
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
अवलोकन
यह ट्यूटोरियल TensorFlow Lattice (TFL) लाइब्रेरी द्वारा प्रदान की गई बाधाओं और नियमितताओं का अवलोकन है। यहां हम सिंथेटिक डेटासेट पर टीएफएल डिब्बाबंद अनुमानक का उपयोग करते हैं, लेकिन ध्यान दें कि इस ट्यूटोरियल में सब कुछ टीएफएल केरस परतों से निर्मित मॉडल के साथ भी किया जा सकता है।
आगे बढ़ने से पहले, सुनिश्चित करें कि आपके रनटाइम में सभी आवश्यक पैकेज स्थापित हैं (जैसा कि नीचे दिए गए कोड सेल में आयात किया गया है)।
सेट अप
TF जाली पैकेज स्थापित करना:
pip install -q tensorflow-lattice
आवश्यक पैकेज आयात करना:
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
इस गाइड में उपयोग किए गए डिफ़ॉल्ट मान:
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
रैंकिंग रेस्तरां के लिए प्रशिक्षण डेटासेट
एक सरलीकृत परिदृश्य की कल्पना करें जहां हम यह निर्धारित करना चाहते हैं कि उपयोगकर्ता किसी रेस्तरां खोज परिणाम पर क्लिक करेंगे या नहीं। कार्य इनपुट सुविधाओं को देखते हुए क्लिकथ्रू दर (सीटीआर) की भविष्यवाणी करना है:
- औसत रेटिंग (
avg_rating): रेंज [1,5] में मूल्यों के साथ एक अंकीय सुविधा। - समीक्षा की संख्या (
num_reviews): 200 पर सीमित कर दिया मूल्यों, जो हम trendiness का एक उपाय के रूप में उपयोग के साथ एक अंकीय सुविधा। - डॉलर रेटिंग (
dollar_rating): सेट { 'डी', 'डीडी "," DDD "," dddd "} में स्ट्रिंग मूल्यों के साथ एक स्पष्ट सुविधा।
यहां हम एक सिंथेटिक डेटासेट बनाते हैं जहां सही सीटीआर सूत्र द्वारा दिया जाता है:
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
जहां \(b(\cdot)\) प्रत्येक तब्दील dollar_rating एक आधारभूत मूल्य रहे हैं:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
यह सूत्र विशिष्ट उपयोगकर्ता पैटर्न को दर्शाता है। उदाहरण के लिए बाकी सब कुछ तय है, उपयोगकर्ता उच्च स्टार रेटिंग वाले रेस्तरां पसंद करते हैं, और "\$\$" रेस्तरां को "\$" से अधिक क्लिक प्राप्त होंगे, इसके बाद "\$\$\$" और "\$\$\$ \$"।
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
आइए इस CTR फ़ंक्शन के कंटूर प्लॉट्स पर एक नज़र डालें।
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
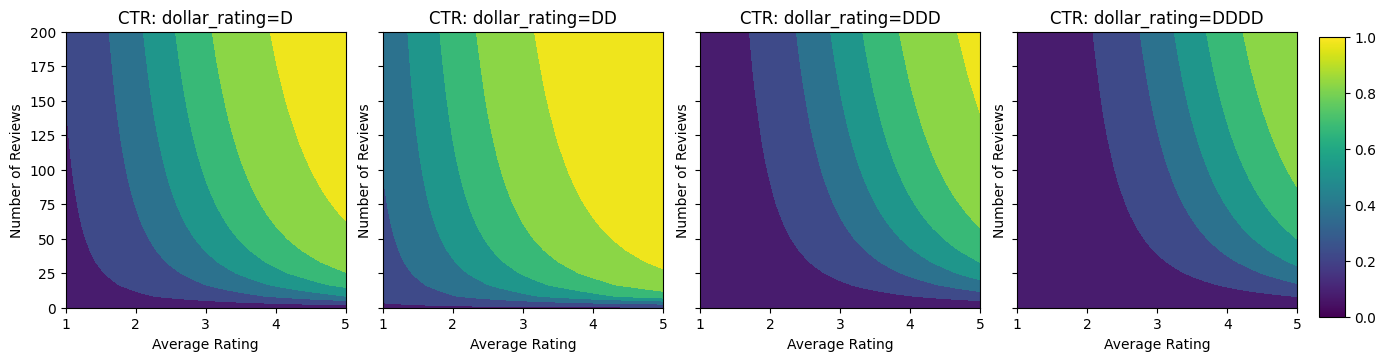
डेटा तैयार करना
अब हमें अपने सिंथेटिक डेटासेट बनाने की जरूरत है। हम रेस्तरां और उनकी विशेषताओं का एक नकली डेटासेट बनाकर शुरू करते हैं।
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
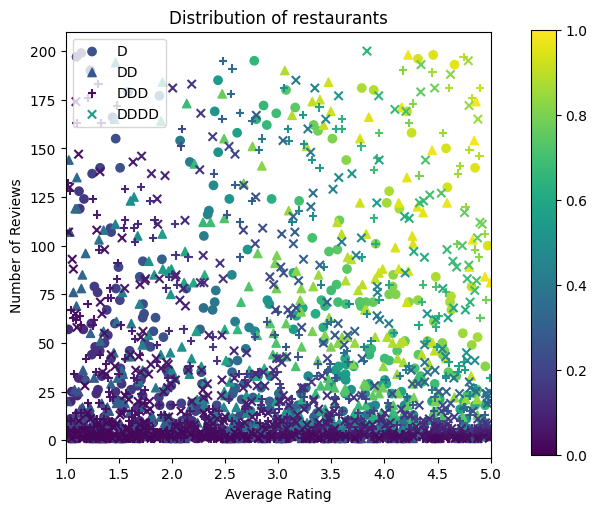
आइए प्रशिक्षण, सत्यापन और परीक्षण डेटासेट तैयार करें। जब खोज परिणामों में कोई रेस्तरां देखा जाता है, तो हम नमूना बिंदु के रूप में उपयोगकर्ता की व्यस्तता (क्लिक या नो क्लिक) को रिकॉर्ड कर सकते हैं।
व्यवहार में, उपयोगकर्ता अक्सर सभी खोज परिणामों से नहीं गुजरते हैं। इसका मतलब यह है कि उपयोगकर्ताओं को केवल मौजूदा रैंकिंग मॉडल द्वारा पहले से ही "अच्छा" माना जाने वाला रेस्तरां दिखाई देगा। नतीजतन, "अच्छे" रेस्तरां अधिक बार प्रभावित होते हैं और प्रशिक्षण डेटासेट में अधिक प्रतिनिधित्व करते हैं। अधिक सुविधाओं का उपयोग करते समय, प्रशिक्षण डेटासेट में सुविधा स्थान के "खराब" भागों में बड़े अंतराल हो सकते हैं।
जब मॉडल का उपयोग रैंकिंग के लिए किया जाता है, तो इसका मूल्यांकन अक्सर सभी प्रासंगिक परिणामों पर अधिक समान वितरण के साथ किया जाता है जो कि प्रशिक्षण डेटासेट द्वारा अच्छी तरह से प्रतिनिधित्व नहीं किया जाता है। अधिक प्रतिनिधित्व वाले डेटा बिंदुओं को ओवरफिट करने के कारण इस मामले में एक लचीला और जटिल मॉडल विफल हो सकता है और इस प्रकार सामान्यीकरण की कमी होती है। हम आकार की कमी है कि उचित भविष्यवाणियों जब यह उन्हें प्रशिक्षण डाटासेट से लेने नहीं कर सकता बनाने के लिए मॉडल मार्गदर्शन जोड़ने के लिए डोमेन ज्ञान को लागू करके इस समस्या को संभाल।
इस उदाहरण में, प्रशिक्षण डेटासेट में ज्यादातर अच्छे और लोकप्रिय रेस्तरां के साथ उपयोगकर्ता इंटरैक्शन होते हैं। ऊपर चर्चा की गई मूल्यांकन सेटिंग को अनुकरण करने के लिए परीक्षण डेटासेट में एक समान वितरण होता है। ध्यान दें कि ऐसे परीक्षण डेटासेट वास्तविक समस्या सेटिंग में उपलब्ध नहीं होंगे।
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)

प्रशिक्षण और मूल्यांकन के लिए उपयोग किए जाने वाले input_fns को परिभाषित करना:
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
फिटिंग ग्रेडिएंट बूस्टेड ट्री
: के केवल दो सुविधाओं के साथ शुरू करते avg_rating और num_reviews ।
हम सत्यापन और परीक्षण मेट्रिक्स की साजिश रचने और गणना करने के लिए कुछ सहायक कार्य बनाते हैं।
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
हम डेटासेट पर TensorFlow ग्रेडिएंट बूस्टेड डिसीजन ट्री फिट कर सकते हैं:
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021

भले ही मॉडल ने वास्तविक सीटीआर के सामान्य आकार पर कब्जा कर लिया है और अच्छे सत्यापन मेट्रिक्स हैं, लेकिन इनपुट स्पेस के कई हिस्सों में इसका प्रति-सहज व्यवहार है: अनुमानित सीटीआर औसत रेटिंग या समीक्षाओं की संख्या में वृद्धि के रूप में घट जाती है। यह प्रशिक्षण डेटासेट द्वारा अच्छी तरह से कवर नहीं किए गए क्षेत्रों में नमूना बिंदुओं की कमी के कारण है। मॉडल के पास केवल डेटा से सही व्यवहार निकालने का कोई तरीका नहीं है।
इस समस्या को हल करने के लिए, हम आकार की बाधा को लागू करते हैं कि मॉडल को औसत रेटिंग और समीक्षाओं की संख्या दोनों के संबंध में नीरस रूप से बढ़ते मूल्यों को आउटपुट करना चाहिए। हम बाद में देखेंगे कि इसे टीएफएल में कैसे लागू किया जाए।
एक डीएनएन फिटिंग
हम DNN क्लासिफायरियर के साथ समान चरणों को दोहरा सकते हैं। हम एक समान पैटर्न का निरीक्षण कर सकते हैं: कम संख्या में समीक्षाओं के साथ पर्याप्त नमूना बिंदु नहीं होने से निरर्थक एक्सट्रपलेशन होता है। ध्यान दें कि भले ही सत्यापन मीट्रिक ट्री समाधान से बेहतर है, परीक्षण मीट्रिक बहुत खराब है।
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022

आकार की कमी
TensorFlow Lattice (TFL) प्रशिक्षण डेटा से परे मॉडल व्यवहार की सुरक्षा के लिए आकार की बाधाओं को लागू करने पर केंद्रित है। ये आकार बाधाएँ TFL Keras परतों पर लागू होती हैं। उनके विवरण में पाया जा सकता हमारे JMLR कागज ।
इस ट्यूटोरियल में हम विभिन्न आकार की बाधाओं को कवर करने के लिए TF डिब्बाबंद अनुमानकों का उपयोग करते हैं, लेकिन ध्यान दें कि ये सभी चरण TFL केरस परतों से बनाए गए मॉडल के साथ किए जा सकते हैं।
किसी अन्य TensorFlow आकलनकर्ता के साथ के रूप में, टीएफएल डिब्बाबंद आकलनकर्ता का उपयोग सुविधा कॉलम इनपुट प्रारूप को परिभाषित करने और एक प्रशिक्षण input_fn का उपयोग डेटा में पारित करने के लिए करने के लिए। TFL डिब्बाबंद अनुमानकों का उपयोग करने के लिए यह भी आवश्यक है:
- एक मॉडल config: मॉडल वास्तुकला और प्रति-सुविधा आकार की कमी और regularizers को परिभाषित।
- एक सुविधा विश्लेषण input_fn: टीएफएल आरंभीकरण के लिए डेटा गुजर input_fn एक TF।
अधिक विस्तृत विवरण के लिए, कृपया डिब्बाबंद अनुमानक ट्यूटोरियल या एपीआई दस्तावेज़ देखें।
दिष्टता
हम पहले दोनों विशेषताओं में एकरसता आकार की बाधाओं को जोड़कर एकरसता की चिंताओं को संबोधित करते हैं।
टीएफएल निर्देश देने के लिए आकार की कमी को लागू करने के लिए, हम सुविधा कॉन्फ़िगरेशन में कमी निर्दिष्ट करें। निम्नलिखित कोड से पता चलता है कि किस प्रकार हम उत्पादन की आवश्यकता होती है सकते हैं होगा- दोनों के संबंध में बढ़ रही है होना करने के लिए num_reviews और avg_rating की स्थापना करके monotonicity="increasing" ।
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972

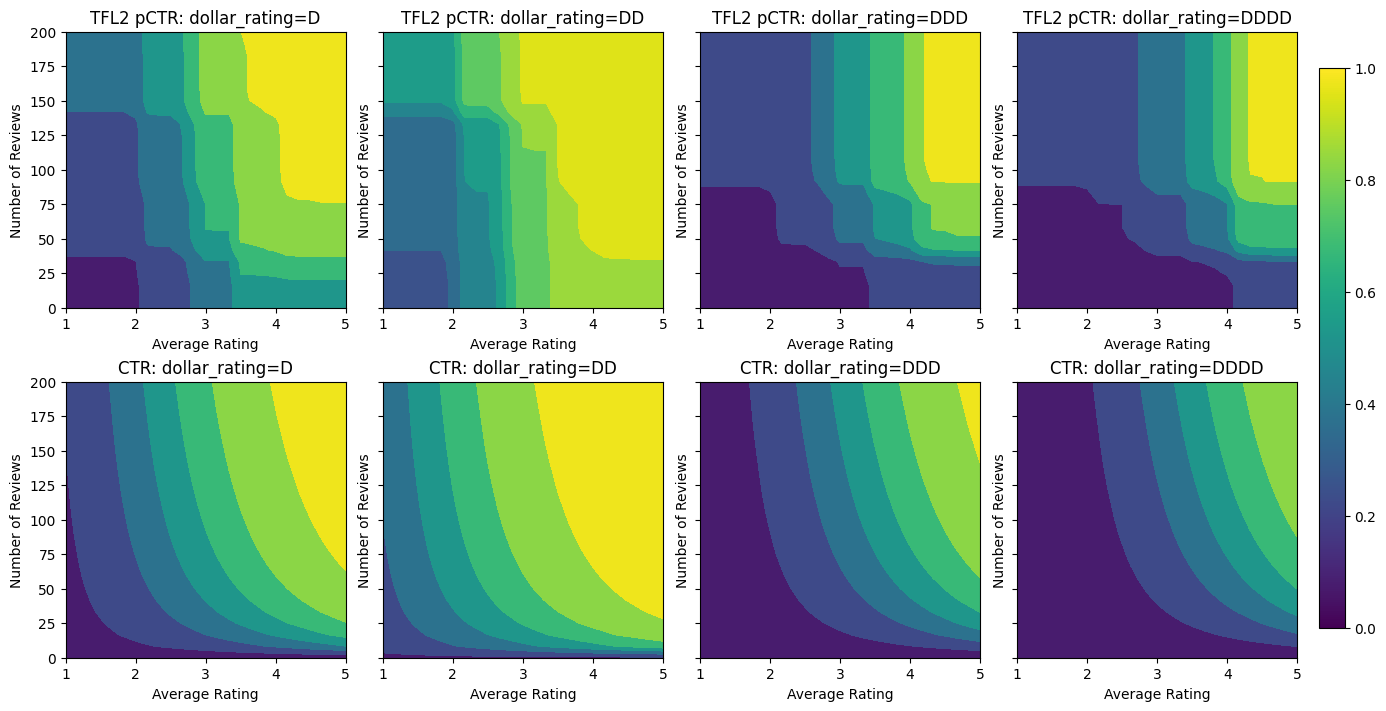
एक का उपयोग करना CalibratedLatticeConfig एक डिब्बा बंद वर्गीकारक कि पहले प्रत्येक इनपुट (एक टुकड़ा के लिहाज से सांख्यिक सुविधाओं के लिए रेखीय कार्य) के लिए एक अंशशोधक लागू होता है बनाता है कैलिब्रेटेड सुविधाओं फ्यूज करने के लिए गैर रैखिक एक जाली परत द्वारा पीछा किया। हम उपयोग कर सकते हैं tfl.visualization मॉडल कल्पना करने के लिए। विशेष रूप से, निम्नलिखित प्लॉट डिब्बाबंद क्लासिफायरियर में शामिल दो प्रशिक्षित अंशशोधकों को दर्शाता है।
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)

बाधाओं को जोड़ने के साथ, औसत रेटिंग बढ़ने या समीक्षाओं की संख्या बढ़ने पर अनुमानित सीटीआर हमेशा बढ़ेगा। यह सुनिश्चित करके किया जाता है कि अंशशोधक और जाली मोनोटोनिक हैं।
न्यासियों का बोर्ड
रिटर्न ह्रासमान का मतलब है कि एक निश्चित सुविधा मूल्य में वृद्धि के सीमांत लाभ के रूप में हम मूल्य में वृद्धि को कम करेगा। हमारे मामले में हम चाहते हैं कि उम्मीद num_reviews सुविधा तो हम अपने अंशशोधक तदनुसार कॉन्फ़िगर कर सकते हैं, इस पद्धति का अनुसरण करता। ध्यान दें कि हम घटते प्रतिफल को दो पर्याप्त स्थितियों में विघटित कर सकते हैं:
- अंशशोधक नीरस रूप से बढ़ रहा है, और
- अंशशोधक अवतल है।
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
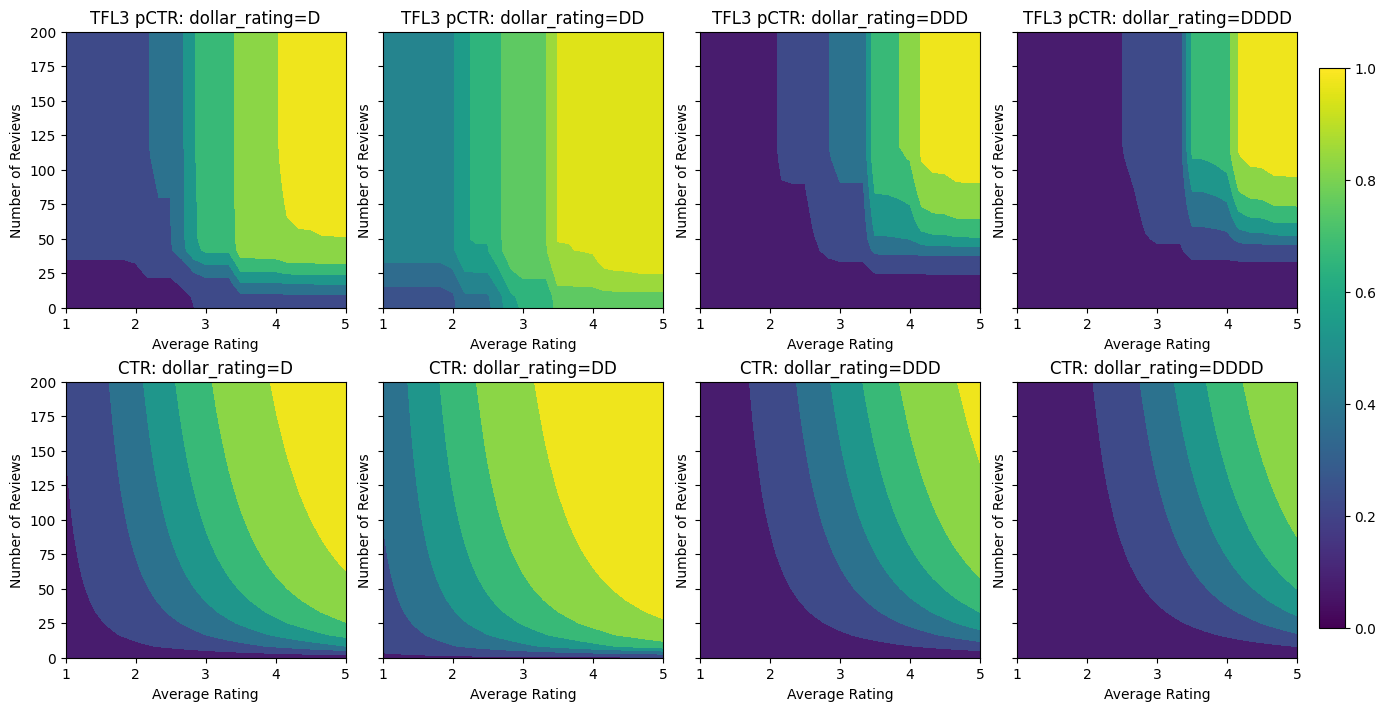

ध्यान दें कि कैसे टेस्टिंग मेट्रिक में कॉन्कैविटी बाधा को जोड़कर सुधार किया जाता है। भविष्यवाणी की साजिश भी जमीनी सच्चाई से बेहतर मिलती है।
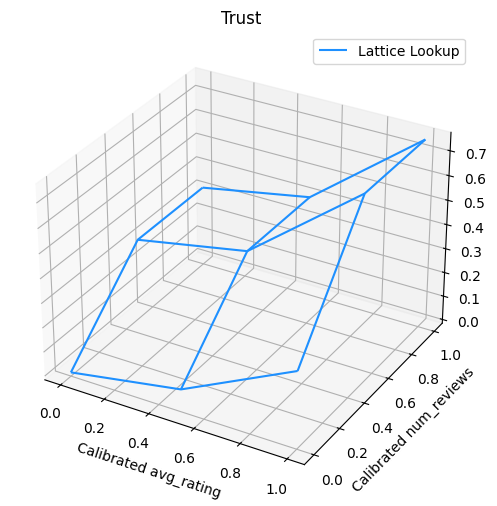
2डी आकार की बाधा: भरोसा
केवल एक या दो समीक्षाओं वाले रेस्तरां के लिए 5-स्टार रेटिंग एक अविश्वसनीय रेटिंग होने की संभावना है (रेस्तरां वास्तव में अच्छा नहीं हो सकता है), जबकि सैकड़ों समीक्षाओं वाले रेस्तरां के लिए 4-स्टार रेटिंग अधिक विश्वसनीय है (रेस्तरां है इस मामले में अच्छा होने की संभावना है)। हम देख सकते हैं कि किसी रेस्तरां की समीक्षाओं की संख्या इस बात को प्रभावित करती है कि हम उसकी औसत रेटिंग पर कितना भरोसा करते हैं।
हम मॉडल को सूचित करने के लिए टीएफएल ट्रस्ट बाधाओं का प्रयोग कर सकते हैं कि एक फीचर का बड़ा (या छोटा) मान किसी अन्य फीचर की अधिक निर्भरता या विश्वास को इंगित करता है। इस सेटिंग के द्वारा किया जाता है reflects_trust_in सुविधा config में विन्यास।
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323

निम्नलिखित प्लॉट प्रशिक्षित जाली फ़ंक्शन प्रस्तुत करता है। विश्वास बाधा के कारण, हम उम्मीद करते हैं कि कैलिब्रेटेड के बड़े मान num_reviews कैलिब्रेटेड के संबंध में उच्च ढलान मजबूर होना पड़ा avg_rating , जाली उत्पादन में और अधिक महत्वपूर्ण कदम हो जाती है।
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
चौरसाई अंशशोधक
चलो अब की अंशशोधक पर एक नज़र डालते हैं avg_rating । यद्यपि यह नीरस रूप से बढ़ रहा है, इसके ढलानों में परिवर्तन अचानक और व्याख्या करना कठिन है। यही कारण है कि पता चलता है कि हम इस अंशशोधक में एक regularizer सेटअप का उपयोग चौरसाई विचार करना चाह सकते regularizer_configs ।
यहाँ हम एक लागू wrinkle regularizer वक्रता में परिवर्तन को कम करने। तुम भी उपयोग कर सकते हैं laplacian अंशशोधक और समतल regularizer hessian regularizer यह अधिक रैखिक बनाने के लिए।
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637


अंशशोधक अब सुचारू हैं, और समग्र अनुमानित सीटीआर जमीनी सच्चाई से बेहतर मेल खाता है। यह परीक्षण मीट्रिक और समोच्च भूखंडों दोनों में परिलक्षित होता है।
श्रेणीबद्ध अंशांकन के लिए आंशिक एकरसता
अब तक हम मॉडल में केवल दो संख्यात्मक विशेषताओं का उपयोग कर रहे हैं। यहां हम एक श्रेणीबद्ध अंशांकन परत का उपयोग करके एक तीसरी विशेषता जोड़ेंगे। फिर से हम प्लॉटिंग और मीट्रिक गणना के लिए सहायक कार्यों को स्थापित करके शुरू करते हैं।
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
तीसरे सुविधा को शामिल करने के लिए, dollar_rating , हम उस स्पष्ट सुविधाओं दोनों एक विशेषता स्तंभ के रूप में और एक सुविधा config के रूप में टीएफएल में एक अलग उपचार की आवश्यकता होती है याद करना चाहिए। यहां हम आंशिक एकरसता बाधा को लागू करते हैं कि "डीडी" रेस्तरां के लिए आउटपुट "डी" रेस्तरां से बड़ा होना चाहिए जब अन्य सभी इनपुट तय हो जाएं। इस का उपयोग किया जाता monotonicity सुविधा config में स्थापित कर लिया।
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056


यह स्पष्ट अंशशोधक मॉडल आउटपुट की वरीयता को दर्शाता है: डीडी> डी> डीडीडी> डीडीडीडी, जो हमारे सेटअप के अनुरूप है। ध्यान दें कि लापता मानों के लिए एक कॉलम भी है। हालांकि हमारे प्रशिक्षण और परीक्षण डेटा में कोई लापता विशेषता नहीं है, मॉडल हमें लापता मूल्य के लिए एक आरोप प्रदान करता है जो डाउनस्ट्रीम मॉडल की सेवा के दौरान होता है।
यहाँ हम भी इस मॉडल पर वातानुकूलित की अनुमानित सीटीआर साजिश dollar_rating । ध्यान दें कि हमारे द्वारा आवश्यक सभी बाधाओं को प्रत्येक स्लाइस में पूरा किया गया है।
आउटपुट कैलिब्रेशन
अब तक हमने जितने भी टीएफएल मॉडल को प्रशिक्षित किया है, उनके लिए जाली परत (मॉडल ग्राफ में "जाली" के रूप में इंगित) सीधे मॉडल भविष्यवाणी को आउटपुट करती है। कभी-कभी हम सुनिश्चित नहीं होते हैं कि मॉडल आउटपुट को उत्सर्जित करने के लिए जाली आउटपुट को फिर से बढ़ाया जाना चाहिए या नहीं:
- विशेषताएं हैं \(log\) मायने रखता है, जबकि लेबल मायने रखता है।
- जाली को बहुत कम कोने रखने के लिए कॉन्फ़िगर किया गया है लेकिन लेबल वितरण अपेक्षाकृत जटिल है।
उन मामलों में हम मॉडल लचीलेपन को बढ़ाने के लिए जाली आउटपुट और मॉडल आउटपुट के बीच एक और अंशशोधक जोड़ सकते हैं। हमारे द्वारा अभी बनाए गए मॉडल में 5 की-पॉइंट्स के साथ एक अंशशोधक परत जोड़ें। हम फ़ंक्शन को सुचारू रखने के लिए आउटपुट अंशशोधक के लिए एक नियमितकर्ता भी जोड़ते हैं।
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394


अंतिम परीक्षण मीट्रिक और प्लॉट दिखाते हैं कि कैसे सामान्य ज्ञान की बाधाओं का उपयोग करने से मॉडल को अप्रत्याशित व्यवहार से बचने और संपूर्ण इनपुट स्पेस में बेहतर तरीके से एक्सट्रपलेशन करने में मदद मिल सकती है।