
| | |  Ver no GitHub Ver no GitHub | |
Este Colab é uma demonstração do uso de Tensorflow Hub para a classificação texto em não-Inglês / línguas locais. Aqui podemos escolher Bangla como a língua local e usar pré-treinado embeddings palavra para resolver uma tarefa de classificação multiclasse onde classificamos Bangla artigos de notícias em 5 categorias. As incorporações pré-treinado para Bangla vem de fastText que é uma biblioteca de Facebook com vetores palavra pré-treinado liberados para 157 línguas.
Usaremos exportador incorporar pré-treinado do TF-Hub para converter a palavra embeddings a um módulo de texto incorporar em primeiro lugar e, em seguida, utilizar o módulo para treinar um classificador com tf.keras , alto nível de usuário API amigável do Tensorflow para construir modelos de aprendizagem de profundidade. Mesmo que estejamos usando embeddings fastText aqui, é possível exportar quaisquer outros embeddings pré-treinados de outras tarefas e obter resultados rapidamente com o hub Tensorflow.
Configurar
# https://github.com/pypa/setuptools/issues/1694#issuecomment-466010982pip install gdown --no-use-pep517
sudo apt-get install -y unzip
Reading package lists... Building dependency tree... Reading state information... unzip is already the newest version (6.0-21ubuntu1.1). The following packages were automatically installed and are no longer required: linux-gcp-5.4-headers-5.4.0-1040 linux-gcp-5.4-headers-5.4.0-1043 linux-gcp-5.4-headers-5.4.0-1044 linux-gcp-5.4-headers-5.4.0-1049 linux-headers-5.4.0-1049-gcp linux-image-5.4.0-1049-gcp linux-modules-5.4.0-1049-gcp linux-modules-extra-5.4.0-1049-gcp Use 'sudo apt autoremove' to remove them. 0 upgraded, 0 newly installed, 0 to remove and 143 not upgraded.
import os
import tensorflow as tf
import tensorflow_hub as hub
import gdown
import numpy as np
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
import seaborn as sns
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py:119: PkgResourcesDeprecationWarning: 0.18ubuntu0.18.04.1 is an invalid version and will not be supported in a future release PkgResourcesDeprecationWarning,
Conjunto de dados
Usaremos BARD (Bangla artigo Dataset), que tem cerca de 376.226 artigos coletados em diferentes portais de notícias Bangla e rotulados com 5 categorias: economia, estado, internacional, esportes e entretenimento. Nós baixar o arquivo de Google Drive este ( bit.ly/BARD_DATASET link) está se referindo a partir deste repositório GitHub.
gdown.download(
url='https://drive.google.com/uc?id=1Ag0jd21oRwJhVFIBohmX_ogeojVtapLy',
output='bard.zip',
quiet=True
)
'bard.zip'
unzip -qo bard.zip
Exportar vetores de palavras pré-treinados para o módulo TF-Hub
TF-Hub fornece alguns scripts úteis para converter embeddings palavras para TF-hub módulos de texto de incorporação aqui . Para fazer o módulo para Bangla ou quaisquer outros idiomas, nós simplesmente temos que baixar a palavra incorporar .txt ou .vec arquivo para o mesmo diretório que export_v2.py e executar o script.
O exportador lê os vetores de incorporação e exporta-lo para um Tensorflow SavedModel . Um SavedModel contém um programa TensorFlow completo, incluindo pesos e gráfico. TF-Hub pode carregar o SavedModel como um módulo , que vamos usar para construir o modelo para classificação de texto. Como estamos usando tf.keras para construir o modelo, vamos usar hub.KerasLayer , que fornece um wrapper para um módulo de TF-Hub para uso como uma camada Keras.
Primeiro vamos começar nossas embeddings palavra de fastText e incorporação exportador da TF-Hub repo .
curl -O https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bn.300.vec.gzcurl -O https://raw.githubusercontent.com/tensorflow/hub/master/examples/text_embeddings_v2/export_v2.pygunzip -qf cc.bn.300.vec.gz --k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 840M 100 840M 0 0 11.6M 0 0:01:12 0:01:12 --:--:-- 12.0M
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 7469 100 7469 0 0 19053 0 --:--:-- --:--:-- --:--:-- 19005
Em seguida, executaremos o script exportador em nosso arquivo de incorporação. Como os embeddings fastText têm uma linha de cabeçalho e são muito grandes (cerca de 3,3 GB para Bangla após a conversão para um módulo), ignoramos a primeira linha e exportamos apenas os primeiros 100.000 tokens para o módulo de embedding de texto.
python export_v2.py --embedding_file=cc.bn.300.vec --export_path=text_module --num_lines_to_ignore=1 --num_lines_to_use=100000
INFO:tensorflow:Assets written to: text_module/assets I1105 11:55:29.817717 140238757988160 builder_impl.py:784] Assets written to: text_module/assets
module_path = "text_module"
embedding_layer = hub.KerasLayer(module_path, trainable=False)
O módulo de incorporação de texto recebe um lote de frases em um tensor 1D de strings como entrada e produz os vetores de incorporação de forma (batch_size, embedding_dim) correspondentes às frases. Ele pré-processa a entrada dividindo em espaços. Embeddings Word são combinados para embeddings frase com as sqrtn combinador (Veja aqui ). Para demonstração, passamos uma lista de palavras Bangla como entrada e obtemos os vetores de incorporação correspondentes.
embedding_layer(['বাস', 'বসবাস', 'ট্রেন', 'যাত্রী', 'ট্রাক'])
<tf.Tensor: shape=(5, 300), dtype=float64, numpy=
array([[ 0.0462, -0.0355, 0.0129, ..., 0.0025, -0.0966, 0.0216],
[-0.0631, -0.0051, 0.085 , ..., 0.0249, -0.0149, 0.0203],
[ 0.1371, -0.069 , -0.1176, ..., 0.029 , 0.0508, -0.026 ],
[ 0.0532, -0.0465, -0.0504, ..., 0.02 , -0.0023, 0.0011],
[ 0.0908, -0.0404, -0.0536, ..., -0.0275, 0.0528, 0.0253]])>
Converter em conjunto de dados Tensorflow
Uma vez que o conjunto de dados é muito grande em vez de carregar todo o conjunto de dados na memória, vamos utilizar um gerador para produzir amostras em tempo de execução em lotes usando Tensorflow Conjunto de Dados funções. O conjunto de dados também é muito desequilibrado, então, antes de usar o gerador, iremos embaralhar o conjunto de dados.
dir_names = ['economy', 'sports', 'entertainment', 'state', 'international']
file_paths = []
labels = []
for i, dir in enumerate(dir_names):
file_names = ["/".join([dir, name]) for name in os.listdir(dir)]
file_paths += file_names
labels += [i] * len(os.listdir(dir))
np.random.seed(42)
permutation = np.random.permutation(len(file_paths))
file_paths = np.array(file_paths)[permutation]
labels = np.array(labels)[permutation]
Podemos verificar a distribuição de rótulos nos exemplos de treinamento e validação após embaralhar.
train_frac = 0.8
train_size = int(len(file_paths) * train_frac)
# plot training vs validation distribution
plt.subplot(1, 2, 1)
plt.hist(labels[0:train_size])
plt.title("Train labels")
plt.subplot(1, 2, 2)
plt.hist(labels[train_size:])
plt.title("Validation labels")
plt.tight_layout()
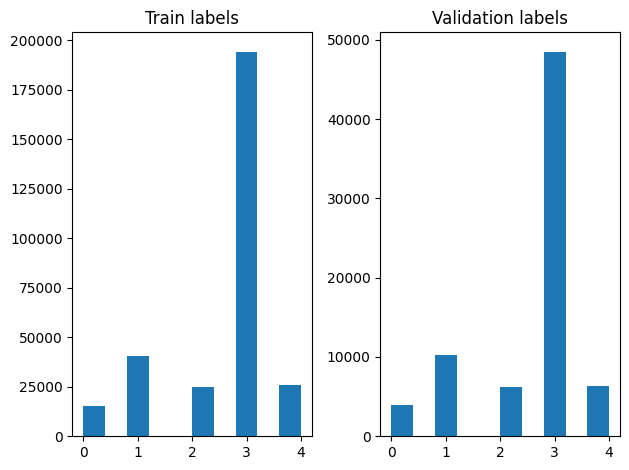
Para criar um conjunto de dados usando um gerador, primeiro escrever uma função gerador que lê cada um dos artigos de file_paths e os rótulos a partir da matriz de etiquetas, e os rendimentos exemplo, uma formação em cada etapa. Nós passamos esta função gerador para o tf.data.Dataset.from_generator método e especificar os tipos de saída. Cada exemplo é a formação de um tuplo contendo um artigo de tf.string tipo de dados e uma etiqueta codificada-quente. Nós dividir o conjunto de dados com uma divisão trem de validação de 80-20 usando tf.data.Dataset.skip e tf.data.Dataset.take métodos.
def load_file(path, label):
return tf.io.read_file(path), label
def make_datasets(train_size):
batch_size = 256
train_files = file_paths[:train_size]
train_labels = labels[:train_size]
train_ds = tf.data.Dataset.from_tensor_slices((train_files, train_labels))
train_ds = train_ds.map(load_file).shuffle(5000)
train_ds = train_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
test_files = file_paths[train_size:]
test_labels = labels[train_size:]
test_ds = tf.data.Dataset.from_tensor_slices((test_files, test_labels))
test_ds = test_ds.map(load_file)
test_ds = test_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
return train_ds, test_ds
train_data, validation_data = make_datasets(train_size)
Treinamento e avaliação de modelo
Uma vez que já adicionou um invólucro em torno do nosso módulo para usá-lo como qualquer outra camada no Keras, podemos criar um pequeno Sequential modelo que é uma pilha linear de camadas. Nós podemos adicionar o nosso módulo de embutir texto com model.add como qualquer outra camada. Compilamos o modelo especificando a perda e o otimizador e o treinamos por 10 épocas. O tf.keras API pode lidar com Tensorflow conjuntos de dados como entrada, para que possamos passar uma instância de DataSet para o método de ajuste para treinamento do modelo. Uma vez que estamos a utilizar a função de gerador, tf.data irá lidar com gerar as amostras, dosagem los e alimentá-los para o modelo.
Modelo
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[], dtype=tf.string),
embedding_layer,
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(5),
])
model.compile(loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam", metrics=['accuracy'])
return model
model = create_model()
# Create earlystopping callback
early_stopping_callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=3)
Treinamento
history = model.fit(train_data,
validation_data=validation_data,
epochs=5,
callbacks=[early_stopping_callback])
Epoch 1/5 1176/1176 [==============================] - 34s 28ms/step - loss: 0.2181 - accuracy: 0.9279 - val_loss: 0.1580 - val_accuracy: 0.9449 Epoch 2/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1411 - accuracy: 0.9505 - val_loss: 0.1411 - val_accuracy: 0.9503 Epoch 3/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1307 - accuracy: 0.9534 - val_loss: 0.1359 - val_accuracy: 0.9524 Epoch 4/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1248 - accuracy: 0.9555 - val_loss: 0.1318 - val_accuracy: 0.9527 Epoch 5/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1196 - accuracy: 0.9567 - val_loss: 0.1247 - val_accuracy: 0.9555
Avaliação
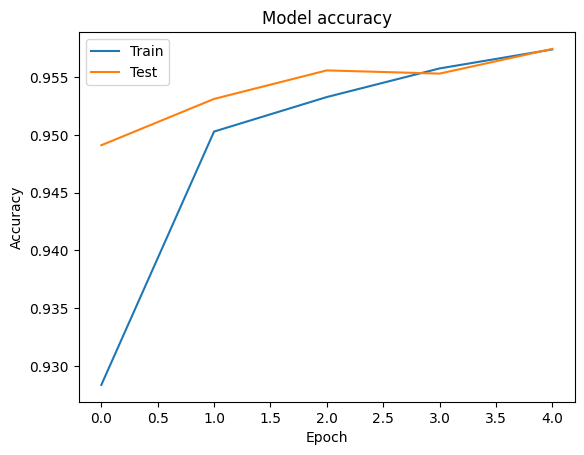
Podemos visualizar as curvas de precisão e de perda para a formação e validação de dados usando o tf.keras.callbacks.History objeto retornado pela tf.keras.Model.fit método, que contém o valor da perda e precisão para cada época.
# Plot training & validation accuracy values
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
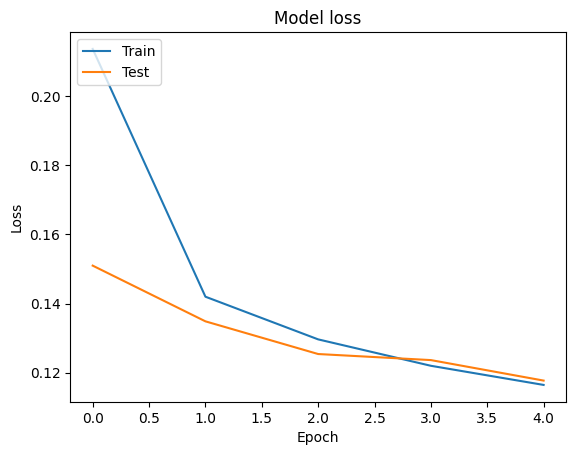
# Plot training & validation loss values
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
Predição
Podemos obter as previsões para os dados de validação e verificar a matriz de confusão para ver o desempenho do modelo para cada uma das 5 classes. Porque tf.keras.Model.predict método retorna uma matriz nd para probabilidades para cada classe, eles podem ser convertidos para etiquetas de classe usando np.argmax .
y_pred = model.predict(validation_data)
y_pred = np.argmax(y_pred, axis=1)
samples = file_paths[0:3]
for i, sample in enumerate(samples):
f = open(sample)
text = f.read()
print(text[0:100])
print("True Class: ", sample.split("/")[0])
print("Predicted Class: ", dir_names[y_pred[i]])
f.close()
রবিন উইলিয়ামস তাঁর হ্যাপি ফিট ছবিতে মজা করে বলেছিলেন, ‘আমি শুনতে পাচ্ছি, মানুষ কিছু একটা চাইছে...সে True Class: entertainment Predicted Class: state নির্মাণ শেষে ফিতা কেটে মন্ত্রী ভবন উদ্বোধন করেছেন বহু আগেই। তবে এখনো চালু করা যায়নি খাগড়াছড়ি জেল True Class: state Predicted Class: state কমলাপুর বীরশ্রেষ্ঠ মোস্তফা কামাল স্টেডিয়ামে কাল ফকিরেরপুল ইয়ংমেন্স ক্লাব ৩-০ গোলে হারিয়েছে স্বাধ True Class: sports Predicted Class: state
Compare o desempenho
Agora podemos tomar os rótulos corretos para os dados de validação de labels e compará-los com as nossas previsões para obter um classification_report .
y_true = np.array(labels[train_size:])
print(classification_report(y_true, y_pred, target_names=dir_names))
precision recall f1-score support
economy 0.83 0.76 0.79 3897
sports 0.99 0.98 0.98 10204
entertainment 0.90 0.94 0.92 6256
state 0.97 0.97 0.97 48512
international 0.92 0.93 0.93 6377
accuracy 0.96 75246
macro avg 0.92 0.92 0.92 75246
weighted avg 0.96 0.96 0.96 75246
Podemos também comparar o desempenho do nosso modelo com os resultados publicados obtidos no original de papel , que tinha um 0,96 precisão .Os autores originais descrito muitas etapas de pré-processamento executada no conjunto de dados, como deixar cair pontuações e algarismos, removendo top 25 mais frequest palavras de parada. Como podemos ver na classification_report , nós também conseguimos obter uma precisão e exatidão 0,96 após o treinamento por apenas 5 épocas sem qualquer pré-processamento!
Neste exemplo, quando criamos a camada Keras do nosso módulo de incorporação, vamos definir o parâmetro trainable=False , o que significa que os pesos de incorporação não será atualizado durante o treinamento. Tentar defini-la como True para alcançar cerca de 97% de precisão usando este conjunto de dados depois de apenas 2 épocas.