbtext.Merge(s, tf.train.Example()).SerializeToString()
example_batch = [
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["red", "blue"]} } }
feature {key: "lengths" value {int64_list {value: [7]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["orange"]} } }
feature {key: "lengths" value {int64_list {value: []} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["black", "yellow"]} } }
feature {key: "lengths" value {int64_list {value: [1, 3]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["green"]} } }
feature {key: "lengths" value {int64_list {value: [3, 5, 2]} } } }''')]
Puede analizar estos datos codificados usando tf.io.parse_example , que toma un tensor de cadenas serializadas y un diccionario de especificación de funciones, y devuelve un diccionario que asigna nombres de funciones a tensores. Para leer las características de longitud variable en tensores irregulares, simplemente use tf.io.RaggedFeature en el diccionario de especificación de características:
feature_specification = {
'colors': tf.io.RaggedFeature(tf.string),
'lengths': tf.io.RaggedFeature(tf.int64),
}
feature_tensors = tf.io.parse_example(example_batch, feature_specification)
for name, value in feature_tensors.items():
print("{}={}".format(name, value))
colors=<tf.RaggedTensor [[b'red', b'blue'], [b'orange'], [b'black', b'yellow'], [b'green']]> lengths=<tf.RaggedTensor [[7], [], [1, 3], [3, 5, 2]]>
tf.io.RaggedFeature también se puede usar para leer entidades con varias dimensiones irregulares. Para obtener más información, consulte la documentación de la API .
conjuntos de datos
tf.data es una API que le permite crear canalizaciones de entrada complejas a partir de piezas simples y reutilizables. Su estructura de datos central es tf.data.Dataset , que representa una secuencia de elementos, en la que cada elemento consta de uno o más componentes.
# Helper function used to print datasets in the examples below.
def print_dictionary_dataset(dataset):
for i, element in enumerate(dataset):
print("Element {}:".format(i))
for (feature_name, feature_value) in element.items():
print('{:>14} = {}'.format(feature_name, feature_value))
Creación de conjuntos de datos con tensores irregulares
Los conjuntos de datos se pueden construir a partir de tensores irregulares usando los mismos métodos que se usan para construirlos a partir de tf.Tensor s o NumPy array s, como Dataset.from_tensor_slices :
dataset = tf.data.Dataset.from_tensor_slices(feature_tensors)
print_dictionary_dataset(dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
Conjuntos de datos por lotes y sin lotes con tensores irregulares
Los conjuntos de datos con tensores irregulares se pueden agrupar (lo que combina n elementos consecutivos en un solo elemento) mediante el método Dataset.batch .
batched_dataset = dataset.batch(2)
print_dictionary_dataset(batched_dataset)
Element 0:
colors = <tf.RaggedTensor [[b'red', b'blue'], [b'orange']]>
lengths = <tf.RaggedTensor [[7], []]>
Element 1:
colors = <tf.RaggedTensor [[b'black', b'yellow'], [b'green']]>
lengths = <tf.RaggedTensor [[1, 3], [3, 5, 2]]>
Por el contrario, un conjunto de datos por lotes se puede transformar en un conjunto de datos plano mediante Dataset.unbatch .
unbatched_dataset = batched_dataset.unbatch()
print_dictionary_dataset(unbatched_dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
Lotes de conjuntos de datos con tensores no irregulares de longitud variable
Si tiene un conjunto de datos que contiene tensores no irregulares y las longitudes de los tensores varían según los elementos, puede agrupar esos tensores no irregulares en tensores irregulares aplicando la transformación dense_to_ragged_batch :
non_ragged_dataset = tf.data.Dataset.from_tensor_slices([1, 5, 3, 2, 8])
non_ragged_dataset = non_ragged_dataset.map(tf.range)
batched_non_ragged_dataset = non_ragged_dataset.apply(
tf.data.experimental.dense_to_ragged_batch(2))
for element in batched_non_ragged_dataset:
print(element)
<tf.RaggedTensor [[0], [0, 1, 2, 3, 4]]> <tf.RaggedTensor [[0, 1, 2], [0, 1]]> <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6, 7]]>
Transformar conjuntos de datos con tensores irregulares
También puede crear o transformar tensores irregulares en conjuntos de datos usando Dataset.map :
def transform_lengths(features):
return {
'mean_length': tf.math.reduce_mean(features['lengths']),
'length_ranges': tf.ragged.range(features['lengths'])}
transformed_dataset = dataset.map(transform_lengths)
print_dictionary_dataset(transformed_dataset)
Element 0: mean_length = 7 length_ranges = <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6]]> Element 1: mean_length = 0 length_ranges = <tf.RaggedTensor []> Element 2: mean_length = 2 length_ranges = <tf.RaggedTensor [[0], [0, 1, 2]]> Element 3: mean_length = 3 length_ranges = <tf.RaggedTensor [[0, 1, 2], [0, 1, 2, 3, 4], [0, 1]]>
función tf
tf.function es un decorador que precalcula gráficos de TensorFlow para funciones de Python, lo que puede mejorar sustancialmente el rendimiento de su código de TensorFlow. Los tensores irregulares se pueden usar de forma transparente con funciones @tf.function . Por ejemplo, la siguiente función funciona con tensores irregulares y no irregulares:
@tf.function
def make_palindrome(x, axis):
return tf.concat([x, tf.reverse(x, [axis])], axis)
make_palindrome(tf.constant([[1, 2], [3, 4], [5, 6]]), axis=1)
<tf.Tensor: shape=(3, 4), dtype=int32, numpy=
array([[1, 2, 2, 1],
[3, 4, 4, 3],
[5, 6, 6, 5]], dtype=int32)>
make_palindrome(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]), axis=1)
2021-09-22 20:36:51.018367: W tensorflow/core/grappler/optimizers/loop_optimizer.cc:907] Skipping loop optimization for Merge node with control input: RaggedConcat/assert_equal_1/Assert/AssertGuard/branch_executed/_9 <tf.RaggedTensor [[1, 2, 2, 1], [3, 3], [4, 5, 6, 6, 5, 4]]>
Si desea especificar explícitamente input_signature para tf.function , puede hacerlo usando tf.RaggedTensorSpec .
@tf.function(
input_signature=[tf.RaggedTensorSpec(shape=[None, None], dtype=tf.int32)])
def max_and_min(rt):
return (tf.math.reduce_max(rt, axis=-1), tf.math.reduce_min(rt, axis=-1))
max_and_min(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]))
(<tf.Tensor: shape=(3,), dtype=int32, numpy=array([2, 3, 6], dtype=int32)>, <tf.Tensor: shape=(3,), dtype=int32, numpy=array([1, 3, 4], dtype=int32)>)
Funciones concretas
Las funciones concretas encapsulan gráficos trazados individuales creados por tf.function . Los tensores irregulares se pueden usar de forma transparente con funciones concretas.
@tf.function
def increment(x):
return x + 1
rt = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
cf = increment.get_concrete_function(rt)
print(cf(rt))
<tf.RaggedTensor [[2, 3], [4], [5, 6, 7]]>
Modelos guardados
Un modelo guardado es un programa TensorFlow serializado que incluye pesos y cálculos. Se puede construir a partir de un modelo Keras oa partir de un modelo personalizado. En cualquier caso, los tensores irregulares se pueden usar de forma transparente con las funciones y métodos definidos por un modelo guardado.
Ejemplo: guardar un modelo de Keras
import tempfile
keras_module_path = tempfile.mkdtemp()
tf.saved_model.save(keras_model, keras_module_path)
imported_model = tf.saved_model.load(keras_module_path)
imported_model(hashed_words)
2021-09-22 20:36:52.069689: W tensorflow/python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
WARNING:absl:Function `_wrapped_model` contains input name(s) args_0 with unsupported characters which will be renamed to args_0_1 in the SavedModel.
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
<tf.Tensor: shape=(4, 1), dtype=float32, numpy=
array([[0.02800461],
[0.00945962],
[0.02283431],
[0.00252927]], dtype=float32)>
Ejemplo: guardar un modelo personalizado
class CustomModule(tf.Module):
def __init__(self, variable_value):
super(CustomModule, self).__init__()
self.v = tf.Variable(variable_value)
@tf.function
def grow(self, x):
return x * self.v
module = CustomModule(100.0)
# Before saving a custom model, you must ensure that concrete functions are
# built for each input signature that you will need.
module.grow.get_concrete_function(tf.RaggedTensorSpec(shape=[None, None],
dtype=tf.float32))
custom_module_path = tempfile.mkdtemp()
tf.saved_model.save(module, custom_module_path)
imported_model = tf.saved_model.load(custom_module_path)
imported_model.grow(tf.ragged.constant([[1.0, 4.0, 3.0], [2.0]]))
INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets <tf.RaggedTensor [[100.0, 400.0, 300.0], [200.0]]>
Operadores sobrecargados
La clase RaggedTensor sobrecarga los operadores aritméticos y de comparación estándar de Python, lo que facilita la realización de operaciones matemáticas básicas por elementos:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
y = tf.ragged.constant([[1, 1], [2], [3, 3, 3]])
print(x + y)
<tf.RaggedTensor [[2, 3], [5], [7, 8, 9]]>
Dado que los operadores sobrecargados realizan cálculos por elementos, las entradas de todas las operaciones binarias deben tener la misma forma o se pueden transmitir a la misma forma. En el caso de transmisión más simple, un solo escalar se combina por elementos con cada valor en un tensor irregular:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
print(x + 3)
<tf.RaggedTensor [[4, 5], [6], [7, 8, 9]]>
Para una discusión de casos más avanzados, consulte la sección sobre Difusión .
Los tensores irregulares sobrecargan el mismo conjunto de operadores que los Tensor normales: los operadores unarios - , ~ y abs() ; y los operadores binarios + , - , * , / , // , % , ** , & , | , ^ , == , < , <= , > y >= .
Indexación
Los tensores irregulares admiten la indexación al estilo de Python, incluida la indexación y el corte multidimensionales. Los siguientes ejemplos demuestran la indexación de tensores irregulares con un tensor irregular 2D y 3D.
Ejemplos de indexación: tensor irregular 2D
queries = tf.ragged.constant(
[['Who', 'is', 'George', 'Washington'],
['What', 'is', 'the', 'weather', 'tomorrow'],
['Goodnight']])
print(queries[1]) # A single query
tf.Tensor([b'What' b'is' b'the' b'weather' b'tomorrow'], shape=(5,), dtype=string)
print(queries[1, 2]) # A single word
tf.Tensor(b'the', shape=(), dtype=string)
print(queries[1:]) # Everything but the first row
<tf.RaggedTensor [[b'What', b'is', b'the', b'weather', b'tomorrow'], [b'Goodnight']]>
print(queries[:, :3]) # The first 3 words of each query
<tf.RaggedTensor [[b'Who', b'is', b'George'], [b'What', b'is', b'the'], [b'Goodnight']]>
print(queries[:, -2:]) # The last 2 words of each query
<tf.RaggedTensor [[b'George', b'Washington'], [b'weather', b'tomorrow'], [b'Goodnight']]>
Ejemplos de indexación: tensor irregular 3D
rt = tf.ragged.constant([[[1, 2, 3], [4]],
[[5], [], [6]],
[[7]],
[[8, 9], [10]]])
print(rt[1]) # Second row (2D RaggedTensor)
<tf.RaggedTensor [[5], [], [6]]>
print(rt[3, 0]) # First element of fourth row (1D Tensor)
tf.Tensor([8 9], shape=(2,), dtype=int32)
print(rt[:, 1:3]) # Items 1-3 of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[], [6]], [], [[10]]]>
print(rt[:, -1:]) # Last item of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[6]], [[7]], [[10]]]>
RaggedTensor admite la indexación y el corte multidimensional con una restricción: no se permite la indexación en una dimensión irregular. Este caso es problemático porque el valor indicado puede existir en algunas filas pero no en otras. En tales casos, no es obvio si debe (1) generar un IndexError ; (2) utilizar un valor predeterminado; o (3) omita ese valor y devuelva un tensor con menos filas de las que tenía al principio. Siguiendo los principios rectores de Python ("Ante la ambigüedad, rechaza la tentación de adivinar"), esta operación no está permitida actualmente.
Conversión de tipo de tensor
La clase RaggedTensor define métodos que se pueden usar para convertir entre RaggedTensor s y tf.Tensor s o tf.SparseTensors :
ragged_sentences = tf.ragged.constant([
['Hi'], ['Welcome', 'to', 'the', 'fair'], ['Have', 'fun']])
# RaggedTensor -> Tensor
print(ragged_sentences.to_tensor(default_value='', shape=[None, 10]))
tf.Tensor( [[b'Hi' b'' b'' b'' b'' b'' b'' b'' b'' b''] [b'Welcome' b'to' b'the' b'fair' b'' b'' b'' b'' b'' b''] [b'Have' b'fun' b'' b'' b'' b'' b'' b'' b'' b'']], shape=(3, 10), dtype=string)
# Tensor -> RaggedTensor
x = [[1, 3, -1, -1], [2, -1, -1, -1], [4, 5, 8, 9]]
print(tf.RaggedTensor.from_tensor(x, padding=-1))
<tf.RaggedTensor [[1, 3], [2], [4, 5, 8, 9]]>
#RaggedTensor -> SparseTensor
print(ragged_sentences.to_sparse())
SparseTensor(indices=tf.Tensor( [[0 0] [1 0] [1 1] [1 2] [1 3] [2 0] [2 1]], shape=(7, 2), dtype=int64), values=tf.Tensor([b'Hi' b'Welcome' b'to' b'the' b'fair' b'Have' b'fun'], shape=(7,), dtype=string), dense_shape=tf.Tensor([3 4], shape=(2,), dtype=int64))
# SparseTensor -> RaggedTensor
st = tf.SparseTensor(indices=[[0, 0], [2, 0], [2, 1]],
values=['a', 'b', 'c'],
dense_shape=[3, 3])
print(tf.RaggedTensor.from_sparse(st))
<tf.RaggedTensor [[b'a'], [], [b'b', b'c']]>
Evaluación de tensores irregulares
Para acceder a los valores en un tensor irregular, puede:
- Use
tf.RaggedTensor.to_listpara convertir el tensor irregular en una lista anidada de Python. - Use
tf.RaggedTensor.numpypara convertir el tensor irregular en una matriz NumPy cuyos valores son matrices NumPy anidadas. - Descomponga el tensor irregular en sus componentes, utilizando las propiedades
tf.RaggedTensor.valuesytf.RaggedTensor.row_splits, o métodos de partición de filas comotf.RaggedTensor.row_lengthsytf.RaggedTensor.value_rowids. - Use la indexación de Python para seleccionar valores del tensor irregular.
rt = tf.ragged.constant([[1, 2], [3, 4, 5], [6], [], [7]])
print("Python list:", rt.to_list())
print("NumPy array:", rt.numpy())
print("Values:", rt.values.numpy())
print("Splits:", rt.row_splits.numpy())
print("Indexed value:", rt[1].numpy())
Python list: [[1, 2], [3, 4, 5], [6], [], [7]] NumPy array: [array([1, 2], dtype=int32) array([3, 4, 5], dtype=int32) array([6], dtype=int32) array([], dtype=int32) array([7], dtype=int32)] Values: [1 2 3 4 5 6 7] Splits: [0 2 5 6 6 7] Indexed value: [3 4 5] /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray return np.array(rows)
Radiodifusión
La transmisión es el proceso de hacer que los tensores con diferentes formas tengan formas compatibles para operaciones elementales. Para obtener más información sobre la transmisión, consulte:
Los pasos básicos para transmitir dos entradas x e y para tener formas compatibles son:
Si
xeyno tienen el mismo número de dimensiones, agregue las dimensiones exteriores (con tamaño 1) hasta que las tengan.Para cada dimensión donde
xeytienen diferentes tamaños:
- Si
xoytienen el tamaño1en la dimensiónd, repita sus valores en la dimensióndpara que coincidan con el tamaño de la otra entrada. - De lo contrario, genere una excepción (
xeyno son compatibles con la transmisión).
Donde el tamaño de un tensor en una dimensión uniforme es un solo número (el tamaño de los cortes a lo largo de esa dimensión); y el tamaño de un tensor en una dimensión irregular es una lista de longitudes de corte (para todos los cortes de esa dimensión).
Ejemplos de transmisión
# x (2D ragged): 2 x (num_rows)
# y (scalar)
# result (2D ragged): 2 x (num_rows)
x = tf.ragged.constant([[1, 2], [3]])
y = 3
print(x + y)
<tf.RaggedTensor [[4, 5], [6]]>
# x (2d ragged): 3 x (num_rows)
# y (2d tensor): 3 x 1
# Result (2d ragged): 3 x (num_rows)
x = tf.ragged.constant(
[[10, 87, 12],
[19, 53],
[12, 32]])
y = [[1000], [2000], [3000]]
print(x + y)
<tf.RaggedTensor [[1010, 1087, 1012], [2019, 2053], [3012, 3032]]>
# x (3d ragged): 2 x (r1) x 2
# y (2d ragged): 1 x 1
# Result (3d ragged): 2 x (r1) x 2
x = tf.ragged.constant(
[[[1, 2], [3, 4], [5, 6]],
[[7, 8]]],
ragged_rank=1)
y = tf.constant([[10]])
print(x + y)
<tf.RaggedTensor [[[11, 12], [13, 14], [15, 16]], [[17, 18]]]>
# x (3d ragged): 2 x (r1) x (r2) x 1
# y (1d tensor): 3
# Result (3d ragged): 2 x (r1) x (r2) x 3
x = tf.ragged.constant(
[
[
[[1], [2]],
[],
[[3]],
[[4]],
],
[
[[5], [6]],
[[7]]
]
],
ragged_rank=2)
y = tf.constant([10, 20, 30])
print(x + y)
<tf.RaggedTensor [[[[11, 21, 31], [12, 22, 32]], [], [[13, 23, 33]], [[14, 24, 34]]], [[[15, 25, 35], [16, 26, 36]], [[17, 27, 37]]]]>
Estos son algunos ejemplos de formas que no transmiten:
# x (2d ragged): 3 x (r1)
# y (2d tensor): 3 x 4 # trailing dimensions do not match
x = tf.ragged.constant([[1, 2], [3, 4, 5, 6], [7]])
y = tf.constant([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 4 b'dim_size=' 2, 4, 1
# x (2d ragged): 3 x (r1)
# y (2d ragged): 3 x (r2) # ragged dimensions do not match.
x = tf.ragged.constant([[1, 2, 3], [4], [5, 6]])
y = tf.ragged.constant([[10, 20], [30, 40], [50]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 2, 2, 1 b'dim_size=' 3, 1, 2
# x (3d ragged): 3 x (r1) x 2
# y (3d ragged): 3 x (r1) x 3 # trailing dimensions do not match
x = tf.ragged.constant([[[1, 2], [3, 4], [5, 6]],
[[7, 8], [9, 10]]])
y = tf.ragged.constant([[[1, 2, 0], [3, 4, 0], [5, 6, 0]],
[[7, 8, 0], [9, 10, 0]]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 2 b'lengths=' 3, 3, 3, 3, 3 b'dim_size=' 2, 2, 2, 2, 2
Codificación RaggedTensor
Los tensores irregulares se codifican mediante la clase RaggedTensor . Internamente, cada RaggedTensor consta de:
- Un tensor de
values, que concatena las filas de longitud variable en una lista plana. -
row_partition, que indica cómo se dividen esos valores planos en filas.
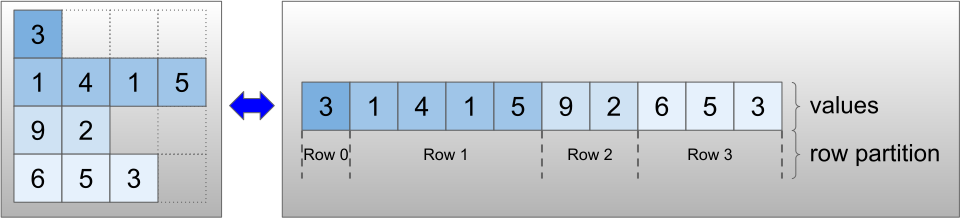
La row_partition se puede almacenar usando cuatro codificaciones diferentes:
-
row_splitses un vector entero que especifica los puntos de división entre filas. -
value_rowidses un vector entero que especifica el índice de fila para cada valor. -
row_lengthses un vector entero que especifica la longitud de cada fila. -
uniform_row_lengthes un escalar entero que especifica una sola longitud para todas las filas.

También se puede incluir un escalar entero nrows en la codificación de row_partition de filas para tener en cuenta las filas finales vacías con value_rowids o filas vacías con uniform_row_length .
rt = tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7])
print(rt)
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
La elección de qué codificación usar para las particiones de filas se administra internamente mediante tensores irregulares para mejorar la eficiencia en algunos contextos. En particular, algunas de las ventajas y desventajas de los diferentes esquemas de partición de filas son:
- Indexación eficiente : la codificación
row_splitspermite la indexación en tiempo constante y el corte en tensores irregulares. - Concatenación eficiente :
row_lengthscodificación de longitudes de fila es más eficiente cuando se concatenan tensores irregulares, ya que las longitudes de fila no cambian cuando dos tensores se concatenan juntos. - Tamaño de codificación pequeño : la codificación
value_rowidses más eficiente cuando se almacenan tensores irregulares que tienen una gran cantidad de filas vacías, ya que el tamaño del tensor depende solo de la cantidad total de valores. Por otro lado, las codificacionesrow_splitsyrow_lengthsson más eficientes cuando se almacenan tensores irregulares con filas más largas, ya que solo requieren un valor escalar para cada fila. - Compatibilidad : el esquema
value_rowidscoincide con el formato de segmentación utilizado por las operaciones, comotf.segment_sum. El esquema derow_limitscoincide con el formato utilizado por operaciones comotf.sequence_mask. - Dimensiones uniformes : como se explica a continuación, la codificación
uniform_row_lengthse utiliza para codificar tensores irregulares con dimensiones uniformes.
Múltiples dimensiones irregulares
Un tensor irregular con varias dimensiones irregulares se codifica utilizando un RaggedTensor anidado para el tensor de values . Cada RaggedTensor anidado agrega una sola dimensión irregular.
![]()
rt = tf.RaggedTensor.from_row_splits(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 3, 5, 9, 10]),
row_splits=[0, 1, 1, 5])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]> Shape: (3, None, None) Number of partitioned dimensions: 2
La función de fábrica tf.RaggedTensor.from_nested_row_splits se puede usar para construir un RaggedTensor con múltiples dimensiones irregulares directamente al proporcionar una lista de tensores de row_splits :
rt = tf.RaggedTensor.from_nested_row_splits(
flat_values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
nested_row_splits=([0, 1, 1, 5], [0, 3, 3, 5, 9, 10]))
print(rt)
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]>
Rango desigual y valores planos
El rango irregular de un tensor irregular es el número de veces que se ha dividido el tensor de values subyacente (es decir, la profundidad de anidamiento de los objetos RaggedTensor ). El tensor de values más interno se conoce como flat_values . En el siguiente ejemplo, conversations tienen ragged_rank=3 y flat_values es un Tensor 1D con 24 cadenas:
# shape = [batch, (paragraph), (sentence), (word)]
conversations = tf.ragged.constant(
[[[["I", "like", "ragged", "tensors."]],
[["Oh", "yeah?"], ["What", "can", "you", "use", "them", "for?"]],
[["Processing", "variable", "length", "data!"]]],
[[["I", "like", "cheese."], ["Do", "you?"]],
[["Yes."], ["I", "do."]]]])
conversations.shape
TensorShape([2, None, None, None])
assert conversations.ragged_rank == len(conversations.nested_row_splits)
conversations.ragged_rank # Number of partitioned dimensions.
3
conversations.flat_values.numpy()
array([b'I', b'like', b'ragged', b'tensors.', b'Oh', b'yeah?', b'What',
b'can', b'you', b'use', b'them', b'for?', b'Processing',
b'variable', b'length', b'data!', b'I', b'like', b'cheese.', b'Do',
b'you?', b'Yes.', b'I', b'do.'], dtype=object)
Dimensiones internas uniformes
Los tensores irregulares con dimensiones internas uniformes se codifican utilizando un tf.Tensor multidimensional para los valores_planos (es decir, los values más internos).
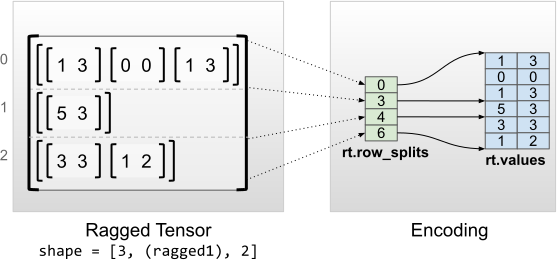
rt = tf.RaggedTensor.from_row_splits(
values=[[1, 3], [0, 0], [1, 3], [5, 3], [3, 3], [1, 2]],
row_splits=[0, 3, 4, 6])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
print("Flat values shape: {}".format(rt.flat_values.shape))
print("Flat values:\n{}".format(rt.flat_values))
<tf.RaggedTensor [[[1, 3], [0, 0], [1, 3]], [[5, 3]], [[3, 3], [1, 2]]]> Shape: (3, None, 2) Number of partitioned dimensions: 1 Flat values shape: (6, 2) Flat values: [[1 3] [0 0] [1 3] [5 3] [3 3] [1 2]]
Dimensiones no internas uniformes
Los tensores irregulares con dimensiones no internas uniformes se codifican dividiendo las filas con uniform_row_length .
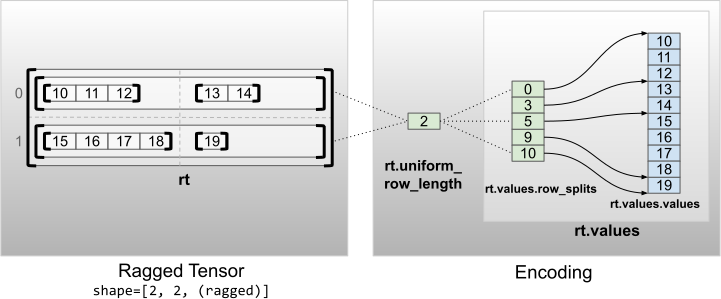
rt = tf.RaggedTensor.from_uniform_row_length(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 5, 9, 10]),
uniform_row_length=2)
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12], [13, 14]], [[15, 16, 17, 18], [19]]]> Shape: (2, 2, None) Number of partitioned dimensions: 2