
Giới thiệu
TFX là nền tảng máy học (ML) quy mô sản xuất của Google dựa trên TensorFlow. Nó cung cấp khung cấu hình và các thư viện dùng chung để tích hợp các thành phần phổ biến cần thiết nhằm xác định, khởi chạy và giám sát hệ thống máy học của bạn.
TFX 1.0
Chúng tôi vui mừng thông báo về tính khả dụng của TFX 1.0.0 . Đây là bản phát hành hậu beta đầu tiên của TFX, cung cấp các tạo phẩm và API công khai ổn định. Bạn có thể yên tâm rằng các đường dẫn TFX trong tương lai của bạn sẽ tiếp tục hoạt động sau khi nâng cấp trong phạm vi tương thích được xác định trong RFC này.
Cài đặt

![]()
pip install tfx
Gói hàng đêm
TFX cũng lưu trữ các gói hàng đêm tại https://pypi-nightly.tensorflow.org trên Google Cloud. Để cài đặt gói hàng đêm mới nhất, vui lòng sử dụng lệnh sau:
pip install --extra-index-url https://pypi-nightly.tensorflow.org/simple --pre tfx
Điều này sẽ cài đặt các gói hàng đêm cho các phần phụ thuộc chính của TFX như Phân tích mô hình TensorFlow (TFMA), Xác thực dữ liệu TensorFlow (TFDV), Chuyển đổi TensorFlow (TFT), Thư viện chia sẻ cơ bản TFX (TFX-BSL), Siêu dữ liệu ML (MLMD).
Giới thiệu về TFX
TFX là một nền tảng để xây dựng và quản lý quy trình công việc ML trong môi trường sản xuất. TFX cung cấp những điều sau:
Bộ công cụ để xây dựng đường ống ML. Đường dẫn TFX cho phép bạn điều phối quy trình làm việc ML của mình trên một số nền tảng, chẳng hạn như: Apache Airflow, Apache Beam và Kubeflow Pipelines.
Một tập hợp các thành phần tiêu chuẩn mà bạn có thể sử dụng như một phần của quy trình hoặc như một phần của tập lệnh đào tạo ML của mình. Các thành phần tiêu chuẩn TFX cung cấp chức năng đã được chứng minh để giúp bạn bắt đầu xây dựng quy trình ML một cách dễ dàng.
Các thư viện cung cấp chức năng cơ bản cho nhiều thành phần tiêu chuẩn. Bạn có thể sử dụng thư viện TFX để thêm chức năng này vào các thành phần tùy chỉnh của riêng mình hoặc sử dụng chúng một cách riêng biệt.
TFX là bộ công cụ học máy quy mô sản xuất của Google dựa trên TensorFlow. Nó cung cấp khung cấu hình và các thư viện dùng chung để tích hợp các thành phần phổ biến cần thiết nhằm xác định, khởi chạy và giám sát hệ thống máy học của bạn.
Thành phần tiêu chuẩn TFX
Đường dẫn TFX là một chuỗi các thành phần triển khai đường dẫn ML được thiết kế đặc biệt cho các tác vụ machine learning hiệu suất cao và có thể mở rộng. Điều đó bao gồm lập mô hình, đào tạo, phục vụ suy luận và quản lý việc triển khai cho các mục tiêu trực tuyến, di động gốc và JavaScript.
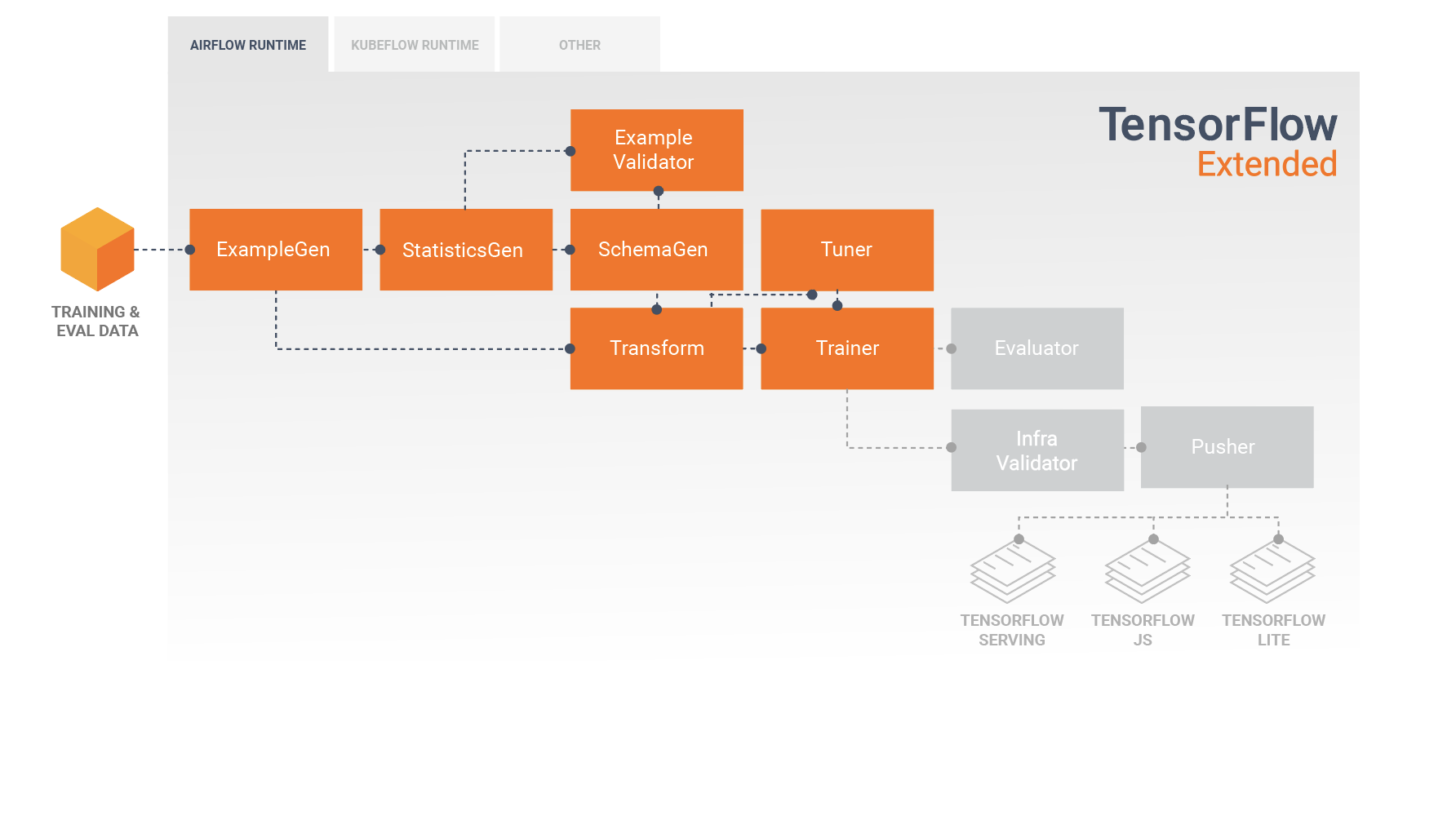
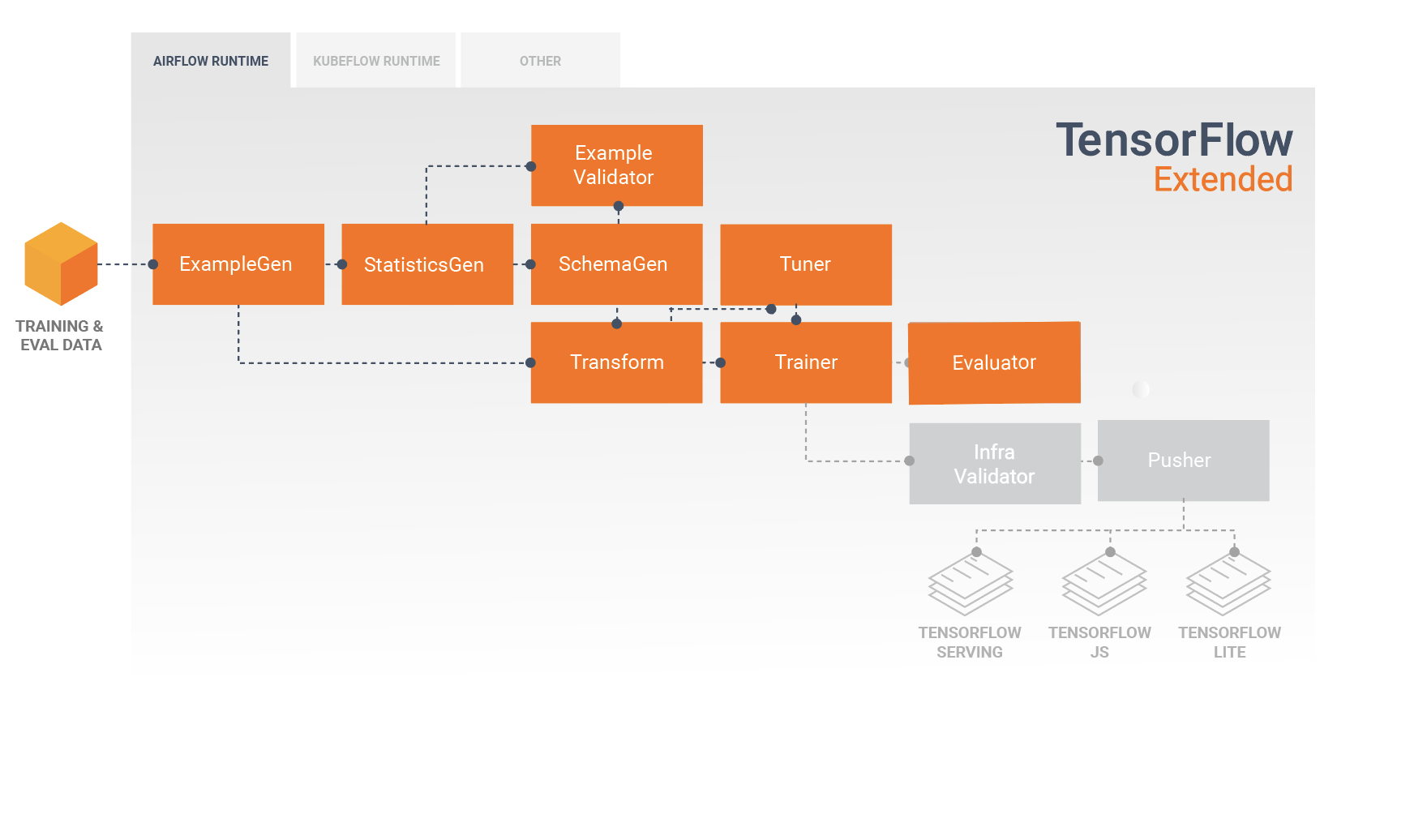
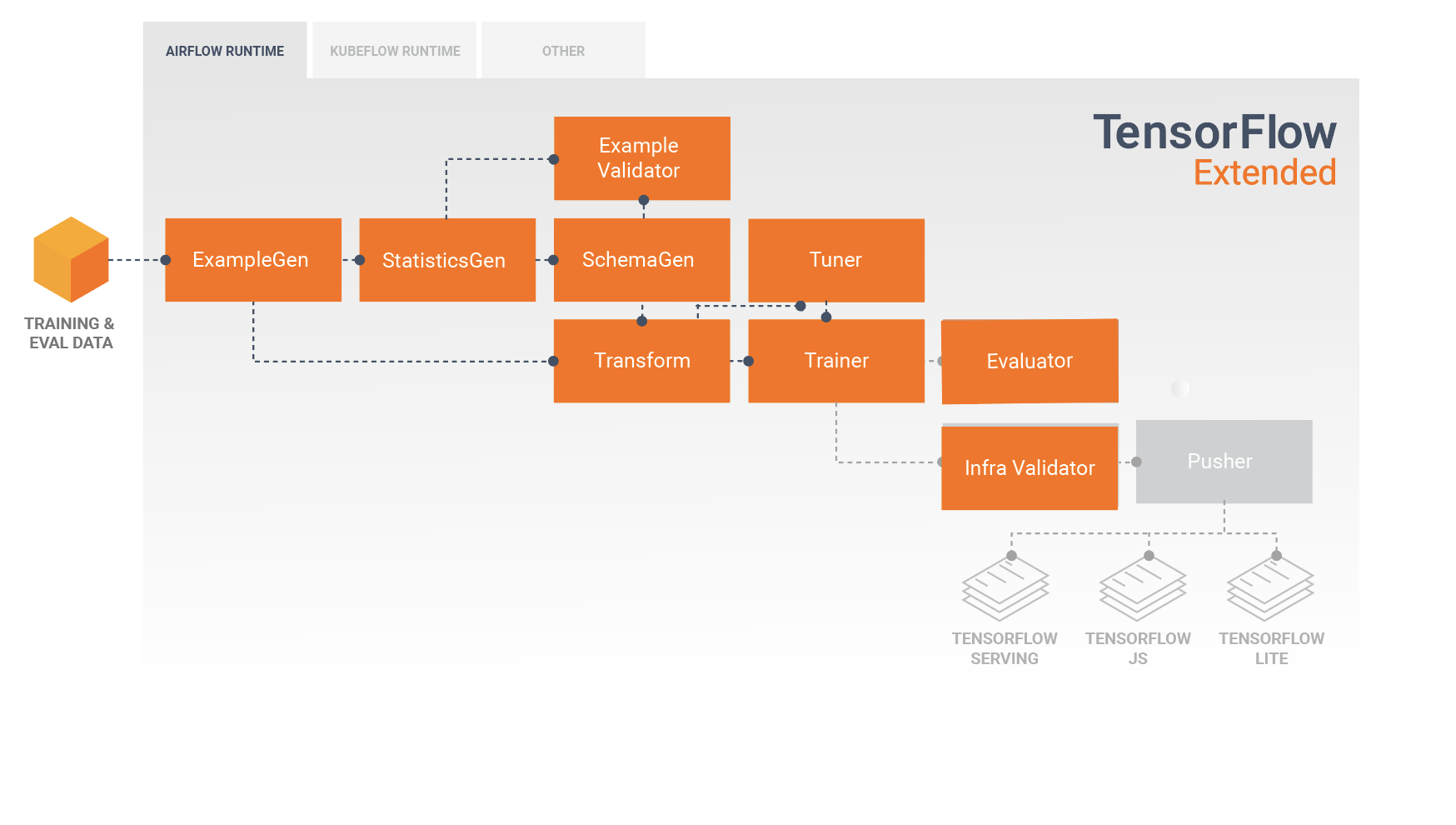
Một đường dẫn TFX thường bao gồm các thành phần sau:
Ví dụGen là thành phần đầu vào ban đầu của một quy trình nhập và phân chia tập dữ liệu đầu vào một cách tùy ý.
StatsGen tính toán số liệu thống kê cho tập dữ liệu.
SchemaGen kiểm tra số liệu thống kê và tạo lược đồ dữ liệu.
Ví dụValidator tìm kiếm các điểm bất thường và giá trị bị thiếu trong tập dữ liệu.
Transform thực hiện kỹ thuật tính năng trên tập dữ liệu.
Huấn luyện viên huấn luyện người mẫu.
Bộ điều chỉnh điều chỉnh các siêu tham số của mô hình.
Trình đánh giá thực hiện phân tích sâu về kết quả đào tạo và giúp bạn xác thực các mô hình đã xuất của mình, đảm bảo rằng chúng "đủ tốt" để đưa vào sản xuất.
InfraValidator kiểm tra mô hình thực sự có thể phục vụ được từ cơ sở hạ tầng và ngăn chặn việc đẩy mô hình xấu.
Pusher triển khai mô hình trên cơ sở hạ tầng phục vụ.
BulkInferrer thực hiện xử lý hàng loạt trên một mô hình có yêu cầu suy luận chưa được gắn nhãn.
Sơ đồ này minh họa luồng dữ liệu giữa các thành phần này:
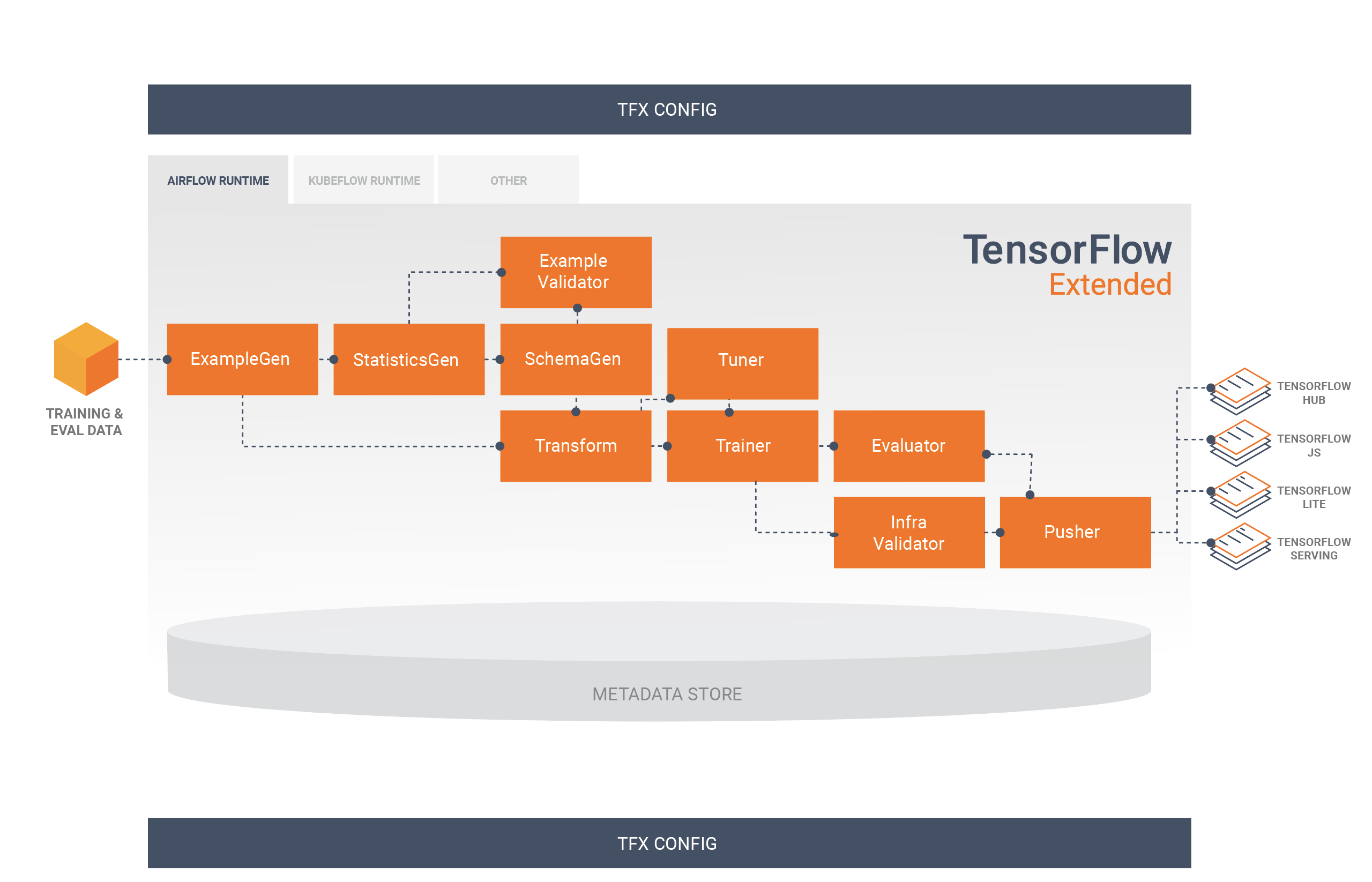
Thư viện TFX
TFX bao gồm cả thư viện và các thành phần đường dẫn. Sơ đồ này minh họa mối quan hệ giữa các thư viện TFX và các thành phần đường dẫn:
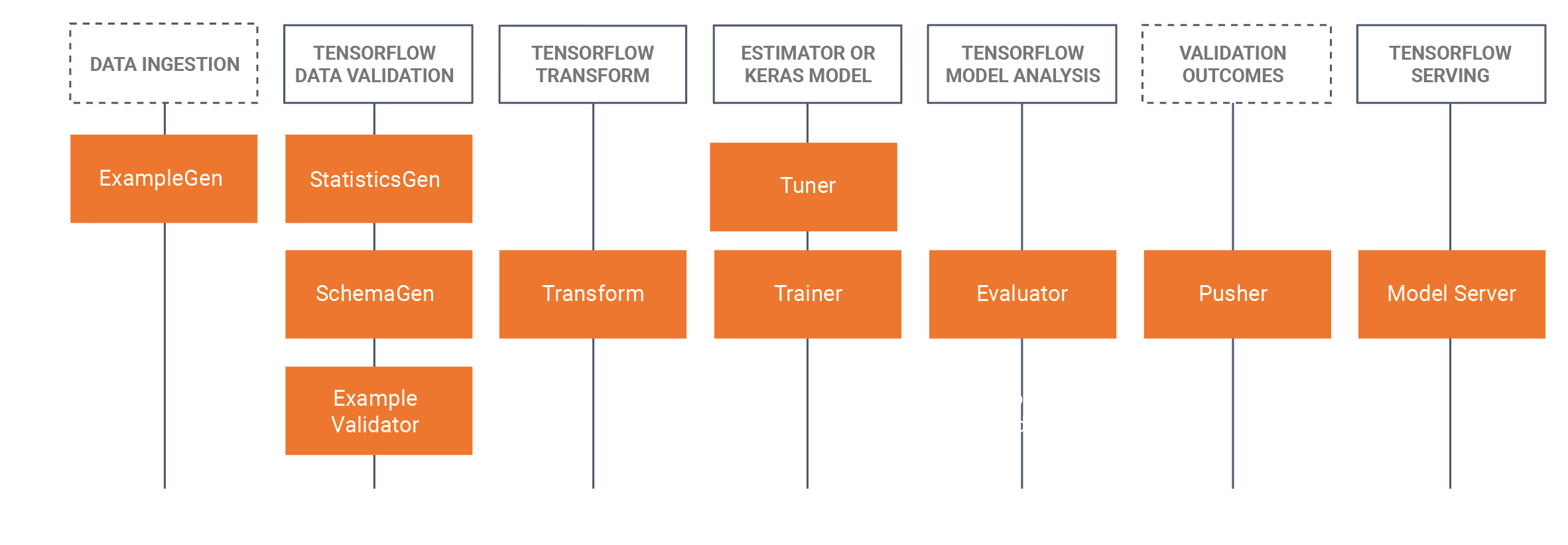
TFX cung cấp một số gói Python là thư viện được sử dụng để tạo các thành phần đường dẫn. Bạn sẽ sử dụng các thư viện này để tạo các thành phần của quy trình để mã của bạn có thể tập trung vào các khía cạnh độc đáo của quy trình.
Thư viện TFX bao gồm:
Xác thực dữ liệu TensorFlow (TFDV) là một thư viện để phân tích và xác thực dữ liệu máy học. Nó được thiết kế để có khả năng mở rộng cao và hoạt động tốt với TensorFlow và TFX. TFDV bao gồm:
- Tính toán có thể mở rộng số liệu thống kê tóm tắt của dữ liệu đào tạo và kiểm tra.
- Tích hợp với trình xem để phân phối và thống kê dữ liệu, cũng như so sánh các khía cạnh của các cặp tập dữ liệu (Các khía cạnh).
- Tạo lược đồ dữ liệu tự động để mô tả những kỳ vọng về dữ liệu như các giá trị, phạm vi và từ vựng bắt buộc.
- Trình xem lược đồ để giúp bạn kiểm tra lược đồ.
- Phát hiện bất thường để xác định các điểm bất thường, chẳng hạn như các tính năng bị thiếu, giá trị nằm ngoài phạm vi hoặc loại tính năng sai, v.v.
- Trình xem các điểm bất thường để bạn có thể xem những tính năng nào có điểm bất thường và tìm hiểu thêm để sửa chúng.
TensorFlow Transform (TFT) là một thư viện để xử lý trước dữ liệu với TensorFlow. Biến đổi TensorFlow rất hữu ích cho dữ liệu yêu cầu vượt qua đầy đủ, chẳng hạn như:
- Chuẩn hóa giá trị đầu vào bằng giá trị trung bình và độ lệch chuẩn.
- Chuyển đổi chuỗi thành số nguyên bằng cách tạo từ vựng trên tất cả các giá trị đầu vào.
- Chuyển đổi số float thành số nguyên bằng cách gán chúng cho các nhóm dựa trên phân phối dữ liệu được quan sát.
TensorFlow được sử dụng để đào tạo các mô hình với TFX. Nó nhập dữ liệu đào tạo và mã mô hình hóa rồi tạo ra kết quả SavingModel. Nó cũng tích hợp một quy trình kỹ thuật tính năng được tạo bởi TensorFlow Transform để xử lý trước dữ liệu đầu vào.
KerasTuner được sử dụng để điều chỉnh các siêu tham số cho mô hình.
Phân tích mô hình TensorFlow (TFMA) là một thư viện để đánh giá các mô hình TensorFlow. Nó được sử dụng cùng với TensorFlow để tạo EvalSavedModel, trở thành cơ sở để phân tích. Nó cho phép người dùng đánh giá mô hình của họ trên lượng lớn dữ liệu theo cách phân tán, sử dụng cùng các số liệu được xác định trong trình huấn luyện của họ. Các số liệu này có thể được tính toán trên các phần dữ liệu khác nhau và được hiển thị trong sổ ghi chép Jupyter.
Siêu dữ liệu TensorFlow (TFMD) cung cấp các biểu diễn tiêu chuẩn cho siêu dữ liệu hữu ích khi đào tạo các mô hình học máy bằng TensorFlow. Siêu dữ liệu có thể được tạo thủ công hoặc tự động trong quá trình phân tích dữ liệu đầu vào và có thể được sử dụng để xác thực, khám phá và chuyển đổi dữ liệu. Các định dạng tuần tự hóa siêu dữ liệu bao gồm:
- Một lược đồ mô tả dữ liệu dạng bảng (ví dụ: tf.Examples).
- Một tập hợp các số liệu thống kê tóm tắt về các bộ dữ liệu đó.
Siêu dữ liệu ML (MLMD) là một thư viện để ghi và truy xuất siêu dữ liệu được liên kết với quy trình làm việc của nhà phát triển ML và nhà khoa học dữ liệu. Thông thường siêu dữ liệu sử dụng các biểu diễn TFMD. MLMD quản lý tính bền vững bằng cách sử dụng SQL-Lite , MySQL và các kho lưu trữ dữ liệu tương tự khác.
Công nghệ hỗ trợ
Yêu cầu
- Apache Beam là một mô hình thống nhất, mã nguồn mở để xác định cả các đường ống xử lý song song dữ liệu theo lô và truyền trực tuyến. TFX sử dụng Apache Beam để triển khai các đường dẫn song song dữ liệu. Sau đó, quy trình này được thực thi bởi một trong các back-end xử lý phân tán được hỗ trợ của Beam, bao gồm Apache Flink, Apache Spark, Google Cloud Dataflow và các back-end khác.
Không bắt buộc
Các công cụ điều phối như Apache Airflow và Kubeflow giúp việc định cấu hình, vận hành, giám sát và duy trì quy trình ML dễ dàng hơn.
Apache Airflow là một nền tảng để lập trình tác giả, lên lịch và giám sát quy trình công việc. TFX sử dụng Airflow để tạo các quy trình làm việc dưới dạng biểu đồ tuần hoàn có hướng (DAG) của các nhiệm vụ. Bộ lập lịch Airflow thực thi các nhiệm vụ trên một loạt công nhân trong khi tuân theo các phần phụ thuộc đã chỉ định. Các tiện ích dòng lệnh phong phú giúp thực hiện các ca phẫu thuật phức tạp trên DAG một cách nhanh chóng. Giao diện người dùng phong phú giúp dễ dàng hình dung các quy trình đang chạy trong sản xuất, theo dõi tiến độ và khắc phục sự cố khi cần. Khi quy trình công việc được xác định là mã, chúng sẽ trở nên dễ bảo trì hơn, dễ phiên bản hơn, có thể kiểm tra được và mang tính cộng tác hơn.
Kubeflow chuyên tâm giúp việc triển khai quy trình máy học (ML) trên Kubernetes trở nên đơn giản, di động và có thể mở rộng. Mục tiêu của Kubeflow không phải là tạo lại các dịch vụ khác mà là cung cấp một cách đơn giản để triển khai các hệ thống nguồn mở tốt nhất cho ML cho các cơ sở hạ tầng đa dạng. Kubeflow Pipelines cho phép kết hợp và thực thi các quy trình công việc có thể tái tạo trên Kubeflow, được tích hợp với trải nghiệm dựa trên sổ tay và thử nghiệm. Các dịch vụ của Kubeflow Pipelines trên Kubernetes bao gồm kho lưu trữ Siêu dữ liệu được lưu trữ, công cụ điều phối dựa trên bộ chứa, máy chủ sổ tay và giao diện người dùng để giúp người dùng phát triển, chạy và quản lý các quy trình ML phức tạp trên quy mô lớn. Kubeflow Pipelines SDK cho phép tạo và chia sẻ các thành phần cũng như thành phần của quy trình theo chương trình.
Tính di động và khả năng tương tác
TFX được thiết kế để có thể di động tới nhiều môi trường và khung điều phối, bao gồm Apache Airflow , Apache Beam và Kubeflow . Nó cũng có thể di chuyển sang các nền tảng điện toán khác nhau, bao gồm cả nền tảng tại chỗ và nền tảng đám mây như Google Cloud Platform (GCP) . Đặc biệt, TFX tương tác với các dịch vụ GCP được quản lý trên máy chủ, chẳng hạn như Nền tảng đào tạo và dự đoán trên nền tảng đám mây AI cũng như Luồng dữ liệu đám mây để xử lý dữ liệu phân tán cho một số khía cạnh khác của vòng đời ML.
Mô hình so với SavingModel
Người mẫu
Mô hình là đầu ra của quá trình đào tạo. Đó là bản ghi tuần tự về các trọng số đã được học trong quá trình luyện tập. Những trọng số này sau đó có thể được sử dụng để tính toán dự đoán cho các ví dụ đầu vào mới. Đối với TFX và TensorFlow, 'model' đề cập đến các điểm kiểm tra chứa trọng số đã học cho đến thời điểm đó.
Lưu ý rằng 'mô hình' cũng có thể đề cập đến định nghĩa của biểu đồ tính toán TensorFlow (tức là tệp Python) thể hiện cách tính toán dự đoán. Hai giác quan có thể được sử dụng thay thế cho nhau tùy theo ngữ cảnh.
Đã lưuMô hình
- SavingModel là gì : một sự tuần tự hóa phổ quát, trung lập về ngôn ngữ, kín đáo, có thể phục hồi của mô hình TensorFlow.
- Tại sao nó quan trọng : Nó cho phép các hệ thống cấp cao hơn sản xuất, chuyển đổi và sử dụng các mô hình TensorFlow bằng cách sử dụng một sự trừu tượng hóa duy nhất.
SavingModel là định dạng tuần tự hóa được đề xuất để phục vụ mô hình TensorFlow trong sản xuất hoặc xuất mô hình được đào tạo cho ứng dụng JavaScript hoặc thiết bị di động gốc. Ví dụ: để biến một mô hình thành dịch vụ REST để đưa ra dự đoán, bạn có thể tuần tự hóa mô hình đó dưới dạng SavingModel và phân phối mô hình đó bằng cách sử dụng TensorFlow Serve. Xem Cung cấp Mô hình TensorFlow để biết thêm thông tin.
Lược đồ
Một số thành phần TFX sử dụng mô tả dữ liệu đầu vào của bạn được gọi là lược đồ . Lược đồ này là một thể hiện của lược đồ.proto . Lược đồ là một loại bộ đệm giao thức , thường được gọi là "protobuf". Lược đồ có thể chỉ định loại dữ liệu cho các giá trị đối tượng, liệu một đối tượng có phải có trong tất cả các ví dụ hay không, phạm vi giá trị được phép và các thuộc tính khác. Một trong những lợi ích của việc sử dụng Xác thực dữ liệu TensorFlow (TFDV) là nó sẽ tự động tạo một lược đồ bằng cách suy ra các loại, danh mục và phạm vi từ dữ liệu huấn luyện.
Đây là một đoạn trích từ một protobuf lược đồ:
...
feature {
name: "age"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
feature {
name: "capital-gain"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
...
Các thành phần sau đây sử dụng lược đồ:
- Xác thực dữ liệu TensorFlow
- Biến đổi dòng chảy Tenor
Trong một đường dẫn TFX điển hình, Xác thực dữ liệu TensorFlow tạo ra một lược đồ được các thành phần khác sử dụng.
Phát triển với TFX
TFX cung cấp nền tảng mạnh mẽ cho mọi giai đoạn của dự án machine learning, từ nghiên cứu, thử nghiệm và phát triển trên máy cục bộ của bạn cho đến quá trình triển khai. Để tránh trùng lặp mã và loại bỏ khả năng đào tạo/phục vụ sai lệch, bạn nên triển khai quy trình TFX cho cả đào tạo mô hình và triển khai các mô hình được đào tạo, đồng thời sử dụng các thành phần Biến đổi tận dụng thư viện Biến đổi TensorFlow cho cả đào tạo và suy luận. Bằng cách đó, bạn sẽ sử dụng cùng một mã phân tích và tiền xử lý giống nhau, đồng thời tránh được sự khác biệt giữa dữ liệu được sử dụng để đào tạo và dữ liệu được cung cấp cho các mô hình được đào tạo của bạn trong sản xuất, cũng như hưởng lợi từ việc viết mã đó một lần.
Khám phá, trực quan hóa và làm sạch dữ liệu
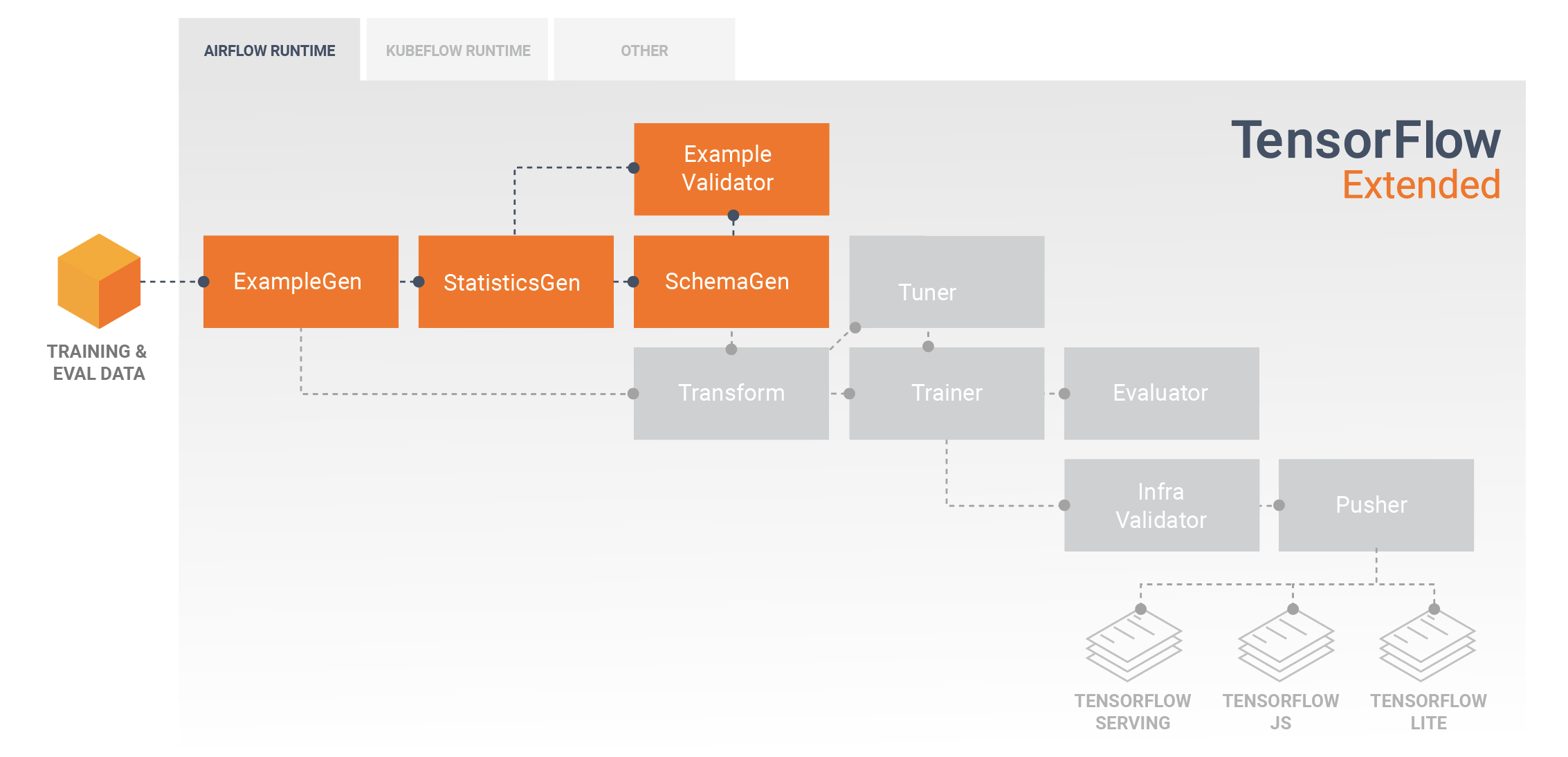
Đường dẫn TFX thường bắt đầu bằng thành phần exampleGen , chấp nhận dữ liệu đầu vào và định dạng dữ liệu đó dưới dạng tf.Examples. Thông thường, việc này được thực hiện sau khi dữ liệu được chia thành các tập dữ liệu huấn luyện và đánh giá để thực sự có hai bản sao của các thành phần exampleGen, mỗi bản dành cho đào tạo và đánh giá. Tiếp theo điều này thường là thành phần StatsGen và thành phần SchemaGen , thành phần này sẽ kiểm tra dữ liệu của bạn và suy ra lược đồ dữ liệu và số liệu thống kê. Lược đồ và số liệu thống kê sẽ được sử dụng bởi thành phần SampleValidator . Thành phần này sẽ tìm kiếm các điểm bất thường, giá trị bị thiếu và loại dữ liệu không chính xác trong dữ liệu của bạn. Tất cả các thành phần này tận dụng khả năng của thư viện Xác thực dữ liệu TensorFlow .
Xác thực dữ liệu TensorFlow (TFDV) là một công cụ có giá trị khi thực hiện khám phá ban đầu, trực quan hóa và làm sạch tập dữ liệu của bạn. TFDV kiểm tra dữ liệu của bạn và suy ra các loại, danh mục và phạm vi dữ liệu, sau đó tự động giúp xác định các điểm bất thường và giá trị bị thiếu. Nó cũng cung cấp các công cụ trực quan có thể giúp bạn kiểm tra và hiểu tập dữ liệu của mình. Sau khi quy trình của bạn hoàn tất, bạn có thể đọc siêu dữ liệu từ MLMD và sử dụng các công cụ trực quan hóa của TFDV trong sổ ghi chép Jupyter để phân tích dữ liệu của mình.
Sau quá trình đào tạo và triển khai mô hình ban đầu của bạn, TFDV có thể được sử dụng để giám sát dữ liệu mới từ các yêu cầu suy luận đến các mô hình đã triển khai của bạn và tìm kiếm các điểm bất thường và/hoặc sai lệch. Điều này đặc biệt hữu ích đối với dữ liệu chuỗi thời gian thay đổi theo thời gian do xu hướng hoặc tính thời vụ và có thể giúp thông báo khi có vấn đề về dữ liệu hoặc khi mô hình cần được đào tạo lại về dữ liệu mới.
Trực quan hóa dữ liệu
Sau khi hoàn thành lần chạy dữ liệu đầu tiên thông qua phần quy trình sử dụng TFDV (thường là StatsGen, SchemaGen và Ví dụValidator), bạn có thể hình dung kết quả trong sổ ghi chép kiểu Jupyter. Đối với các lần chạy bổ sung, bạn có thể so sánh các kết quả này khi thực hiện điều chỉnh cho đến khi dữ liệu tối ưu cho mô hình và ứng dụng của bạn.
Trước tiên, bạn sẽ truy vấn Siêu dữ liệu ML (MLMD) để xác định kết quả của việc thực thi các thành phần này, sau đó sử dụng API hỗ trợ trực quan hóa trong TFDV để tạo trực quan hóa trong sổ ghi chép của bạn. Điều này bao gồm tfdv.load_statistics() và tfdv.visualize_statistics() Bằng cách sử dụng hình ảnh trực quan này, bạn có thể hiểu rõ hơn các đặc điểm của tập dữ liệu của mình và nếu cần, hãy sửa đổi theo yêu cầu.
Mô hình phát triển và đào tạo
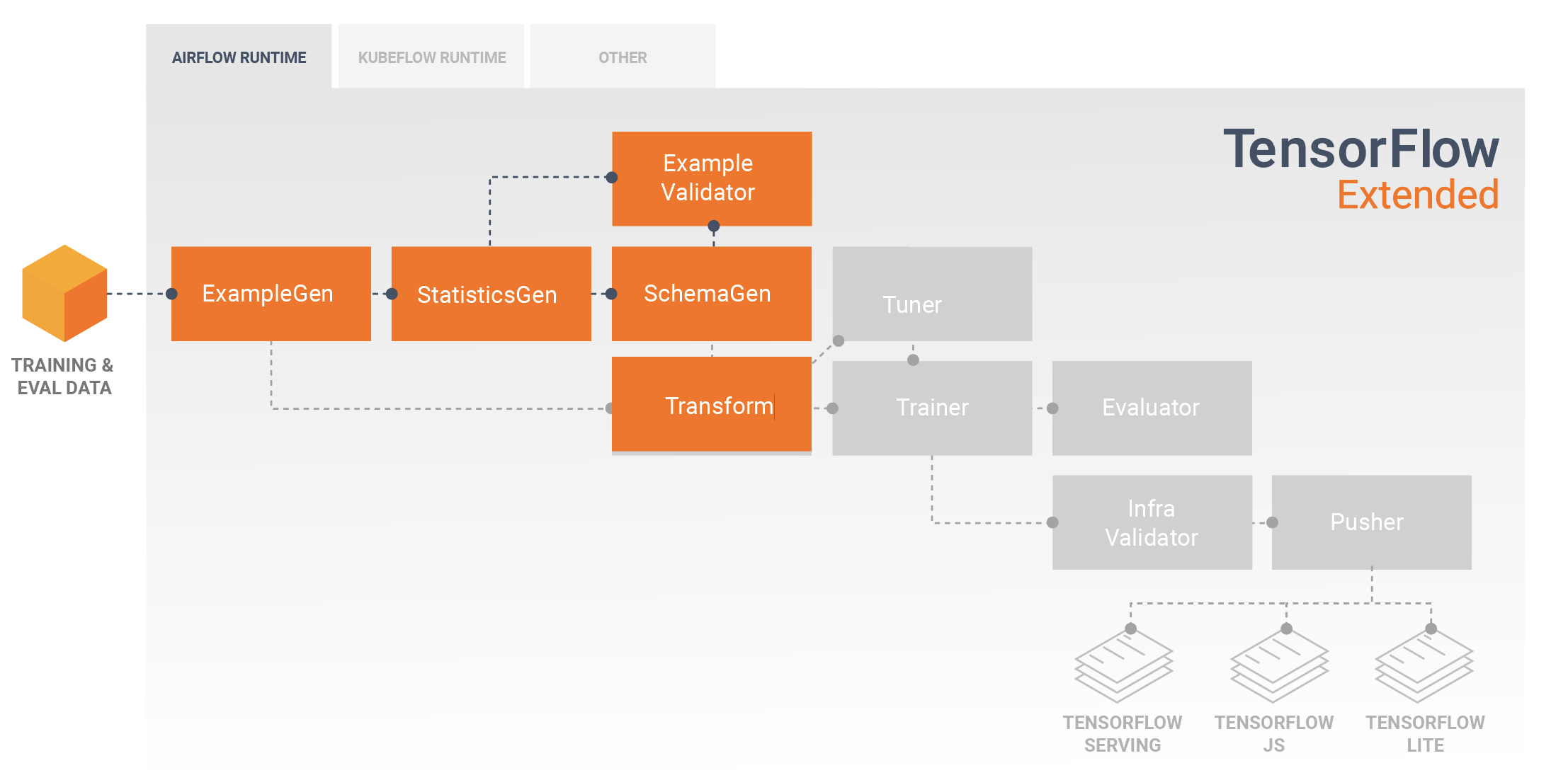
Một quy trình TFX điển hình sẽ bao gồm thành phần Chuyển đổi , thành phần này sẽ thực hiện kỹ thuật tính năng bằng cách tận dụng các khả năng của thư viện Chuyển đổi TensorFlow (TFT) . Thành phần Transform sử dụng lược đồ được tạo bởi thành phần SchemaGen và áp dụng các phép biến đổi dữ liệu để tạo, kết hợp và chuyển đổi các tính năng sẽ được sử dụng để huấn luyện mô hình của bạn. Việc dọn dẹp các giá trị bị thiếu và chuyển đổi các loại cũng nên được thực hiện trong thành phần Biến đổi nếu có khả năng những giá trị này cũng sẽ xuất hiện trong dữ liệu được gửi cho các yêu cầu suy luận. Có một số cân nhắc quan trọng khi thiết kế mã TensorFlow để đào tạo về TFX.
Kết quả của thành phần Transform là một SavingModel sẽ được nhập và sử dụng trong mã lập mô hình của bạn trong TensorFlow, trong thành phần Trainer . SavingModel này bao gồm tất cả các phép biến đổi kỹ thuật dữ liệu đã được tạo trong thành phần Biến đổi, sao cho các phép biến đổi giống hệt nhau được thực hiện bằng cách sử dụng cùng một mã trong cả quá trình đào tạo và suy luận. Bằng cách sử dụng mã lập mô hình, bao gồm SavingModel từ thành phần Transform, bạn có thể sử dụng dữ liệu đào tạo và đánh giá cũng như đào tạo mô hình của mình.
Khi làm việc với các mô hình dựa trên Công cụ ước tính, phần cuối cùng của mã lập mô hình sẽ lưu mô hình của bạn dưới dạng cả SavingModel và EvalSavedModel. Việc lưu dưới dạng EvalSavedModel đảm bảo các số liệu được sử dụng trong thời gian đào tạo cũng có sẵn trong quá trình đánh giá (lưu ý rằng điều này không bắt buộc đối với các mô hình dựa trên máy ảnh). Việc lưu EvalSavedModel yêu cầu bạn nhập thư viện Phân tích mô hình TensorFlow (TFMA) trong thành phần Trainer của bạn.
import tensorflow_model_analysis as tfma
...
tfma.export.export_eval_savedmodel(
estimator=estimator,
export_dir_base=eval_model_dir,
eval_input_receiver_fn=receiver_fn)
Một thành phần Tuner tùy chọn có thể được thêm vào trước Trainer để điều chỉnh các siêu tham số (ví dụ: số lớp) cho mô hình. Với mô hình và không gian tìm kiếm của siêu tham số nhất định, thuật toán điều chỉnh sẽ tìm ra siêu tham số tốt nhất dựa trên mục tiêu.
Phân tích và hiểu hiệu suất của mô hình
Sau quá trình đào tạo và phát triển mô hình ban đầu, điều quan trọng là phải phân tích và thực sự hiểu rõ hiệu suất mô hình của bạn. Một quy trình TFX điển hình sẽ bao gồm thành phần Bộ đánh giá , giúp tận dụng các khả năng của thư viện Phân tích mô hình TensorFlow (TFMA) , cung cấp bộ công cụ mạnh mẽ cho giai đoạn phát triển này. Thành phần Evaluator sử dụng mô hình mà bạn đã xuất ở trên và cho phép bạn chỉ định danh sách tfma.SlicingSpec mà bạn có thể sử dụng khi trực quan hóa và phân tích hiệu suất mô hình của mình. Mỗi SlicingSpec xác định một phần dữ liệu huấn luyện mà bạn muốn kiểm tra, chẳng hạn như các danh mục cụ thể cho các tính năng phân loại hoặc phạm vi cụ thể cho các tính năng số.
Ví dụ: điều này rất quan trọng để cố gắng hiểu hiệu suất mô hình của bạn đối với các phân khúc khách hàng khác nhau, có thể được phân đoạn theo số lần mua hàng hàng năm, dữ liệu địa lý, nhóm tuổi hoặc giới tính. Điều này có thể đặc biệt quan trọng đối với các tập dữ liệu có đuôi dài, trong đó hiệu suất của một nhóm thống trị có thể che giấu hiệu suất không thể chấp nhận được đối với các nhóm quan trọng nhưng nhỏ hơn. Ví dụ: mô hình của bạn có thể hoạt động tốt đối với nhân viên trung bình nhưng lại thất bại thảm hại đối với nhân viên điều hành và điều quan trọng là bạn phải biết điều đó.
Phân tích và trực quan hóa mô hình
Sau khi hoàn thành lần chạy dữ liệu đầu tiên thông qua việc huấn luyện mô hình và chạy thành phần Người đánh giá (sử dụng TFMA ) trên kết quả huấn luyện, bạn có thể hình dung kết quả trong sổ ghi chép kiểu Jupyter. Đối với các lần chạy bổ sung, bạn có thể so sánh các kết quả này khi thực hiện điều chỉnh cho đến khi kết quả tối ưu cho mô hình và ứng dụng của bạn.
Trước tiên, bạn sẽ truy vấn Siêu dữ liệu ML (MLMD) để xác định kết quả của việc thực thi các thành phần này, sau đó sử dụng API hỗ trợ trực quan hóa trong TFMA để tạo trực quan hóa trong sổ ghi chép của bạn. Điều này bao gồm tfma.load_eval_results và tfma.view.render_slicing_metrics. Sử dụng hình ảnh trực quan này, bạn có thể hiểu rõ hơn các đặc điểm của mô hình của mình và nếu cần, hãy sửa đổi theo yêu cầu.
Xác thực hiệu suất mô hình
Là một phần của việc phân tích hiệu suất của mô hình, bạn có thể muốn xác thực hiệu suất dựa trên đường cơ sở (chẳng hạn như mô hình hiện đang phục vụ). Xác thực mô hình được thực hiện bằng cách chuyển cả mô hình ứng viên và mô hình cơ sở cho thành phần Người đánh giá . Người đánh giá tính toán các số liệu (ví dụ: AUC, tổn thất) cho cả ứng viên và đường cơ sở cùng với một tập hợp các số liệu khác biệt tương ứng. Sau đó, các ngưỡng có thể được áp dụng và sử dụng để đẩy mô hình của bạn vào sản xuất.
Xác thực rằng một mô hình có thể được phục vụ
Trước khi triển khai mô hình được đào tạo, bạn có thể muốn xác thực xem mô hình đó có thực sự phục vụ được trong cơ sở hạ tầng phục vụ hay không. Điều này đặc biệt quan trọng trong môi trường sản xuất để đảm bảo rằng mô hình mới được xuất bản không ngăn hệ thống đưa ra dự đoán. Thành phần InfraValidator sẽ triển khai mô hình của bạn trong môi trường hộp cát và tùy ý gửi các yêu cầu thực để kiểm tra xem mô hình của bạn có hoạt động chính xác hay không.
Mục tiêu triển khai
Sau khi bạn đã phát triển và đào tạo một mô hình mà bạn hài lòng, giờ là lúc triển khai mô hình đó đến một hoặc nhiều mục tiêu triển khai nơi mô hình sẽ nhận được yêu cầu suy luận. TFX hỗ trợ triển khai cho ba loại mục tiêu triển khai. Các mô hình đã đào tạo đã được xuất dưới dạng SavingModels có thể được triển khai cho bất kỳ hoặc tất cả các mục tiêu triển khai này.
Suy luận: Phục vụ TensorFlow
TensorFlow Serve (TFS) là một hệ thống cung cấp linh hoạt, hiệu suất cao dành cho các mô hình học máy, được thiết kế cho môi trường sản xuất. Nó sử dụng SavingModel và sẽ chấp nhận các yêu cầu suy luận qua giao diện REST hoặc gRPC. Nó chạy như một tập hợp các quy trình trên một hoặc nhiều máy chủ mạng, sử dụng một trong một số kiến trúc nâng cao để xử lý việc đồng bộ hóa và tính toán phân tán. Xem tài liệu TFS để biết thêm thông tin về cách phát triển và triển khai các giải pháp TFS.
Trong một quy trình thông thường, SavingModel đã được đào tạo trong thành phần Trainer trước tiên sẽ được xác thực dưới mức trong thành phần InfraValidator . InfraValidator khởi chạy máy chủ mô hình TFS canary để thực sự phục vụ SavingModel. Nếu quá trình xác thực đã vượt qua, thành phần Pusher cuối cùng sẽ triển khai SavingModel cho cơ sở hạ tầng TFS của bạn. Điều này bao gồm việc xử lý nhiều phiên bản và cập nhật mô hình.
Suy luận trong các ứng dụng di động và IoT gốc: TensorFlow Lite
TensorFlow Lite là một bộ công cụ dành riêng để giúp các nhà phát triển sử dụng Mô hình TensorFlow đã được đào tạo của họ trong các ứng dụng IoT và di động gốc. Nó sử dụng các SavingModels giống như TensorFlow Serve và áp dụng các tối ưu hóa như lượng tử hóa và cắt bớt để tối ưu hóa kích thước và hiệu suất của các mô hình kết quả cho những thách thức khi chạy trên thiết bị di động và thiết bị IoT. Xem tài liệu TensorFlow Lite để biết thêm thông tin về cách sử dụng TensorFlow Lite.
Suy luận trong JavaScript: TensorFlow JS
TensorFlow JS là thư viện JavaScript để đào tạo và triển khai các mô hình ML trong trình duyệt và trên Node.js. Nó sử dụng các SavingModels giống như TensorFlow Serve và TensorFlow Lite, đồng thời chuyển đổi chúng sang định dạng Web TensorFlow.js. Xem tài liệu TensorFlow JS để biết thêm chi tiết về cách sử dụng TensorFlow JS.
Tạo đường ống TFX bằng luồng không khí
Kiểm tra xưởng luồng không khí để biết chi tiết
Tạo quy trình TFX với Kubeflow
Cài đặt
Kubeflow yêu cầu cụm Kubernetes để chạy quy trình trên quy mô lớn. Xem hướng dẫn triển khai Kubeflow để hướng dẫn các tùy chọn triển khai cụm Kubeflow.
Định cấu hình và chạy đường ống TFX
Vui lòng làm theo hướng dẫn TFX trên Cloud AI Platform Pipeline để chạy quy trình mẫu TFX trên Kubeflow. Các thành phần TFX đã được đóng gói để tạo nên quy trình Kubeflow và mẫu minh họa khả năng định cấu hình quy trình để đọc tập dữ liệu công khai lớn cũng như thực hiện các bước đào tạo và xử lý dữ liệu trên quy mô lớn trên đám mây.
Giao diện dòng lệnh cho các hành động đường ống
TFX cung cấp CLI hợp nhất giúp thực hiện đầy đủ các hành động quy trình như tạo, cập nhật, chạy, liệt kê và xóa quy trình trên nhiều bộ điều phối khác nhau bao gồm Apache Airflow, Apache Beam và Kubeflow. Để biết chi tiết, vui lòng làm theo các hướng dẫn sau .