
| | |  Ver en GitHub Ver en GitHub | |
Este Colab es una demostración de la utilización de Tensorflow Hub para la clasificación texto en distintos al inglés / idiomas locales. Aquí elegimos bengalí como el idioma local y el uso pretrained incrustaciones de palabras para resolver una tarea de clasificación multiclase, donde clasificamos Bangla artículos de noticias en 5 categorías. Las inclusiones pretrained para Bangla proviene de FastText que es una biblioteca de Facebook con vectores de palabras pretrained liberados de 157 idiomas.
Vamos a utilizar la incrustación exportador pretrained de TF-Hub para convertir las palabras incrustaciones a un módulo de texto incrustar primero y luego utilizar el módulo para entrenar a un clasificador con tf.keras , fácil de usar API de alto nivel de Tensorflow para construir modelos de aprendizaje profundo. Incluso si usamos incrustaciones fastText aquí, es posible exportar cualquier otra incrustación previamente entrenada de otras tareas y obtener resultados rápidamente con Tensorflow Hub.
Configuración
# https://github.com/pypa/setuptools/issues/1694#issuecomment-466010982pip install gdown --no-use-pep517
sudo apt-get install -y unzip
Reading package lists... Building dependency tree... Reading state information... unzip is already the newest version (6.0-21ubuntu1.1). The following packages were automatically installed and are no longer required: linux-gcp-5.4-headers-5.4.0-1040 linux-gcp-5.4-headers-5.4.0-1043 linux-gcp-5.4-headers-5.4.0-1044 linux-gcp-5.4-headers-5.4.0-1049 linux-headers-5.4.0-1049-gcp linux-image-5.4.0-1049-gcp linux-modules-5.4.0-1049-gcp linux-modules-extra-5.4.0-1049-gcp Use 'sudo apt autoremove' to remove them. 0 upgraded, 0 newly installed, 0 to remove and 143 not upgraded.
import os
import tensorflow as tf
import tensorflow_hub as hub
import gdown
import numpy as np
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
import seaborn as sns
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py:119: PkgResourcesDeprecationWarning: 0.18ubuntu0.18.04.1 is an invalid version and will not be supported in a future release PkgResourcesDeprecationWarning,
Conjunto de datos
Vamos a utilizar BARD (Bangla artículo conjunto de datos), que cuenta con alrededor de 376.226 artículos recogidos de diferentes portales de noticias en bengalí y etiquetados con 5 categorías: economía, estado, internacionales, deportes y entretenimiento. Descargamos el archivo desde Google Drive esto ( bit.ly/BARD_DATASET enlace) se está refiriendo a partir de este repositorio GitHub.
gdown.download(
url='https://drive.google.com/uc?id=1Ag0jd21oRwJhVFIBohmX_ogeojVtapLy',
output='bard.zip',
quiet=True
)
'bard.zip'
unzip -qo bard.zip
Exportar vectores de palabras previamente entrenados al módulo TF-Hub
TF-Hub proporciona algunas secuencias de comandos útiles para la conversión de incrustaciones de palabras para los módulos de texto de incrustación TF-hub aquí . Para hacer que el módulo de Bangla o cualquier otro idioma, simplemente tenemos que descargar la palabra incrustar .txt o .vec archivo en el mismo directorio que export_v2.py y ejecutar el script.
El exportador lee los vectores de incrustación y la exporta a un Tensorflow SavedModel . Un modelo guardado contiene un programa TensorFlow completo que incluye pesos y gráficos. TF-Hub puede cargar el SavedModel como un módulo , el cual utilizaremos para construir el modelo de clasificación de texto. Puesto que estamos utilizando tf.keras para construir el modelo, vamos a utilizar hub.KerasLayer , que proporciona un contenedor para un módulo TF-Hub para su uso como capa Keras.
En primer lugar vamos a tener en nuestras inmersiones Palabras FastText y exportador de la incrustación de TF-Hub de recompra .
curl -O https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bn.300.vec.gzcurl -O https://raw.githubusercontent.com/tensorflow/hub/master/examples/text_embeddings_v2/export_v2.pygunzip -qf cc.bn.300.vec.gz --k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 840M 100 840M 0 0 11.6M 0 0:01:12 0:01:12 --:--:-- 12.0M
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 7469 100 7469 0 0 19053 0 --:--:-- --:--:-- --:--:-- 19005
Luego, ejecutaremos el script exportador en nuestro archivo de incrustación. Dado que las incrustaciones de fastText tienen una línea de encabezado y son bastante grandes (alrededor de 3.3 GB para bengalí después de convertir a un módulo) ignoramos la primera línea y exportamos solo los primeros 100.000 tokens al módulo de incrustación de texto.
python export_v2.py --embedding_file=cc.bn.300.vec --export_path=text_module --num_lines_to_ignore=1 --num_lines_to_use=100000
INFO:tensorflow:Assets written to: text_module/assets I1105 11:55:29.817717 140238757988160 builder_impl.py:784] Assets written to: text_module/assets
module_path = "text_module"
embedding_layer = hub.KerasLayer(module_path, trainable=False)
El módulo de incrustación de texto toma un lote de oraciones en un tensor de cadenas 1D como entrada y genera los vectores de incrustación de forma (batch_size, embedding_dim) correspondientes a las oraciones. Preprocesa la entrada dividiéndola en espacios. Incrustaciones de palabras se combinan para incrustaciones oración con la sqrtn combinador (Ver aquí ). Para la demostración, pasamos una lista de palabras en bengalí como entrada y obtenemos los vectores de incrustación correspondientes.
embedding_layer(['বাস', 'বসবাস', 'ট্রেন', 'যাত্রী', 'ট্রাক'])
<tf.Tensor: shape=(5, 300), dtype=float64, numpy=
array([[ 0.0462, -0.0355, 0.0129, ..., 0.0025, -0.0966, 0.0216],
[-0.0631, -0.0051, 0.085 , ..., 0.0249, -0.0149, 0.0203],
[ 0.1371, -0.069 , -0.1176, ..., 0.029 , 0.0508, -0.026 ],
[ 0.0532, -0.0465, -0.0504, ..., 0.02 , -0.0023, 0.0011],
[ 0.0908, -0.0404, -0.0536, ..., -0.0275, 0.0528, 0.0253]])>
Convertir a conjunto de datos de Tensorflow
Dado que el conjunto de datos es muy grande en lugar de cargar todo el conjunto de datos en la memoria vamos a utilizar un generador para producir muestras en tiempo de ejecución en lotes utilizando Tensorflow del conjunto de datos funciones. El conjunto de datos también está muy desequilibrado, por lo que, antes de usar el generador, barajaremos el conjunto de datos.
dir_names = ['economy', 'sports', 'entertainment', 'state', 'international']
file_paths = []
labels = []
for i, dir in enumerate(dir_names):
file_names = ["/".join([dir, name]) for name in os.listdir(dir)]
file_paths += file_names
labels += [i] * len(os.listdir(dir))
np.random.seed(42)
permutation = np.random.permutation(len(file_paths))
file_paths = np.array(file_paths)[permutation]
labels = np.array(labels)[permutation]
Podemos comprobar la distribución de etiquetas en los ejemplos de formación y validación después de barajar.
train_frac = 0.8
train_size = int(len(file_paths) * train_frac)
# plot training vs validation distribution
plt.subplot(1, 2, 1)
plt.hist(labels[0:train_size])
plt.title("Train labels")
plt.subplot(1, 2, 2)
plt.hist(labels[train_size:])
plt.title("Validation labels")
plt.tight_layout()
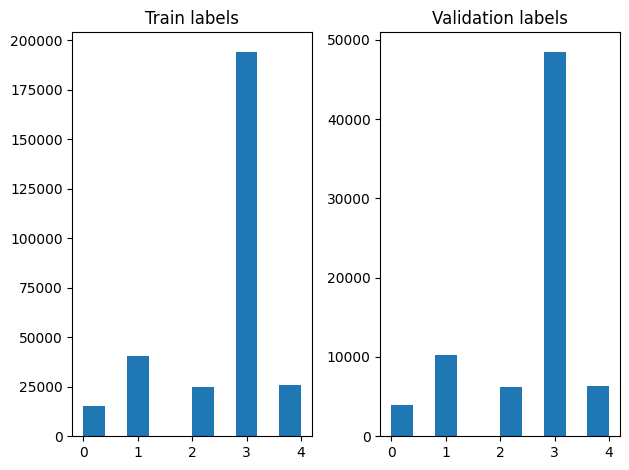
Para crear un conjunto de datos utilizando un generador, primero escribimos una función de generador que lee cada uno de los artículos de file_paths y las etiquetas de la agrupación de etiquetas, y los rendimientos ejemplo una formación en cada etapa. Pasamos esta función generador a la tf.data.Dataset.from_generator método y especificar los tipos de salida. Cada ejemplo de formación es una tupla que contiene un artículo de tf.string tipo de datos y la etiqueta codificada de una sola caliente. Dividimos el conjunto de datos con una fracción de tren-validación de 80-20 usando tf.data.Dataset.skip y tf.data.Dataset.take métodos.
def load_file(path, label):
return tf.io.read_file(path), label
def make_datasets(train_size):
batch_size = 256
train_files = file_paths[:train_size]
train_labels = labels[:train_size]
train_ds = tf.data.Dataset.from_tensor_slices((train_files, train_labels))
train_ds = train_ds.map(load_file).shuffle(5000)
train_ds = train_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
test_files = file_paths[train_size:]
test_labels = labels[train_size:]
test_ds = tf.data.Dataset.from_tensor_slices((test_files, test_labels))
test_ds = test_ds.map(load_file)
test_ds = test_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
return train_ds, test_ds
train_data, validation_data = make_datasets(train_size)
Formación y evaluación de modelos
Como ya hemos añadido una envoltura alrededor de nuestro módulo de utilizarlo como cualquier otra capa en Keras, podemos crear una pequeña secuencial modelo que es una pila lineal de capas. Podemos añadir nuestro módulo de la incrustación de texto con model.add al igual que cualquier otra capa. Compilamos el modelo especificando la pérdida y el optimizador y lo entrenamos durante 10 épocas. El tf.keras API puede manejar Tensorflow conjuntos de datos como entrada, por lo que podemos pasar a una instancia de conjunto de datos para el método de ajuste para el entrenamiento del modelo. Ya que estamos usando la función de generador, tf.data se encargará de generar las muestras, preparación de lotes ellos y alimentarlos al modelo.
Modelo
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[], dtype=tf.string),
embedding_layer,
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(5),
])
model.compile(loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam", metrics=['accuracy'])
return model
model = create_model()
# Create earlystopping callback
early_stopping_callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=3)
Capacitación
history = model.fit(train_data,
validation_data=validation_data,
epochs=5,
callbacks=[early_stopping_callback])
Epoch 1/5 1176/1176 [==============================] - 34s 28ms/step - loss: 0.2181 - accuracy: 0.9279 - val_loss: 0.1580 - val_accuracy: 0.9449 Epoch 2/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1411 - accuracy: 0.9505 - val_loss: 0.1411 - val_accuracy: 0.9503 Epoch 3/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1307 - accuracy: 0.9534 - val_loss: 0.1359 - val_accuracy: 0.9524 Epoch 4/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1248 - accuracy: 0.9555 - val_loss: 0.1318 - val_accuracy: 0.9527 Epoch 5/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1196 - accuracy: 0.9567 - val_loss: 0.1247 - val_accuracy: 0.9555
Evaluación
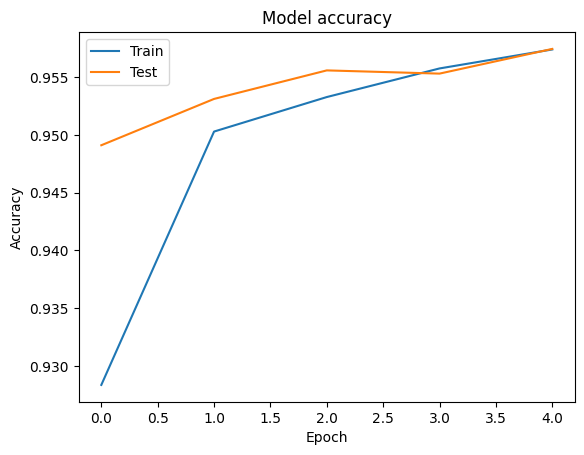
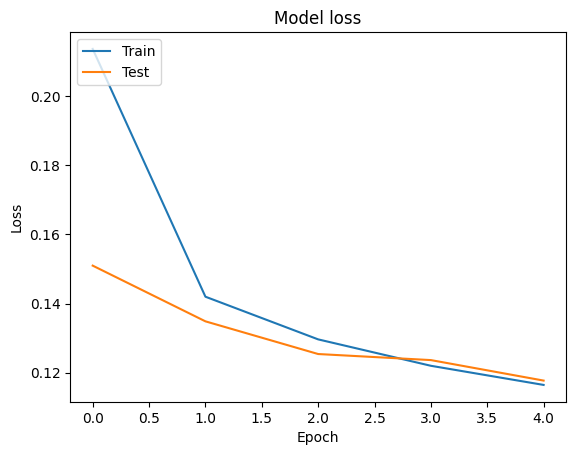
Podemos visualizar las curvas de pérdida de precisión y para el entrenamiento y validación de datos utilizando el tf.keras.callbacks.History objeto devuelto por el tf.keras.Model.fit método, que contiene el valor de la pérdida y la precisión de cada época.
# Plot training & validation accuracy values
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
# Plot training & validation loss values
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
Predicción
Podemos obtener las predicciones para los datos de validación y verificar la matriz de confusión para ver el desempeño del modelo para cada una de las 5 clases. Debido tf.keras.Model.predict método devuelve una matriz nd para probabilidades para cada clase, pueden ser convertidos a etiquetas de clase utilizando np.argmax .
y_pred = model.predict(validation_data)
y_pred = np.argmax(y_pred, axis=1)
samples = file_paths[0:3]
for i, sample in enumerate(samples):
f = open(sample)
text = f.read()
print(text[0:100])
print("True Class: ", sample.split("/")[0])
print("Predicted Class: ", dir_names[y_pred[i]])
f.close()
রবিন উইলিয়ামস তাঁর হ্যাপি ফিট ছবিতে মজা করে বলেছিলেন, ‘আমি শুনতে পাচ্ছি, মানুষ কিছু একটা চাইছে...সে True Class: entertainment Predicted Class: state নির্মাণ শেষে ফিতা কেটে মন্ত্রী ভবন উদ্বোধন করেছেন বহু আগেই। তবে এখনো চালু করা যায়নি খাগড়াছড়ি জেল True Class: state Predicted Class: state কমলাপুর বীরশ্রেষ্ঠ মোস্তফা কামাল স্টেডিয়ামে কাল ফকিরেরপুল ইয়ংমেন্স ক্লাব ৩-০ গোলে হারিয়েছে স্বাধ True Class: sports Predicted Class: state
Comparar rendimiento
Ahora podemos tomar las etiquetas correctas de los datos de validación de labels y los compare con nuestras predicciones para obtener una classification_report .
y_true = np.array(labels[train_size:])
print(classification_report(y_true, y_pred, target_names=dir_names))
precision recall f1-score support
economy 0.83 0.76 0.79 3897
sports 0.99 0.98 0.98 10204
entertainment 0.90 0.94 0.92 6256
state 0.97 0.97 0.97 48512
international 0.92 0.93 0.93 6377
accuracy 0.96 75246
macro avg 0.92 0.92 0.92 75246
weighted avg 0.96 0.96 0.96 75246
También podemos comparar el rendimiento de nuestro modelo con los resultados publicados obtenidos en el original de papel , que tenía un 0,96 precisión .Los autores originales describen muchos pasos de preprocesamiento realizan en el conjunto de datos, como la caída de signos de puntuación y dígitos, que quita la tapa 25 la mayoría de las palabras vacías fRequest. Como podemos ver en la classification_report , también gestionamos para obtener una precisión y exactitud de 0,96 después del entrenamiento por sólo 5 épocas sin ningún procesamiento previo!
En este ejemplo, cuando creamos la capa Keras de nuestro módulo de incrustación, fijamos el parámetro trainable=False , lo que significa que los pesos de incrustación no se actualizará durante el entrenamiento. Inténtelo a True para llegar a alrededor del 97% de precisión usando este conjunto de datos después de sólo 2 épocas.