
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | | |
סקירה כללית
ביקורות על סרטים מהחברה 'מסווגים זה כחיובי או שלילי באמצעות הטקסט של הביקורות. זוהי דוגמה של סיווג בינארי, כסוג חשוב החלים נרחב של בעיה בלמידה חישובית.
נדגים את השימוש בהסדרת גרפים במחברת זו על ידי בניית גרף מהקלט הנתון. המתכון הכללי לבניית מודל מוסדר גרף באמצעות מסגרת למידה מובנית עצבית (NSL) כאשר הקלט אינו מכיל גרף מפורש הוא כדלקמן:
- צור הטבעות עבור כל מדגם טקסט בקלט. ניתן לעשות זאת באמצעות מודלים מאומן מראש כגון word2vec , סיבוב , ברט וכו '
- בנו גרף על סמך הטמעות אלו על ידי שימוש במדד דמיון כגון מרחק 'L2', מרחק 'קוסינוס' וכו'. צמתים בגרף מתאימים לדגימות והקצוות בגרף תואמים לדמיון בין זוגות דגימות.
- צור נתוני אימון מהגרף המסונתז לעיל ותכונות לדוגמה. נתוני האימון שיתקבלו יכילו תכונות שכנות בנוסף לתכונות הצומת המקוריות.
- צור רשת עצבית כמודל בסיס באמצעות ה-API הרציף של Keras, פונקציונלי או תת-מחלקה.
- עטפו את מודל הבסיס עם מחלקת העטיפה GraphRegularization, שמסופקת על ידי מסגרת NSL, כדי ליצור מודל גרף חדש של Keras. מודל חדש זה יכלול אובדן הסדרת גרף כמונח ההסדרה ביעד ההכשרה שלו.
- אימון והערכת מודל Keras הגרף.
דרישות
- התקן את חבילת הלמידה המובנית העצבית.
- התקן tensorflow-hub.
pip install --quiet neural-structured-learningpip install --quiet tensorflow-hub
תלות ויבוא
import matplotlib.pyplot as plt
import numpy as np
import neural_structured_learning as nsl
import tensorflow as tf
import tensorflow_hub as hub
# Resets notebook state
tf.keras.backend.clear_session()
print("Version: ", tf.__version__)
print("Eager mode: ", tf.executing_eagerly())
print("Hub version: ", hub.__version__)
print(
"GPU is",
"available" if tf.config.list_physical_devices("GPU") else "NOT AVAILABLE")
Version: 2.8.0-rc0 Eager mode: True Hub version: 0.12.0 GPU is NOT AVAILABLE 2022-01-05 12:28:32.113752: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
מערך נתונים של IMDB
הנתונים IMDB מכיל את הטקסט של 50,000 ביקורות סרטים מן במסד הנתונים הקולנועיים . אלה מחולקים ל-25,000 ביקורות לאימון ו-25,000 ביקורות לבדיקה. מגדיר ההדרכה ובחינות מאוזנים, כלומר הם מכילים מספר שווה של ביקורות חיוביות ושליליות.
במדריך זה, נשתמש בגרסה מעובדת מראש של מערך הנתונים של IMDB.
הורד מערך נתונים IMDB מעובד מראש
מערך הנתונים של IMDB מגיע ארוז עם TensorFlow. זה כבר עבר עיבוד מוקדם כך שהביקורות (רצפי מילים) הומרו לרצפים של מספרים שלמים, כאשר כל מספר שלם מייצג מילה מסוימת במילון.
הקוד הבא מוריד את מערך הנתונים של IMDB (או משתמש בעותק שמור אם הוא כבר הורד):
imdb = tf.keras.datasets.imdb
(pp_train_data, pp_train_labels), (pp_test_data, pp_test_labels) = (
imdb.load_data(num_words=10000))
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz 17465344/17464789 [==============================] - 0s 0us/step 17473536/17464789 [==============================] - 0s 0us/step
טענת num_words=10000 שומר את המילים הנפוצות ביותר 10,000 העליונה בנתון האימון. המילים הנדירות נזרקות כדי לשמור על גודל אוצר המילים לניהול.
חקור את הנתונים
בואו ניקח רגע להבין את הפורמט של הנתונים. מערך הנתונים מגיע מעובד מראש: כל דוגמה היא מערך של מספרים שלמים המייצגים את המילים של ביקורת הסרט. כל תווית היא ערך שלם של 0 או 1, כאשר 0 היא ביקורת שלילית ו-1 היא ביקורת חיובית.
print('Training entries: {}, labels: {}'.format(
len(pp_train_data), len(pp_train_labels)))
training_samples_count = len(pp_train_data)
Training entries: 25000, labels: 25000
טקסט הביקורות הומר למספרים שלמים, כאשר כל מספר שלם מייצג מילה מסוימת במילון. כך נראית הביקורת הראשונה:
print(pp_train_data[0])
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
ביקורות סרטים עשויות להיות באורכים שונים. הקוד שלהלן מציג את מספר המילים בביקורת הראשונה והשנייה. מכיוון שכניסות לרשת עצבית חייבות להיות באותו אורך, נצטרך לפתור זאת מאוחר יותר.
len(pp_train_data[0]), len(pp_train_data[1])
(218, 189)
המר את המספרים השלמים בחזרה למילים
זה עשוי להיות שימושי לדעת כיצד להמיר מספרים שלמים בחזרה לטקסט המתאים. כאן, ניצור פונקציית מסייעת לשאילתה על אובייקט מילון המכיל את המספר השלם למיפוי מחרוזת:
def build_reverse_word_index():
# A dictionary mapping words to an integer index
word_index = imdb.get_word_index()
# The first indices are reserved
word_index = {k: (v + 3) for k, v in word_index.items()}
word_index['<PAD>'] = 0
word_index['<START>'] = 1
word_index['<UNK>'] = 2 # unknown
word_index['<UNUSED>'] = 3
return dict((value, key) for (key, value) in word_index.items())
reverse_word_index = build_reverse_word_index()
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb_word_index.json 1646592/1641221 [==============================] - 0s 0us/step 1654784/1641221 [==============================] - 0s 0us/step
עכשיו אנחנו יכולים להשתמש decode_review פונקציה להצגת טקסט עבור הבדיקה הראשונה:
decode_review(pp_train_data[0])
"<START> this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert <UNK> is an amazing actor and now the same being director <UNK> father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for <UNK> and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also <UNK> to the two little boy's that played the <UNK> of norman and paul they were just brilliant children are often left out of the <UNK> list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all"
בניית גרפים
בניית גרפים כוללת יצירת הטבעות עבור דוגמאות טקסט ולאחר מכן שימוש בפונקציית דמיון כדי להשוות בין ההטבעות.
לפני שנמשיך הלאה, תחילה אנו יוצרים ספרייה לאחסון חפצים שנוצרו על ידי מדריך זה.
mkdir -p /tmp/imdb
צור הטמעות לדוגמה
נשתמש שיבוצים סיבוב pretrained ליצור שיבוצים של tf.train.Example פורמט עבור כל דגימה בקלט. אנו מאחסנים את שיבוצים וכתוצאה מכך TFRecord בפורמט יחד עם תכונה נוספת אשר מייצג את הזהות של כל דגימה. זה חשוב ויאפשר לנו להתאים הטמעות לדוגמה עם צמתים מתאימים בגרף מאוחר יותר.
pretrained_embedding = 'https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1'
hub_layer = hub.KerasLayer(
pretrained_embedding, input_shape=[], dtype=tf.string, trainable=True)
def _int64_feature(value):
"""Returns int64 tf.train.Feature."""
return tf.train.Feature(int64_list=tf.train.Int64List(value=value.tolist()))
def _bytes_feature(value):
"""Returns bytes tf.train.Feature."""
return tf.train.Feature(
bytes_list=tf.train.BytesList(value=[value.encode('utf-8')]))
def _float_feature(value):
"""Returns float tf.train.Feature."""
return tf.train.Feature(float_list=tf.train.FloatList(value=value.tolist()))
def create_embedding_example(word_vector, record_id):
"""Create tf.Example containing the sample's embedding and its ID."""
text = decode_review(word_vector)
# Shape = [batch_size,].
sentence_embedding = hub_layer(tf.reshape(text, shape=[-1,]))
# Flatten the sentence embedding back to 1-D.
sentence_embedding = tf.reshape(sentence_embedding, shape=[-1])
features = {
'id': _bytes_feature(str(record_id)),
'embedding': _float_feature(sentence_embedding.numpy())
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_embeddings(word_vectors, output_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(output_path) as writer:
for word_vector in word_vectors:
example = create_embedding_example(word_vector, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features containing embeddings for training data in
# TFRecord format.
create_embeddings(pp_train_data, '/tmp/imdb/embeddings.tfr', 0)
25000
בנה גרף
עכשיו כשיש לנו את ההטבעות לדוגמה, נשתמש בהן כדי לבנות גרף דמיון, כלומר, צמתים בגרף זה יתאימו לדגימות וקצוות בגרף זה יתאימו לדמיון בין זוגות של צמתים.
למידה מובנית עצבית מספקת ספריית בניית גרפים לבניית גרף המבוסס על הטבעות לדוגמה. היא משתמשת דמיון קוסינוס כמדד דמיון להשוות שיבוצים וקצוות לבנות ביניהם. זה גם מאפשר לנו לציין סף דמיון, שניתן להשתמש בו כדי להשליך קצוות לא דומים מהגרף הסופי. בדוגמה זו, תוך שימוש ב-0.99 כסף הדמיון ו-12345 בתור הזרע האקראי, בסופו של דבר אנו מקבלים גרף בעל 429,415 קצוות דו-כיווניים. כאן אנו משתמשים התמיכה של בונת הגרף עבור hashing רגיש-יישוב (LSH) כדי להאיץ בניית גרף. לפרטים על שימוש תמיכת LSH של בונת הגרף, לראות את build_graph_from_config תיעוד API.
graph_builder_config = nsl.configs.GraphBuilderConfig(
similarity_threshold=0.99, lsh_splits=32, lsh_rounds=15, random_seed=12345)
nsl.tools.build_graph_from_config(['/tmp/imdb/embeddings.tfr'],
'/tmp/imdb/graph_99.tsv',
graph_builder_config)
כל קצה דו-כיווני מיוצג על ידי שני קצוות מכוונים בקובץ TSV הפלט, כך שהקובץ הזה מכיל 429,415 * 2 = 858,830 שורות בסך הכל:
wc -l /tmp/imdb/graph_99.tsv
858830 /tmp/imdb/graph_99.tsv
תכונות לדוגמה
אנו יוצרים תכונות מדגמות לבעיה שלנו באמצעות tf.train.Example הפורמט להתמיד אותם TFRecord הפורמט. כל דוגמה תכלול את שלושת התכונות הבאות:
- id: הצומת מזהה של המדגם.
- מילים: An לרשימת Int64 המכיל מזהים מילה.
- תווית: סינגלטון Int64 זיהוי כיתת היעד של הסקירה.
def create_example(word_vector, label, record_id):
"""Create tf.Example containing the sample's word vector, label, and ID."""
features = {
'id': _bytes_feature(str(record_id)),
'words': _int64_feature(np.asarray(word_vector)),
'label': _int64_feature(np.asarray([label])),
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_records(word_vectors, labels, record_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(record_path) as writer:
for word_vector, label in zip(word_vectors, labels):
example = create_example(word_vector, label, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features (word vectors and labels) for training and test
# data in TFRecord format.
next_record_id = create_records(pp_train_data, pp_train_labels,
'/tmp/imdb/train_data.tfr', 0)
create_records(pp_test_data, pp_test_labels, '/tmp/imdb/test_data.tfr',
next_record_id)
50000
הגדל את נתוני האימון עם שכני הגרף
מכיוון שיש לנו את התכונות לדוגמה ואת הגרף המסונתז, אנו יכולים ליצור את נתוני האימון המוגדלים עבור למידה מובנית עצבית. מסגרת ה-NSL מספקת ספרייה לשילוב הגרף והתכונות לדוגמה כדי לייצר את נתוני ההדרכה הסופיים להסדרת הגרפים. נתוני האימון שיתקבלו יכללו תכונות מדגמיות מקוריות וכן תכונות של שכניהם המקבילים.
במדריך זה, אנו רואים קצוות לא מכוונים ומשתמשים במקסימום 3 שכנים לכל דגימה כדי להגדיל את נתוני האימון עם שכנים גרפים.
nsl.tools.pack_nbrs(
'/tmp/imdb/train_data.tfr',
'',
'/tmp/imdb/graph_99.tsv',
'/tmp/imdb/nsl_train_data.tfr',
add_undirected_edges=True,
max_nbrs=3)
דגם בסיס
כעת אנו מוכנים לבנות מודל בסיס ללא הסדרת גרפים. על מנת לבנות מודל זה, נוכל להשתמש בהטבעות ששימשו בבניית הגרף, או שנוכל ללמוד הטמעות חדשות ביחד עם משימת הסיווג. לצורך מחברת זו, נעשה את הדבר האחרון.
משתנים גלובליים
NBR_FEATURE_PREFIX = 'NL_nbr_'
NBR_WEIGHT_SUFFIX = '_weight'
היפרפרמטרים
נשתמש מופע של HParams כדי inclue hyperparameters וקבועים שונים שימשו לאימונים והערכה. אנו מתארים בקצרה כל אחד מהם להלן:
num_classes: ישנן 2 כיתות - חיוביות ושליליות.
max_seq_length: זהו המספר המרבי של מילות נחשבות מכול ביקורת סרט בדוגמא זו.
vocab_size: זהו הגודל של אוצר המילים נחשב למשל זה.
DISTANCE_TYPE: זהו המרחק מטרי המשמש להסדרת המדגם עם שכנותיה.
graph_regularization_multiplier: זו קובעת את המשקל היחסי של המונח להסדרת גרף פונקצית ההפסד הכולל.
num_neighbors: מספר שכנים משמשים להסדרת גרף. יש ערך זה להיות קטן או שווה ל
max_nbrsהטיעון בשימוש מעל כאשר פנייתnsl.tools.pack_nbrs.num_fc_units: מספר היחידות בשכבה המחוברת המלא של הרשת העצבית.
train_epochs: מספר תקופות האימונים.
גודל יצווה שמש לאימונים והערכה: batch_size.
eval_steps: מספר אצוות כדי תהליך לפני רואה סיום בדיקה. אם מוגדר
None, כל המופעים בערכת בדיקה מוערכים.
class HParams(object):
"""Hyperparameters used for training."""
def __init__(self):
### dataset parameters
self.num_classes = 2
self.max_seq_length = 256
self.vocab_size = 10000
### neural graph learning parameters
self.distance_type = nsl.configs.DistanceType.L2
self.graph_regularization_multiplier = 0.1
self.num_neighbors = 2
### model architecture
self.num_embedding_dims = 16
self.num_lstm_dims = 64
self.num_fc_units = 64
### training parameters
self.train_epochs = 10
self.batch_size = 128
### eval parameters
self.eval_steps = None # All instances in the test set are evaluated.
HPARAMS = HParams()
הכן את הנתונים
יש להמיר את הביקורות - מערכי המספרים השלמים - לטנזורים לפני הזנה לרשת העצבית. המרה זו יכולה להתבצע בכמה דרכים:
המרת המערכים לתוך וקטורים של
0ים ו1ים המציין התרחשות מילה, בדומה קידוד חד חם. לדוגמה, את הרצף[3, 5]יהפוך10000וקטור מימדי שכולו אפסים למעט מדדי3ו5, אשר הם אלה. ואז, להפוך את זה השכבה הראשונה שלנו ברשת-ADenseשכבה-שיכול לטפל צף נתוני וקטור נקודה. גישה זו צורכת זיכרון רב, אם כי, המחייבnum_words * num_reviewsמטריקס גודל.לחלופין, אנו יכולים כרית המערכים כך שלכולם יש אותו האורך, ולאחר מכן ליצור מותח שלם של צורת
max_length * num_reviews. אנו יכולים להשתמש בשכבת הטבעה המסוגלת לטפל בצורה זו כשכבה הראשונה ברשת שלנו.
במדריך זה, נשתמש בגישה השנייה.
מאז סיקורי הסרטים חייבים להיות באותו האורך, נשתמש pad_sequence הפונקציה המוגדרת מתחת לתקנן את האורכים.
def make_dataset(file_path, training=False):
"""Creates a `tf.data.TFRecordDataset`.
Args:
file_path: Name of the file in the `.tfrecord` format containing
`tf.train.Example` objects.
training: Boolean indicating if we are in training mode.
Returns:
An instance of `tf.data.TFRecordDataset` containing the `tf.train.Example`
objects.
"""
def pad_sequence(sequence, max_seq_length):
"""Pads the input sequence (a `tf.SparseTensor`) to `max_seq_length`."""
pad_size = tf.maximum([0], max_seq_length - tf.shape(sequence)[0])
padded = tf.concat(
[sequence.values,
tf.fill((pad_size), tf.cast(0, sequence.dtype))],
axis=0)
# The input sequence may be larger than max_seq_length. Truncate down if
# necessary.
return tf.slice(padded, [0], [max_seq_length])
def parse_example(example_proto):
"""Extracts relevant fields from the `example_proto`.
Args:
example_proto: An instance of `tf.train.Example`.
Returns:
A pair whose first value is a dictionary containing relevant features
and whose second value contains the ground truth labels.
"""
# The 'words' feature is a variable length word ID vector.
feature_spec = {
'words': tf.io.VarLenFeature(tf.int64),
'label': tf.io.FixedLenFeature((), tf.int64, default_value=-1),
}
# We also extract corresponding neighbor features in a similar manner to
# the features above during training.
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
nbr_weight_key = '{}{}{}'.format(NBR_FEATURE_PREFIX, i,
NBR_WEIGHT_SUFFIX)
feature_spec[nbr_feature_key] = tf.io.VarLenFeature(tf.int64)
# We assign a default value of 0.0 for the neighbor weight so that
# graph regularization is done on samples based on their exact number
# of neighbors. In other words, non-existent neighbors are discounted.
feature_spec[nbr_weight_key] = tf.io.FixedLenFeature(
[1], tf.float32, default_value=tf.constant([0.0]))
features = tf.io.parse_single_example(example_proto, feature_spec)
# Since the 'words' feature is a variable length word vector, we pad it to a
# constant maximum length based on HPARAMS.max_seq_length
features['words'] = pad_sequence(features['words'], HPARAMS.max_seq_length)
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
features[nbr_feature_key] = pad_sequence(features[nbr_feature_key],
HPARAMS.max_seq_length)
labels = features.pop('label')
return features, labels
dataset = tf.data.TFRecordDataset([file_path])
if training:
dataset = dataset.shuffle(10000)
dataset = dataset.map(parse_example)
dataset = dataset.batch(HPARAMS.batch_size)
return dataset
train_dataset = make_dataset('/tmp/imdb/nsl_train_data.tfr', True)
test_dataset = make_dataset('/tmp/imdb/test_data.tfr')
בנה את הדגם
רשת עצבית נוצרת על ידי ערימת שכבות - זה דורש שתי החלטות ארכיטקטוניות עיקריות:
- בכמה שכבות להשתמש בדגם?
- כמה יחידות נסתרות להשתמש עבור כל שכבה?
בדוגמה זו, נתוני הקלט מורכבים ממערך של מדדי מילים. התוויות לניבוי הן 0 או 1.
אנו נשתמש ב-LSTM דו-כיווני כמודל הבסיס שלנו במדריך זה.
# This function exists as an alternative to the bi-LSTM model used in this
# notebook.
def make_feed_forward_model():
"""Builds a simple 2 layer feed forward neural network."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size, 16)(inputs)
pooling_layer = tf.keras.layers.GlobalAveragePooling1D()(embedding_layer)
dense_layer = tf.keras.layers.Dense(16, activation='relu')(pooling_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
def make_bilstm_model():
"""Builds a bi-directional LSTM model."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size,
HPARAMS.num_embedding_dims)(
inputs)
lstm_layer = tf.keras.layers.Bidirectional(
tf.keras.layers.LSTM(HPARAMS.num_lstm_dims))(
embedding_layer)
dense_layer = tf.keras.layers.Dense(
HPARAMS.num_fc_units, activation='relu')(
lstm_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
# Feel free to use an architecture of your choice.
model = make_bilstm_model()
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
words (InputLayer) [(None, 256)] 0
embedding (Embedding) (None, 256, 16) 160000
bidirectional (Bidirectiona (None, 128) 41472
l)
dense (Dense) (None, 64) 8256
dense_1 (Dense) (None, 1) 65
=================================================================
Total params: 209,793
Trainable params: 209,793
Non-trainable params: 0
_________________________________________________________________
השכבות מוערמות ביעילות ברצף כדי לבנות את המסווגן:
- הרובד הראשון הוא
Inputשכבה אשר לוקחת את אוצר המילים מקודדים-השלם. - השכבה הבאה היא
Embeddingשכבה, אשר לוקחת את אוצר המילים מקודדים-שלמות ונראה את וקטור ההטבעה לכול מילה-מדד. וקטורים אלה נלמדים כאשר המודל מתאמן. הוקטורים מוסיפים מימד למערך הפלט. הממדים וכתוצאה מכך הם:(batch, sequence, embedding). - לאחר מכן, שכבת LSTM דו-כיוונית מחזירה וקטור פלט באורך קבוע עבור כל דוגמה.
- וקטור פלט קבוע באורך זה מוזרם דרך מלאה מחוברת (
Denseשכבה) עם 64 יחידות נסתרות. - השכבה האחרונה מחוברת בצפיפות עם צומת פלט יחיד. שימוש
sigmoidפונקצית ההפעלה, ערך זה הוא לצוף בין 0 לבין 1, מייצג הסתברות, או ברמת ביטחון.
יחידות נסתרות
המודל הנ"ל יש שתיים או ביניים "חבויות" שכבות, בין הקלט והפלט, ולמעט Embedding השכבה. מספר הפלטים (יחידות, צמתים או נוירונים) הוא הממד של מרחב הייצוג של השכבה. במילים אחרות, מידת החופש שמותר לרשת בעת לימוד ייצוג פנימי.
אם למודל יש יותר יחידות נסתרות (מרחב ייצוג ממדי גבוה יותר), ו/או יותר שכבות, אז הרשת יכולה ללמוד ייצוגים מורכבים יותר. עם זאת, זה הופך את הרשת ליקרה יותר מבחינה חישובית ועלול להוביל ללימוד דפוסים לא רצויים - דפוסים המשפרים ביצועים בנתוני אימון אך לא בנתוני המבחן. זה נקרא overfitting.
פונקציית אובדן ואופטימיזציה
דגם צריך פונקציית אובדן ואופטימיזר לאימון. מכיוון שמדובר בבעיה סיווג בינארי ואת מודל תפוקות הסתברות (שכבה יחידה אחת עם הפעלת סיגמואיד), נשתמש binary_crossentropy פונקציה הפסד.
model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
צור ערכת אימות
בעת אימון, אנו רוצים לבדוק את דיוק המודל על נתונים שלא ראה בעבר. צור ערכת אימות באמצעות הגדרת בנפרד שבריר של נתוני האימון המקורי. (למה לא להשתמש בערכת הבדיקות עכשיו? המטרה שלנו היא לפתח ולכוון את המודל שלנו באמצעות נתוני האימון בלבד, ולאחר מכן להשתמש בנתוני הבדיקה רק פעם אחת כדי להעריך את הדיוק שלנו).
במדריך זה, אנו לוקחים בערך 10% מדגימות ההכשרה הראשוניות (10% מ-25,000) כנתונים מסומנים לאימון והשאר כנתוני אימות. מכיוון שחלוקת הרכבת/מבחן הראשונית הייתה 50/50 (25,000 דגימות כל אחת), חלוקת הרכבת/תיקוף/הבדיקה האפקטיבית שיש לנו כעת היא 5/45/50.
שים לב ש-'train_dataset' כבר נערך באצווה וערבב.
validation_fraction = 0.9
validation_size = int(validation_fraction *
int(training_samples_count / HPARAMS.batch_size))
print(validation_size)
validation_dataset = train_dataset.take(validation_size)
train_dataset = train_dataset.skip(validation_size)
175
אימון הדגם
אמן את הדגם במיני קבוצות. בזמן האימון, עקוב אחר אובדן המודל והדיוק בערכת האימות:
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
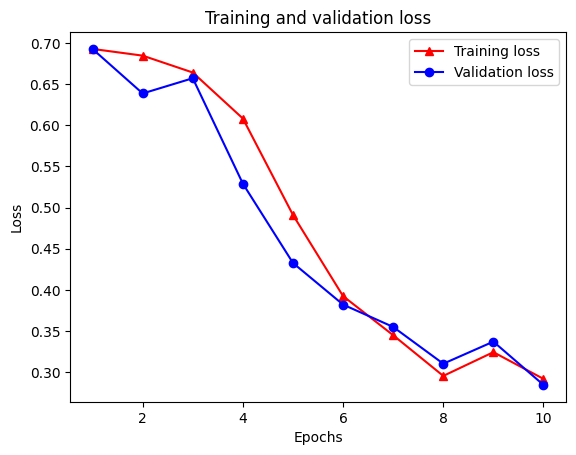
Epoch 1/10 /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/engine/functional.py:559: UserWarning: Input dict contained keys ['NL_nbr_0_words', 'NL_nbr_1_words', 'NL_nbr_0_weight', 'NL_nbr_1_weight'] which did not match any model input. They will be ignored by the model. inputs = self._flatten_to_reference_inputs(inputs) 21/21 [==============================] - 22s 889ms/step - loss: 0.6932 - accuracy: 0.5065 - val_loss: 0.6928 - val_accuracy: 0.5004 Epoch 2/10 21/21 [==============================] - 17s 841ms/step - loss: 0.6918 - accuracy: 0.5000 - val_loss: 0.6843 - val_accuracy: 0.4988 Epoch 3/10 21/21 [==============================] - 17s 839ms/step - loss: 0.6677 - accuracy: 0.5069 - val_loss: 0.5976 - val_accuracy: 0.6507 Epoch 4/10 21/21 [==============================] - 17s 836ms/step - loss: 0.5579 - accuracy: 0.6912 - val_loss: 0.4801 - val_accuracy: 0.7974 Epoch 5/10 21/21 [==============================] - 17s 837ms/step - loss: 0.4377 - accuracy: 0.7965 - val_loss: 0.3678 - val_accuracy: 0.8372 Epoch 6/10 21/21 [==============================] - 17s 836ms/step - loss: 0.3526 - accuracy: 0.8408 - val_loss: 0.4261 - val_accuracy: 0.8283 Epoch 7/10 21/21 [==============================] - 17s 835ms/step - loss: 0.4090 - accuracy: 0.8273 - val_loss: 0.3961 - val_accuracy: 0.8346 Epoch 8/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3105 - accuracy: 0.8842 - val_loss: 0.2976 - val_accuracy: 0.8813 Epoch 9/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3335 - accuracy: 0.8673 - val_loss: 0.3373 - val_accuracy: 0.8537 Epoch 10/10 21/21 [==============================] - 17s 837ms/step - loss: 0.3104 - accuracy: 0.8765 - val_loss: 0.2804 - val_accuracy: 0.8902
העריכו את המודל
עכשיו, בואו נראה איך המודל מתפקד. שני ערכים יוחזרו. הפסד (מספר המייצג את השגיאה שלנו, ערכים נמוכים יותר טובים יותר), ודיוק.
results = model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(results)
196/196 [==============================] - 16s 76ms/step - loss: 0.3695 - accuracy: 0.8389 [0.3694916367530823, 0.838919997215271]
צור גרף של דיוק/הפסד לאורך זמן
model.fit() מחזירה History אובייקט המכיל מילון עם כל מה שקרה במהלך האימון:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
ישנן ארבע ערכים: אחד לכל מדד מנוטר במהלך ההדרכה והאימות. אנו יכולים להשתמש בהם כדי לשרטט את אובדן האימון והאימות לצורך השוואה, כמו גם את דיוק ההדרכה והאימות:
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
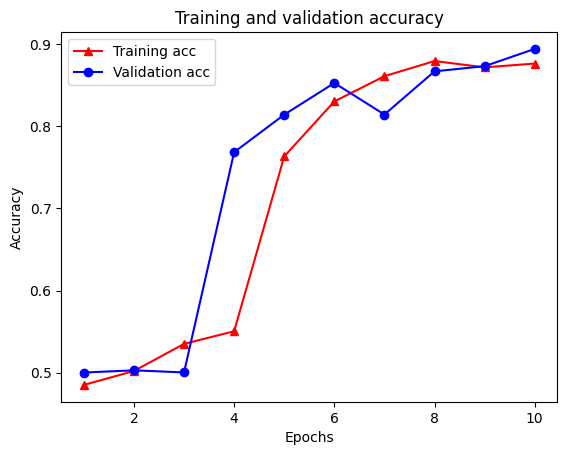
שימו לב אובדן האימון פוחתת עם כל תקופה והעליות דיוק אימון עם כל תקופה. זה צפוי בעת שימוש באופטימיזציה של ירידה בשיפוע - זה אמור למזער את הכמות הרצויה בכל איטרציה.
הסדרת גרפים
כעת אנו מוכנים לנסות הסדרת גרפים באמצעות מודל הבסיס שבנינו למעלה. נשתמש GraphRegularization מעמד המעטפת שמספק מסגרת למידת Structured העצבית לעטוף את הדגם הבסיסי (דו-LSTM) לכלול להסדרת גרף. שאר השלבים לאימון והערכת המודל המוסדר בגרף דומים לזה של מודל הבסיס.
צור מודל מוסדר בגרף
כדי להעריך את היתרון המצטבר של הסדרת גרפים, ניצור מופע מודל בסיס חדש. הסיבה לכך היא model כבר מאומן במשך כמה חזרות, ולשימוש חוזר מודל מודרך זה כדי ליצור מודל גרף-סדיר לא יהיה השוואה הוגנת עבור model .
# Build a new base LSTM model.
base_reg_model = make_bilstm_model()
# Wrap the base model with graph regularization.
graph_reg_config = nsl.configs.make_graph_reg_config(
max_neighbors=HPARAMS.num_neighbors,
multiplier=HPARAMS.graph_regularization_multiplier,
distance_type=HPARAMS.distance_type,
sum_over_axis=-1)
graph_reg_model = nsl.keras.GraphRegularization(base_reg_model,
graph_reg_config)
graph_reg_model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
אימון הדגם
graph_reg_history = graph_reg_model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
Epoch 1/10
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:446: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape_1:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape:0", shape=(None, 1), dtype=float32), dense_shape=Tensor("gradient_tape/GraphRegularization/graph_loss/Cast:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
21/21 [==============================] - 28s 1s/step - loss: 0.6928 - accuracy: 0.5131 - scaled_graph_loss: 4.3840e-05 - val_loss: 0.6923 - val_accuracy: 0.4997
Epoch 2/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6852 - accuracy: 0.5158 - scaled_graph_loss: 0.0021 - val_loss: 0.6818 - val_accuracy: 0.4996
Epoch 3/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6698 - accuracy: 0.5123 - scaled_graph_loss: 0.0021 - val_loss: 0.6534 - val_accuracy: 0.5001
Epoch 4/10
21/21 [==============================] - 20s 959ms/step - loss: 0.6194 - accuracy: 0.6285 - scaled_graph_loss: 0.0284 - val_loss: 0.5297 - val_accuracy: 0.7955
Epoch 5/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5805 - accuracy: 0.7346 - scaled_graph_loss: 0.0545 - val_loss: 0.5601 - val_accuracy: 0.6349
Epoch 6/10
21/21 [==============================] - 19s 934ms/step - loss: 0.5509 - accuracy: 0.7662 - scaled_graph_loss: 0.0654 - val_loss: 0.4899 - val_accuracy: 0.7538
Epoch 7/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5326 - accuracy: 0.7877 - scaled_graph_loss: 0.0701 - val_loss: 0.4395 - val_accuracy: 0.7923
Epoch 8/10
21/21 [==============================] - 20s 940ms/step - loss: 0.5157 - accuracy: 0.8258 - scaled_graph_loss: 0.0811 - val_loss: 0.4585 - val_accuracy: 0.7909
Epoch 9/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5063 - accuracy: 0.8388 - scaled_graph_loss: 0.0868 - val_loss: 0.4272 - val_accuracy: 0.8433
Epoch 10/10
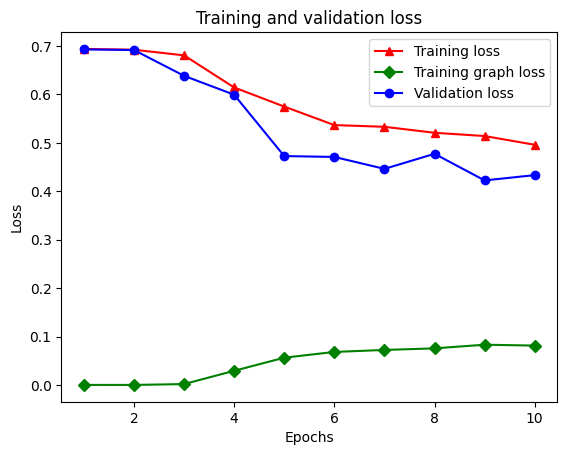
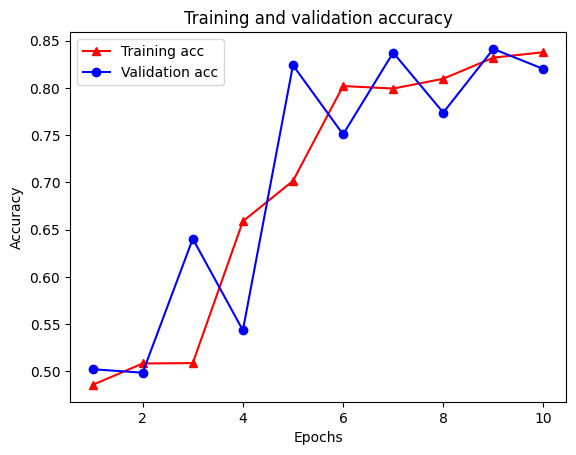
21/21 [==============================] - 19s 934ms/step - loss: 0.5053 - accuracy: 0.8438 - scaled_graph_loss: 0.0858 - val_loss: 0.4485 - val_accuracy: 0.7680
העריכו את המודל
graph_reg_results = graph_reg_model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(graph_reg_results)
196/196 [==============================] - 16s 76ms/step - loss: 0.4890 - accuracy: 0.7246 [0.4889770448207855, 0.7246000170707703]
צור גרף של דיוק/הפסד לאורך זמן
graph_reg_history_dict = graph_reg_history.history
graph_reg_history_dict.keys()
dict_keys(['loss', 'accuracy', 'scaled_graph_loss', 'val_loss', 'val_accuracy'])
ישנם חמישה ערכים בסך הכל במילון: אובדן אימון, דיוק אימון, אובדן גרף אימון, אובדן אימות ודיוק אימות. נוכל לשרטט את כולם יחד לשם השוואה. שימו לב שאובדן הגרף מחושב רק במהלך האימון.
acc = graph_reg_history_dict['accuracy']
val_acc = graph_reg_history_dict['val_accuracy']
loss = graph_reg_history_dict['loss']
graph_loss = graph_reg_history_dict['scaled_graph_loss']
val_loss = graph_reg_history_dict['val_loss']
epochs = range(1, len(acc) + 1)
plt.clf() # clear figure
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-gD" is for solid green line with diamond markers.
plt.plot(epochs, graph_loss, '-gD', label='Training graph loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
כוחה של למידה מפוקחת למחצה
למידה מפוקחת למחצה וליתר דיוק, הסדרת גרפים בהקשר של מדריך זה, יכולה להיות חזקה מאוד כאשר כמות נתוני האימון קטנה. המחסור בנתוני הכשרה מפוצה על ידי מינוף דמיון בין מדגמי ההכשרה, דבר שאינו אפשרי בלמידה מפוקחת מסורתית.
אנו מגדירים יחס פיקוח כיחס של אימון דגימות למספר הכולל של דגימות הכולל הכשרה, אימות, ולבדוק דגימות. במחברת זו, השתמשנו ביחס פיקוח של 0.05 (כלומר, 5% מהנתונים המסומנים) להדרכה הן את המודל הבסיסי והן את המודל המוסדר בגרף. אנו מדגים את ההשפעה של יחס הפיקוח על דיוק המודל בתא למטה.
# Accuracy values for both the Bi-LSTM model and the feed forward NN model have
# been precomputed for the following supervision ratios.
supervision_ratios = [0.3, 0.15, 0.05, 0.03, 0.02, 0.01, 0.005]
model_tags = ['Bi-LSTM model', 'Feed Forward NN model']
base_model_accs = [[84, 84, 83, 80, 65, 52, 50], [87, 86, 76, 74, 67, 52, 51]]
graph_reg_model_accs = [[84, 84, 83, 83, 65, 63, 50],
[87, 86, 80, 75, 67, 52, 50]]
plt.clf() # clear figure
fig, axes = plt.subplots(1, 2)
fig.set_size_inches((12, 5))
for ax, model_tag, base_model_acc, graph_reg_model_acc in zip(
axes, model_tags, base_model_accs, graph_reg_model_accs):
# "-r^" is for solid red line with triangle markers.
ax.plot(base_model_acc, '-r^', label='Base model')
# "-gD" is for solid green line with diamond markers.
ax.plot(graph_reg_model_acc, '-gD', label='Graph-regularized model')
ax.set_title(model_tag)
ax.set_xlabel('Supervision ratio')
ax.set_ylabel('Accuracy(%)')
ax.set_ylim((25, 100))
ax.set_xticks(range(len(supervision_ratios)))
ax.set_xticklabels(supervision_ratios)
ax.legend(loc='best')
plt.show()
<Figure size 432x288 with 0 Axes>
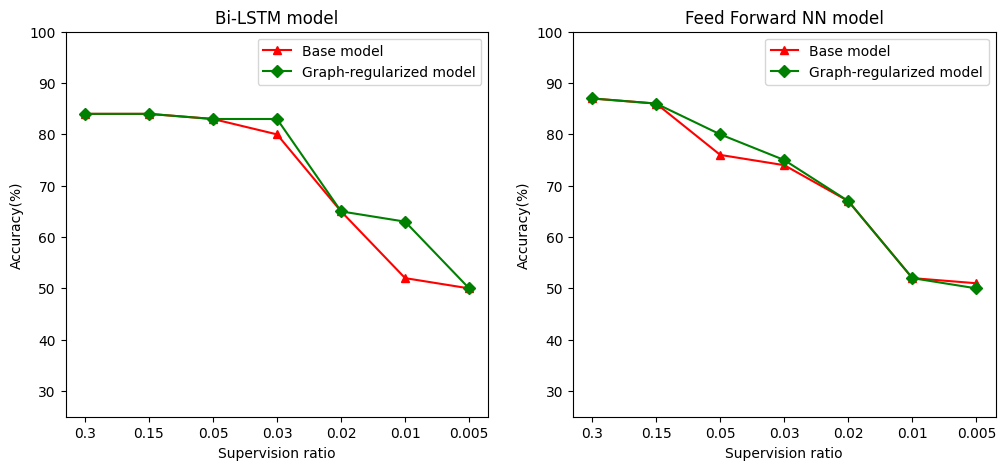
ניתן לראות שככל שיחס הפיקוח יורד, גם דיוק המודל יורד. זה נכון הן עבור המודל הבסיסי והן עבור המודל המוסדר בגרף, ללא קשר לארכיטקטורת המודל שבה נעשה שימוש. עם זאת, שימו לב שהמודל המוסדר בגרף מתפקד טוב יותר מהמודל הבסיסי עבור שתי הארכיטקטורות. בפרט, עבור דגם Bi-LSTM, כאשר יחס הפיקוח הוא 0.01, את הדיוק של המודל-הסדירה הגרף הוא \ 20% גבוהים יותר מזה של הדגם הבסיסי. זה בעיקר בגלל למידה מפוקחת למחצה עבור המודל המוסדר בגרף, שבו נעשה שימוש בדמיון מבני בין דגימות אימון בנוסף לדגימות האימון עצמן.
סיכום
הדגמנו את השימוש בהסדרת גרפים באמצעות המסגרת של למידה מובנית עצבית (NSL) גם כאשר הקלט אינו מכיל גרף מפורש. שקלנו את המשימה של סיווג סנטימנטים של ביקורות סרטים ב-IMDB שלגביה סינתזנו גרף דמיון המבוסס על הטבעות ביקורת. אנו ממליצים למשתמשים להתנסות נוספת על ידי שינוי הפרמטרים של היפר, כמות הפיקוח ועל ידי שימוש בארכיטקטורות מודל שונות.