
Una vez que sus datos estén en una canalización TFX, puede usar componentes TFX para analizarlos y transformarlos. Puede utilizar estas herramientas incluso antes de entrenar un modelo.
Hay muchas razones para analizar y transformar tus datos:
- Para encontrar problemas en sus datos. Los problemas comunes incluyen:
- Datos faltantes, como entidades con valores vacíos.
- Las etiquetas se tratan como características, para que su modelo pueda ver la respuesta correcta durante el entrenamiento.
- Funciones con valores fuera del rango esperado.
- Anomalías de datos.
- El modelo de transferencia aprendida tiene un preprocesamiento que no coincide con los datos de entrenamiento.
- Diseñar conjuntos de funciones más eficaces. Por ejemplo, puedes identificar:
- Funciones especialmente informativas.
- Funciones redundantes.
- Características que varían tanto en escala que pueden ralentizar el aprendizaje.
- Funciones con poca o ninguna información predictiva única.
Las herramientas TFX pueden ayudar a encontrar errores en los datos y ayudar con la ingeniería de funciones.
Validación de datos de TensorFlow
- Descripción general
- Validación de ejemplo basada en esquemas
- Detección de sesgos al servicio de la capacitación
- Detección de deriva
Descripción general
TensorFlow Data Validation identifica anomalías en el entrenamiento y el suministro de datos, y puede crear automáticamente un esquema examinando los datos. El componente se puede configurar para detectar diferentes clases de anomalías en los datos. Puede
- Realice comprobaciones de validez comparando estadísticas de datos con un esquema que codifique las expectativas del usuario.
- Detecte el sesgo en la entrega de capacitación comparando ejemplos en datos de capacitación y entrega.
- Detecte la desviación de datos observando una serie de datos.
Documentamos cada una de estas funcionalidades de forma independiente:
- Validación de ejemplo basada en esquemas
- Detección de sesgos al servicio de la capacitación
- Detección de deriva
Validación de ejemplo basada en esquemas
La validación de datos de TensorFlow identifica cualquier anomalía en los datos de entrada comparando las estadísticas de los datos con un esquema. El esquema codifica propiedades que se espera que satisfagan los datos de entrada, como tipos de datos o valores categóricos, y el usuario puede modificarlos o reemplazarlos.
La validación de datos de Tensorflow generalmente se invoca varias veces dentro del contexto de la canalización TFX: (i) para cada división obtenida de EjemploGen, (ii) para todos los datos pretransformados utilizados por Transform y (iii) para todos los datos posteriores a la transformación generados por Transformar. Cuando se invoca en el contexto de Transformación (ii-iii), las opciones estadísticas y las restricciones basadas en esquemas se pueden establecer definiendo stats_options_updater_fn . Esto es particularmente útil al validar datos no estructurados (por ejemplo, características de texto). Vea el código de usuario para ver un ejemplo.
Funciones avanzadas de esquema
Esta sección cubre una configuración de esquema más avanzada que puede ayudar con configuraciones especiales.
Funciones escasas
La codificación de características dispersas en los ejemplos generalmente introduce múltiples características que se espera que tengan la misma valencia para todos los ejemplos. Por ejemplo, la característica escasa:
WeightedCategories = [('CategoryA', 0.3), ('CategoryX', 0.7)]
WeightedCategoriesIndex = ['CategoryA', 'CategoryX']
WeightedCategoriesValue = [0.3, 0.7]
sparse_feature {
name: 'WeightedCategories'
index_feature { name: 'WeightedCategoriesIndex' }
value_feature { name: 'WeightedCategoriesValue' }
}
La definición de característica dispersa requiere uno o más índices y una característica de valor que se refieren a características que existen en el esquema. La definición explícita de características dispersas permite a TFDV verificar que las valencias de todas las características referidas coincidan.
Algunos casos de uso introducen restricciones de valencia similares entre funciones, pero no necesariamente codifican una función dispersa. El uso de la función dispersa debería desbloquearte, pero no es lo ideal.
Entornos de esquema
De forma predeterminada, las validaciones suponen que todos los ejemplos de una canalización se adhieren a un único esquema. En algunos casos, es necesario introducir ligeras variaciones en el esquema; por ejemplo, las funciones utilizadas como etiquetas son necesarias durante el entrenamiento (y deben validarse), pero faltan durante la publicación. Los entornos se pueden utilizar para expresar dichos requisitos, en particular default_environment() , in_environment() , not_in_environment() .
Por ejemplo, supongamos que se requiere una función llamada "LABEL" para la capacitación, pero se espera que no esté presente en la publicación. Esto se puede expresar mediante:
- Defina dos entornos distintos en el esquema: ["SERVING", "TRAINING"] y asocie 'LABEL' únicamente con el entorno "TRAINING".
- Asocie los datos de entrenamiento con el entorno "TRAINING" y los datos de servicio con el entorno "SERVING".
Generación de esquemas
El esquema de datos de entrada se especifica como una instancia del esquema TensorFlow.
En lugar de construir un esquema manualmente desde cero, un desarrollador puede confiar en la construcción automática de esquemas de TensorFlow Data Validation. Específicamente, TensorFlow Data Validation construye automáticamente un esquema inicial basado en estadísticas calculadas sobre los datos de entrenamiento disponibles en la canalización. Los usuarios pueden simplemente revisar este esquema generado automáticamente, modificarlo según sea necesario, registrarlo en un sistema de control de versiones e insertarlo explícitamente en el proceso para su posterior validación.
TFDV incluye infer_schema() para generar un esquema automáticamente. Por ejemplo:
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
Esto desencadena una generación automática de esquema basada en las siguientes reglas:
Si un esquema ya se ha generado automáticamente, se utiliza tal cual.
De lo contrario, TensorFlow Data Validation examina las estadísticas de datos disponibles y calcula un esquema adecuado para los datos.
Nota: El esquema generado automáticamente es el de mejor esfuerzo y solo intenta inferir propiedades básicas de los datos. Se espera que los usuarios lo revisen y modifiquen según sea necesario.
Detección de sesgos al servicio de la capacitación
Descripción general
La validación de datos de TensorFlow puede detectar un sesgo de distribución entre los datos de entrenamiento y de entrega. El sesgo de distribución ocurre cuando la distribución de los valores de las características para los datos de entrenamiento es significativamente diferente de los datos de entrega. Una de las causas clave del sesgo en la distribución es el uso de un corpus completamente diferente para entrenar la generación de datos para superar la falta de datos iniciales en el corpus deseado. Otra razón es un mecanismo de muestreo defectuoso que solo elige una submuestra de los datos de entrega para entrenar.
Escenario de ejemplo
Consulte la Guía de introducción a la validación de datos de TensorFlow para obtener información sobre cómo configurar la detección de sesgos en el servicio de capacitación.
Detección de deriva
La detección de deriva se admite entre intervalos de datos consecutivos (es decir, entre el intervalo N y el intervalo N+1), como por ejemplo entre diferentes días de datos de entrenamiento. Expresamos la deriva en términos de distancia L-infinito para características categóricas y divergencia aproximada de Jensen-Shannon para características numéricas. Puede establecer la distancia umbral para recibir advertencias cuando la deriva sea mayor de lo aceptable. Establecer la distancia correcta suele ser un proceso iterativo que requiere experimentación y conocimiento del dominio.
Consulte la Guía de introducción a la validación de datos de TensorFlow para obtener información sobre cómo configurar la detección de deriva.
Uso de visualizaciones para verificar sus datos
TensorFlow Data Validation proporciona herramientas para visualizar la distribución de valores de características. Al examinar estas distribuciones en un cuaderno Jupyter usando Facets, puede detectar problemas comunes con los datos.
Identificación de distribuciones sospechosas
Puede identificar errores comunes en sus datos utilizando una pantalla de descripción general de facetas para buscar distribuciones sospechosas de valores de características.
Datos desequilibrados
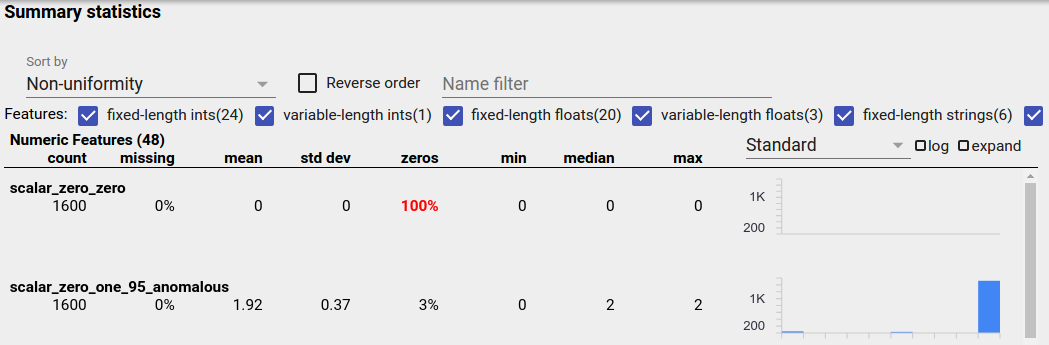
Una característica desequilibrada es una característica en la que predomina un valor. Las características desequilibradas pueden ocurrir naturalmente, pero si una característica siempre tiene el mismo valor, es posible que tenga un error de datos. Para detectar características desequilibradas en una descripción general de facetas, elija "No uniformidad" en el menú desplegable "Ordenar por".
Las funciones más desequilibradas aparecerán en la parte superior de cada lista de tipos de funciones. Por ejemplo, la siguiente captura de pantalla muestra una característica que es todo ceros y una segunda que está muy desequilibrada, en la parte superior de la lista "Funciones numéricas":
Datos distribuidos uniformemente
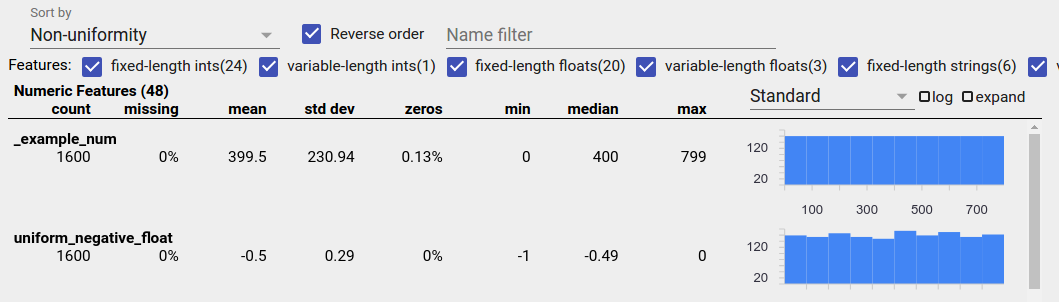
Una característica distribuida uniformemente es aquella para la cual todos los valores posibles aparecen casi con la misma frecuencia. Al igual que con los datos desequilibrados, esta distribución puede ocurrir de forma natural, pero también puede deberse a errores en los datos.
Para detectar características distribuidas uniformemente en una descripción general de facetas, elija "No uniformidad" en el menú desplegable "Ordenar por" y marque la casilla de verificación "Orden inverso":
Los datos de cadena se representan mediante gráficos de barras si hay 20 valores únicos o menos, y como un gráfico de distribución acumulativa si hay más de 20 valores únicos. Entonces, para datos de cadenas, las distribuciones uniformes pueden aparecer como gráficos de barras planas como el de arriba o como líneas rectas como el de abajo:

Errores que pueden producir datos distribuidos uniformemente
A continuación se muestran algunos errores comunes que pueden producir datos distribuidos uniformemente:
Usar cadenas para representar tipos de datos que no son cadenas, como fechas. Por ejemplo, tendrá muchos valores únicos para una función de fecha y hora con representaciones como "2017-03-01-11-45-03". Los valores únicos se distribuirán uniformemente.
Incluyendo índices como "número de fila" como características. Aquí nuevamente tienes muchos valores únicos.
Datos faltantes
Para comprobar si a una característica le faltan valores por completo:
- Elija "Cantidad faltante/cero" en el menú desplegable "Ordenar por".
- Marque la casilla de verificación "Orden inverso".
- Mire la columna "faltante" para ver el porcentaje de instancias con valores faltantes para una característica.
Un error de datos también puede causar valores de características incompletos. Por ejemplo, puede esperar que la lista de valores de una característica siempre tenga tres elementos y descubrir que a veces solo tiene uno. Para comprobar si hay valores incompletos u otros casos en los que las listas de valores de características no tienen la cantidad esperada de elementos:
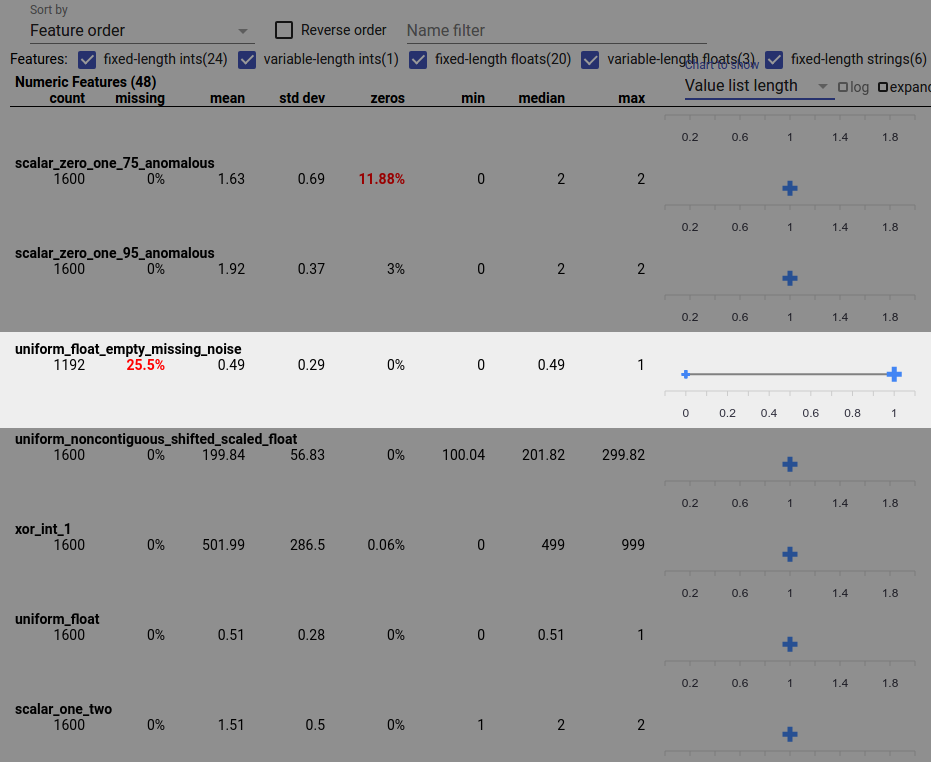
Elija "Longitud de la lista de valores" en el menú desplegable "Gráfico para mostrar" a la derecha.
Mire el cuadro a la derecha de cada fila de características. El gráfico muestra el rango de longitudes de la lista de valores para la característica. Por ejemplo, la fila resaltada en la siguiente captura de pantalla muestra una característica que tiene algunas listas de valores de longitud cero:
Grandes diferencias de escala entre funciones
Si sus características varían mucho en escala, entonces el modelo puede tener dificultades para aprender. Por ejemplo, si algunas características varían de 0 a 1 y otras varían de 0 a 1.000.000.000, tienes una gran diferencia de escala. Compare las columnas "máximo" y "mínimo" de las funciones para encontrar escalas que varían ampliamente.
Considere la posibilidad de normalizar los valores de las características para reducir estas amplias variaciones.
Etiquetas con etiquetas no válidas
Los estimadores de TensorFlow tienen restricciones sobre el tipo de datos que aceptan como etiquetas. Por ejemplo, los clasificadores binarios normalmente solo funcionan con etiquetas {0, 1}.
Revise los valores de las etiquetas en la descripción general de facetas y asegúrese de que cumplan con los requisitos de los estimadores .