
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
जब मशीन सीखने वाले मॉडल, आप विभिन्न चयन करने की आवश्यकता hyperparameters इस तरह के एक परत में छोड़ने वालों की दर या सीखने दर के रूप में,। ये निर्णय सटीकता जैसे मॉडल मेट्रिक्स को प्रभावित करते हैं। इसलिए, मशीन लर्निंग वर्कफ़्लो में एक महत्वपूर्ण कदम आपकी समस्या के लिए सर्वोत्तम हाइपरपैरामीटर की पहचान करना है, जिसमें अक्सर प्रयोग शामिल होता है। इस प्रक्रिया को "हाइपरपैरामीटर ऑप्टिमाइज़ेशन" या "हाइपरपैरामीटर ट्यूनिंग" के रूप में जाना जाता है।
TensorBoard में HParams डैशबोर्ड सबसे अच्छे प्रयोग या हाइपरपैरामीटर के सबसे आशाजनक सेट की पहचान करने की इस प्रक्रिया में मदद करने के लिए कई उपकरण प्रदान करता है।
यह ट्यूटोरियल निम्नलिखित चरणों पर ध्यान केंद्रित करेगा:
- प्रयोग सेटअप और एचपीराम्स सारांश
- Adapt TensorFlow हाइपरपैरामीटर और मेट्रिक्स लॉग करने के लिए चलता है
- रन प्रारंभ करें और उन सभी को एक मूल निर्देशिका के अंतर्गत लॉग करें
- TensorBoard के HParams डैशबोर्ड में परिणामों की कल्पना करें
TF 2.0 स्थापित करके और TensorBoard नोटबुक एक्सटेंशन लोड करके प्रारंभ करें:
# Load the TensorBoard notebook extension
%load_ext tensorboard
# Clear any logs from previous runsrm -rf ./logs/
TensorFlow और TensorBoard HParams प्लगइन आयात करें:
import tensorflow as tf
from tensorboard.plugins.hparams import api as hp
डाउनलोड FashionMNIST डाटासेट और यह स्केल:
fashion_mnist = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = fashion_mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 8192/5148 [===============================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step
1. प्रयोग सेटअप और एचपीराम्स प्रयोग सारांश
मॉडल में तीन हाइपरपैरामीटर के साथ प्रयोग:
- पहली सघन परत में इकाइयों की संख्या
- ड्रापआउट लेयर में ड्रॉपआउट दर
- अनुकूलक
कोशिश करने के लिए मानों की सूची बनाएं, और एक प्रयोग कॉन्फ़िगरेशन को TensorBoard में लॉग करें। यह चरण वैकल्पिक है: आप UI में हाइपरपैरामीटर के अधिक सटीक फ़िल्टरिंग को सक्षम करने के लिए डोमेन जानकारी प्रदान कर सकते हैं, और आप निर्दिष्ट कर सकते हैं कि कौन से मीट्रिक प्रदर्शित किए जाने चाहिए।
HP_NUM_UNITS = hp.HParam('num_units', hp.Discrete([16, 32]))
HP_DROPOUT = hp.HParam('dropout', hp.RealInterval(0.1, 0.2))
HP_OPTIMIZER = hp.HParam('optimizer', hp.Discrete(['adam', 'sgd']))
METRIC_ACCURACY = 'accuracy'
with tf.summary.create_file_writer('logs/hparam_tuning').as_default():
hp.hparams_config(
hparams=[HP_NUM_UNITS, HP_DROPOUT, HP_OPTIMIZER],
metrics=[hp.Metric(METRIC_ACCURACY, display_name='Accuracy')],
)
आप इस चरण को छोड़कर आगे बढ़ सकते हैं, तो आप एक स्ट्रिंग शाब्दिक का उपयोग भी आप अन्यथा एक का प्रयोग करेंगे कर सकते हैं HParam मूल्य: जैसे, hparams['dropout'] के बजाय hparams[HP_DROPOUT] ।
2. Adapt TensorFlow हाइपरपैरामीटर और मेट्रिक्स लॉग करने के लिए चलता है
मॉडल काफी सरल होगा: उनके बीच एक ड्रॉपआउट परत के साथ दो घनी परतें। प्रशिक्षण कोड परिचित लगेगा, हालांकि हाइपरपैरामीटर अब हार्डकोडेड नहीं हैं। इसके बजाय, hyperparameters एक में प्रदान की जाती हैं hparams शब्दकोश और प्रशिक्षण समारोह के दौरान इस्तेमाल:
def train_test_model(hparams):
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(hparams[HP_NUM_UNITS], activation=tf.nn.relu),
tf.keras.layers.Dropout(hparams[HP_DROPOUT]),
tf.keras.layers.Dense(10, activation=tf.nn.softmax),
])
model.compile(
optimizer=hparams[HP_OPTIMIZER],
loss='sparse_categorical_crossentropy',
metrics=['accuracy'],
)
model.fit(x_train, y_train, epochs=1) # Run with 1 epoch to speed things up for demo purposes
_, accuracy = model.evaluate(x_test, y_test)
return accuracy
प्रत्येक रन के लिए, हाइपरपैरामीटर और अंतिम सटीकता के साथ एक hparams सारांश लॉग करें:
def run(run_dir, hparams):
with tf.summary.create_file_writer(run_dir).as_default():
hp.hparams(hparams) # record the values used in this trial
accuracy = train_test_model(hparams)
tf.summary.scalar(METRIC_ACCURACY, accuracy, step=1)
केरस मॉडल को प्रशिक्षित करते समय, आप इसे सीधे लिखने के बजाय कॉलबैक का उपयोग कर सकते हैं:
model.fit(
...,
callbacks=[
tf.keras.callbacks.TensorBoard(logdir), # log metrics
hp.KerasCallback(logdir, hparams), # log hparams
],
)
3. रन प्रारंभ करें और उन सभी को एक मूल निर्देशिका के अंतर्गत लॉग करें
अब आप कई प्रयोग कर सकते हैं, प्रत्येक को हाइपरपैरामीटर के एक अलग सेट के साथ प्रशिक्षित कर सकते हैं।
सरलता के लिए, ग्रिड खोज का उपयोग करें: असतत मापदंडों के सभी संयोजनों और वास्तविक-मूल्यवान पैरामीटर की निचली और ऊपरी सीमाओं का प्रयास करें। अधिक जटिल परिदृश्यों के लिए, प्रत्येक हाइपरपैरामीटर मान को यादृच्छिक रूप से चुनना अधिक प्रभावी हो सकता है (इसे यादृच्छिक खोज कहा जाता है)। अधिक उन्नत तरीके हैं जिनका उपयोग किया जा सकता है।
कुछ प्रयोग चलाएँ, जिसमें कुछ मिनट लगेंगे:
session_num = 0
for num_units in HP_NUM_UNITS.domain.values:
for dropout_rate in (HP_DROPOUT.domain.min_value, HP_DROPOUT.domain.max_value):
for optimizer in HP_OPTIMIZER.domain.values:
hparams = {
HP_NUM_UNITS: num_units,
HP_DROPOUT: dropout_rate,
HP_OPTIMIZER: optimizer,
}
run_name = "run-%d" % session_num
print('--- Starting trial: %s' % run_name)
print({h.name: hparams[h] for h in hparams})
run('logs/hparam_tuning/' + run_name, hparams)
session_num += 1
--- Starting trial: run-0
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 62us/sample - loss: 0.6872 - accuracy: 0.7564
10000/10000 [==============================] - 0s 35us/sample - loss: 0.4806 - accuracy: 0.8321
--- Starting trial: run-1
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9428 - accuracy: 0.6769
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6519 - accuracy: 0.7770
--- Starting trial: run-2
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 60us/sample - loss: 0.8158 - accuracy: 0.7078
10000/10000 [==============================] - 0s 36us/sample - loss: 0.5309 - accuracy: 0.8154
--- Starting trial: run-3
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 50us/sample - loss: 1.1465 - accuracy: 0.6019
10000/10000 [==============================] - 0s 36us/sample - loss: 0.7007 - accuracy: 0.7683
--- Starting trial: run-4
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 65us/sample - loss: 0.6178 - accuracy: 0.7849
10000/10000 [==============================] - 0s 38us/sample - loss: 0.4645 - accuracy: 0.8395
--- Starting trial: run-5
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 55us/sample - loss: 0.8989 - accuracy: 0.6896
10000/10000 [==============================] - 0s 37us/sample - loss: 0.6335 - accuracy: 0.7853
--- Starting trial: run-6
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 64us/sample - loss: 0.6404 - accuracy: 0.7782
10000/10000 [==============================] - 0s 37us/sample - loss: 0.4802 - accuracy: 0.8265
--- Starting trial: run-7
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9633 - accuracy: 0.6703
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6516 - accuracy: 0.7755
4. TensorBoard के HParams प्लगइन में परिणामों की कल्पना करें
HParams डैशबोर्ड अब खोला जा सकता है। TensorBoard प्रारंभ करें और शीर्ष पर "HParams" पर क्लिक करें।
%tensorboard --logdir logs/hparam_tuning
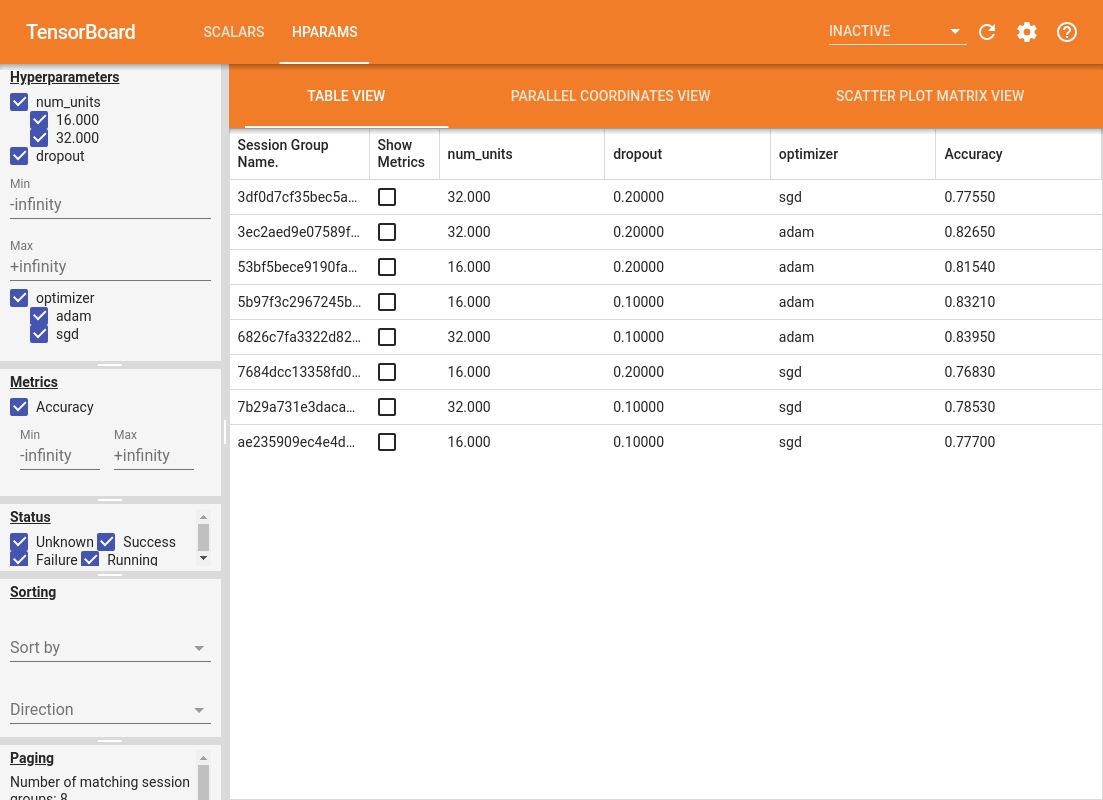
डैशबोर्ड का बायां फलक फ़िल्टरिंग क्षमताएं प्रदान करता है जो एचपीराम्स डैशबोर्ड में सभी दृश्यों में सक्रिय हैं:
- फ़िल्टर करें कि कौन से हाइपरपैरामीटर/मेट्रिक्स डैशबोर्ड में दिखाए गए हैं
- फ़िल्टर करें कि कौन से हाइपरपैरामीटर/मीट्रिक मान डैशबोर्ड में दिखाए गए हैं
- रन स्थिति पर फ़िल्टर करें (चल रहा है, सफलता, ...)
- तालिका दृश्य में हाइपरपैरामीटर/मीट्रिक के आधार पर क्रमित करें
- दिखाने के लिए सत्र समूहों की संख्या (कई प्रयोग होने पर प्रदर्शन के लिए उपयोगी)
विभिन्न उपयोगी सूचनाओं के साथ HParams डैशबोर्ड के तीन अलग-अलग दृश्य हैं:
- तालिका देखें रन, उनके hyperparameters, और उनके मीट्रिक सूचीबद्ध हैं।
- समानांतर निर्देशांक देखें एक लाइन प्रत्येक hyperparemeter और मीट्रिक के लिए एक धुरी के माध्यम से जा के रूप में प्रत्येक रन दर्शाता है। किसी क्षेत्र को चिह्नित करने के लिए माउस को किसी भी अक्ष पर क्लिक करें और खींचें जो केवल इसके माध्यम से गुजरने वाले रनों को हाइलाइट करेगा। यह पहचानने के लिए उपयोगी हो सकता है कि हाइपरपैरामीटर के कौन से समूह सबसे महत्वपूर्ण हैं। कुल्हाड़ियों को खुद खींचकर फिर से व्यवस्थित किया जा सकता है।
- स्कैटर प्लॉट देखने से पता चलता भूखंडों प्रत्येक hyperparameter / प्रत्येक मीट्रिक के साथ मीट्रिक की तुलना। यह सहसंबंधों की पहचान करने में मदद कर सकता है। एक विशिष्ट प्लॉट में एक क्षेत्र का चयन करने के लिए क्लिक करें और खींचें और उन सत्रों को अन्य भूखंडों में हाइलाइट करें।
एक तालिका पंक्ति, एक समानांतर निर्देशांक रेखा, और एक स्कैटर प्लॉट बाजार पर क्लिक करके उस सत्र के लिए प्रशिक्षण चरणों के कार्य के रूप में मेट्रिक्स का एक प्लॉट देखा जा सकता है (हालाँकि इस ट्यूटोरियल में प्रत्येक रन के लिए केवल एक चरण का उपयोग किया जाता है)।
HParams डैशबोर्ड की क्षमताओं को और अधिक एक्सप्लोर करने के लिए, अधिक प्रयोगों के साथ प्रीजेनरेटेड लॉग का एक सेट डाउनलोड करें:
wget -q 'https://storage.googleapis.com/download.tensorflow.org/tensorboard/hparams_demo_logs.zip'unzip -q hparams_demo_logs.zip -d logs/hparam_demo
TensorBoard में ये लॉग देखें:
%tensorboard --logdir logs/hparam_demo
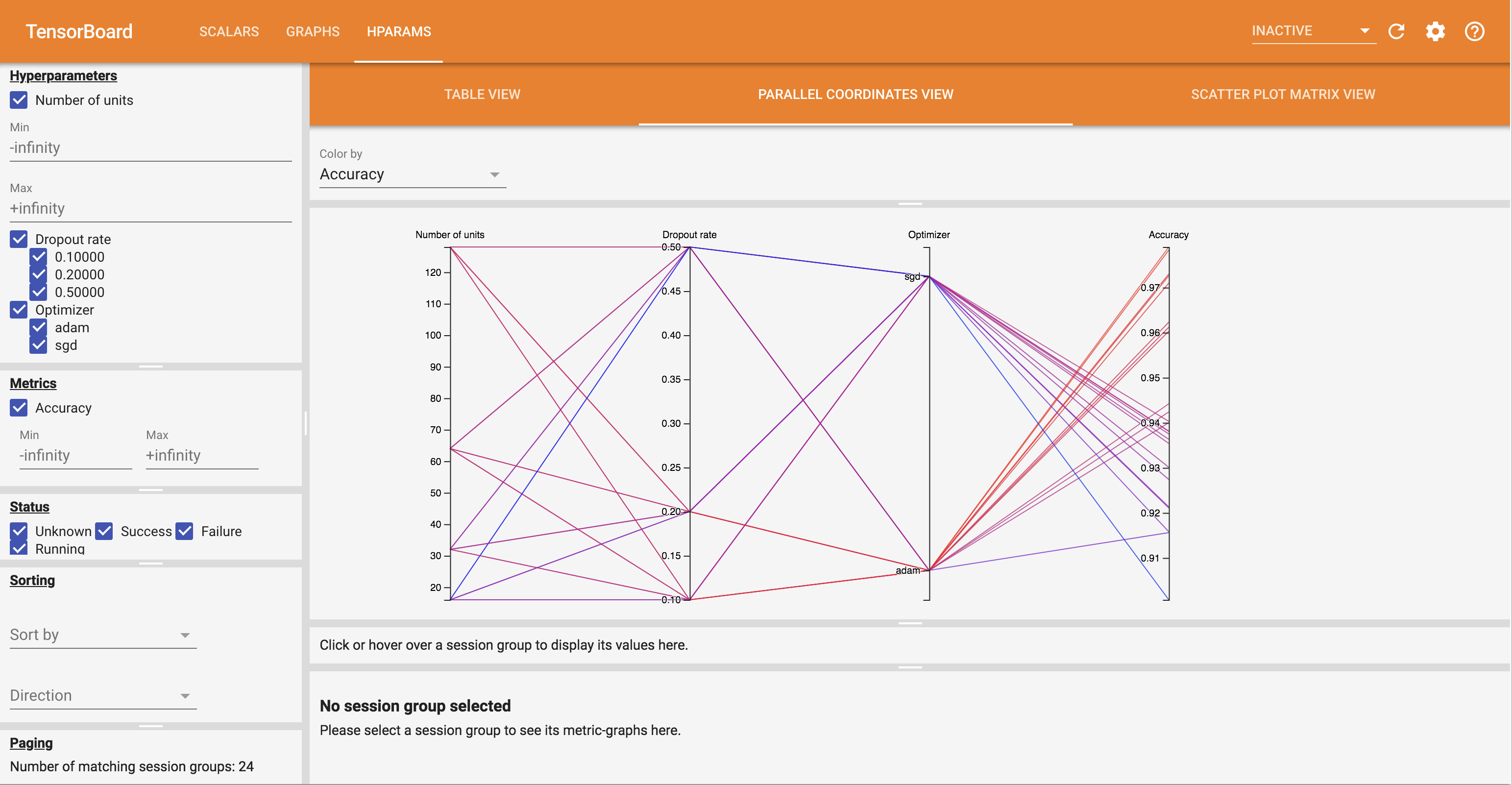
आप HParams डैशबोर्ड में विभिन्न दृश्यों को आज़मा सकते हैं।
उदाहरण के लिए, समानांतर निर्देशांक दृश्य पर जाकर और सटीकता अक्ष पर क्लिक करके और खींचकर, आप उच्चतम सटीकता के साथ रनों का चयन कर सकते हैं। चूंकि ये रन अनुकूलक अक्ष में 'एडम' से गुजरते हैं, आप यह निष्कर्ष निकाल सकते हैं कि 'एडम' ने इन प्रयोगों पर 'एसजीडी' से बेहतर प्रदर्शन किया।