
Comienza ahora
TensorFlow Hub es un repositorio completo de modelos previamente entrenados que están listos para que realices los ajustes necesarios y los implementes donde quieras. Descarga los modelos entrenados más recientes con una cantidad mínima de código con la biblioteca tensorflow_hub.
Los siguientes instructivos deberían ayudarte a comenzar a utilizar y aplicar modelos de TF Hub según tus necesidades. Los instructivos interactivos te permiten modificarlos y ejecutarlos con los cambios. Haz clic en el botón Ejecutar en Google Colab en la parte superior de un instructivo interactivo para empezar a trabajar en él.
Para principiantes
Si no tienes experiencia con el aprendizaje automático ni con TensorFlow, comienza con una descripción general sobre cómo clasificar imágenes y textos, detectar objetos en imágenes o replicar el estilo de artistas famosos en tus propias imágenes:

Clasificación de imágenes
Compila un modelo de Keras sobre un clasificador de imágenes previamente entrenado para distinguir flores.
Clasifica texto con BERT
Usa BERT para compilar un modelo de Keras que permita resolver una tarea de análisis de opiniones para clasificar textos.Transferencia de estilo
Haz que una red neuronal vuelva a dibujar una imagen con el estilo de Picasso, de van Gogh o con tu propio estilo.
Detección de objetos
Detecta objetos en imágenes con módulos como FasterRCNN o SSD.Para desarrolladores experimentados
Echa un vistazo a los instructivos más avanzados para descubrir cómo usar modelos de video, PLN, imágenes y audio desde TensorFlow Hub.
Instructivos de PLN
Resuelve tareas comunes de PLN con modelos de TensorFlow Hub. Consulta todos los instructivos de PLN disponibles en la barra de navegación izquierda.
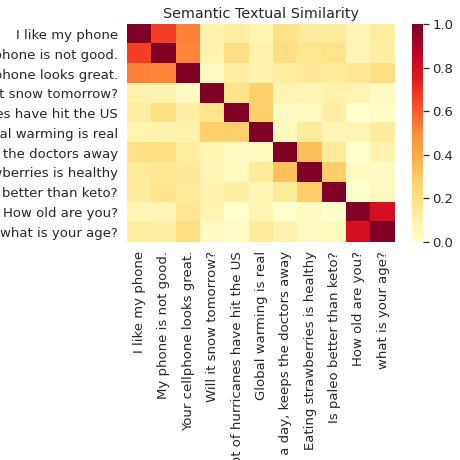
Similitud semántica
Clasifica y compara semánticamente oraciones con el Codificador universal de oraciones.
BERT en TPU
Usa BERT para resolver tareas comparativas de GLUE benchmark ejecutándose en TPU.Preguntas y respuestas del Codificador universal de oraciones en varios idiomas
Responde preguntas realizadas en otros idiomas desde el conjunto de datos de SQuAD con el modelo de preguntas y respuestas del Codificador universal de oraciones en varios idiomas.Instructivos de imágenes
Explora cómo usar GAN, modelos de superresolución y más. Consulta todos los instructivos de imágenes disponibles en la barra de navegación izquierda.

GAN para la generación de imágenes
Genera rostros artificiales e interpola de un rostro a otro con los GAN.
Superresolución
Mejora la resolución de las imágenes de reducción de muestreo.
Extensión de imagen
Completa la parte cubierta de una determinada imagen.Instructivos de audio
Explora los instructivos con modelos entrenados para datos de audio, incluidos el reconocimiento del tono y la clasificación del sonido.
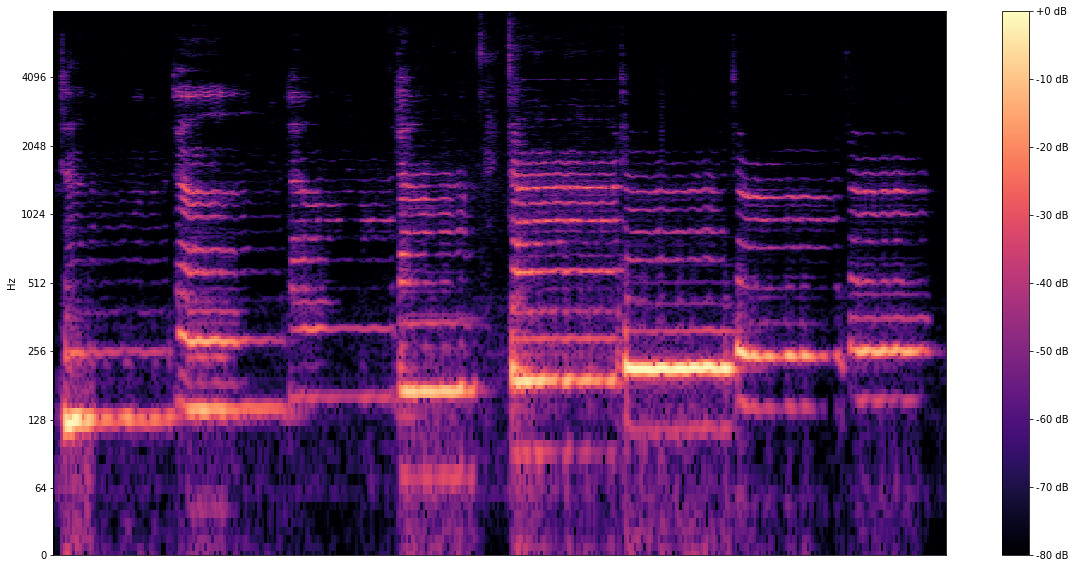
Reconocimiento de tono
Grábate cantando y detecta el tono de tu voz con el modelo SPICE.
Clasificación de sonido
Usa el modelo YAMNet para clasificar sonidos en 521 clases de eventos de audio desde el corpus de AudioSet-YouTube.Videos instructivos
Prueba los modelos de AA para datos de video a fin de reconocer las acciones, interpolar videos y más.

Reconocimiento de acciones
Detecta una de 400 acciones de un video con el modelo de ConvNet 3D aumentado.
Interpolación de video
Interpola entre fotogramas de video que usan Inbetweening con convoluciones 3D.