
Un esempio di un componente chiave di TensorFlow Extended
 Visualizza l'origine su GitHub
Visualizza l'origine su GitHubQuesto esempio di notebook Colab illustra come utilizzare TensorFlow Data Validation (TFDV) per analizzare e visualizzare il set di dati. Ciò include l'analisi di statistiche descrittive, la deduzione di uno schema, il controllo e la correzione di anomalie e il controllo di deriva e inclinazione nel nostro set di dati. È importante comprendere le caratteristiche del set di dati, incluso il modo in cui potrebbe cambiare nel tempo nella pipeline di produzione. È anche importante cercare le anomalie nei dati e confrontare i set di dati di addestramento, valutazione e pubblicazione per assicurarsi che siano coerenti.
Utilizzeremo i dati del set di dati Taxi Trips rilasciato dalla città di Chicago.
Ulteriori informazioni sul set di dati in Google BigQuery . Esplora il set di dati completo nell'interfaccia utente di BigQuery .
Le colonne nel set di dati sono:
| pickup_community_area | tariffa | viaggio_inizio_mese |
| trip_start_hour | viaggio_inizio_giorno | trip_start_timestamp |
| pickup_latitude | pickup_longitude | dropoff_latitude |
| dropoff_longitude | viaggio_miglia | ritiro_censimento_tratto |
| dropoff_census_tract | modalità di pagamento | società |
| viaggio_secondi | dropoff_community_area | Consigli |
Installa e importa i pacchetti
Installa i pacchetti per TensorFlow Data Validation.
Aggiorna Pip
Per evitare l'aggiornamento di Pip in un sistema durante l'esecuzione in locale, verifica che sia in esecuzione in Colab. I sistemi locali possono ovviamente essere aggiornati separatamente.
try:
import colab
!pip install --upgrade pip
except:
pass
Installa i pacchetti di convalida dei dati
Installa i pacchetti e le dipendenze di convalida dei dati TensorFlow, operazione che richiede alcuni minuti. Potresti visualizzare avvisi ed errori relativi a versioni delle dipendenze incompatibili, che risolverai nella sezione successiva.
print('Installing TensorFlow Data Validation')
!pip install --upgrade 'tensorflow_data_validation[visualization]<2'
Importa TensorFlow e ricarica i pacchetti aggiornati
Il passaggio precedente aggiorna i pacchetti predefiniti nell'ambiente Gooogle Colab, quindi devi ricaricare le risorse del pacchetto per risolvere le nuove dipendenze.
import pkg_resources
import importlib
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
Verificare le versioni di TensorFlow e la convalida dei dati prima di procedere.
import tensorflow as tf
import tensorflow_data_validation as tfdv
print('TF version:', tf.__version__)
print('TFDV version:', tfdv.version.__version__)
TF version: 2.7.0 TFDV version: 1.5.0
Carica il set di dati
Scaricheremo il nostro set di dati da Google Cloud Storage.
import os
import tempfile, urllib, zipfile
# Set up some globals for our file paths
BASE_DIR = tempfile.mkdtemp()
DATA_DIR = os.path.join(BASE_DIR, 'data')
OUTPUT_DIR = os.path.join(BASE_DIR, 'chicago_taxi_output')
TRAIN_DATA = os.path.join(DATA_DIR, 'train', 'data.csv')
EVAL_DATA = os.path.join(DATA_DIR, 'eval', 'data.csv')
SERVING_DATA = os.path.join(DATA_DIR, 'serving', 'data.csv')
# Download the zip file from GCP and unzip it
zip, headers = urllib.request.urlretrieve('https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/chicago_data.zip')
zipfile.ZipFile(zip).extractall(BASE_DIR)
zipfile.ZipFile(zip).close()
print("Here's what we downloaded:")
!ls -R {os.path.join(BASE_DIR, 'data')}
Here's what we downloaded: /tmp/tmp_waiqx43/data: eval serving train /tmp/tmp_waiqx43/data/eval: data.csv /tmp/tmp_waiqx43/data/serving: data.csv /tmp/tmp_waiqx43/data/train: data.csv
Calcola e visualizza le statistiche
Per prima cosa useremo tfdv.generate_statistics_from_csv per calcolare le statistiche per i nostri dati di addestramento. (ignora gli avvisi veloci)
TFDV può elaborare statistiche descrittive che forniscono una rapida panoramica dei dati in termini di caratteristiche presenti e forme delle loro distribuzioni di valore.
Internamente, TFDV utilizza il framework di elaborazione parallela dei dati di Apache Beam per scalare il calcolo delle statistiche su grandi set di dati. Per le applicazioni che desiderano integrarsi in modo più approfondito con TFDV (ad esempio, allegare la generazione di statistiche alla fine di una pipeline di generazione di dati), l'API espone anche un Beam PTransform per la generazione di statistiche.
train_stats = tfdv.generate_statistics_from_csv(data_location=TRAIN_DATA)
WARNING:apache_beam.runners.interactive.interactive_environment:Dependencies required for Interactive Beam PCollection visualization are not available, please use: `pip install apache-beam[interactive]` to install necessary dependencies to enable all data visualization features. WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter. WARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)` WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)`
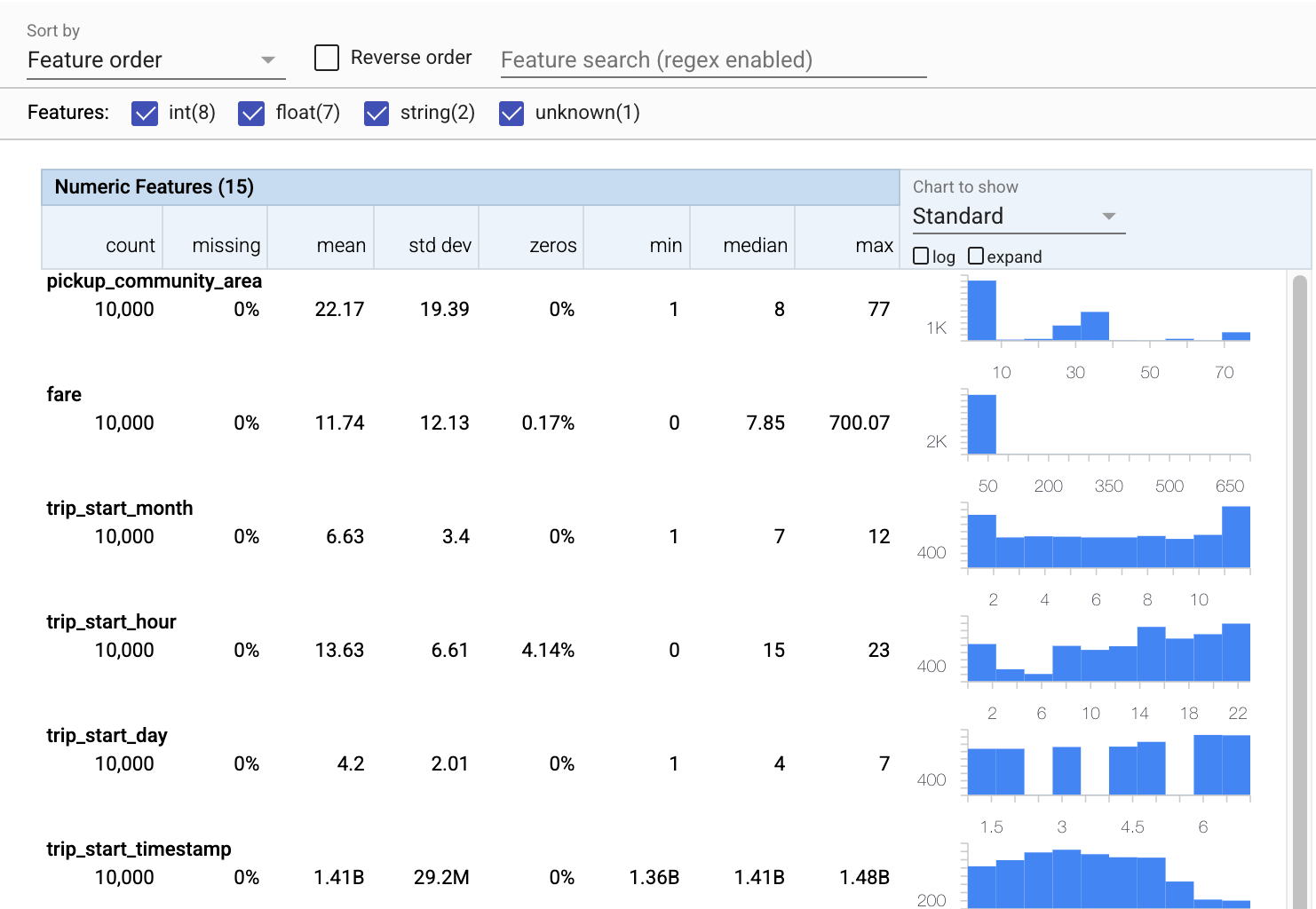
Ora utilizziamo tfdv.visualize_statistics , che utilizza Facets per creare una visualizzazione succinta dei nostri dati di allenamento:
- Si noti che le caratteristiche numeriche e le caratteristiche di categoria vengono visualizzate separatamente e che i grafici vengono visualizzati mostrando le distribuzioni per ciascuna caratteristica.
- Si noti che le funzionalità con valori mancanti o zero visualizzano una percentuale in rosso come indicatore visivo che potrebbero esserci problemi con gli esempi in tali funzionalità. La percentuale è la percentuale di esempi che hanno valori mancanti o zero per quella caratteristica.
- Si noti che non ci sono esempi con valori per
pickup_census_tract. Questa è un'opportunità per la riduzione della dimensionalità! - Prova a fare clic su "espandi" sopra i grafici per cambiare la visualizzazione
- Prova a passare il mouse sopra le barre nei grafici per visualizzare intervalli e conteggi di bucket
- Prova a passare dalla scala logaritmica a quella lineare e nota come la scala logaritmica rivela molti più dettagli sulla funzione categoriale
payment_type - Prova a selezionare "quantiles" dal menu "Grafico da mostrare" e passa il mouse sopra i marcatori per mostrare le percentuali di quantile
# docs-infra: no-execute
tfdv.visualize_statistics(train_stats)
Dedurre uno schema
Ora usiamo tfdv.infer_schema per creare uno schema per i nostri dati. Uno schema definisce i vincoli per i dati rilevanti per ML. I vincoli di esempio includono il tipo di dati di ciascuna funzionalità, numerica o categoriale, o la frequenza della sua presenza nei dati. Per le caratteristiche categoriali lo schema definisce anche il dominio, l'elenco dei valori accettabili. Poiché la scrittura di uno schema può essere un compito noioso, specialmente per set di dati con molte funzionalità, TFDV fornisce un metodo per generare una versione iniziale dello schema basata sulle statistiche descrittive.
Ottenere lo schema corretto è importante perché il resto della nostra pipeline di produzione si baserà sullo schema generato da TFDV per essere corretto. Lo schema fornisce anche la documentazione per i dati, quindi è utile quando diversi sviluppatori lavorano sugli stessi dati. Usiamo tfdv.display_schema per visualizzare lo schema dedotto in modo da poterlo rivedere.
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
Verificare la presenza di errori nei dati di valutazione
Finora abbiamo esaminato solo i dati di allenamento. È importante che i nostri dati di valutazione siano coerenti con i nostri dati di addestramento, incluso che utilizzi lo stesso schema. È anche importante che i dati di valutazione includano esempi di intervalli di valori più o meno identici per le nostre caratteristiche numeriche dei nostri dati di addestramento, in modo che la nostra copertura della superficie di perdita durante la valutazione sia più o meno la stessa che durante l'addestramento. Lo stesso vale per le caratteristiche categoriali. In caso contrario, potremmo avere problemi di formazione che non vengono identificati durante la valutazione, perché non abbiamo valutato parte della nostra superficie di perdita.
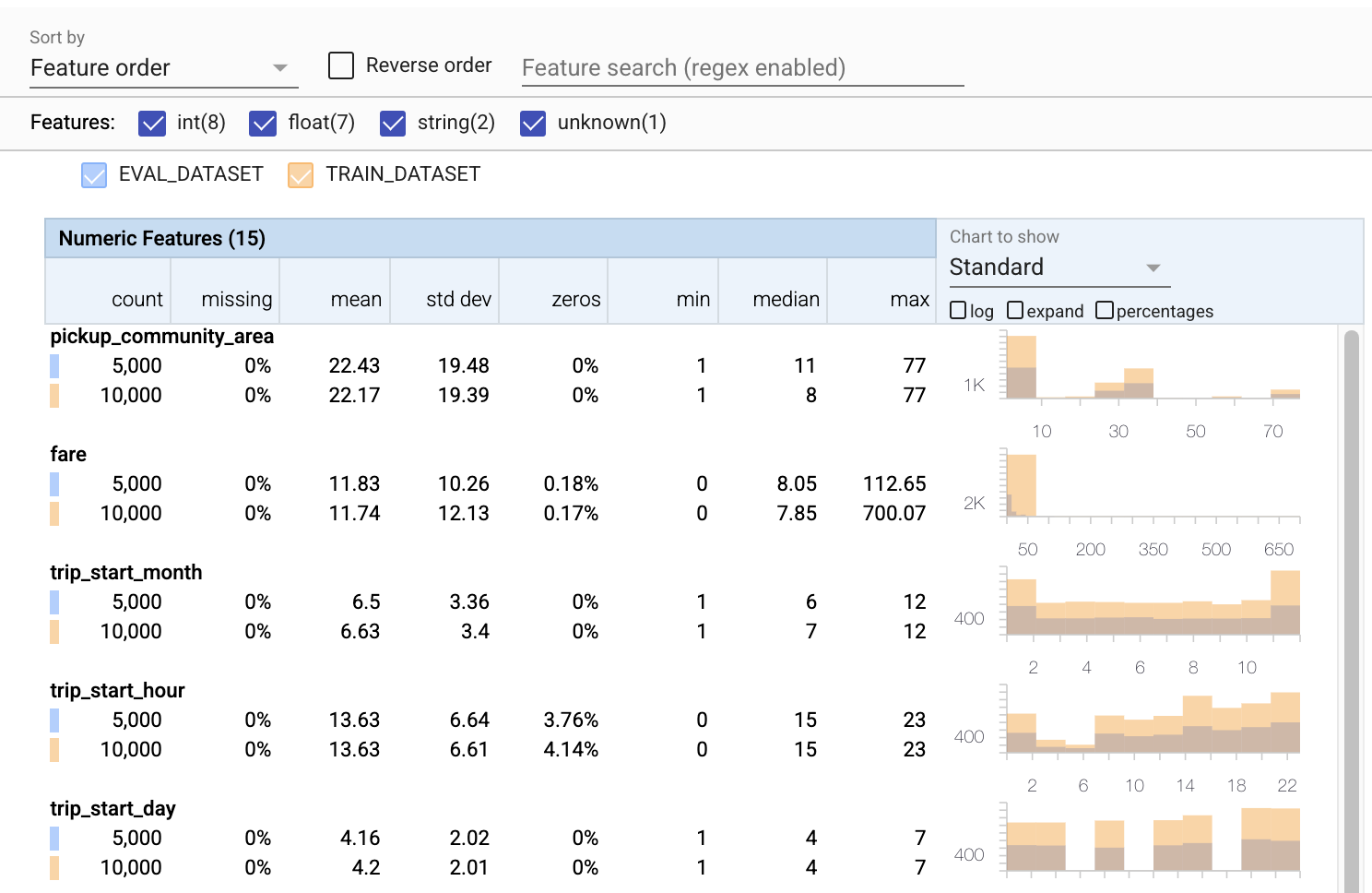
- Si noti che ogni funzionalità ora include le statistiche per i set di dati di addestramento e valutazione.
- Si noti che i grafici ora hanno i set di dati di addestramento e valutazione sovrapposti, semplificando il confronto.
- Si noti che i grafici ora includono una visualizzazione percentuale, che può essere combinata con il registro o le scale lineari predefinite.
- Si noti che la media e la mediana di
trip_milessono diverse per l'allenamento rispetto ai set di dati di valutazione. Ciò causerà problemi? - Wow, i
tipsmassimi sono molto diversi per l'allenamento rispetto ai set di dati di valutazione. Ciò causerà problemi? - Fare clic su espandi nel grafico delle caratteristiche numeriche e selezionare la scala logaritmica. Esamina la funzione
trip_secondse nota la differenza nel max. La valutazione mancherà parti della superficie della perdita?
# Compute stats for evaluation data
eval_stats = tfdv.generate_statistics_from_csv(data_location=EVAL_DATA)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
# docs-infra: no-execute
# Compare evaluation data with training data
tfdv.visualize_statistics(lhs_statistics=eval_stats, rhs_statistics=train_stats,
lhs_name='EVAL_DATASET', rhs_name='TRAIN_DATASET')
Verificare eventuali anomalie di valutazione
Il nostro set di dati di valutazione corrisponde allo schema del nostro set di dati di addestramento? Ciò è particolarmente importante per le caratteristiche categoriali, in cui vogliamo identificare l'intervallo di valori accettabili.
# Check eval data for errors by validating the eval data stats using the previously inferred schema.
anomalies = tfdv.validate_statistics(statistics=eval_stats, schema=schema)
tfdv.display_anomalies(anomalies)
Correggere le anomalie di valutazione nello schema
Ops! Sembra che abbiamo dei nuovi valori per l' company nei nostri dati di valutazione, che non avevamo nei nostri dati di formazione. Abbiamo anche un nuovo valore per payment_type . Queste dovrebbero essere considerate anomalie, ma ciò che decidiamo di fare al riguardo dipende dalla nostra conoscenza del dominio dei dati. Se un'anomalia indica veramente un errore di dati, i dati sottostanti dovrebbero essere corretti. Altrimenti, possiamo semplicemente aggiornare lo schema per includere i valori nel set di dati eval.
A meno che non modifichiamo il nostro set di dati di valutazione, non possiamo correggere tutto, ma possiamo correggere le cose nello schema che siamo a nostro agio ad accettare. Ciò include il rilassamento della nostra visione di ciò che è e ciò che non è un'anomalia per caratteristiche particolari, nonché l'aggiornamento del nostro schema per includere i valori mancanti per le caratteristiche categoriali. TFDV ci ha permesso di scoprire cosa dobbiamo sistemare.
Effettuiamo queste correzioni ora, quindi rivediamo ancora una volta.
# Relax the minimum fraction of values that must come from the domain for feature company.
company = tfdv.get_feature(schema, 'company')
company.distribution_constraints.min_domain_mass = 0.9
# Add new value to the domain of feature payment_type.
payment_type_domain = tfdv.get_domain(schema, 'payment_type')
payment_type_domain.value.append('Prcard')
# Validate eval stats after updating the schema
updated_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(updated_anomalies)
Ehi, guarda quello! Abbiamo verificato che i dati di formazione e valutazione ora sono coerenti! Grazie TFDV ;)
Ambienti dello schema
Abbiamo anche diviso un set di dati "di pubblicazione" per questo esempio, quindi dovremmo controllare anche quello. Per impostazione predefinita, tutti i set di dati in una pipeline devono usare lo stesso schema, ma spesso esistono delle eccezioni. Ad esempio, nell'apprendimento supervisionato dobbiamo includere le etichette nel nostro set di dati, ma quando serviamo il modello per l'inferenza le etichette non verranno incluse. In alcuni casi è necessario introdurre lievi variazioni di schema.
Gli ambienti possono essere utilizzati per esprimere tali requisiti. In particolare, le funzionalità in schema possono essere associate a un insieme di ambienti utilizzando default_environment , in_environment e not_in_environment .
Ad esempio, in questo set di dati la funzione tips è inclusa come etichetta per la formazione, ma manca nei dati di pubblicazione. Senza l'ambiente specificato, verrà visualizzato come un'anomalia.
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
Ci occuperemo della funzionalità dei tips di seguito. Abbiamo anche un valore INT nei nostri secondi di viaggio, dove il nostro schema prevedeva un FLOAT. Rendendoci consapevoli di questa differenza, TFDV aiuta a scoprire le incongruenze nel modo in cui i dati vengono generati per la formazione e l'elaborazione. È molto facile non essere a conoscenza di problemi del genere finché le prestazioni del modello non ne risentono, a volte in modo catastrofico. Può essere o meno un problema significativo, ma in ogni caso questo dovrebbe essere motivo di ulteriori indagini.
In questo caso, possiamo convertire in sicurezza i valori INT in FLOAT, quindi vogliamo dire a TFDV di usare il nostro schema per dedurre il tipo. Facciamolo ora.
options = tfdv.StatsOptions(schema=schema, infer_type_from_schema=True)
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA, stats_options=options)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
Ora abbiamo solo la funzione dei tips (che è la nostra etichetta) che appare come un'anomalia ("Colonna eliminata"). Ovviamente non ci aspettiamo di avere etichette nei nostri dati di pubblicazione, quindi diciamo a TFDV di ignorarlo.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
tfdv.display_anomalies(serving_anomalies_with_env)
Controllare la deriva e l'inclinazione
Oltre a verificare se un set di dati è conforme alle aspettative stabilite nello schema, TFDV fornisce anche funzionalità per rilevare deriva e skew. TFDV esegue questo controllo confrontando le statistiche dei diversi dataset in base ai comparatori drift/skew specificati nello schema.
Deriva
Il rilevamento della deriva è supportato per le caratteristiche categoriali e tra intervalli di dati consecutivi (ovvero tra l'intervallo N e l'intervallo N+1), ad esempio tra diversi giorni di dati di addestramento. Esprimiamo la deriva in termini di distanza L-infinito e puoi impostare la distanza di soglia in modo da ricevere avvisi quando la deriva è superiore a quella accettabile. L'impostazione della distanza corretta è in genere un processo iterativo che richiede conoscenza e sperimentazione del dominio.
Storto
TFDV è in grado di rilevare tre diversi tipi di asimmetria nei dati: asimmetria dello schema, asimmetria delle funzionalità e asimmetria della distribuzione.
Schema obliquo
L'inclinazione dello schema si verifica quando i dati di addestramento e pubblicazione non sono conformi allo stesso schema. Ci si aspetta che i dati di training e di elaborazione aderiscano allo stesso schema. Eventuali scostamenti previsti tra i due (ad esempio la caratteristica dell'etichetta che è presente solo nei dati di addestramento ma non nella pubblicazione) deve essere specificata tramite il campo degli ambienti nello schema.
Caratteristica inclinata
L'inclinazione delle funzionalità si verifica quando i valori delle funzionalità su cui si allena un modello sono diversi dai valori delle funzionalità che vede al momento della pubblicazione. Ad esempio, questo può accadere quando:
- Un'origine dati che fornisce alcuni valori di funzionalità viene modificata tra l'addestramento e il tempo di elaborazione
- Esiste una logica diversa per la generazione di funzionalità tra la formazione e il servizio. Ad esempio, se applichi alcune trasformazioni solo in uno dei due percorsi di codice.
Distorsione di distribuzione
L'inclinazione della distribuzione si verifica quando la distribuzione del set di dati di addestramento è significativamente diversa dalla distribuzione del set di dati di servizio. Una delle cause principali dell'inclinazione della distribuzione è l'utilizzo di codice diverso o origini dati diverse per generare il set di dati di addestramento. Un altro motivo è un meccanismo di campionamento difettoso che sceglie un sottocampione non rappresentativo dei dati di servizio su cui eseguire l'allenamento.
# Add skew comparator for 'payment_type' feature.
payment_type = tfdv.get_feature(schema, 'payment_type')
payment_type.skew_comparator.infinity_norm.threshold = 0.01
# Add drift comparator for 'company' feature.
company=tfdv.get_feature(schema, 'company')
company.drift_comparator.infinity_norm.threshold = 0.001
skew_anomalies = tfdv.validate_statistics(train_stats, schema,
previous_statistics=eval_stats,
serving_statistics=serving_stats)
tfdv.display_anomalies(skew_anomalies)
In questo esempio vediamo una certa deriva, ma è ben al di sotto della soglia che abbiamo impostato.
Blocca lo schema
Ora che lo schema è stato rivisto e curato, lo memorizzeremo in un file per riflettere il suo stato "congelato".
from tensorflow.python.lib.io import file_io
from google.protobuf import text_format
file_io.recursive_create_dir(OUTPUT_DIR)
schema_file = os.path.join(OUTPUT_DIR, 'schema.pbtxt')
tfdv.write_schema_text(schema, schema_file)
!cat {schema_file}
feature {
name: "pickup_community_area"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "fare"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_month"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_hour"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_day"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_timestamp"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_latitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_longitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_latitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "dropoff_longitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "trip_miles"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_census_tract"
type: BYTES
presence {
min_count: 0
}
}
feature {
name: "dropoff_census_tract"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "payment_type"
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
skew_comparator {
infinity_norm {
threshold: 0.01
}
}
shape {
dim {
size: 1
}
}
}
feature {
name: "company"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "company"
presence {
min_count: 1
}
distribution_constraints {
min_domain_mass: 0.9
}
drift_comparator {
infinity_norm {
threshold: 0.001
}
}
}
feature {
name: "trip_seconds"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_community_area"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "tips"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
not_in_environment: "SERVING"
shape {
dim {
size: 1
}
}
}
string_domain {
name: "payment_type"
value: "Cash"
value: "Credit Card"
value: "Dispute"
value: "No Charge"
value: "Pcard"
value: "Unknown"
value: "Prcard"
}
string_domain {
name: "company"
value: "0118 - 42111 Godfrey S.Awir"
value: "0694 - 59280 Chinesco Trans Inc"
value: "1085 - 72312 N and W Cab Co"
value: "2733 - 74600 Benny Jona"
value: "2809 - 95474 C & D Cab Co Inc."
value: "3011 - 66308 JBL Cab Inc."
value: "3152 - 97284 Crystal Abernathy"
value: "3201 - C&D Cab Co Inc"
value: "3201 - CID Cab Co Inc"
value: "3253 - 91138 Gaither Cab Co."
value: "3385 - 23210 Eman Cab"
value: "3623 - 72222 Arrington Enterprises"
value: "3897 - Ilie Malec"
value: "4053 - Adwar H. Nikola"
value: "4197 - 41842 Royal Star"
value: "4615 - 83503 Tyrone Henderson"
value: "4615 - Tyrone Henderson"
value: "4623 - Jay Kim"
value: "5006 - 39261 Salifu Bawa"
value: "5006 - Salifu Bawa"
value: "5074 - 54002 Ahzmi Inc"
value: "5074 - Ahzmi Inc"
value: "5129 - 87128"
value: "5129 - 98755 Mengisti Taxi"
value: "5129 - Mengisti Taxi"
value: "5724 - KYVI Cab Inc"
value: "585 - Valley Cab Co"
value: "5864 - 73614 Thomas Owusu"
value: "5864 - Thomas Owusu"
value: "5874 - 73628 Sergey Cab Corp."
value: "5997 - 65283 AW Services Inc."
value: "5997 - AW Services Inc."
value: "6488 - 83287 Zuha Taxi"
value: "6743 - Luhak Corp"
value: "Blue Ribbon Taxi Association Inc."
value: "C & D Cab Co Inc"
value: "Chicago Elite Cab Corp."
value: "Chicago Elite Cab Corp. (Chicago Carriag"
value: "Chicago Medallion Leasing INC"
value: "Chicago Medallion Management"
value: "Choice Taxi Association"
value: "Dispatch Taxi Affiliation"
value: "KOAM Taxi Association"
value: "Northwest Management LLC"
value: "Taxi Affiliation Services"
value: "Top Cab Affiliation"
}
default_environment: "TRAINING"
default_environment: "SERVING"
Quando usare TFDV
È facile pensare che TFDV si applichi solo all'inizio della tua pipeline di formazione, come abbiamo fatto qui, ma in realtà ha molti usi. Eccone altri:
- Convalida di nuovi dati per l'inferenza per assicurarci di non aver improvvisamente iniziato a ricevere funzionalità errate
- Convalida di nuovi dati per l'inferenza per assicurarsi che il nostro modello sia stato addestrato su quella parte della superficie decisionale
- Convalida dei nostri dati dopo averli trasformati e aver eseguito l'ingegneria delle funzionalità (probabilmente utilizzando TensorFlow Transform ) per assicurarci di non aver fatto qualcosa di sbagliato