
| | |  Visualizza l'origine su GitHub Visualizza l'origine su GitHub | |
I modelli a variabili latenti tentano di catturare la struttura nascosta in dati ad alta dimensione. Gli esempi includono l'analisi dei componenti principali (PCA) e l'analisi fattoriale. I processi gaussiani sono modelli "non parametrici" che possono catturare in modo flessibile la struttura di correlazione locale e l'incertezza. Il processo gaussiano latente modello variabile ( Lawrence, 2004 ) combina questi concetti.
Contesto: processi gaussiani
Un processo gaussiano è un insieme di variabili casuali tale che la distribuzione marginale su qualsiasi sottoinsieme finito è una distribuzione normale multivariata. Per uno sguardo dettagliato a medici nel contesto della regressione, controlla gaussiana regressione del processo in tensorflow Probabilità .
Usiamo un cosiddetto insieme degli indici di etichettare ciascuna delle variabili casuali nell'insieme che i GP comprende. Nel caso di un insieme di indici finiti, otteniamo solo una normale multivariata. GP di sono più interessanti, però, quando si considerano le collezioni infinite. Nel caso di insiemi indice come \(\mathbb{R}^D\), dove abbiamo una variabile casuale per ogni punto \(D\)spazio dimensionale, il medico può essere pensato come una distribuzione su funzioni casuali. Un solo pareggio da una tale GP, se potesse essere realizzata, sarebbe assegnare un valore (congiuntamente normalmente distribuito) per ogni punto in \(\mathbb{R}^D\). In questo CoLab, ci concentreremo su GP di sopra un certo\(\mathbb{R}^D\).
Le distribuzioni normali sono completamente determinate dalle loro statistiche di primo e secondo ordine: in effetti, un modo per definire la distribuzione normale è quello i cui cumulanti di ordine superiore sono tutti zero. Questo è il caso per il GP di troppo: abbiamo completamente specifichiamo un GP descrivendo il * media e covarianza. Ricordiamo che per le normali multivariate di dimensione finita, la media è un vettore e la covarianza è una matrice quadrata simmetrica definita positiva. Nel GP infinito-dimensionale, queste strutture generalizzano ad una funzione medio \(m : \mathbb{R}^D \to \mathbb{R}\), definita in ogni punto di indici, e una funzione di covarianza "kernel",\(k : \mathbb{R}^D \times \mathbb{R}^D \to \mathbb{R}\). La funzione kernel è richiesto di essere definita positiva , che dice in sostanza che, limitato a un insieme finito di punti, produce una matrice postiive-definite.
La maggior parte della struttura di un GP deriva dalla sua funzione kernel di covarianza: questa funzione descrive come i valori delle funzioni campione variano tra punti vicini (o non così vicini). Diverse funzioni di covarianza incoraggiano diversi gradi di levigatezza. Una funzione kernel comunemente utilizzato è quello "a potenza quadratica" (ovvero, "gaussiana", "quadrato esponenziale" o "funzione a base radiale"), \(k(x, x') = \sigma^2 e^{(x - x^2) / \lambda^2}\). Altri esempi sono riportate a David Duvenaud pagina kernel libro di cucina , così come nel testo canonico processi gaussiani per l'apprendimento automatico .
* Con un insieme di indici infinito, richiediamo anche una condizione di consistenza. Poiché la definizione del GP è in termini di marginali finiti, dobbiamo richiedere che questi marginali siano coerenti indipendentemente dall'ordine in cui vengono presi i marginali. Questo è un argomento piuttosto avanzato nella teoria dei processi stocastici, fuori dallo scopo di questo tutorial; basti dire che alla fine le cose vanno bene!
Applicazione di GP: modelli di regressione e variabili latenti
Un modo possiamo usare GP è per la regressione: dato un mazzo di dati osservati sotto forma di ingressi \(\{x_i\}_{i=1}^N\) (elementi di indici) e osservazioni\(\{y_i\}_{i=1}^N\), possiamo usare questi per formare una distribuzione predittiva posteriori ad una nuova serie di punti di \(\{x_j^*\}_{j=1}^M\). Dal momento che le distribuzioni sono tutti gaussiana, questo si riduce a qualche algebra lineare semplice (ma nota: i calcoli necessari hanno runtime cubica del numero di punti di dati e richiedono spazio quadratica del numero di punti dati - questo è un importante fattore limitante l'uso di medici generici e molte ricerche attuali si concentrano su alternative computazionalmente praticabili all'esatta inferenza a posteriori). Copriamo GP di regressione in modo più dettagliato nel GP di regressione della PTF CoLab .
Un altro modo in cui possiamo usare i GP è come modello di variabile latente: data una raccolta di osservazioni ad alta dimensione (ad es. immagini), possiamo postulare una struttura latente a bassa dimensione. Assumiamo che, in base alla struttura latente, il gran numero di output (pixel nell'immagine) siano indipendenti l'uno dall'altro. La formazione in questo modello consiste in
- ottimizzazione dei parametri del modello (parametri della funzione del kernel e, ad esempio, la variazione del rumore di osservazione), e
- trovare, per ogni osservazione di addestramento (immagine), una posizione di punto corrispondente nell'insieme di indici. Tutta l'ottimizzazione può essere eseguita massimizzando la probabilità logaritmica marginale dei dati.
Importazioni
import numpy as np
import tensorflow.compat.v2 as tf
tf.enable_v2_behavior()
import tensorflow_probability as tfp
tfd = tfp.distributions
tfk = tfp.math.psd_kernels
%pylab inline
Populating the interactive namespace from numpy and matplotlib
Carica dati MNIST
# Load the MNIST data set and isolate a subset of it.
(x_train, y_train), (_, _) = tf.keras.datasets.mnist.load_data()
N = 1000
small_x_train = x_train[:N, ...].astype(np.float64) / 256.
small_y_train = y_train[:N]
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11493376/11490434 [==============================] - 0s 0us/step 11501568/11490434 [==============================] - 0s 0us/step
Preparare variabili addestrabili
Addestreremo insieme 3 parametri del modello e gli input latenti.
# Create some trainable model parameters. We will constrain them to be strictly
# positive when constructing the kernel and the GP.
unconstrained_amplitude = tf.Variable(np.float64(1.), name='amplitude')
unconstrained_length_scale = tf.Variable(np.float64(1.), name='length_scale')
unconstrained_observation_noise = tf.Variable(np.float64(1.), name='observation_noise')
# We need to flatten the images and, somewhat unintuitively, transpose from
# shape [100, 784] to [784, 100]. This is because the 784 pixels will be
# treated as *independent* conditioned on the latent inputs, meaning we really
# have a batch of 784 GP's with 100 index_points.
observations_ = small_x_train.reshape(N, -1).transpose()
# Create a collection of N 2-dimensional index points that will represent our
# latent embeddings of the data. (Lawrence, 2004) prescribes initializing these
# with PCA, but a random initialization actually gives not-too-bad results, so
# we use this for simplicity. For a fun exercise, try doing the
# PCA-initialization yourself!
init_ = np.random.normal(size=(N, 2))
latent_index_points = tf.Variable(init_, name='latent_index_points')
Costruisci il modello e le operazioni di addestramento
# Create our kernel and GP distribution
EPS = np.finfo(np.float64).eps
def create_kernel():
amplitude = tf.math.softplus(EPS + unconstrained_amplitude)
length_scale = tf.math.softplus(EPS + unconstrained_length_scale)
kernel = tfk.ExponentiatedQuadratic(amplitude, length_scale)
return kernel
def loss_fn():
observation_noise_variance = tf.math.softplus(
EPS + unconstrained_observation_noise)
gp = tfd.GaussianProcess(
kernel=create_kernel(),
index_points=latent_index_points,
observation_noise_variance=observation_noise_variance)
log_probs = gp.log_prob(observations_, name='log_prob')
return -tf.reduce_mean(log_probs)
trainable_variables = [unconstrained_amplitude,
unconstrained_length_scale,
unconstrained_observation_noise,
latent_index_points]
optimizer = tf.optimizers.Adam(learning_rate=1.0)
@tf.function(autograph=False, jit_compile=True)
def train_model():
with tf.GradientTape() as tape:
loss_value = loss_fn()
grads = tape.gradient(loss_value, trainable_variables)
optimizer.apply_gradients(zip(grads, trainable_variables))
return loss_value
Addestrare e tracciare gli incorporamenti latenti risultanti
# Initialize variables and train!
num_iters = 100
log_interval = 20
lips = np.zeros((num_iters, N, 2), np.float64)
for i in range(num_iters):
loss = train_model()
lips[i] = latent_index_points.numpy()
if i % log_interval == 0 or i + 1 == num_iters:
print("Loss at step %d: %f" % (i, loss))
Loss at step 0: 1108.121688 Loss at step 20: -159.633761 Loss at step 40: -263.014394 Loss at step 60: -283.713056 Loss at step 80: -288.709413 Loss at step 99: -289.662253
Risultati della trama
# Plot the latent locations before and after training
plt.figure(figsize=(7, 7))
plt.title("Before training")
plt.grid(False)
plt.scatter(x=init_[:, 0], y=init_[:, 1],
c=y_train[:N], cmap=plt.get_cmap('Paired'), s=50)
plt.show()
plt.figure(figsize=(7, 7))
plt.title("After training")
plt.grid(False)
plt.scatter(x=lips[-1, :, 0], y=lips[-1, :, 1],
c=y_train[:N], cmap=plt.get_cmap('Paired'), s=50)
plt.show()
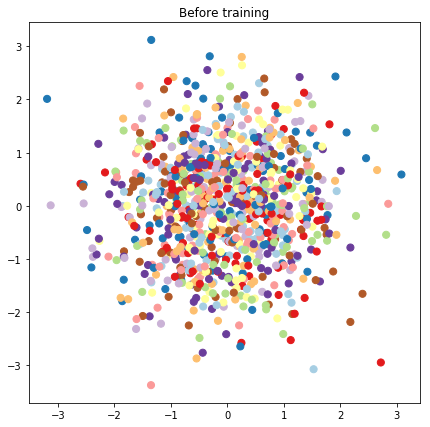
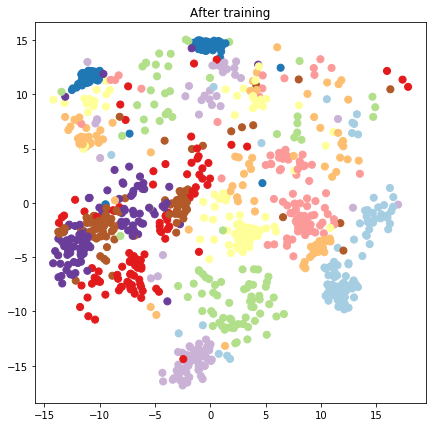
Costruire un modello predittivo e operazioni di campionamento
# We'll draw samples at evenly spaced points on a 10x10 grid in the latent
# input space.
sample_grid_points = 10
grid_ = np.linspace(-4, 4, sample_grid_points).astype(np.float64)
# Create a 10x10 grid of 2-vectors, for a total shape [10, 10, 2]
grid_ = np.stack(np.meshgrid(grid_, grid_), axis=-1)
# This part's a bit subtle! What we defined above was a batch of 784 (=28x28)
# independent GP distributions over the input space. Each one corresponds to a
# single pixel of an MNIST image. Now what we'd like to do is draw 100 (=10x10)
# *independent* samples, each one separately conditioned on all the observations
# as well as the learned latent input locations above.
#
# The GP regression model below will define a batch of 784 independent
# posteriors. We'd like to get 100 independent samples each at a different
# latent index point. We could loop over the points in the grid, but that might
# be a bit slow. Instead, we can vectorize the computation by tacking on *even
# more* batch dimensions to our GaussianProcessRegressionModel distribution.
# In the below grid_ shape, we have concatentaed
# 1. batch shape: [sample_grid_points, sample_grid_points, 1]
# 2. number of examples: [1]
# 3. number of latent input dimensions: [2]
# The `1` in the batch shape will broadcast with 784. The final result will be
# samples of shape [10, 10, 784, 1]. The `1` comes from the "number of examples"
# and we can just `np.squeeze` it off.
grid_ = grid_.reshape(sample_grid_points, sample_grid_points, 1, 1, 2)
# Create the GPRegressionModel instance which represents the posterior
# predictive at the grid of new points.
gprm = tfd.GaussianProcessRegressionModel(
kernel=create_kernel(),
# Shape [10, 10, 1, 1, 2]
index_points=grid_,
# Shape [1000, 2]. 1000 2 dimensional vectors.
observation_index_points=latent_index_points,
# Shape [784, 1000]. A batch of 784 1000-dimensional observations.
observations=observations_)
Disegna campioni condizionati dai dati e incorporamenti latenti
Campioniamo a 100 punti su una griglia 2-d nello spazio latente.
samples = gprm.sample()
# Plot the grid of samples at new points. We do a bit of tweaking of the samples
# first, squeezing off extra 1-shapes and normalizing the values.
samples_ = np.squeeze(samples.numpy())
samples_ = ((samples_ -
samples_.min(-1, keepdims=True)) /
(samples_.max(-1, keepdims=True) -
samples_.min(-1, keepdims=True)))
samples_ = samples_.reshape(sample_grid_points, sample_grid_points, 28, 28)
samples_ = samples_.transpose([0, 2, 1, 3])
samples_ = samples_.reshape(28 * sample_grid_points, 28 * sample_grid_points)
plt.figure(figsize=(7, 7))
ax = plt.subplot()
ax.grid(False)
ax.imshow(-samples_, interpolation='none', cmap='Greys')
plt.show()

Conclusione
Abbiamo fatto un breve tour del modello variabile latente di processo gaussiano e mostrato come possiamo implementarlo in poche righe di codice TF e TF Probability.