| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Visão geral
O TensorFlow implementa um subconjunto da API NumPy , disponível como tf.experimental.numpy . Isso permite executar o código NumPy, acelerado pelo TensorFlow, além de permitir acesso a todas as APIs do TensorFlow.
Configurar
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow.experimental.numpy as tnp
import timeit
print("Using TensorFlow version %s" % tf.__version__)
Using TensorFlow version 2.6.0
Ativando o comportamento NumPy
Para usar o tnp como NumPy, habilite o comportamento do NumPy para o TensorFlow:
tnp.experimental_enable_numpy_behavior()
Essa chamada permite a promoção de tipo no TensorFlow e também altera a inferência de tipo, ao converter literais em tensores, para seguir mais estritamente o padrão NumPy.
Matriz TensorFlow NumPy ND
Uma instância de tf.experimental.numpy.ndarray , chamada ND Array , representa um array denso multidimensional de um determinado dtype colocado em um determinado dispositivo. É um alias para tf.Tensor . Confira a classe ND array para métodos úteis como ndarray.T , ndarray.reshape , ndarray.ravel e outros.
Primeiro, crie um objeto de matriz ND e, em seguida, invoque métodos diferentes.
# Create an ND array and check out different attributes.
ones = tnp.ones([5, 3], dtype=tnp.float32)
print("Created ND array with shape = %s, rank = %s, "
"dtype = %s on device = %s\n" % (
ones.shape, ones.ndim, ones.dtype, ones.device))
# `ndarray` is just an alias to `tf.Tensor`.
print("Is `ones` an instance of tf.Tensor: %s\n" % isinstance(ones, tf.Tensor))
# Try commonly used member functions.
print("ndarray.T has shape %s" % str(ones.T.shape))
print("narray.reshape(-1) has shape %s" % ones.reshape(-1).shape)
Created ND array with shape = (5, 3), rank = 2, dtype = <dtype: 'float32'> on device = /job:localhost/replica:0/task:0/device:GPU:0 Is `ones` an instance of tf.Tensor: True ndarray.T has shape (3, 5) narray.reshape(-1) has shape (15,)
Tipo de promoção
As APIs do TensorFlow NumPy têm semântica bem definida para converter literais em array ND, bem como para realizar promoção de tipo em entradas de array ND. Por favor, veja np.result_type para mais detalhes.
As APIs do TensorFlow deixam as entradas tf.Tensor inalteradas e não realizam promoção de tipo nelas, enquanto as APIs do TensorFlow NumPy promovem todas as entradas de acordo com as regras de promoção de tipo NumPy. No próximo exemplo, você realizará a promoção de tipo. Primeiro, execute a adição nas entradas da matriz ND de diferentes tipos e observe os tipos de saída. Nenhuma dessas promoções de tipo seria permitida pelas APIs do TensorFlow.
print("Type promotion for operations")
values = [tnp.asarray(1, dtype=d) for d in
(tnp.int32, tnp.int64, tnp.float32, tnp.float64)]
for i, v1 in enumerate(values):
for v2 in values[i + 1:]:
print("%s + %s => %s" %
(v1.dtype.name, v2.dtype.name, (v1 + v2).dtype.name))
Type promotion for operations int32 + int64 => int64 int32 + float32 => float64 int32 + float64 => float64 int64 + float32 => float64 int64 + float64 => float64 float32 + float64 => float64
Finalmente, converta literais em array ND usando ndarray.asarray e observe o tipo resultante.
print("Type inference during array creation")
print("tnp.asarray(1).dtype == tnp.%s" % tnp.asarray(1).dtype.name)
print("tnp.asarray(1.).dtype == tnp.%s\n" % tnp.asarray(1.).dtype.name)
Type inference during array creation tnp.asarray(1).dtype == tnp.int64 tnp.asarray(1.).dtype == tnp.float64
Ao converter literais em array ND, NumPy prefere tipos largos como tnp.int64 e tnp.float64 . Em contraste, tf.convert_to_tensor prefere os tipos tf.int32 e tf.float32 para converter constantes em tf.Tensor . As APIs do TensorFlow NumPy seguem o comportamento do NumPy para números inteiros. Quanto aos floats, o argumento prefer_float32 de experimental_enable_numpy_behavior permite controlar se prefere tf.float32 sobre tf.float64 (o padrão é False ). Por exemplo:
tnp.experimental_enable_numpy_behavior(prefer_float32=True)
print("When prefer_float32 is True:")
print("tnp.asarray(1.).dtype == tnp.%s" % tnp.asarray(1.).dtype.name)
print("tnp.add(1., 2.).dtype == tnp.%s" % tnp.add(1., 2.).dtype.name)
tnp.experimental_enable_numpy_behavior(prefer_float32=False)
print("When prefer_float32 is False:")
print("tnp.asarray(1.).dtype == tnp.%s" % tnp.asarray(1.).dtype.name)
print("tnp.add(1., 2.).dtype == tnp.%s" % tnp.add(1., 2.).dtype.name)
When prefer_float32 is True: tnp.asarray(1.).dtype == tnp.float32 tnp.add(1., 2.).dtype == tnp.float32 When prefer_float32 is False: tnp.asarray(1.).dtype == tnp.float64 tnp.add(1., 2.).dtype == tnp.float64
Transmissão
Semelhante ao TensorFlow, o NumPy define semântica rica para valores de "transmissão". Você pode conferir o guia de transmissão do NumPy para obter mais informações e compará-lo com a semântica de transmissão do TensorFlow .
x = tnp.ones([2, 3])
y = tnp.ones([3])
z = tnp.ones([1, 2, 1])
print("Broadcasting shapes %s, %s and %s gives shape %s" % (
x.shape, y.shape, z.shape, (x + y + z).shape))
Broadcasting shapes (2, 3), (3,) and (1, 2, 1) gives shape (1, 2, 3)
Indexação
NumPy define regras de indexação muito sofisticadas. Consulte o guia de indexação do NumPy . Observe o uso de matrizes ND como índices abaixo.
x = tnp.arange(24).reshape(2, 3, 4)
print("Basic indexing")
print(x[1, tnp.newaxis, 1:3, ...], "\n")
print("Boolean indexing")
print(x[:, (True, False, True)], "\n")
print("Advanced indexing")
print(x[1, (0, 0, 1), tnp.asarray([0, 1, 1])])
Basic indexing tf.Tensor( [[[16 17 18 19] [20 21 22 23]]], shape=(1, 2, 4), dtype=int64) Boolean indexing tf.Tensor( [[[ 0 1 2 3] [ 8 9 10 11]] [[12 13 14 15] [20 21 22 23]]], shape=(2, 2, 4), dtype=int64) Advanced indexing tf.Tensor([12 13 17], shape=(3,), dtype=int64)
# Mutation is currently not supported
try:
tnp.arange(6)[1] = -1
except TypeError:
print("Currently, TensorFlow NumPy does not support mutation.")
Currently, TensorFlow NumPy does not support mutation.
Modelo de exemplo
Em seguida, você pode ver como criar um modelo e executar inferência nele. Este modelo simples aplica uma camada relu seguida de uma projeção linear. As seções posteriores mostrarão como calcular gradientes para este modelo usando a GradientTape do TensorFlow.
class Model(object):
"""Model with a dense and a linear layer."""
def __init__(self):
self.weights = None
def predict(self, inputs):
if self.weights is None:
size = inputs.shape[1]
# Note that type `tnp.float32` is used for performance.
stddev = tnp.sqrt(size).astype(tnp.float32)
w1 = tnp.random.randn(size, 64).astype(tnp.float32) / stddev
bias = tnp.random.randn(64).astype(tnp.float32)
w2 = tnp.random.randn(64, 2).astype(tnp.float32) / 8
self.weights = (w1, bias, w2)
else:
w1, bias, w2 = self.weights
y = tnp.matmul(inputs, w1) + bias
y = tnp.maximum(y, 0) # Relu
return tnp.matmul(y, w2) # Linear projection
model = Model()
# Create input data and compute predictions.
print(model.predict(tnp.ones([2, 32], dtype=tnp.float32)))
tf.Tensor( [[-1.7706785 1.1137733] [-1.7706785 1.1137733]], shape=(2, 2), dtype=float32)
TensorFlow NumPy e NumPy
O TensorFlow NumPy implementa um subconjunto da especificação completa do NumPy. Embora mais símbolos sejam adicionados ao longo do tempo, existem recursos sistemáticos que não serão suportados em um futuro próximo. Isso inclui suporte à API NumPy C, integração Swig, ordem de armazenamento Fortran, visualizações e stride_tricks e alguns dtype (como np.recarray e np.object ). Para obter mais detalhes, consulte a documentação da API TensorFlow NumPy .
Interoperabilidade NumPy
Os arrays do TensorFlow ND podem interoperar com funções NumPy. Esses objetos implementam a interface __array__ . O NumPy usa essa interface para converter argumentos de função em valores np.ndarray antes de processá-los.
Da mesma forma, as funções do TensorFlow NumPy podem aceitar entradas de diferentes tipos, incluindo np.ndarray . Essas entradas são convertidas em uma matriz ND chamando ndarray.asarray nelas.
A conversão da matriz ND de e para np.ndarray pode acionar cópias de dados reais. Consulte a seção sobre cópias de buffer para obter mais detalhes.
# ND array passed into NumPy function.
np_sum = np.sum(tnp.ones([2, 3]))
print("sum = %s. Class: %s" % (float(np_sum), np_sum.__class__))
# `np.ndarray` passed into TensorFlow NumPy function.
tnp_sum = tnp.sum(np.ones([2, 3]))
print("sum = %s. Class: %s" % (float(tnp_sum), tnp_sum.__class__))
sum = 6.0. Class: <class 'numpy.float64'> sum = 6.0. Class: <class 'tensorflow.python.framework.ops.EagerTensor'>
# It is easy to plot ND arrays, given the __array__ interface.
labels = 15 + 2 * tnp.random.randn(1, 1000)
_ = plt.hist(labels)
Cópias de buffer
A mistura do TensorFlow NumPy com o código NumPy pode acionar cópias de dados. Isso ocorre porque o TensorFlow NumPy tem requisitos mais rígidos de alinhamento de memória do que os do NumPy.
Quando um np.ndarray é passado para o TensorFlow NumPy, ele verifica os requisitos de alinhamento e aciona uma cópia, se necessário. Ao passar um buffer de CPU de matriz ND para o NumPy, geralmente o buffer atenderá aos requisitos de alinhamento e o NumPy não precisará criar uma cópia.
As matrizes ND podem se referir a buffers colocados em dispositivos que não sejam a memória da CPU local. Nesses casos, invocar uma função NumPy acionará cópias na rede ou no dispositivo conforme necessário.
Dado isso, a mistura com as chamadas da API NumPy geralmente deve ser feita com cautela e o usuário deve estar atento às sobrecargas de cópia de dados. Intercalar chamadas TensorFlow NumPy com chamadas TensorFlow geralmente é seguro e evita a cópia de dados. Consulte a seção sobre interoperabilidade do TensorFlow para obter mais detalhes.
Operador precedente
O TensorFlow NumPy define um __array_priority__ maior que o do NumPy. Isso significa que, para operadores envolvendo ND array e np.ndarray , o primeiro terá precedência, ou seja, a entrada np.ndarray será convertida em um array ND e a implementação do TensorFlow NumPy do operador será invocada.
x = tnp.ones([2]) + np.ones([2])
print("x = %s\nclass = %s" % (x, x.__class__))
x = tf.Tensor([2. 2.], shape=(2,), dtype=float64) class = <class 'tensorflow.python.framework.ops.EagerTensor'>
TF NumPy e TensorFlow
O TensorFlow NumPy foi desenvolvido com base no TensorFlow e, portanto, interopera perfeitamente com o TensorFlow.
tf.Tensor e matriz ND
ND array é um alias para tf.Tensor , então obviamente eles podem ser misturados sem acionar cópias de dados reais.
x = tf.constant([1, 2])
print(x)
# `asarray` and `convert_to_tensor` here are no-ops.
tnp_x = tnp.asarray(x)
print(tnp_x)
print(tf.convert_to_tensor(tnp_x))
# Note that tf.Tensor.numpy() will continue to return `np.ndarray`.
print(x.numpy(), x.numpy().__class__)
tf.Tensor([1 2], shape=(2,), dtype=int32) tf.Tensor([1 2], shape=(2,), dtype=int32) tf.Tensor([1 2], shape=(2,), dtype=int32) [1 2] <class 'numpy.ndarray'>
Interoperabilidade do TensorFlow
Um array ND pode ser passado para as APIs do TensorFlow, já que o array ND é apenas um alias para tf.Tensor . Conforme mencionado anteriormente, tal interoperação não faz cópias de dados, mesmo para dados colocados em aceleradores ou dispositivos remotos.
Por outro lado, objetos tf.Tensor podem ser passados para APIs tf.experimental.numpy , sem realizar cópias de dados.
# ND array passed into TensorFlow function.
tf_sum = tf.reduce_sum(tnp.ones([2, 3], tnp.float32))
print("Output = %s" % tf_sum)
# `tf.Tensor` passed into TensorFlow NumPy function.
tnp_sum = tnp.sum(tf.ones([2, 3]))
print("Output = %s" % tnp_sum)
Output = tf.Tensor(6.0, shape=(), dtype=float32) Output = tf.Tensor(6.0, shape=(), dtype=float32)
Gradientes e Jacobianos: tf.GradientTape
O GradientTape do TensorFlow pode ser usado para retropropagação por meio do código TensorFlow e TensorFlow NumPy.
Use o modelo criado na seção Modelo de exemplo e calcule gradientes e jacobians.
def create_batch(batch_size=32):
"""Creates a batch of input and labels."""
return (tnp.random.randn(batch_size, 32).astype(tnp.float32),
tnp.random.randn(batch_size, 2).astype(tnp.float32))
def compute_gradients(model, inputs, labels):
"""Computes gradients of squared loss between model prediction and labels."""
with tf.GradientTape() as tape:
assert model.weights is not None
# Note that `model.weights` need to be explicitly watched since they
# are not tf.Variables.
tape.watch(model.weights)
# Compute prediction and loss
prediction = model.predict(inputs)
loss = tnp.sum(tnp.square(prediction - labels))
# This call computes the gradient through the computation above.
return tape.gradient(loss, model.weights)
inputs, labels = create_batch()
gradients = compute_gradients(model, inputs, labels)
# Inspect the shapes of returned gradients to verify they match the
# parameter shapes.
print("Parameter shapes:", [w.shape for w in model.weights])
print("Gradient shapes:", [g.shape for g in gradients])
# Verify that gradients are of type ND array.
assert isinstance(gradients[0], tnp.ndarray)
Parameter shapes: [TensorShape([32, 64]), TensorShape([64]), TensorShape([64, 2])] Gradient shapes: [TensorShape([32, 64]), TensorShape([64]), TensorShape([64, 2])]
# Computes a batch of jacobians. Each row is the jacobian of an element in the
# batch of outputs w.r.t. the corresponding input batch element.
def prediction_batch_jacobian(inputs):
with tf.GradientTape() as tape:
tape.watch(inputs)
prediction = model.predict(inputs)
return prediction, tape.batch_jacobian(prediction, inputs)
inp_batch = tnp.ones([16, 32], tnp.float32)
output, batch_jacobian = prediction_batch_jacobian(inp_batch)
# Note how the batch jacobian shape relates to the input and output shapes.
print("Output shape: %s, input shape: %s" % (output.shape, inp_batch.shape))
print("Batch jacobian shape:", batch_jacobian.shape)
Output shape: (16, 2), input shape: (16, 32) Batch jacobian shape: (16, 2, 32)
Compilação de rastreamento: tf.function
A função tf.function do tf.function funciona "compilando os rastreamentos" do código e otimizando esses rastreamentos para um desempenho muito mais rápido. Veja a Introdução a Gráficos e Funções .
tf.function pode ser usado para otimizar o código TensorFlow NumPy. Aqui está um exemplo simples para demonstrar as acelerações. Observe que o corpo do código tf.function inclui chamadas para as APIs TensorFlow NumPy.
inputs, labels = create_batch(512)
print("Eager performance")
compute_gradients(model, inputs, labels)
print(timeit.timeit(lambda: compute_gradients(model, inputs, labels),
number=10) * 100, "ms")
print("\ntf.function compiled performance")
compiled_compute_gradients = tf.function(compute_gradients)
compiled_compute_gradients(model, inputs, labels) # warmup
print(timeit.timeit(lambda: compiled_compute_gradients(model, inputs, labels),
number=10) * 100, "ms")
Eager performance 1.291419400013183 ms tf.function compiled performance 0.5561202000080812 ms
Vetorização: tf.vectorized_map
O TensorFlow tem suporte embutido para vetorizar loops paralelos, o que permite acelerações de uma a duas ordens de magnitude. Essas acelerações são acessíveis por meio da API tf.vectorized_map e também se aplicam ao código TensorFlow NumPy.
Às vezes, é útil calcular o gradiente de cada saída em um lote com o elemento de lote de entrada correspondente. Tal cálculo pode ser feito de forma eficiente usando tf.vectorized_map como mostrado abaixo.
@tf.function
def vectorized_per_example_gradients(inputs, labels):
def single_example_gradient(arg):
inp, label = arg
return compute_gradients(model,
tnp.expand_dims(inp, 0),
tnp.expand_dims(label, 0))
# Note that a call to `tf.vectorized_map` semantically maps
# `single_example_gradient` over each row of `inputs` and `labels`.
# The interface is similar to `tf.map_fn`.
# The underlying machinery vectorizes away this map loop which gives
# nice speedups.
return tf.vectorized_map(single_example_gradient, (inputs, labels))
batch_size = 128
inputs, labels = create_batch(batch_size)
per_example_gradients = vectorized_per_example_gradients(inputs, labels)
for w, p in zip(model.weights, per_example_gradients):
print("Weight shape: %s, batch size: %s, per example gradient shape: %s " % (
w.shape, batch_size, p.shape))
Weight shape: (32, 64), batch size: 128, per example gradient shape: (128, 32, 64) Weight shape: (64,), batch size: 128, per example gradient shape: (128, 64) Weight shape: (64, 2), batch size: 128, per example gradient shape: (128, 64, 2)
# Benchmark the vectorized computation above and compare with
# unvectorized sequential computation using `tf.map_fn`.
@tf.function
def unvectorized_per_example_gradients(inputs, labels):
def single_example_gradient(arg):
inp, label = arg
return compute_gradients(model,
tnp.expand_dims(inp, 0),
tnp.expand_dims(label, 0))
return tf.map_fn(single_example_gradient, (inputs, labels),
fn_output_signature=(tf.float32, tf.float32, tf.float32))
print("Running vectorized computation")
print(timeit.timeit(lambda: vectorized_per_example_gradients(inputs, labels),
number=10) * 100, "ms")
print("\nRunning unvectorized computation")
per_example_gradients = unvectorized_per_example_gradients(inputs, labels)
print(timeit.timeit(lambda: unvectorized_per_example_gradients(inputs, labels),
number=10) * 100, "ms")
Running vectorized computation 0.5265710999992734 ms Running unvectorized computation 40.35122630002661 ms
Posicionamento do dispositivo
O TensorFlow NumPy pode realizar operações em CPUs, GPUs, TPUs e dispositivos remotos. Ele usa mecanismos padrão do TensorFlow para posicionamento do dispositivo. Abaixo, um exemplo simples mostra como listar todos os dispositivos e, em seguida, fazer alguns cálculos em um dispositivo específico.
O TensorFlow também possui APIs para replicar a computação entre dispositivos e realizar reduções coletivas que não serão abordadas aqui.
Listar dispositivos
tf.config.list_logical_devices e tf.config.list_physical_devices podem ser usados para encontrar quais dispositivos usar.
print("All logical devices:", tf.config.list_logical_devices())
print("All physical devices:", tf.config.list_physical_devices())
# Try to get the GPU device. If unavailable, fallback to CPU.
try:
device = tf.config.list_logical_devices(device_type="GPU")[0]
except IndexError:
device = "/device:CPU:0"
All logical devices: [LogicalDevice(name='/device:CPU:0', device_type='CPU'), LogicalDevice(name='/device:GPU:0', device_type='GPU')] All physical devices: [PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
Colocando operações: tf.device
As operações podem ser colocadas em um dispositivo chamando-o em um escopo tf.device .
print("Using device: %s" % str(device))
# Run operations in the `tf.device` scope.
# If a GPU is available, these operations execute on the GPU and outputs are
# placed on the GPU memory.
with tf.device(device):
prediction = model.predict(create_batch(5)[0])
print("prediction is placed on %s" % prediction.device)
Using device: LogicalDevice(name='/device:GPU:0', device_type='GPU') prediction is placed on /job:localhost/replica:0/task:0/device:GPU:0
Copiando matrizes ND entre dispositivos: tnp.copy
Uma chamada para tnp.copy , colocada em um determinado escopo de dispositivo, copiará os dados para esse dispositivo, a menos que os dados já estejam nesse dispositivo.
with tf.device("/device:CPU:0"):
prediction_cpu = tnp.copy(prediction)
print(prediction.device)
print(prediction_cpu.device)
/job:localhost/replica:0/task:0/device:GPU:0 /job:localhost/replica:0/task:0/device:CPU:0
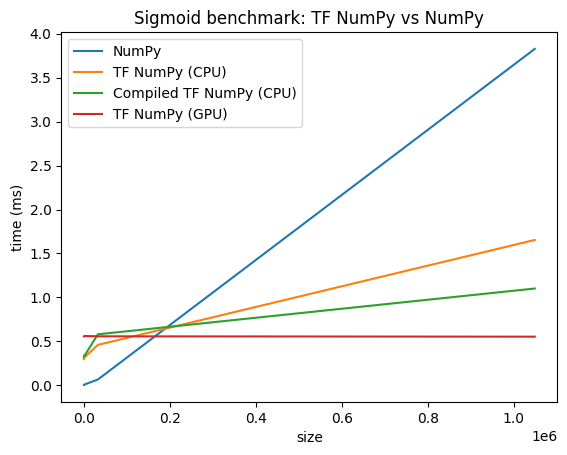
Comparações de desempenho
O TensorFlow NumPy usa kernels TensorFlow altamente otimizados que podem ser despachados em CPUs, GPUs e TPUs. O TensorFlow também realiza muitas otimizações de compilador, como fusão de operações, que se traduzem em melhorias de desempenho e memória. Consulte Otimização de gráfico do TensorFlow com Grappler para saber mais.
No entanto, o TensorFlow tem maiores despesas gerais para operações de despacho em comparação com o NumPy. Para cargas de trabalho compostas por pequenas operações (menos de cerca de 10 microssegundos), essas sobrecargas podem dominar o tempo de execução e o NumPy pode fornecer melhor desempenho. Para outros casos, o TensorFlow geralmente deve fornecer melhor desempenho.
Execute o benchmark abaixo para comparar o desempenho do NumPy e do TensorFlow NumPy para diferentes tamanhos de entrada.
def benchmark(f, inputs, number=30, force_gpu_sync=False):
"""Utility to benchmark `f` on each value in `inputs`."""
times = []
for inp in inputs:
def _g():
if force_gpu_sync:
one = tnp.asarray(1)
f(inp)
if force_gpu_sync:
with tf.device("CPU:0"):
tnp.copy(one) # Force a sync for GPU case
_g() # warmup
t = timeit.timeit(_g, number=number)
times.append(t * 1000. / number)
return times
def plot(np_times, tnp_times, compiled_tnp_times, has_gpu, tnp_times_gpu):
"""Plot the different runtimes."""
plt.xlabel("size")
plt.ylabel("time (ms)")
plt.title("Sigmoid benchmark: TF NumPy vs NumPy")
plt.plot(sizes, np_times, label="NumPy")
plt.plot(sizes, tnp_times, label="TF NumPy (CPU)")
plt.plot(sizes, compiled_tnp_times, label="Compiled TF NumPy (CPU)")
if has_gpu:
plt.plot(sizes, tnp_times_gpu, label="TF NumPy (GPU)")
plt.legend()
# Define a simple implementation of `sigmoid`, and benchmark it using
# NumPy and TensorFlow NumPy for different input sizes.
def np_sigmoid(y):
return 1. / (1. + np.exp(-y))
def tnp_sigmoid(y):
return 1. / (1. + tnp.exp(-y))
@tf.function
def compiled_tnp_sigmoid(y):
return tnp_sigmoid(y)
sizes = (2 ** 0, 2 ** 5, 2 ** 10, 2 ** 15, 2 ** 20)
np_inputs = [np.random.randn(size).astype(np.float32) for size in sizes]
np_times = benchmark(np_sigmoid, np_inputs)
with tf.device("/device:CPU:0"):
tnp_inputs = [tnp.random.randn(size).astype(np.float32) for size in sizes]
tnp_times = benchmark(tnp_sigmoid, tnp_inputs)
compiled_tnp_times = benchmark(compiled_tnp_sigmoid, tnp_inputs)
has_gpu = len(tf.config.list_logical_devices("GPU"))
if has_gpu:
with tf.device("/device:GPU:0"):
tnp_inputs = [tnp.random.randn(size).astype(np.float32) for size in sizes]
tnp_times_gpu = benchmark(compiled_tnp_sigmoid, tnp_inputs, 100, True)
else:
tnp_times_gpu = None
plot(np_times, tnp_times, compiled_tnp_times, has_gpu, tnp_times_gpu)