
| | |  Afficher sur GitHub Afficher sur GitHub | | |
Ce bloc-notes vous montre comment affiner les modèles CropNet de TensorFlow Hub sur un ensemble de données de TFDS ou sur votre propre ensemble de données de détection des maladies des cultures.
Vous serez:
- Chargez le jeu de données TFDS sur le manioc ou vos propres données
- Enrichir les données avec des exemples inconnus (négatifs) pour obtenir un modèle plus robuste
- Appliquer des augmentations d'image aux données
- Charger et affiner un modèle CropNet à partir de TF Hub
- Exportez un modèle TFLite, prêt à être déployé sur votre application avec Task Library , MLKit ou TFLite directement
Importations et dépendances
Avant de commencer, vous devrez installer certaines des dépendances qui seront nécessaires comme Model Maker et la dernière version de TensorFlow Datasets.
pip install --use-deprecated=legacy-resolver tflite-model-makerpip install -U tensorflow-datasets
import matplotlib.pyplot as plt
import os
import seaborn as sns
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.lite.model_maker.core.export_format import ExportFormat
from tensorflow_examples.lite.model_maker.core.task import image_preprocessing
from tflite_model_maker import image_classifier
from tflite_model_maker import ImageClassifierDataLoader
from tflite_model_maker.image_classifier import ModelSpec
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_addons/utils/ensure_tf_install.py:67: UserWarning: Tensorflow Addons supports using Python ops for all Tensorflow versions above or equal to 2.5.0 and strictly below 2.8.0 (nightly versions are not supported). The versions of TensorFlow you are currently using is 2.8.0-rc1 and is not supported. Some things might work, some things might not. If you were to encounter a bug, do not file an issue. If you want to make sure you're using a tested and supported configuration, either change the TensorFlow version or the TensorFlow Addons's version. You can find the compatibility matrix in TensorFlow Addon's readme: https://github.com/tensorflow/addons UserWarning, /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/numba/core/errors.py:154: UserWarning: Insufficiently recent colorama version found. Numba requires colorama >= 0.3.9 warnings.warn(msg)
Charger un jeu de données TFDS pour affiner
Utilisons l'ensemble de données publiquement disponible sur la maladie des feuilles de manioc de TFDS.
tfds_name = 'cassava'
(ds_train, ds_validation, ds_test), ds_info = tfds.load(
name=tfds_name,
split=['train', 'validation', 'test'],
with_info=True,
as_supervised=True)
TFLITE_NAME_PREFIX = tfds_name
Ou chargez vos propres données pour affiner
Au lieu d'utiliser un jeu de données TFDS, vous pouvez également vous entraîner sur vos propres données. Cet extrait de code montre comment charger votre propre jeu de données personnalisé. Voir ce lien pour la structure prise en charge des données. Un exemple est fourni ici en utilisant l'ensemble de données accessible au public sur la maladie des feuilles de manioc .
# data_root_dir = tf.keras.utils.get_file(
# 'cassavaleafdata.zip',
# 'https://storage.googleapis.com/emcassavadata/cassavaleafdata.zip',
# extract=True)
# data_root_dir = os.path.splitext(data_root_dir)[0] # Remove the .zip extension
# builder = tfds.ImageFolder(data_root_dir)
# ds_info = builder.info
# ds_train = builder.as_dataset(split='train', as_supervised=True)
# ds_validation = builder.as_dataset(split='validation', as_supervised=True)
# ds_test = builder.as_dataset(split='test', as_supervised=True)
Visualisez des échantillons de train split
Examinons quelques exemples de l'ensemble de données, y compris l'identifiant de classe et le nom de classe pour les échantillons d'image et leurs étiquettes.
_ = tfds.show_examples(ds_train, ds_info)

Ajouter des images à utiliser comme exemples inconnus à partir d'ensembles de données TFDS
Ajoutez des exemples inconnus (négatifs) supplémentaires à l'ensemble de données d'apprentissage et attribuez-leur un nouveau numéro d'étiquette de classe inconnue. L'objectif est d'avoir un modèle qui, lorsqu'il est utilisé dans la pratique (par exemple sur le terrain), a la possibilité de prédire "Inconnu" lorsqu'il voit quelque chose d'inattendu.
Vous trouverez ci-dessous une liste d'ensembles de données qui seront utilisés pour échantillonner les images inconnues supplémentaires. Il comprend 3 ensembles de données complètement différents pour augmenter la diversité. L'un d'eux est un ensemble de données sur les maladies des feuilles des haricots, de sorte que le modèle est exposé à des plantes malades autres que le manioc.
UNKNOWN_TFDS_DATASETS = [{
'tfds_name': 'imagenet_v2/matched-frequency',
'train_split': 'test[:80%]',
'test_split': 'test[80%:]',
'num_examples_ratio_to_normal': 1.0,
}, {
'tfds_name': 'oxford_flowers102',
'train_split': 'train',
'test_split': 'test',
'num_examples_ratio_to_normal': 1.0,
}, {
'tfds_name': 'beans',
'train_split': 'train',
'test_split': 'test',
'num_examples_ratio_to_normal': 1.0,
}]
Les ensembles de données UNKNOWN sont également chargés à partir de TFDS.
# Load unknown datasets.
weights = [
spec['num_examples_ratio_to_normal'] for spec in UNKNOWN_TFDS_DATASETS
]
num_unknown_train_examples = sum(
int(w * ds_train.cardinality().numpy()) for w in weights)
ds_unknown_train = tf.data.Dataset.sample_from_datasets([
tfds.load(
name=spec['tfds_name'], split=spec['train_split'],
as_supervised=True).repeat(-1) for spec in UNKNOWN_TFDS_DATASETS
], weights).take(num_unknown_train_examples)
ds_unknown_train = ds_unknown_train.apply(
tf.data.experimental.assert_cardinality(num_unknown_train_examples))
ds_unknown_tests = [
tfds.load(
name=spec['tfds_name'], split=spec['test_split'], as_supervised=True)
for spec in UNKNOWN_TFDS_DATASETS
]
ds_unknown_test = ds_unknown_tests[0]
for ds in ds_unknown_tests[1:]:
ds_unknown_test = ds_unknown_test.concatenate(ds)
# All examples from the unknown datasets will get a new class label number.
num_normal_classes = len(ds_info.features['label'].names)
unknown_label_value = tf.convert_to_tensor(num_normal_classes, tf.int64)
ds_unknown_train = ds_unknown_train.map(lambda image, _:
(image, unknown_label_value))
ds_unknown_test = ds_unknown_test.map(lambda image, _:
(image, unknown_label_value))
# Merge the normal train dataset with the unknown train dataset.
weights = [
ds_train.cardinality().numpy(),
ds_unknown_train.cardinality().numpy()
]
ds_train_with_unknown = tf.data.Dataset.sample_from_datasets(
[ds_train, ds_unknown_train], [float(w) for w in weights])
ds_train_with_unknown = ds_train_with_unknown.apply(
tf.data.experimental.assert_cardinality(sum(weights)))
print((f"Added {ds_unknown_train.cardinality().numpy()} negative examples."
f"Training dataset has now {ds_train_with_unknown.cardinality().numpy()}"
' examples in total.'))
Added 16968 negative examples.Training dataset has now 22624 examples in total.
Appliquer des augmentations
Pour toutes les images, pour les rendre plus diversifiées, vous appliquerez une augmentation, comme des changements dans :
- Luminosité
- Contraste
- Saturation
- Teinte
- Recadrer
Ces types d'augmentations contribuent à rendre le modèle plus robuste aux variations des entrées d'image.
def random_crop_and_random_augmentations_fn(image):
# preprocess_for_train does random crop and resize internally.
image = image_preprocessing.preprocess_for_train(image)
image = tf.image.random_brightness(image, 0.2)
image = tf.image.random_contrast(image, 0.5, 2.0)
image = tf.image.random_saturation(image, 0.75, 1.25)
image = tf.image.random_hue(image, 0.1)
return image
def random_crop_fn(image):
# preprocess_for_train does random crop and resize internally.
image = image_preprocessing.preprocess_for_train(image)
return image
def resize_and_center_crop_fn(image):
image = tf.image.resize(image, (256, 256))
image = image[16:240, 16:240]
return image
no_augment_fn = lambda image: image
train_augment_fn = lambda image, label: (
random_crop_and_random_augmentations_fn(image), label)
eval_augment_fn = lambda image, label: (resize_and_center_crop_fn(image), label)
Pour appliquer l'augmentation, il utilise la méthode map de la classe Dataset.
ds_train_with_unknown = ds_train_with_unknown.map(train_augment_fn)
ds_validation = ds_validation.map(eval_augment_fn)
ds_test = ds_test.map(eval_augment_fn)
ds_unknown_test = ds_unknown_test.map(eval_augment_fn)
INFO:tensorflow:Use default resize_bicubic. INFO:tensorflow:Use default resize_bicubic. INFO:tensorflow:Use customized resize method bilinear INFO:tensorflow:Use customized resize method bilinear
Enveloppez les données dans un format convivial pour Model Maker
Pour utiliser ces ensembles de données avec Model Maker, ils doivent se trouver dans une classe ImageClassifierDataLoader.
label_names = ds_info.features['label'].names + ['UNKNOWN']
train_data = ImageClassifierDataLoader(ds_train_with_unknown,
ds_train_with_unknown.cardinality(),
label_names)
validation_data = ImageClassifierDataLoader(ds_validation,
ds_validation.cardinality(),
label_names)
test_data = ImageClassifierDataLoader(ds_test, ds_test.cardinality(),
label_names)
unknown_test_data = ImageClassifierDataLoader(ds_unknown_test,
ds_unknown_test.cardinality(),
label_names)
Entraînement à la course
TensorFlow Hub propose plusieurs modèles pour l'apprentissage par transfert.
Ici, vous pouvez en choisir un et vous pouvez également continuer à expérimenter avec d'autres pour essayer d'obtenir de meilleurs résultats.
Si vous souhaitez essayer encore plus de modèles, vous pouvez les ajouter à partir de cette collection .
Choisissez un modèle de base
model_name = 'mobilenet_v3_large_100_224'
map_model_name = {
'cropnet_cassava':
'https://tfhub.dev/google/cropnet/feature_vector/cassava_disease_V1/1',
'cropnet_concat':
'https://tfhub.dev/google/cropnet/feature_vector/concat/1',
'cropnet_imagenet':
'https://tfhub.dev/google/cropnet/feature_vector/imagenet/1',
'mobilenet_v3_large_100_224':
'https://tfhub.dev/google/imagenet/mobilenet_v3_large_100_224/feature_vector/5',
}
model_handle = map_model_name[model_name]
Pour affiner le modèle, vous utiliserez Model Maker. Cela facilite la solution globale car après la formation du modèle, il le convertira également en TFLite.
Model Maker fait de cette conversion la meilleure possible et avec toutes les informations nécessaires pour déployer facilement le modèle sur l'appareil ultérieurement.
La spécification du modèle est la façon dont vous indiquez à Model Maker quel modèle de base vous souhaitez utiliser.
image_model_spec = ModelSpec(uri=model_handle)
Un détail important ici est la définition de train_whole_model qui affinera le modèle de base pendant la formation. Cela rend le processus plus lent mais le modèle final a une plus grande précision. La configuration de la shuffle garantit que le modèle voit les données dans un ordre mélangé aléatoire, ce qui est une bonne pratique pour l'apprentissage du modèle.
model = image_classifier.create(
train_data,
model_spec=image_model_spec,
batch_size=128,
learning_rate=0.03,
epochs=5,
shuffle=True,
train_whole_model=True,
validation_data=validation_data)
INFO:tensorflow:Retraining the models...
INFO:tensorflow:Retraining the models...
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
hub_keras_layer_v1v2 (HubKe (None, 1280) 4226432
rasLayerV1V2)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 6) 7686
=================================================================
Total params: 4,234,118
Trainable params: 4,209,718
Non-trainable params: 24,400
_________________________________________________________________
None
Epoch 1/5
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/optimizer_v2/gradient_descent.py:102: UserWarning: The `lr` argument is deprecated, use `learning_rate` instead.
super(SGD, self).__init__(name, **kwargs)
176/176 [==============================] - 120s 488ms/step - loss: 0.8874 - accuracy: 0.9148 - val_loss: 1.1721 - val_accuracy: 0.7935
Epoch 2/5
176/176 [==============================] - 84s 444ms/step - loss: 0.7907 - accuracy: 0.9532 - val_loss: 1.0761 - val_accuracy: 0.8100
Epoch 3/5
176/176 [==============================] - 85s 441ms/step - loss: 0.7743 - accuracy: 0.9582 - val_loss: 1.0305 - val_accuracy: 0.8444
Epoch 4/5
176/176 [==============================] - 79s 409ms/step - loss: 0.7653 - accuracy: 0.9611 - val_loss: 1.0166 - val_accuracy: 0.8422
Epoch 5/5
176/176 [==============================] - 75s 402ms/step - loss: 0.7534 - accuracy: 0.9665 - val_loss: 0.9988 - val_accuracy: 0.8555
Évaluer le modèle lors du fractionnement de test
model.evaluate(test_data)
59/59 [==============================] - 10s 81ms/step - loss: 0.9956 - accuracy: 0.8594 [0.9956456422805786, 0.8594164252281189]
Pour avoir une compréhension encore meilleure du modèle affiné, il est bon d'analyser la matrice de confusion. Cela montrera à quelle fréquence une classe est prédite comme une autre.
def predict_class_label_number(dataset):
"""Runs inference and returns predictions as class label numbers."""
rev_label_names = {l: i for i, l in enumerate(label_names)}
return [
rev_label_names[o[0][0]]
for o in model.predict_top_k(dataset, batch_size=128)
]
def show_confusion_matrix(cm, labels):
plt.figure(figsize=(10, 8))
sns.heatmap(cm, xticklabels=labels, yticklabels=labels,
annot=True, fmt='g')
plt.xlabel('Prediction')
plt.ylabel('Label')
plt.show()
confusion_mtx = tf.math.confusion_matrix(
list(ds_test.map(lambda x, y: y)),
predict_class_label_number(test_data),
num_classes=len(label_names))
show_confusion_matrix(confusion_mtx, label_names)
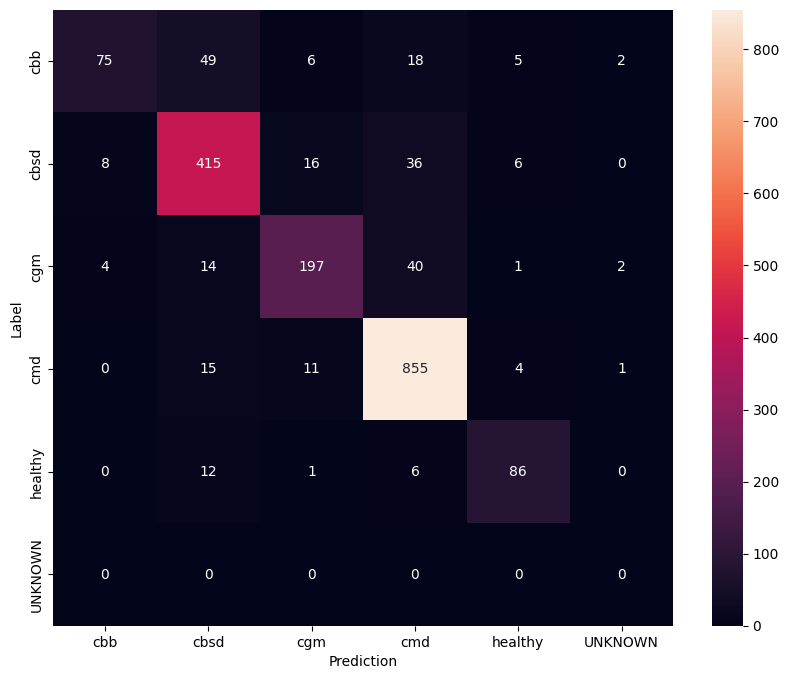
Évaluer le modèle sur des données de test inconnues
Dans cette évaluation, nous nous attendons à ce que le modèle ait une précision de près de 1. Toutes les images sur lesquelles le modèle est testé ne sont pas liées à l'ensemble de données normal et nous nous attendons donc à ce que le modèle prédise l'étiquette de classe "Inconnu".
model.evaluate(unknown_test_data)
259/259 [==============================] - 36s 127ms/step - loss: 0.6777 - accuracy: 0.9996 [0.677702784538269, 0.9996375441551208]
Imprimez la matrice de confusion.
unknown_confusion_mtx = tf.math.confusion_matrix(
list(ds_unknown_test.map(lambda x, y: y)),
predict_class_label_number(unknown_test_data),
num_classes=len(label_names))
show_confusion_matrix(unknown_confusion_mtx, label_names)
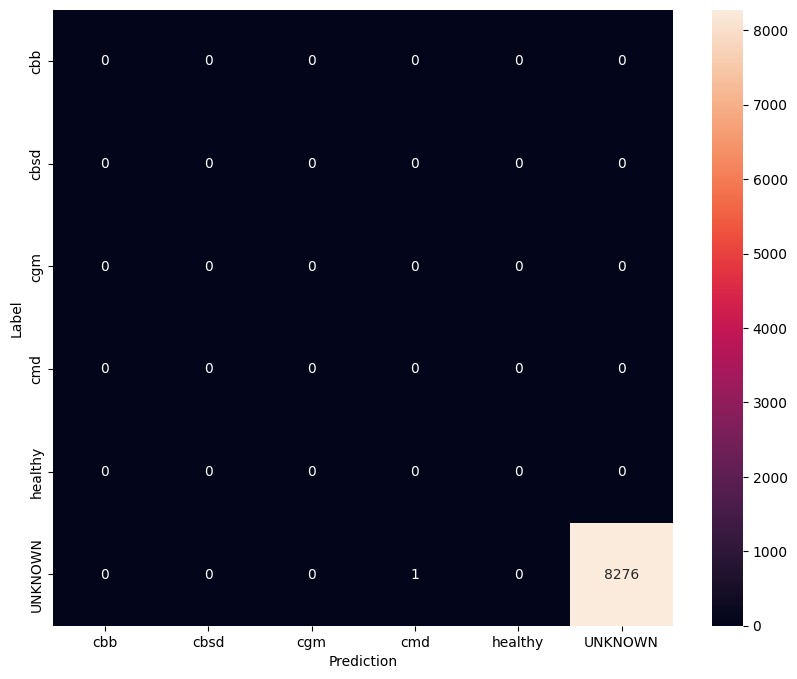
Exporter le modèle en tant que TFLite et SavedModel
Nous pouvons désormais exporter les modèles formés aux formats TFLite et SavedModel pour les déployer sur l'appareil et les utiliser pour l'inférence dans TensorFlow.
tflite_filename = f'{TFLITE_NAME_PREFIX}_model_{model_name}.tflite'
model.export(export_dir='.', tflite_filename=tflite_filename)
2022-01-26 12:25:57.742415: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
INFO:tensorflow:Assets written to: /tmp/tmppliqmyki/assets
INFO:tensorflow:Assets written to: /tmp/tmppliqmyki/assets
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/lite/python/convert.py:746: UserWarning: Statistics for quantized inputs were expected, but not specified; continuing anyway.
warnings.warn("Statistics for quantized inputs were expected, but not "
2022-01-26 12:26:07.247752: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:357] Ignored output_format.
2022-01-26 12:26:07.247806: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:360] Ignored drop_control_dependency.
INFO:tensorflow:Label file is inside the TFLite model with metadata.
fully_quantize: 0, inference_type: 6, input_inference_type: 3, output_inference_type: 3
INFO:tensorflow:Label file is inside the TFLite model with metadata.
INFO:tensorflow:Saving labels in /tmp/tmp_k_gr9mu/labels.txt
INFO:tensorflow:Saving labels in /tmp/tmp_k_gr9mu/labels.txt
INFO:tensorflow:TensorFlow Lite model exported successfully: ./cassava_model_mobilenet_v3_large_100_224.tflite
INFO:tensorflow:TensorFlow Lite model exported successfully: ./cassava_model_mobilenet_v3_large_100_224.tflite
# Export saved model version.
model.export(export_dir='.', export_format=ExportFormat.SAVED_MODEL)
INFO:tensorflow:Assets written to: ./saved_model/assets INFO:tensorflow:Assets written to: ./saved_model/assets
Prochaines étapes
Le modèle que vous venez de former peut être utilisé sur des appareils mobiles et même déployé sur le terrain !
Pour télécharger le modèle, cliquez sur l'icône de dossier du menu Fichiers sur le côté gauche du colab, puis choisissez l'option de téléchargement.
La même technique utilisée ici pourrait être appliquée à d'autres tâches sur les maladies des plantes qui pourraient être plus adaptées à votre cas d'utilisation ou à tout autre type de tâche de classification d'images. Si vous souhaitez suivre et déployer sur une application Android, vous pouvez continuer sur ce guide de démarrage rapide Android .