
| | |  GitHub에서 소스 보기 GitHub에서 소스 보기 | |
기계 학습 모델을 구축 할 때, 당신은 다양한 선택해야 하는 하이퍼 같은 층에서 드롭 아웃 속도 나 학습 속도 등을. 이러한 결정은 정확도와 같은 모델 메트릭에 영향을 줍니다. 따라서 머신 러닝 워크플로에서 중요한 단계는 문제에 가장 적합한 하이퍼파라미터를 식별하는 것입니다. 여기에는 종종 실험이 포함됩니다. 이 프로세스를 "초매개변수 최적화" 또는 "초매개변수 조정"이라고 합니다.
TensorBoard의 HParams 대시보드는 최상의 실험 또는 가장 유망한 하이퍼파라미터 집합을 식별하는 이 프로세스를 지원하는 여러 도구를 제공합니다.
이 자습서에서는 다음 단계에 중점을 둘 것입니다.
- 실험 설정 및 HParams 요약
- 초매개변수 및 측정항목을 기록하기 위해 TensorFlow 실행을 조정합니다.
- 실행을 시작하고 하나의 상위 디렉토리 아래에 모두 기록합니다.
- TensorBoard의 HParams 대시보드에서 결과 시각화
TF 2.0을 설치하고 TensorBoard 노트북 확장을 로드하여 시작합니다.
# Load the TensorBoard notebook extension
%load_ext tensorboard
# Clear any logs from previous runsrm -rf ./logs/
TensorFlow 및 TensorBoard HParams 플러그인 가져오기:
import tensorflow as tf
from tensorboard.plugins.hparams import api as hp
다운로드 FashionMNIST의 데이터 집합을하고 그것을 확장 :
fashion_mnist = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = fashion_mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 8192/5148 [===============================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step
1. 실험 설정 및 HParams 실험 요약
모델에서 세 개의 하이퍼파라미터로 실험합니다.
- 첫 번째 조밀한 층의 단위 수
- 드롭아웃 레이어의 드롭아웃 비율
- 옵티마이저
시도할 값을 나열하고 TensorBoard에 실험 구성을 기록합니다. 이 단계는 선택 사항입니다. 도메인 정보를 제공하여 UI에서 초매개변수를 보다 정확하게 필터링할 수 있고 표시할 메트릭을 지정할 수 있습니다.
HP_NUM_UNITS = hp.HParam('num_units', hp.Discrete([16, 32]))
HP_DROPOUT = hp.HParam('dropout', hp.RealInterval(0.1, 0.2))
HP_OPTIMIZER = hp.HParam('optimizer', hp.Discrete(['adam', 'sgd']))
METRIC_ACCURACY = 'accuracy'
with tf.summary.create_file_writer('logs/hparam_tuning').as_default():
hp.hparams_config(
hparams=[HP_NUM_UNITS, HP_DROPOUT, HP_OPTIMIZER],
metrics=[hp.Metric(METRIC_ACCURACY, display_name='Accuracy')],
)
이 단계를 건너 뛸 경우 그렇지 않으면 사용 할 때마다, 당신은 문자열 리터럴을 사용할 수 있습니다 HParam 예 : 값 hparams['dropout'] 대신 hparams[HP_DROPOUT] .
2. TensorFlow 실행을 조정하여 하이퍼파라미터 및 메트릭을 기록합니다.
모델은 매우 간단합니다. 두 개의 조밀한 레이어와 그 사이에 드롭아웃 레이어가 있습니다. 하이퍼파라미터가 더 이상 하드코딩되지 않더라도 훈련 코드는 친숙해 보일 것입니다. 대신, 하이퍼 파라미터는 제공됩니다 hparams 사전 및 교육 기능 전반에 걸쳐 사용 :
def train_test_model(hparams):
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(hparams[HP_NUM_UNITS], activation=tf.nn.relu),
tf.keras.layers.Dropout(hparams[HP_DROPOUT]),
tf.keras.layers.Dense(10, activation=tf.nn.softmax),
])
model.compile(
optimizer=hparams[HP_OPTIMIZER],
loss='sparse_categorical_crossentropy',
metrics=['accuracy'],
)
model.fit(x_train, y_train, epochs=1) # Run with 1 epoch to speed things up for demo purposes
_, accuracy = model.evaluate(x_test, y_test)
return accuracy
각 실행에 대해 하이퍼파라미터 및 최종 정확도가 포함된 hparams 요약을 기록합니다.
def run(run_dir, hparams):
with tf.summary.create_file_writer(run_dir).as_default():
hp.hparams(hparams) # record the values used in this trial
accuracy = train_test_model(hparams)
tf.summary.scalar(METRIC_ACCURACY, accuracy, step=1)
Keras 모델을 훈련할 때 직접 작성하는 대신 콜백을 사용할 수 있습니다.
model.fit(
...,
callbacks=[
tf.keras.callbacks.TensorBoard(logdir), # log metrics
hp.KerasCallback(logdir, hparams), # log hparams
],
)
3. 실행을 시작하고 하나의 상위 디렉토리 아래에 모두 기록합니다.
이제 여러 실험을 시도하여 각기 다른 초매개변수 세트로 실험을 훈련할 수 있습니다.
단순성을 위해 그리드 검색을 사용하십시오. 이산 매개변수의 모든 조합과 실제 값 매개변수의 하한 및 상한만 시도합니다. 더 복잡한 시나리오의 경우 각 하이퍼파라미터 값을 무작위로 선택하는 것이 더 효과적일 수 있습니다(이를 무작위 검색이라고 함). 사용할 수 있는 고급 방법이 있습니다.
몇 분 정도 소요되는 몇 가지 실험을 실행합니다.
session_num = 0
for num_units in HP_NUM_UNITS.domain.values:
for dropout_rate in (HP_DROPOUT.domain.min_value, HP_DROPOUT.domain.max_value):
for optimizer in HP_OPTIMIZER.domain.values:
hparams = {
HP_NUM_UNITS: num_units,
HP_DROPOUT: dropout_rate,
HP_OPTIMIZER: optimizer,
}
run_name = "run-%d" % session_num
print('--- Starting trial: %s' % run_name)
print({h.name: hparams[h] for h in hparams})
run('logs/hparam_tuning/' + run_name, hparams)
session_num += 1
--- Starting trial: run-0
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 62us/sample - loss: 0.6872 - accuracy: 0.7564
10000/10000 [==============================] - 0s 35us/sample - loss: 0.4806 - accuracy: 0.8321
--- Starting trial: run-1
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9428 - accuracy: 0.6769
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6519 - accuracy: 0.7770
--- Starting trial: run-2
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 60us/sample - loss: 0.8158 - accuracy: 0.7078
10000/10000 [==============================] - 0s 36us/sample - loss: 0.5309 - accuracy: 0.8154
--- Starting trial: run-3
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 50us/sample - loss: 1.1465 - accuracy: 0.6019
10000/10000 [==============================] - 0s 36us/sample - loss: 0.7007 - accuracy: 0.7683
--- Starting trial: run-4
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 65us/sample - loss: 0.6178 - accuracy: 0.7849
10000/10000 [==============================] - 0s 38us/sample - loss: 0.4645 - accuracy: 0.8395
--- Starting trial: run-5
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 55us/sample - loss: 0.8989 - accuracy: 0.6896
10000/10000 [==============================] - 0s 37us/sample - loss: 0.6335 - accuracy: 0.7853
--- Starting trial: run-6
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 64us/sample - loss: 0.6404 - accuracy: 0.7782
10000/10000 [==============================] - 0s 37us/sample - loss: 0.4802 - accuracy: 0.8265
--- Starting trial: run-7
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9633 - accuracy: 0.6703
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6516 - accuracy: 0.7755
4. TensorBoard의 HParams 플러그인에서 결과 시각화
이제 HParams 대시보드를 열 수 있습니다. TensorBoard를 시작하고 상단의 "HParams"를 클릭합니다.
%tensorboard --logdir logs/hparam_tuning
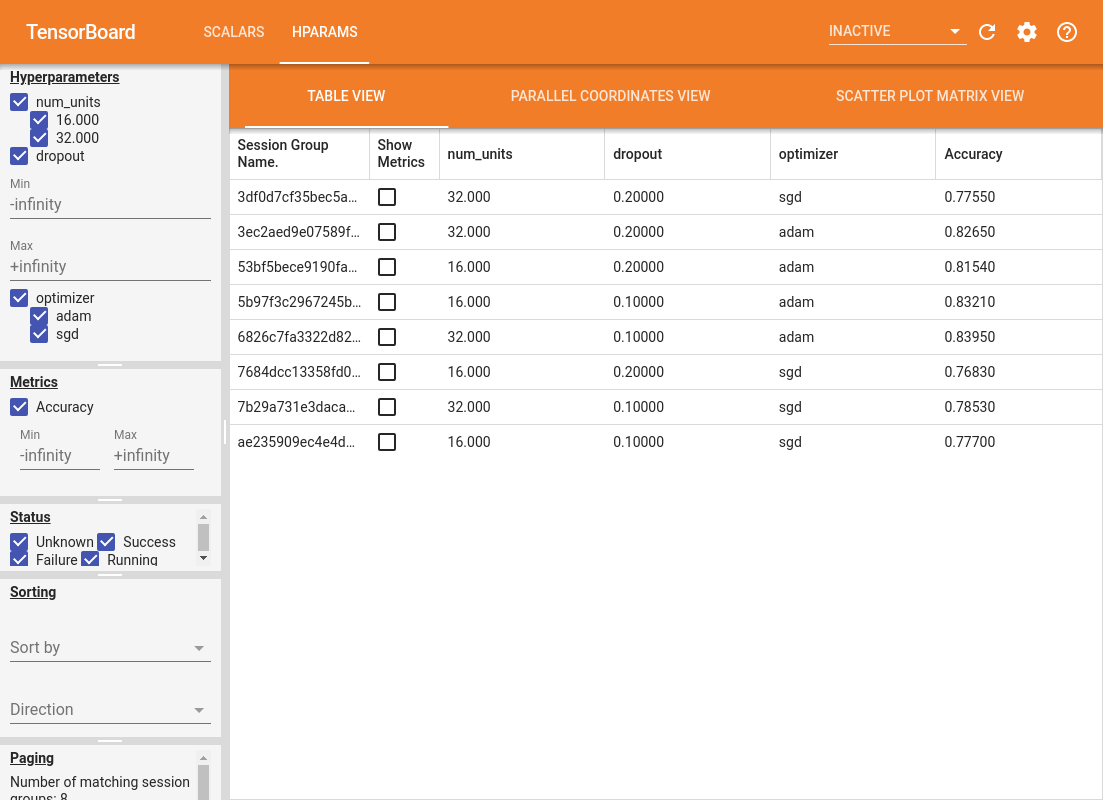
대시보드의 왼쪽 창은 HParams 대시보드의 모든 보기에서 활성화되는 필터링 기능을 제공합니다.
- 대시보드에 표시되는 하이퍼파라미터/메트릭 필터링
- 대시보드에 표시되는 하이퍼파라미터/메트릭 값 필터링
- 실행 상태 필터링(실행 중, 성공, ...)
- 테이블 보기에서 하이퍼파라미터/메트릭으로 정렬
- 표시할 세션 그룹 수(실험이 많을 때 성능에 유용)
HParams 대시보드에는 다양한 유용한 정보가 포함된 세 가지 보기가 있습니다.
- 테이블보기는 실행, 자신의 하이퍼 파라미터, 그들의 통계를 보여줍니다.
- 병렬 좌표보기 각 hyperparemeter 및 측정 축을 통과하는 선으로 각 실행을 보여줍니다. 축에서 마우스를 클릭하고 끌어 해당 영역을 통과하는 런만 강조 표시하는 영역을 표시합니다. 이것은 어떤 하이퍼파라미터 그룹이 가장 중요한지 식별하는 데 유용할 수 있습니다. 축 자체는 드래그하여 재정렬할 수 있습니다.
- 각각의 기준을 가진 각 hyperparameter을 / 비교 산포도보기 쇼 플롯. 이것은 상관 관계를 식별하는 데 도움이 될 수 있습니다. 클릭하고 끌어 특정 플롯에서 영역을 선택하고 다른 플롯에서 해당 세션을 강조 표시합니다.
테이블 행, 평행 좌표선 및 산점도 시장을 클릭하면 해당 세션에 대한 교육 단계의 함수로 메트릭 플롯을 볼 수 있습니다(이 자습서에서는 각 실행에 대해 한 단계만 사용됨).
HParams 대시보드의 기능을 추가로 탐색하려면 더 많은 실험을 통해 미리 생성된 로그 세트를 다운로드하십시오.
wget -q 'https://storage.googleapis.com/download.tensorflow.org/tensorboard/hparams_demo_logs.zip'unzip -q hparams_demo_logs.zip -d logs/hparam_demo
TensorBoard에서 다음 로그를 봅니다.
%tensorboard --logdir logs/hparam_demo
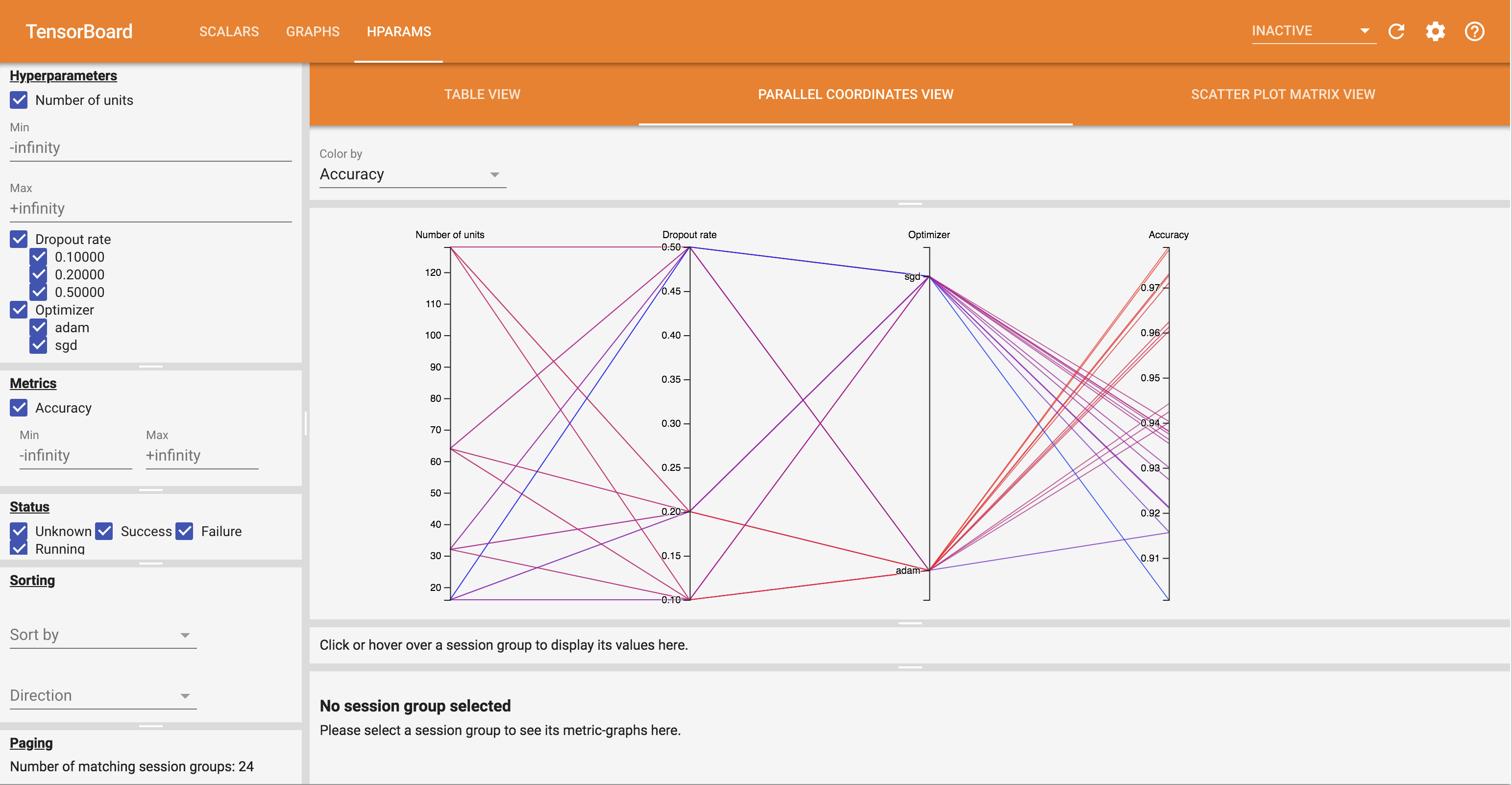
HParams 대시보드에서 다양한 보기를 시도할 수 있습니다.
예를 들어 평행 좌표 보기로 이동하여 정확도 축을 클릭하고 드래그하면 가장 정확도가 높은 런을 선택할 수 있습니다. 이러한 실행이 옵티마이저 축의 'adam'을 통과함에 따라 이 실험에서 'adam'이 'gd'보다 더 나은 성능을 보였다는 결론을 내릴 수 있습니다.