
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
Olasılık temel bileşenler analizi (PCA) bir alt boyutlu gizli boşluk yoluyla verileri analiz bir boyut indirgeme tekniğidir ( Devirme Bishop 1999 ). Genellikle verilerde eksik değerler olduğunda veya çok boyutlu ölçekleme için kullanılır.
ithalat
import functools
import warnings
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import tensorflow.compat.v2 as tf
import tensorflow_probability as tfp
from tensorflow_probability import bijectors as tfb
from tensorflow_probability import distributions as tfd
tf.enable_v2_behavior()
plt.style.use("ggplot")
warnings.filterwarnings('ignore')
Model
Bir veri seti düşünün \(\mathbf{X} = \{\mathbf{x}_n\}\) arasında \(N\) her bir veri noktası olan veri noktaları, \(D\)boyutlu, $ \ mathbf {x} _n \ in \ mathbb {R} ^ D\(. We aim to represent each \)\ mathbf {x} _n bir latent değişken altında $ \(\mathbf{z}_n \in \mathbb{R}^K\) düşük bir boyuta sahip, $ K <D\(. The set of principal axes \)\ mathbf {B} $ verilerine gizli değişkenler ile ilgilidir.
Spesifik olarak, her bir gizli değişkenin normal dağıldığını varsayıyoruz,
\[ \begin{equation*} \mathbf{z}_n \sim N(\mathbf{0}, \mathbf{I}). \end{equation*} \]
Karşılık gelen veri noktası bir projeksiyon yoluyla oluşturulur,
\[ \begin{equation*} \mathbf{x}_n \mid \mathbf{z}_n \sim N(\mathbf{W}\mathbf{z}_n, \sigma^2\mathbf{I}), \end{equation*} \]
burada matris \(\mathbf{W}\in\mathbb{R}^{D\times K}\) ana eksen olarak da bilinir. Olasılık PCA, biz genellikle ana eksenleri tahmin ilgilenen edilir \(\mathbf{W}\) ve gürültü terimi\(\sigma^2\).
Olasılıksal PCA, klasik PCA'yı genelleştirir. Gizli değişkeni marjinalleştirerek, her veri noktasının dağılımı
\[ \begin{equation*} \mathbf{x}_n \sim N(\mathbf{0}, \mathbf{W}\mathbf{W}^\top + \sigma^2\mathbf{I}). \end{equation*} \]
Gürültü kovaryans sonsuz küçüklükteki, olduğunda Klasik PCA olasılık PCA özgül durumda \(\sigma^2 \to 0\).
Aşağıdaki modelimizi kurduk. Bizim analizde, biz varsayalım \(\sigma\) bilinir ve bunun yerine tahmin noktasının \(\mathbf{W}\) bir modeli parametresi olarak, biz ana eksen üzerinde dağılımını anlamak amacıyla üzerine bir önceki yerleştirin. Özellikle, biz kullanacağız, bir TFP JointDistribution olarak modelini ifade edeceğiz JointDistributionCoroutineAutoBatched .
def probabilistic_pca(data_dim, latent_dim, num_datapoints, stddv_datapoints):
w = yield tfd.Normal(loc=tf.zeros([data_dim, latent_dim]),
scale=2.0 * tf.ones([data_dim, latent_dim]),
name="w")
z = yield tfd.Normal(loc=tf.zeros([latent_dim, num_datapoints]),
scale=tf.ones([latent_dim, num_datapoints]),
name="z")
x = yield tfd.Normal(loc=tf.matmul(w, z),
scale=stddv_datapoints,
name="x")
num_datapoints = 5000
data_dim = 2
latent_dim = 1
stddv_datapoints = 0.5
concrete_ppca_model = functools.partial(probabilistic_pca,
data_dim=data_dim,
latent_dim=latent_dim,
num_datapoints=num_datapoints,
stddv_datapoints=stddv_datapoints)
model = tfd.JointDistributionCoroutineAutoBatched(concrete_ppca_model)
Veri
Modeli, ortak ön dağılımdan örnekleyerek veri üretmek için kullanabiliriz.
actual_w, actual_z, x_train = model.sample()
print("Principal axes:")
print(actual_w)
Principal axes: tf.Tensor( [[ 2.2801023] [-1.1619819]], shape=(2, 1), dtype=float32)
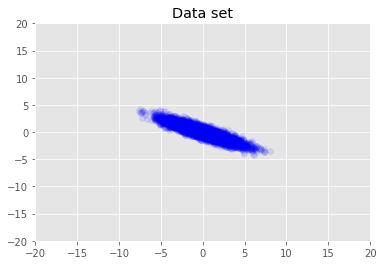
Veri setini görselleştiriyoruz.
plt.scatter(x_train[0, :], x_train[1, :], color='blue', alpha=0.1)
plt.axis([-20, 20, -20, 20])
plt.title("Data set")
plt.show()
Maksimum Arka Çıkarım
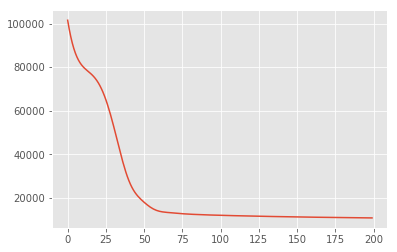
İlk önce, sonsal olasılık yoğunluğunu maksimize eden gizli değişkenlerin nokta tahminini ararız. Bu maksimum olarak a posteriori (MAP) çıkarsama bilinmektedir ve değerlerinin hesaplanması yapılır \(\mathbf{W}\) ve \(\mathbf{Z}\) arka yoğunluğu en üst düzeye çıkarmak \(p(\mathbf{W}, \mathbf{Z} \mid \mathbf{X}) \propto p(\mathbf{W}, \mathbf{Z}, \mathbf{X})\).
w = tf.Variable(tf.random.normal([data_dim, latent_dim]))
z = tf.Variable(tf.random.normal([latent_dim, num_datapoints]))
target_log_prob_fn = lambda w, z: model.log_prob((w, z, x_train))
losses = tfp.math.minimize(
lambda: -target_log_prob_fn(w, z),
optimizer=tf.optimizers.Adam(learning_rate=0.05),
num_steps=200)
plt.plot(losses)
[<matplotlib.lines.Line2D at 0x7f19897a42e8>]
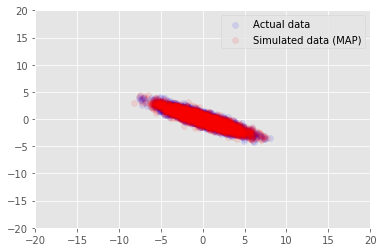
Biz bilgilerin tahmin değerleri için örnek verilerine modeli kullanabilirsiniz \(\mathbf{W}\) ve \(\mathbf{Z}\)ve biz koşuluna gerçek veri kümesine karşılaştırın.
print("MAP-estimated axes:")
print(w)
_, _, x_generated = model.sample(value=(w, z, None))
plt.scatter(x_train[0, :], x_train[1, :], color='blue', alpha=0.1, label='Actual data')
plt.scatter(x_generated[0, :], x_generated[1, :], color='red', alpha=0.1, label='Simulated data (MAP)')
plt.legend()
plt.axis([-20, 20, -20, 20])
plt.show()
MAP-estimated axes:
<tf.Variable 'Variable:0' shape=(2, 1) dtype=float32, numpy=
array([[ 2.9135954],
[-1.4826864]], dtype=float32)>
Varyasyon çıkarımı
MAP, sonsal dağılımın modunu (veya modlardan birini) bulmak için kullanılabilir, ancak bununla ilgili başka bir bilgi sağlamaz. Önümüzdeki arka distribtion varyasyon parazitine kullanmak \(p(\mathbf{W}, \mathbf{Z} \mid \mathbf{X})\) bir varyasyon dağıtım kullanılarak yaklaşılır \(q(\mathbf{W}, \mathbf{Z})\) tarafından parametrize \(\boldsymbol{\lambda}\). Amaç varyasyon parametreler bulmaktır \(\boldsymbol{\lambda}\) q ve posterior arasında KL ayrışmayı en aza o \(\mathrm{KL}(q(\mathbf{W}, \mathbf{Z}) \mid\mid p(\mathbf{W}, \mathbf{Z} \mid \mathbf{X}))\)alt bağlı delilleri maksimize eşdeğer veya \(\mathbb{E}_{q(\mathbf{W},\mathbf{Z};\boldsymbol{\lambda})}\left[ \log p(\mathbf{W},\mathbf{Z},\mathbf{X}) - \log q(\mathbf{W},\mathbf{Z}; \boldsymbol{\lambda}) \right]\).
qw_mean = tf.Variable(tf.random.normal([data_dim, latent_dim]))
qz_mean = tf.Variable(tf.random.normal([latent_dim, num_datapoints]))
qw_stddv = tfp.util.TransformedVariable(1e-4 * tf.ones([data_dim, latent_dim]),
bijector=tfb.Softplus())
qz_stddv = tfp.util.TransformedVariable(
1e-4 * tf.ones([latent_dim, num_datapoints]),
bijector=tfb.Softplus())
def factored_normal_variational_model():
qw = yield tfd.Normal(loc=qw_mean, scale=qw_stddv, name="qw")
qz = yield tfd.Normal(loc=qz_mean, scale=qz_stddv, name="qz")
surrogate_posterior = tfd.JointDistributionCoroutineAutoBatched(
factored_normal_variational_model)
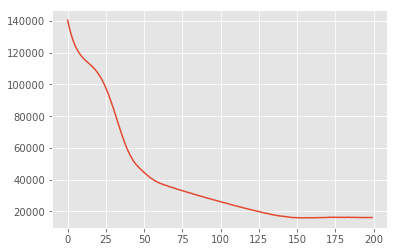
losses = tfp.vi.fit_surrogate_posterior(
target_log_prob_fn,
surrogate_posterior=surrogate_posterior,
optimizer=tf.optimizers.Adam(learning_rate=0.05),
num_steps=200)
print("Inferred axes:")
print(qw_mean)
print("Standard Deviation:")
print(qw_stddv)
plt.plot(losses)
plt.show()
Inferred axes:
<tf.Variable 'Variable:0' shape=(2, 1) dtype=float32, numpy=
array([[ 2.4168603],
[-1.2236133]], dtype=float32)>
Standard Deviation:
<TransformedVariable: dtype=float32, shape=[2, 1], fn="softplus", numpy=
array([[0.0042499 ],
[0.00598824]], dtype=float32)>
posterior_samples = surrogate_posterior.sample(50)
_, _, x_generated = model.sample(value=(posterior_samples))
# It's a pain to plot all 5000 points for each of our 50 posterior samples, so
# let's subsample to get the gist of the distribution.
x_generated = tf.reshape(tf.transpose(x_generated, [1, 0, 2]), (2, -1))[:, ::47]
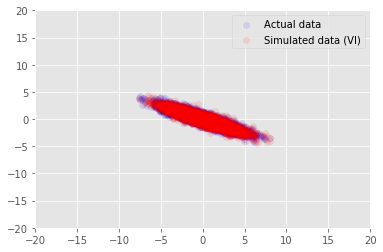
plt.scatter(x_train[0, :], x_train[1, :], color='blue', alpha=0.1, label='Actual data')
plt.scatter(x_generated[0, :], x_generated[1, :], color='red', alpha=0.1, label='Simulated data (VI)')
plt.legend()
plt.axis([-20, 20, -20, 20])
plt.show()
Teşekkür
Bu eğitimde başlangıçta Edward 1,0 (yazılmış kaynak ). Bu sürümü yazmaya ve revize etmeye katkıda bulunan herkese teşekkür ederiz.
Referanslar
[1]: Michael E. Bahşiş ve Christopher M. Bishop. Olasılıksal temel bileşen analizi. Kraliyet İstatistik Derneği Dergisi: Seri B (İstatistiksel Metodolojisi), 61 (3): 611-622, 1999.