
| | |  Ver en GitHub Ver en GitHub | | |
Este cuaderno ilustra cómo acceder al Codificador Universal de Oraciones y usarlo para tareas de clasificación de oraciones y similitud de oraciones.
El Codificador Universal de Oraciones hace que obtener incrustaciones a nivel de oración sea tan fácil como lo ha sido históricamente buscar las incrustaciones para palabras individuales. Las incrustaciones de oraciones se pueden usar trivialmente para calcular la similitud de significado a nivel de oración, así como para permitir un mejor desempeño en las tareas de clasificación posteriores utilizando datos de entrenamiento menos supervisados.
Configuración
Esta sección configura el entorno para el acceso al codificador universal de frases en TF Hub y proporciona ejemplos de cómo aplicar el codificador a palabras, oraciones y párrafos.
%%capture
!pip3 install seaborn
Más información detallada acerca de la instalación Tensorflow se puede encontrar en https://www.tensorflow.org/install/ .
Cargue el módulo TF Hub del Universal Sentence Encoder
from absl import logging
import tensorflow as tf
import tensorflow_hub as hub
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
import re
import seaborn as sns
module_url = "https://tfhub.dev/google/universal-sentence-encoder/4"
model = hub.load(module_url)
print ("module %s loaded" % module_url)
def embed(input):
return model(input)
module https://tfhub.dev/google/universal-sentence-encoder/4 loaded
Calcule una representación para cada mensaje, mostrando varias longitudes admitidas.
word = "Elephant"
sentence = "I am a sentence for which I would like to get its embedding."
paragraph = (
"Universal Sentence Encoder embeddings also support short paragraphs. "
"There is no hard limit on how long the paragraph is. Roughly, the longer "
"the more 'diluted' the embedding will be.")
messages = [word, sentence, paragraph]
# Reduce logging output.
logging.set_verbosity(logging.ERROR)
message_embeddings = embed(messages)
for i, message_embedding in enumerate(np.array(message_embeddings).tolist()):
print("Message: {}".format(messages[i]))
print("Embedding size: {}".format(len(message_embedding)))
message_embedding_snippet = ", ".join(
(str(x) for x in message_embedding[:3]))
print("Embedding: [{}, ...]\n".format(message_embedding_snippet))
Message: Elephant Embedding size: 512 Embedding: [0.008344474248588085, 0.00048079612315632403, 0.06595245748758316, ...] Message: I am a sentence for which I would like to get its embedding. Embedding size: 512 Embedding: [0.05080860108137131, -0.016524313017725945, 0.015737781301140785, ...] Message: Universal Sentence Encoder embeddings also support short paragraphs. There is no hard limit on how long the paragraph is. Roughly, the longer the more 'diluted' the embedding will be. Embedding size: 512 Embedding: [-0.028332678601145744, -0.05586216226220131, -0.012941479682922363, ...]
Ejemplo de tarea de similitud textual semántica
Las incrustaciones producidas por Universal Sentence Encoder están aproximadamente normalizadas. La similitud semántica de dos oraciones puede calcularse trivialmente como el producto interno de las codificaciones.
def plot_similarity(labels, features, rotation):
corr = np.inner(features, features)
sns.set(font_scale=1.2)
g = sns.heatmap(
corr,
xticklabels=labels,
yticklabels=labels,
vmin=0,
vmax=1,
cmap="YlOrRd")
g.set_xticklabels(labels, rotation=rotation)
g.set_title("Semantic Textual Similarity")
def run_and_plot(messages_):
message_embeddings_ = embed(messages_)
plot_similarity(messages_, message_embeddings_, 90)
Similitud visualizada
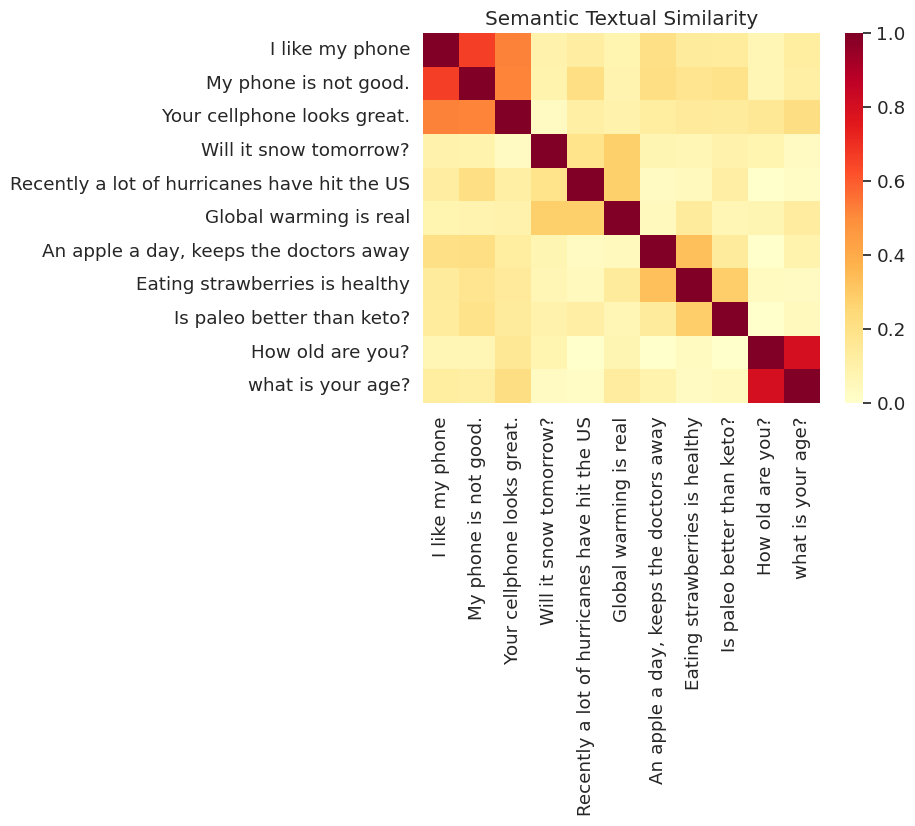
Aquí mostramos la similitud en un mapa de calor. El gráfico final es una matriz de 9x9, donde cada entrada [i, j] es de color basado en el producto interno de las codificaciones para frase i y j .
messages = [
# Smartphones
"I like my phone",
"My phone is not good.",
"Your cellphone looks great.",
# Weather
"Will it snow tomorrow?",
"Recently a lot of hurricanes have hit the US",
"Global warming is real",
# Food and health
"An apple a day, keeps the doctors away",
"Eating strawberries is healthy",
"Is paleo better than keto?",
# Asking about age
"How old are you?",
"what is your age?",
]
run_and_plot(messages)
Evaluación: Benchmark STS (Semantic Textual Similarity)
El Benchmark STS proporciona una evaluación intrínseca del grado en que las puntuaciones de similitud calcula utilizando frase inclusiones align con juicios humanos. El punto de referencia requiere que los sistemas devuelvan puntuaciones de similitud para una selección diversa de pares de oraciones. Correlación de Pearson se utiliza entonces para evaluar la calidad de las puntuaciones de similitud de la máquina contra las sentencias humanos.
Descargar datos
import pandas
import scipy
import math
import csv
sts_dataset = tf.keras.utils.get_file(
fname="Stsbenchmark.tar.gz",
origin="http://ixa2.si.ehu.es/stswiki/images/4/48/Stsbenchmark.tar.gz",
extract=True)
sts_dev = pandas.read_table(
os.path.join(os.path.dirname(sts_dataset), "stsbenchmark", "sts-dev.csv"),
error_bad_lines=False,
skip_blank_lines=True,
usecols=[4, 5, 6],
names=["sim", "sent_1", "sent_2"])
sts_test = pandas.read_table(
os.path.join(
os.path.dirname(sts_dataset), "stsbenchmark", "sts-test.csv"),
error_bad_lines=False,
quoting=csv.QUOTE_NONE,
skip_blank_lines=True,
usecols=[4, 5, 6],
names=["sim", "sent_1", "sent_2"])
# cleanup some NaN values in sts_dev
sts_dev = sts_dev[[isinstance(s, str) for s in sts_dev['sent_2']]]
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/IPython/core/interactiveshell.py:3444: FutureWarning: The error_bad_lines argument has been deprecated and will be removed in a future version. exec(code_obj, self.user_global_ns, self.user_ns)
Evaluar incrustaciones de oraciones
sts_data = sts_dev
def run_sts_benchmark(batch):
sts_encode1 = tf.nn.l2_normalize(embed(tf.constant(batch['sent_1'].tolist())), axis=1)
sts_encode2 = tf.nn.l2_normalize(embed(tf.constant(batch['sent_2'].tolist())), axis=1)
cosine_similarities = tf.reduce_sum(tf.multiply(sts_encode1, sts_encode2), axis=1)
clip_cosine_similarities = tf.clip_by_value(cosine_similarities, -1.0, 1.0)
scores = 1.0 - tf.acos(clip_cosine_similarities) / math.pi
"""Returns the similarity scores"""
return scores
dev_scores = sts_data['sim'].tolist()
scores = []
for batch in np.array_split(sts_data, 10):
scores.extend(run_sts_benchmark(batch))
pearson_correlation = scipy.stats.pearsonr(scores, dev_scores)
print('Pearson correlation coefficient = {0}\np-value = {1}'.format(
pearson_correlation[0], pearson_correlation[1]))
Pearson correlation coefficient = 0.8036394630692778 p-value = 0.0