
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
В этом примере вы изучите результат McClean, 2019 , в котором говорится, что не любая структура квантовой нейронной сети хорошо справляется с обучением. В частности, вы увидите, что определенное большое семейство случайных квантовых цепей не может служить хорошими квантовыми нейронными сетями, потому что они имеют градиенты, которые исчезают почти везде. В этом примере вы не будете обучать какие-либо модели для конкретной задачи обучения, а вместо этого сосредоточитесь на более простой проблеме понимания поведения градиентов.
Настраивать
pip install tensorflow==2.7.0
Установите TensorFlow Quantum:
pip install tensorflow-quantum
# Update package resources to account for version changes.
import importlib, pkg_resources
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
Теперь импортируйте TensorFlow и зависимости модуля:
import tensorflow as tf
import tensorflow_quantum as tfq
import cirq
import sympy
import numpy as np
# visualization tools
%matplotlib inline
import matplotlib.pyplot as plt
from cirq.contrib.svg import SVGCircuit
np.random.seed(1234)
2022-02-04 12:15:43.355568: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
1. Резюме
Случайные квантовые схемы с множеством блоков, которые выглядят так (\(R_{P}(\theta)\) — случайное вращение Паули):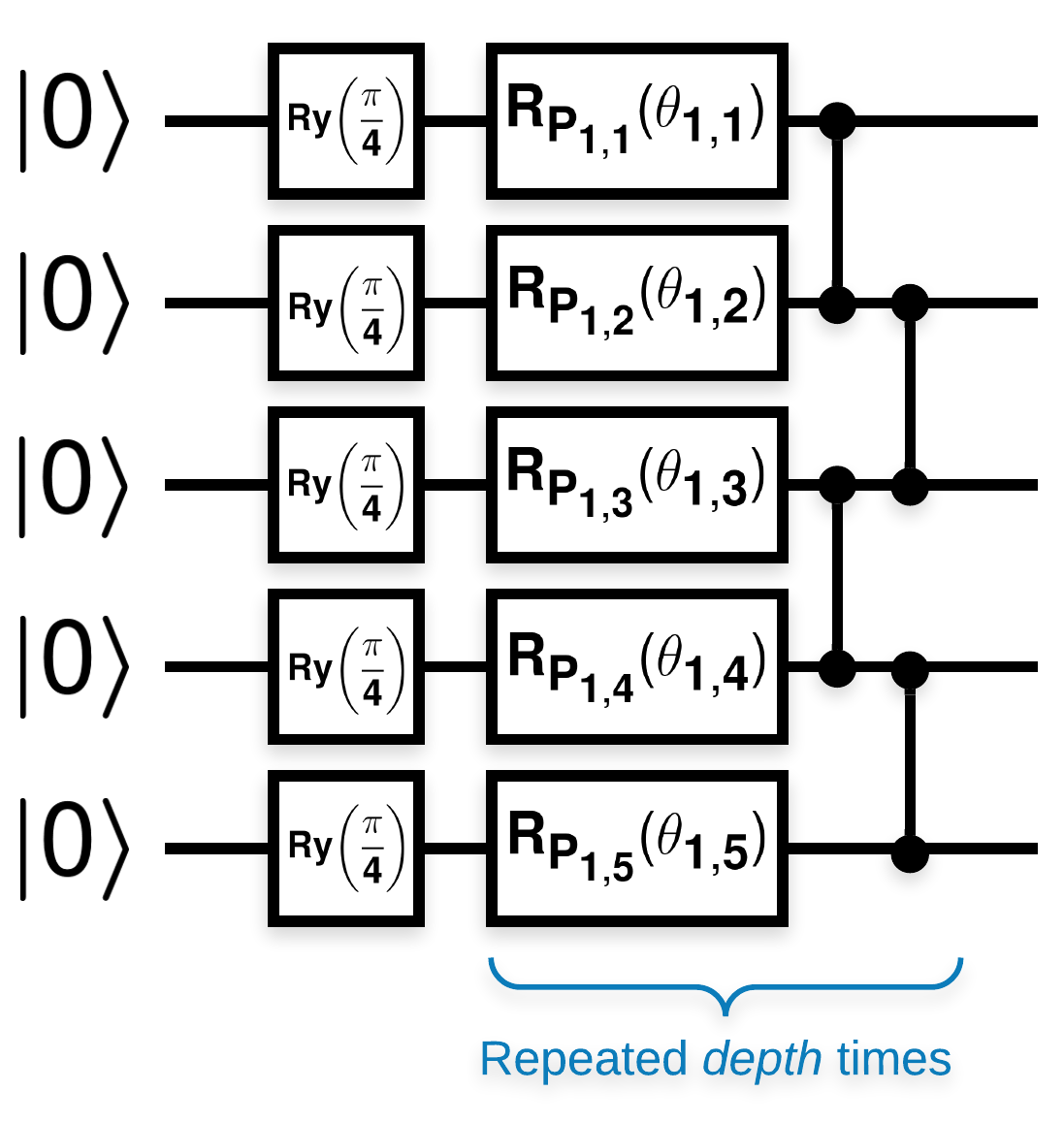
Где, если \(f(x)\) определяется как ожидаемое значение относительно \(Z_{a}Z_{b}\) для любых кубитов \(a\) и \(b\), тогда возникает проблема, что \(f'(x)\) имеет среднее значение, очень близкое к 0, и сильно не меняется. Вы увидите это ниже:
2. Генерация случайных цепей
Построение из бумаги простое. В следующем примере реализована простая функция, которая генерирует случайную квантовую схему — иногда называемую квантовой нейронной сетью (QNN) — с заданной глубиной на наборе кубитов:
def generate_random_qnn(qubits, symbol, depth):
"""Generate random QNN's with the same structure from McClean et al."""
circuit = cirq.Circuit()
for qubit in qubits:
circuit += cirq.ry(np.pi / 4.0)(qubit)
for d in range(depth):
# Add a series of single qubit rotations.
for i, qubit in enumerate(qubits):
random_n = np.random.uniform()
random_rot = np.random.uniform(
) * 2.0 * np.pi if i != 0 or d != 0 else symbol
if random_n > 2. / 3.:
# Add a Z.
circuit += cirq.rz(random_rot)(qubit)
elif random_n > 1. / 3.:
# Add a Y.
circuit += cirq.ry(random_rot)(qubit)
else:
# Add a X.
circuit += cirq.rx(random_rot)(qubit)
# Add CZ ladder.
for src, dest in zip(qubits, qubits[1:]):
circuit += cirq.CZ(src, dest)
return circuit
generate_random_qnn(cirq.GridQubit.rect(1, 3), sympy.Symbol('theta'), 2)
Авторы исследуют градиент одного параметра \(\theta_{1,1}\). Давайте продолжим, поместив sympy.Symbol в схему, где будет \(\theta_{1,1}\) . Поскольку авторы не анализируют статистику для каких-либо других символов в схеме, давайте заменим их случайными значениями сейчас, а не позже.
3. Запуск цепей
Сгенерируйте несколько таких схем вместе с наблюдаемой, чтобы проверить утверждение о том, что градиенты не сильно различаются. Во-первых, сгенерируйте пакет случайных цепей. Выберите случайную наблюдаемую ZZ и пакетно рассчитайте градиенты и дисперсию с помощью TensorFlow Quantum.
3.1 Вычисление отклонения партии
Давайте напишем вспомогательную функцию, которая вычисляет дисперсию градиента данной наблюдаемой по пакету схем:
def process_batch(circuits, symbol, op):
"""Compute the variance of a batch of expectations w.r.t. op on each circuit that
contains `symbol`. Note that this method sets up a new compute graph every time it is
called so it isn't as performant as possible."""
# Setup a simple layer to batch compute the expectation gradients.
expectation = tfq.layers.Expectation()
# Prep the inputs as tensors
circuit_tensor = tfq.convert_to_tensor(circuits)
values_tensor = tf.convert_to_tensor(
np.random.uniform(0, 2 * np.pi, (n_circuits, 1)).astype(np.float32))
# Use TensorFlow GradientTape to track gradients.
with tf.GradientTape() as g:
g.watch(values_tensor)
forward = expectation(circuit_tensor,
operators=op,
symbol_names=[symbol],
symbol_values=values_tensor)
# Return variance of gradients across all circuits.
grads = g.gradient(forward, values_tensor)
grad_var = tf.math.reduce_std(grads, axis=0)
return grad_var.numpy()[0]
3.1 Настройка и запуск
Выберите количество случайных цепей для генерации, а также их глубину и количество кубитов, на которые они должны воздействовать. Затем постройте результаты.
n_qubits = [2 * i for i in range(2, 7)
] # Ranges studied in paper are between 2 and 24.
depth = 50 # Ranges studied in paper are between 50 and 500.
n_circuits = 200
theta_var = []
for n in n_qubits:
# Generate the random circuits and observable for the given n.
qubits = cirq.GridQubit.rect(1, n)
symbol = sympy.Symbol('theta')
circuits = [
generate_random_qnn(qubits, symbol, depth) for _ in range(n_circuits)
]
op = cirq.Z(qubits[0]) * cirq.Z(qubits[1])
theta_var.append(process_batch(circuits, symbol, op))
plt.semilogy(n_qubits, theta_var)
plt.title('Gradient Variance in QNNs')
plt.xlabel('n_qubits')
plt.xticks(n_qubits)
plt.ylabel('$\\partial \\theta$ variance')
plt.show()
WARNING:tensorflow:5 out of the last 5 calls to <function Adjoint.differentiate_analytic at 0x7f9e3b5c68c0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
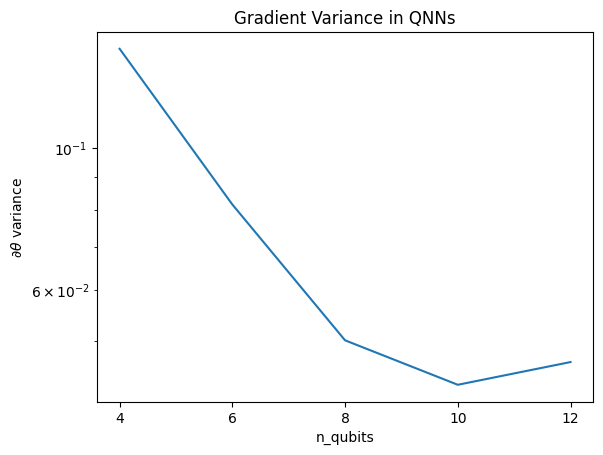
Этот график показывает, что для задач квантового машинного обучения нельзя просто угадать случайный анзац QNN и надеяться на лучшее. В схеме модели должна присутствовать некоторая структура, чтобы градиенты менялись до точки, в которой может происходить обучение.
4. Эвристика
Интересная эвристика от Grant, 2019 позволяет начать очень близко к рандому, но не совсем. Используя те же схемы, что и McClean et al., авторы предлагают другой метод инициализации для классических параметров управления, чтобы избежать бесплодных плато. Техника инициализации запускает некоторые слои с совершенно случайными параметрами управления, но в слоях, непосредственно следующих за ними, параметры выбираются так, чтобы начальное преобразование, сделанное первыми несколькими слоями, было отменено. Авторы называют это блоком идентичности .
Преимущество этой эвристики заключается в том, что при изменении всего одного параметра все остальные блоки за пределами текущего блока останутся идентичными, а сигнал градиента проходит намного сильнее, чем раньше. Это позволяет пользователю выбирать, какие переменные и блоки изменять, чтобы получить сильный сигнал градиента. Эта эвристика не предотвращает попадание пользователя в бесплодное плато во время фазы обучения (и ограничивает полностью одновременное обновление), она просто гарантирует, что вы можете начать за пределами плато.
4.1 Новая конструкция QNN
Теперь создайте функцию для генерации QNN блоков идентичности. Эта реализация немного отличается от той, что в статье. А пока посмотрите на поведение градиента одного параметра, чтобы оно согласовывалось с McClean et al, поэтому можно сделать некоторые упрощения.
Для создания блока идентификации и обучения модели обычно требуется \(U1(\theta_{1a}) U1(\theta_{1b})^{\dagger}\) а не \(U1(\theta_1) U1(\theta_1)^{\dagger}\). Первоначально \(\theta_{1a}\) и \(\theta_{1b}\) — это одни и те же углы, но они изучаются независимо. В противном случае вы всегда будете получать идентичность даже после обучения. Выбор количества блоков идентификации является эмпирическим. Чем глубже блок, тем меньше дисперсия в середине блока. Но в начале и конце блока дисперсия градиентов параметров должна быть большой.
def generate_identity_qnn(qubits, symbol, block_depth, total_depth):
"""Generate random QNN's with the same structure from Grant et al."""
circuit = cirq.Circuit()
# Generate initial block with symbol.
prep_and_U = generate_random_qnn(qubits, symbol, block_depth)
circuit += prep_and_U
# Generate dagger of initial block without symbol.
U_dagger = (prep_and_U[1:])**-1
circuit += cirq.resolve_parameters(
U_dagger, param_resolver={symbol: np.random.uniform() * 2 * np.pi})
for d in range(total_depth - 1):
# Get a random QNN.
prep_and_U_circuit = generate_random_qnn(
qubits,
np.random.uniform() * 2 * np.pi, block_depth)
# Remove the state-prep component
U_circuit = prep_and_U_circuit[1:]
# Add U
circuit += U_circuit
# Add U^dagger
circuit += U_circuit**-1
return circuit
generate_identity_qnn(cirq.GridQubit.rect(1, 3), sympy.Symbol('theta'), 2, 2)
4.2 Сравнение
Здесь вы можете видеть, что эвристика действительно помогает предотвратить столь быстрое исчезновение дисперсии градиента:
block_depth = 10
total_depth = 5
heuristic_theta_var = []
for n in n_qubits:
# Generate the identity block circuits and observable for the given n.
qubits = cirq.GridQubit.rect(1, n)
symbol = sympy.Symbol('theta')
circuits = [
generate_identity_qnn(qubits, symbol, block_depth, total_depth)
for _ in range(n_circuits)
]
op = cirq.Z(qubits[0]) * cirq.Z(qubits[1])
heuristic_theta_var.append(process_batch(circuits, symbol, op))
plt.semilogy(n_qubits, theta_var)
plt.semilogy(n_qubits, heuristic_theta_var)
plt.title('Heuristic vs. Random')
plt.xlabel('n_qubits')
plt.xticks(n_qubits)
plt.ylabel('$\\partial \\theta$ variance')
plt.show()
WARNING:tensorflow:6 out of the last 6 calls to <function Adjoint.differentiate_analytic at 0x7f9e3b5c68c0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
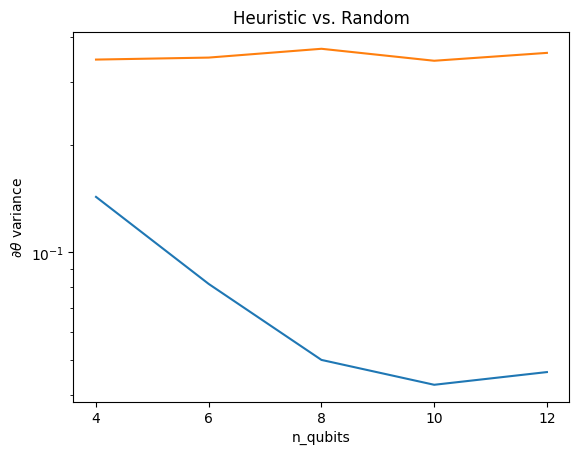
Это большое улучшение в получении более сильных сигналов градиента от (почти) случайных QNN.