
Tổng quan
EvalSavedModel có còn cần thiết không?
TFMA trước đây yêu cầu tất cả số liệu phải được lưu trữ trong biểu đồ tensorflow bằng cách sử dụng EvalSavedModel đặc biệt. Giờ đây, số liệu có thể được tính toán bên ngoài biểu đồ TF bằng cách triển khai beam.CombineFn .
Một số khác biệt chính là:
-
EvalSavedModelyêu cầu xuất đặc biệt từ trình huấn luyện trong khi mô hình phân phát có thể được sử dụng mà không cần bất kỳ thay đổi nào đối với mã đào tạo. - Khi sử dụng
EvalSavedModel, mọi số liệu được thêm vào thời gian đào tạo sẽ tự động có sẵn tại thời điểm đánh giá. Nếu không cóEvalSavedModelthì các số liệu này phải được thêm lại.- Ngoại lệ đối với quy tắc này là nếu sử dụng mô hình máy ảnh thì số liệu cũng có thể được thêm tự động vì máy ảnh lưu thông tin số liệu cùng với mô hình đã lưu.
TFMA có thể hoạt động với cả số liệu trong biểu đồ và số liệu bên ngoài không?
TFMA cho phép sử dụng phương pháp kết hợp trong đó một số số liệu có thể được tính toán trong biểu đồ trong khi các số liệu khác có thể được tính toán bên ngoài. Nếu bạn hiện có EvalSavedModel thì bạn có thể tiếp tục sử dụng nó.
Có hai trường hợp:
- Sử dụng TFMA
EvalSavedModelcho cả việc trích xuất tính năng và tính toán số liệu nhưng cũng có thể thêm các số liệu bổ sung dựa trên bộ kết hợp. Trong trường hợp này, bạn sẽ nhận được tất cả số liệu trong biểu đồ từEvalSavedModelcùng với mọi số liệu bổ sung từ dựa trên trình kết hợp có thể chưa được hỗ trợ trước đó. - Sử dụng TFMA
EvalSavedModelđể trích xuất tính năng/dự đoán nhưng sử dụng số liệu dựa trên bộ kết hợp cho tất cả các tính toán số liệu. Chế độ này hữu ích nếu có các phép biến đổi đối tượng có trongEvalSavedModelmà bạn muốn sử dụng để cắt nhưng muốn thực hiện tất cả các phép tính số liệu bên ngoài biểu đồ.
Cài đặt
Những loại mô hình nào được hỗ trợ?
TFMA hỗ trợ các mô hình máy ảnh, các mô hình dựa trên API chữ ký TF2 chung, cũng như các mô hình dựa trên công cụ ước tính TF (mặc dù tùy thuộc vào trường hợp sử dụng, các mô hình dựa trên công cụ ước tính có thể yêu cầu sử dụng EvalSavedModel ).
Xem hướng dẫn get_started để biết danh sách đầy đủ các loại mô hình được hỗ trợ và mọi hạn chế.
Làm cách nào để thiết lập TFMA để hoạt động với mô hình dựa trên máy ảnh gốc?
Sau đây là cấu hình ví dụ cho mô hình máy ảnh dựa trên các giả định sau:
- Mô hình đã lưu là để phục vụ và sử dụng tên chữ ký
serving_default(điều này có thể được thay đổi bằng cách sử dụngmodel_specs[0].signature_name). - Nên đánh giá các số liệu tích hợp từ
model.compile(...)(điều này có thể bị tắt thông quaoptions.include_default_metrictrong tfma.EvalConfig ).
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
Xem số liệu để biết thêm thông tin về các loại số liệu khác có thể được định cấu hình.
Làm cách nào để thiết lập TFMA để hoạt động với mô hình dựa trên chữ ký TF2 chung?
Sau đây là cấu hình ví dụ cho mô hình TF2 chung. Bên dưới, signature_name là tên của chữ ký cụ thể sẽ được sử dụng để đánh giá.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "<signature-name>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "BinaryCrossentropy" }
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
Xem số liệu để biết thêm thông tin về các loại số liệu khác có thể được định cấu hình.
Làm cách nào để thiết lập TFMA để hoạt động với mô hình dựa trên công cụ ước tính?
Trong trường hợp này có ba sự lựa chọn.
Tùy chọn1: Sử dụng Mô hình phân phát
Nếu tùy chọn này được sử dụng thì mọi số liệu được thêm vào trong quá trình đào tạo sẽ KHÔNG được đưa vào đánh giá.
Sau đây là cấu hình ví dụ giả sử serving_default là tên chữ ký được sử dụng:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
Xem số liệu để biết thêm thông tin về các loại số liệu khác có thể được định cấu hình.
Tùy chọn2: Sử dụng EvalSavedModel cùng với các chỉ số dựa trên bộ kết hợp bổ sung
Trong trường hợp này, hãy sử dụng EvalSavedModel cho cả việc trích xuất và đánh giá tính năng/dự đoán, đồng thời thêm các chỉ số dựa trên bộ kết hợp bổ sung.
Sau đây là một cấu hình ví dụ:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
Xem số liệu để biết thêm thông tin về các loại số liệu khác có thể được định cấu hình và EvalSavedModel để biết thêm thông tin về cách thiết lập EvalSavedModel.
Tùy chọn 3: Chỉ sử dụng Mô hình EvalSavedModel để trích xuất tính năng/dự đoán
Tương tự như tùy chọn (2), nhưng chỉ sử dụng EvalSavedModel để trích xuất tính năng/dự đoán. Tùy chọn này hữu ích nếu chỉ mong muốn các số liệu bên ngoài, nhưng có những chuyển đổi tính năng mà bạn muốn cắt nhỏ. Tương tự như tùy chọn (1), mọi số liệu được thêm vào trong quá trình đào tạo sẽ KHÔNG được đưa vào đánh giá.
Trong trường hợp này, cấu hình giống như trên, chỉ có include_default_metrics bị tắt.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
options {
include_default_metrics { value: false }
}
""", tfma.EvalConfig())
Xem số liệu để biết thêm thông tin về các loại số liệu khác có thể được định cấu hình và EvalSavedModel để biết thêm thông tin về cách thiết lập EvalSavedModel.
Làm cách nào để thiết lập TFMA để hoạt động với mô hình dựa trên mô hình ước tính của máy ảnh?
Thiết lập máy ảnh model_to_estimator tương tự như cấu hình công cụ ước tính. Tuy nhiên, có một số khác biệt cụ thể về cách thức hoạt động của mô hình với công cụ ước tính. Cụ thể, mô hình-to-esimtator trả về kết quả đầu ra của nó dưới dạng một lệnh trong đó khóa dict là tên của lớp đầu ra cuối cùng trong mô hình máy ảnh được liên kết (nếu không có tên nào được cung cấp, máy ảnh sẽ chọn tên mặc định cho bạn chẳng hạn như dense_1 hoặc output_1 ). Từ góc độ TFMA, hành vi này tương tự như những gì sẽ là đầu ra của một mô hình nhiều đầu ra mặc dù mô hình cho bộ ước tính có thể chỉ dành cho một mô hình duy nhất. Để giải quyết sự khác biệt này, cần phải thực hiện thêm một bước nữa để thiết lập tên đầu ra. Tuy nhiên, ba tùy chọn tương tự được áp dụng làm công cụ ước tính.
Sau đây là ví dụ về những thay đổi cần thiết đối với cấu hình dựa trên công cụ ước tính:
from google.protobuf import text_format
config = text_format.Parse("""
... as for estimator ...
metrics_specs {
output_names: ["<keras-output-layer>"]
# Add metrics here.
}
... as for estimator ...
""", tfma.EvalConfig())
Làm cách nào để thiết lập TFMA để hoạt động với các dự đoán được tính toán trước (tức là mô hình bất khả tri)? ( TFRecord và tf.Example )
Để định cấu hình TFMA hoạt động với các dự đoán được tính toán trước, tfma.PredictExtractor mặc định phải bị tắt và tfma.InputExtractor phải được định cấu hình để phân tích các dự đoán cùng với các tính năng đầu vào khác. Điều này được thực hiện bằng cách định cấu hình tfma.ModelSpec với tên của khóa tính năng được sử dụng cho các dự đoán cùng với nhãn và trọng số.
Sau đây là một thiết lập ví dụ:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
prediction_key: "<prediction-key>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
Xem số liệu để biết thêm thông tin về số liệu có thể được định cấu hình.
Lưu ý rằng mặc dù tfma.ModelSpec đang được định cấu hình nhưng một mô hình không thực sự được sử dụng (tức là không có tfma.EvalSharedModel ). Lệnh gọi chạy phân tích mô hình có thể trông như sau:
eval_result = tfma.run_model_analysis(
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location="/path/to/file/containing/tfrecords",
output_path="/path/for/metrics_for_slice_proto")
Làm cách nào để thiết lập TFMA để hoạt động với các dự đoán được tính toán trước (tức là mô hình bất khả tri)? ( pd.DataFrame )
Đối với các tập dữ liệu nhỏ có thể vừa với bộ nhớ, một giải pháp thay thế cho TFRecord là pandas.DataFrame s. TFMA có thể hoạt động trên pandas.DataFrame bằng cách sử dụng API tfma.analyze_raw_data . Để biết giải thích về tfma.MetricsSpec và tfma.SlicingSpec , hãy xem hướng dẫn thiết lập . Xem số liệu để biết thêm thông tin về số liệu có thể được định cấu hình.
Sau đây là một thiết lập ví dụ:
# Run in a Jupyter Notebook.
df_data = ... # your pd.DataFrame
eval_config = text_format.Parse("""
model_specs {
label_key: 'label'
prediction_key: 'prediction'
}
metrics_specs {
metrics { class_name: "AUC" }
metrics { class_name: "ConfusionMatrixPlot" }
}
slicing_specs {}
slicing_specs {
feature_keys: 'language'
}
""", config.EvalConfig())
eval_result = tfma.analyze_raw_data(df_data, eval_config)
tfma.view.render_slicing_metrics(eval_result)
Số liệu
Những loại số liệu nào được hỗ trợ?
TFMA hỗ trợ nhiều số liệu khác nhau bao gồm:
- số liệu hồi quy
- số liệu phân loại nhị phân
- số liệu phân loại nhiều lớp/đa nhãn
- số liệu trung bình vi mô / trung bình vĩ mô
- số liệu dựa trên truy vấn/xếp hạng
Các số liệu từ mô hình nhiều đầu ra có được hỗ trợ không?
Đúng. Xem hướng dẫn về số liệu để biết thêm chi tiết.
Các số liệu từ nhiều mô hình có được hỗ trợ không?
Đúng. Xem hướng dẫn về số liệu để biết thêm chi tiết.
Cài đặt số liệu (tên, v.v.) có thể được tùy chỉnh không?
Đúng. Cài đặt số liệu có thể được tùy chỉnh (ví dụ: đặt ngưỡng cụ thể, v.v.) bằng cách thêm cài đặt config vào cấu hình số liệu. Xem hướng dẫn số liệu để biết thêm chi tiết.
Các số liệu tùy chỉnh có được hỗ trợ không?
Đúng. Bằng cách viết triển khai tf.keras.metrics.Metric tùy chỉnh hoặc bằng cách viết triển khai beam.CombineFn tùy chỉnh. Hướng dẫn về số liệu có nhiều chi tiết hơn.
Những loại số liệu nào không được hỗ trợ?
Miễn là số liệu của bạn có thể được tính bằng cách sử dụng beam.CombineFn thì không có hạn chế nào về loại số liệu có thể được tính toán dựa trên tfma.metrics.Metric . Nếu làm việc với số liệu bắt nguồn từ tf.keras.metrics.Metric thì phải đáp ứng các tiêu chí sau:
- Có thể tính toán số liệu thống kê đầy đủ cho số liệu trên từng ví dụ một cách độc lập, sau đó kết hợp các số liệu thống kê đầy đủ này bằng cách thêm chúng trên tất cả các ví dụ và xác định giá trị số liệu chỉ từ các số liệu thống kê đầy đủ này.
- Ví dụ: để đảm bảo độ chính xác, số liệu thống kê đầy đủ là "tổng số chính xác" và "tổng số ví dụ". Có thể tính toán hai số này cho từng ví dụ riêng lẻ và cộng chúng lại thành một nhóm ví dụ để có được giá trị phù hợp cho các ví dụ đó. Độ chính xác cuối cùng có thể được tính toán bằng cách sử dụng "tổng số ví dụ đúng/tổng số".
Tiện ích bổ sung
Tôi có thể sử dụng TFMA để đánh giá tính công bằng hoặc sai lệch trong mô hình của mình không?
TFMA bao gồm tiện ích bổ sung FairnessIndicators cung cấp các số liệu sau xuất để đánh giá tác động của sai lệch ngoài ý muốn trong các mô hình phân loại.
Tùy chỉnh
Nếu tôi cần tùy chỉnh thêm thì sao?
TFMA rất linh hoạt và cho phép bạn tùy chỉnh hầu hết tất cả các phần của quy trình bằng cách sử dụng Extractors , Evaluators và/hoặc Writers tùy chỉnh. Những điều trừu tượng này sẽ được thảo luận chi tiết hơn trong tài liệu kiến trúc .
Khắc phục sự cố, gỡ lỗi và nhận trợ giúp
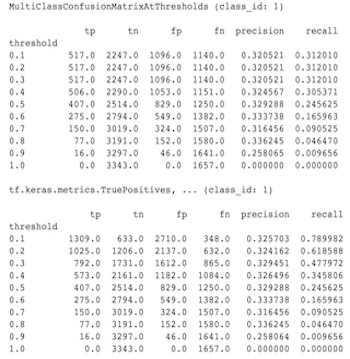
Tại sao số liệu MultiClassConfusionMatrix không khớp với số liệu ConfusionMatrix nhị phân
Đây thực sự là những tính toán khác nhau. Quá trình nhị phân hóa thực hiện so sánh cho từng ID lớp một cách độc lập (tức là dự đoán cho từng lớp được so sánh riêng với các ngưỡng được cung cấp). Trong trường hợp này, có thể hai hoặc nhiều lớp đều chỉ ra rằng chúng khớp với dự đoán vì giá trị dự đoán của chúng lớn hơn ngưỡng (điều này sẽ còn rõ ràng hơn ở các ngưỡng thấp hơn). Trong trường hợp ma trận nhầm lẫn nhiều lớp, vẫn chỉ có một giá trị dự đoán đúng và nó khớp với giá trị thực tế hoặc không. Ngưỡng chỉ được sử dụng để buộc dự đoán không khớp với lớp nào nếu nó nhỏ hơn ngưỡng. Ngưỡng càng cao thì dự đoán của lớp nhị phân càng khó khớp. Tương tự như vậy, ngưỡng càng thấp thì các dự đoán của lớp nhị phân càng dễ khớp. Điều này có nghĩa là ở các ngưỡng > 0,5, các giá trị nhị phân và các giá trị ma trận đa lớp sẽ được căn chỉnh gần hơn và ở các ngưỡng < 0,5, chúng sẽ cách xa nhau hơn.
Ví dụ: giả sử chúng ta có 10 lớp trong đó lớp 2 được dự đoán với xác suất là 0,8, nhưng lớp thực tế là lớp 1 có xác suất là 0,15. Nếu bạn nhị phân hóa trên lớp 1 và sử dụng ngưỡng 0,1 thì lớp 1 sẽ được coi là đúng (0,15 > 0,1) nên sẽ được tính là TP. Tuy nhiên, đối với trường hợp nhiều lớp, lớp 2 sẽ được coi là đúng (0,8 > 0.1) và vì lớp 1 là thực tế nên nó sẽ được tính là FN. Bởi vì ở các ngưỡng thấp hơn, nhiều giá trị hơn sẽ được coi là dương, nên nhìn chung sẽ có số lượng TP và FP cao hơn đối với ma trận nhầm lẫn nhị phân so với ma trận nhầm lẫn nhiều lớp và tương tự TN và FN cũng thấp hơn.
Sau đây là ví dụ về sự khác biệt được quan sát giữa MultiClassConfusionMatrixAtThresholds và số lượng tương ứng từ quá trình nhị phân hóa một trong các lớp.
Tại sao số liệu Precision@1 và Recall@1 của tôi có cùng giá trị?
Ở giá trị k cao nhất là 1 độ chính xác và thu hồi là như nhau. Độ chính xác bằng TP / (TP + FP) và thu hồi bằng TP / (TP + FN) . Dự đoán hàng đầu luôn dương và sẽ khớp hoặc không khớp với nhãn. Nói cách khác, với N ví dụ, TP + FP = N Tuy nhiên, nếu nhãn không khớp với dự đoán hàng đầu thì điều này cũng hàm ý rằng một dự đoán k không phải top 1 đã được khớp và với k top được đặt thành 1 thì tất cả các dự đoán không phải top 1 sẽ là 0. Điều này ngụ ý FN phải là (N - TP) hoặc N = TP + FN . Kết quả cuối cùng là precision@1 = TP / N = recall@1 . Lưu ý rằng điều này chỉ áp dụng khi có một nhãn cho mỗi ví dụ, không áp dụng cho nhiều nhãn.
Tại sao số liệu Mean_label và Mean_prediction của tôi luôn là 0,5?
Điều này rất có thể xảy ra do số liệu được định cấu hình cho vấn đề phân loại nhị phân, nhưng mô hình đang đưa ra xác suất cho cả hai lớp thay vì chỉ một lớp. Điều này thường xảy ra khi sử dụng API phân loại của tenorflow . Giải pháp là chọn lớp mà bạn muốn dựa trên các dự đoán và sau đó nhị phân hóa trên lớp đó. Ví dụ:
eval_config = text_format.Parse("""
...
metrics_specs {
binarize { class_ids: { values: [0] } }
metrics { class_name: "MeanLabel" }
metrics { class_name: "MeanPrediction" }
...
}
...
""", config.EvalConfig())
Làm cách nào để diễn giải MultiLabelConfusionMatrixPlot?
Với một nhãn cụ thể, MultiLabelConfusionMatrixPlot (và MultiLabelConfusionMatrix ) có liên quan có thể được sử dụng để so sánh kết quả của các nhãn khác và dự đoán của chúng khi nhãn được chọn thực sự đúng. Ví dụ: giả sử chúng ta có ba lớp bird , plane và superman và chúng ta đang phân loại các hình ảnh để cho biết liệu chúng có chứa một hoặc nhiều lớp trong số này hay không. MultiLabelConfusionMatrix sẽ tính toán tích Descartes của từng lớp thực tế với các lớp khác (được gọi là lớp dự đoán). Lưu ý rằng mặc dù ghép nối là (actual, predicted) , lớp predicted không nhất thiết ngụ ý một dự đoán tích cực, nó chỉ đại diện cho cột được dự đoán trong ma trận thực tế và dự đoán. Ví dụ: giả sử chúng ta đã tính các ma trận sau:
(bird, bird) -> { tp: 6, fp: 0, fn: 2, tn: 0}
(bird, plane) -> { tp: 2, fp: 2, fn: 2, tn: 2}
(bird, superman) -> { tp: 1, fp: 1, fn: 4, tn: 2}
(plane, bird) -> { tp: 3, fp: 1, fn: 1, tn: 3}
(plane, plane) -> { tp: 4, fp: 0, fn: 4, tn: 0}
(plane, superman) -> { tp: 1, fp: 3, fn: 3, tn: 1}
(superman, bird) -> { tp: 3, fp: 2, fn: 2, tn: 2}
(superman, plane) -> { tp: 2, fp: 3, fn: 2, tn: 2}
(superman, superman) -> { tp: 4, fp: 0, fn: 5, tn: 0}
num_examples: 20
MultiLabelConfusionMatrixPlot có ba cách để hiển thị dữ liệu này. Trong mọi trường hợp, cách đọc bảng là theo từng hàng theo quan điểm của lớp thực tế.
1) Tổng số dự đoán
Trong trường hợp này, đối với một hàng nhất định (tức là lớp thực tế), số lượng TP + FP cho các lớp khác là bao nhiêu. Đối với số lượng ở trên, màn hình của chúng tôi sẽ như sau:
| Dự đoán chim | Máy bay dự đoán | Siêu nhân dự đoán | |
|---|---|---|---|
| chim thực tế | 6 | 4 | 2 |
| Mặt phẳng thực tế | 4 | 4 | 4 |
| siêu nhân thực tế | 5 | 5 | 4 |
Khi những bức ảnh thực sự có một bird chúng tôi đã dự đoán chính xác 6 con trong số đó. Đồng thời chúng ta cũng dự đoán plane (đúng hoặc sai) 4 lần và superman (đúng hoặc sai) 2 lần.
2) Số dự đoán sai
Trong trường hợp này, đối với một hàng nhất định (tức là lớp thực tế), số lượng FP đối với các lớp khác là bao nhiêu. Đối với số lượng ở trên, màn hình của chúng tôi sẽ như sau:
| Dự đoán chim | Máy bay dự đoán | dự đoán siêu nhân | |
|---|---|---|---|
| chim thực tế | 0 | 2 | 1 |
| Mặt phẳng thực tế | 1 | 0 | 3 |
| siêu nhân thực tế | 2 | 3 | 0 |
Khi những bức ảnh thực sự có một bird chúng tôi đã dự đoán sai plane 2 lần và superman 1 lần.
3) Số âm tính giả
Trong trường hợp này, đối với một hàng nhất định (tức là lớp thực tế), số FN cho các lớp khác là bao nhiêu. Đối với số lượng ở trên, màn hình của chúng tôi sẽ như sau:
| Dự đoán chim | Máy bay dự đoán | dự đoán siêu nhân | |
|---|---|---|---|
| chim thực tế | 2 | 2 | 4 |
| Mặt phẳng thực tế | 1 | 4 | 3 |
| siêu nhân thực tế | 2 | 2 | 5 |
Khi những bức ảnh thực sự có một bird chúng tôi đã không thể đoán được nó 2 lần. Đồng thời, chúng tôi đã thất bại trong việc dự đoán plane 2 lần và superman 4 lần.
Tại sao tôi gặp lỗi không tìm thấy khóa dự đoán?
Một số mô hình đưa ra dự đoán của họ dưới dạng từ điển. Ví dụ: công cụ ước tính TF cho bài toán phân loại nhị phân sẽ xuất ra một từ điển chứa probabilities , class_ids , v.v. Trong hầu hết các trường hợp, TFMA có các giá trị mặc định để tìm các tên khóa được sử dụng phổ biến như predictions , probabilities , v.v. Tuy nhiên, nếu mô hình của bạn được tùy chỉnh nhiều thì nó có thể các khóa đầu ra dưới tên mà TFMA không biết. Trong những trường hợp này, cài đặt prediciton_key phải được thêm vào tfma.ModelSpec để xác định tên của khóa mà đầu ra được lưu trữ bên dưới.