
Perkenalan
Tutorial ini dirancang untuk memperkenalkan TensorFlow Extended (TFX) dan AIPlatform Pipelines , serta membantu Anda mempelajari cara membuat pipeline machine learning Anda sendiri di Google Cloud. Ini menunjukkan integrasi dengan TFX, AI Platform Pipelines, dan Kubeflow, serta interaksi dengan TFX di notebook Jupyter.
Di akhir tutorial ini, Anda akan membuat dan menjalankan ML Pipeline, yang dihosting di Google Cloud. Anda akan dapat memvisualisasikan hasil setiap proses, dan melihat silsilah artefak yang dibuat.
Anda akan mengikuti proses pengembangan ML pada umumnya, dimulai dengan memeriksa kumpulan data, dan diakhiri dengan alur kerja yang lengkap. Sepanjang prosesnya, Anda akan menjelajahi cara untuk melakukan debug dan memperbarui saluran Anda, serta mengukur kinerja.
Kumpulan Data Taksi Chicago


Anda menggunakan kumpulan data Taxi Trips yang dirilis oleh Kota Chicago.
Anda dapat membaca lebih lanjut tentang kumpulan data di Google BigQuery . Jelajahi kumpulan data lengkap di UI BigQuery .
Model Goal - Klasifikasi biner
Akankah pelanggan memberi tip lebih atau kurang dari 20%?
1. Siapkan proyek Google Cloud
1.a Siapkan lingkungan Anda di Google Cloud
Untuk memulai, Anda memerlukan Akun Google Cloud. Jika Anda sudah memilikinya, lanjutkan ke Buat Proyek Baru .
Buka Google Cloud Console .
Setujui persyaratan dan ketentuan Google Cloud
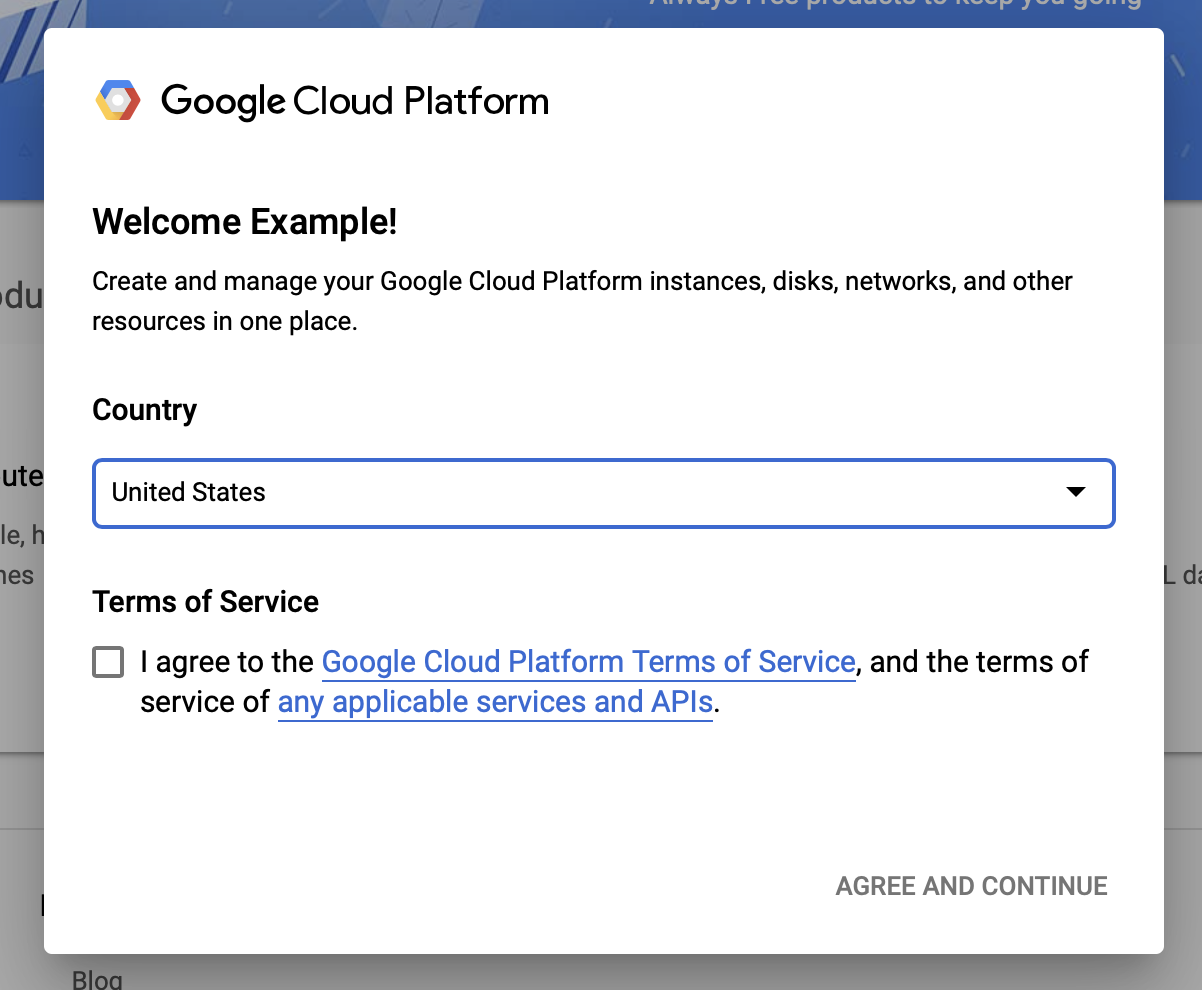
Jika Anda ingin memulai dengan akun uji coba gratis, klik Coba Gratis (atau Mulai gratis ).
Pilih negara Anda.
Setuju dengan persyaratan layanan.
Masukkan detail penagihan.
Anda tidak akan dikenakan biaya pada saat ini. Jika Anda tidak memiliki proyek Google Cloud lainnya, Anda dapat menyelesaikan tutorial ini tanpa melebihi batas Tingkat Gratis Google Cloud , yang mencakup maksimal 8 inti yang berjalan pada waktu yang sama.
1.b Buat proyek baru.
- Dari dasbor utama Google Cloud , klik dropdown proyek di samping header Google Cloud Platform , dan pilih Proyek Baru .
- Beri nama proyek Anda dan masukkan detail proyek lainnya
- Setelah Anda membuat proyek, pastikan untuk memilihnya dari drop-down proyek.
2. Menyiapkan dan menerapkan AI Platform Pipeline pada cluster Kubernetes baru
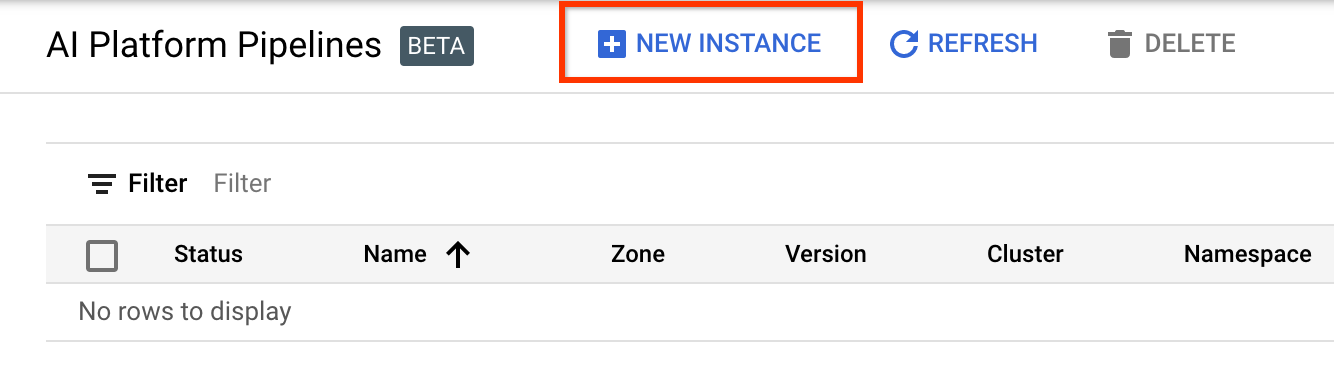
Buka halaman Kluster Alur Platform AI .
Di bawah Menu Navigasi Utama: ≡ > AI Platform > Pipelines
Klik + Instans Baru untuk membuat cluster baru.
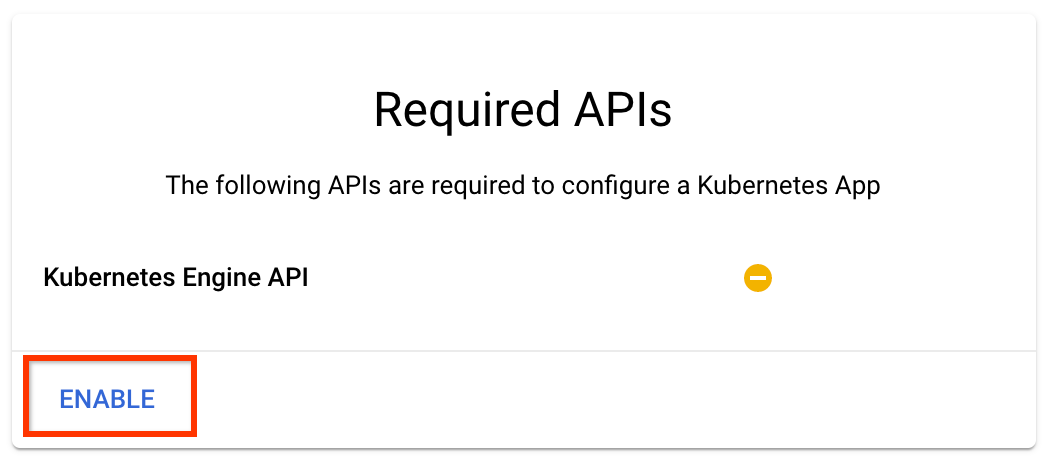
Pada halaman ikhtisar Kubeflow Pipelines , klik Konfigurasikan .

Klik "Aktifkan" untuk mengaktifkan API Kubernetes Engine
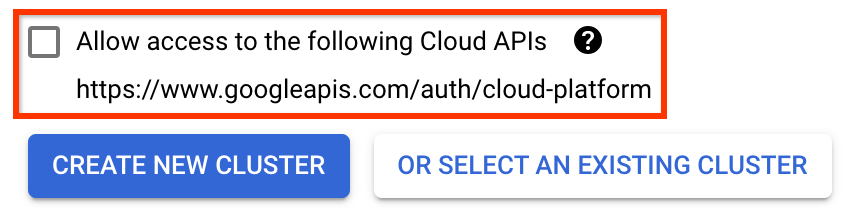
Pada halaman Deploy Kubeflow Pipelines :
Pilih zona (atau "wilayah") untuk klaster Anda. Jaringan dan subjaringan dapat diatur, namun untuk keperluan tutorial ini kami akan membiarkannya sebagai default.
PENTING Centang kotak berlabel Izinkan akses ke API cloud berikut . (Ini diperlukan agar cluster ini dapat mengakses bagian lain dari proyek Anda. Jika Anda melewatkan langkah ini, memperbaikinya nanti akan agak rumit.)
Klik Create New Cluster , dan tunggu beberapa menit hingga cluster selesai dibuat. Ini akan memakan waktu beberapa menit. Ketika selesai Anda akan melihat pesan seperti:
Cluster "cluster-1" berhasil dibuat di zona "us-central1-a".
Pilih namespace dan nama instance (menggunakan default tidak masalah). Untuk keperluan tutorial ini jangan centang executor.emissary atau Managedstorage.enabled .
Klik Deploy , dan tunggu beberapa saat hingga pipeline telah di-deploy. Dengan menerapkan Kubeflow Pipelines, Anda menyetujui Persyaratan Layanan.
3. Siapkan instance Notebook Cloud AI Platform.
Buka halaman Meja Kerja Vertex AI . Saat pertama kali menjalankan Workbench, Anda harus mengaktifkan Notebooks API.
Di bawah Menu Navigasi Utama: ≡ -> Vertex AI -> Workbench
Jika diminta, aktifkan Compute Engine API.
Buat Notebook Baru dengan TensorFlow Enterprise 2.7 (atau lebih tinggi) terinstal.
Notebook Baru -> TensorFlow Enterprise 2.7 -> Tanpa GPU
Pilih wilayah dan zona, dan beri nama instance notebook.
Agar tetap berada dalam batas Tingkat Gratis, Anda mungkin perlu mengubah pengaturan default di sini untuk mengurangi jumlah vCPU yang tersedia untuk instance ini dari 4 menjadi 2:
- Pilih Opsi Tingkat Lanjut di bagian bawah formulir Buku catatan baru .
Pada Konfigurasi mesin, Anda mungkin ingin memilih konfigurasi dengan 1 atau 2 vCPU jika Anda ingin tetap menggunakan tingkat gratis.
Tunggu hingga buku catatan baru dibuat, lalu klik Aktifkan Notebooks API
4. Luncurkan Buku Catatan Memulai
Buka halaman Kluster Alur Platform AI .
Di bawah Menu Navigasi Utama: ≡ -> AI Platform -> Pipelines
Pada baris untuk klaster yang Anda gunakan dalam tutorial ini, klik Open Pipelines Dashboard .

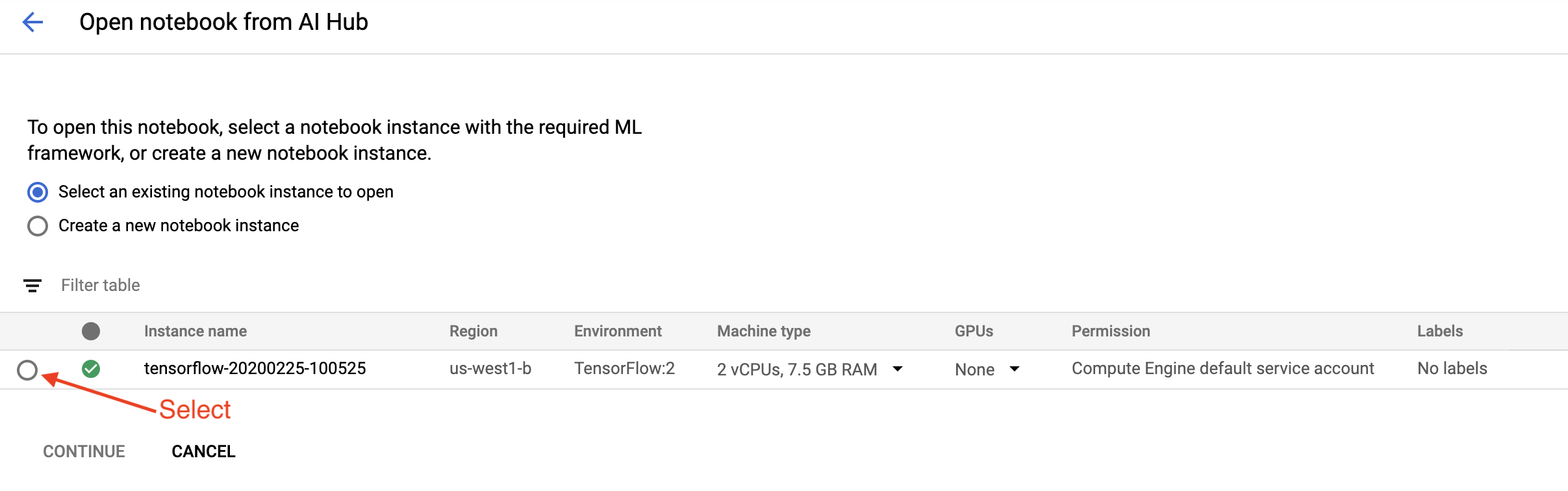
Di halaman Memulai , klik Buka Notebook Cloud AI Platform di Google Cloud .

Pilih instans Notebook yang Anda gunakan untuk tutorial ini dan Lanjutkan , lalu Konfirmasi .
5. Lanjutkan mengerjakan Notebook
Memasang
Notebook Memulai dimulai dengan menginstal TFX dan Kubeflow Pipelines (KFP) ke dalam VM tempat Jupyter Lab dijalankan.
Kemudian memeriksa versi TFX mana yang diinstal, melakukan impor, dan menetapkan serta mencetak ID Proyek:

Terhubung dengan layanan Google Cloud Anda
Konfigurasi alur memerlukan ID proyek Anda, yang bisa Anda dapatkan melalui notebook dan ditetapkan sebagai variabel lingkungan.
# Read GCP project id from env.
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
GCP_PROJECT_ID=shell_output[0]
print("GCP project ID:" + GCP_PROJECT_ID)
Sekarang atur titik akhir klaster KFP Anda.
Ini dapat ditemukan dari URL dasbor Pipelines. Buka dasbor Kubeflow Pipeline dan lihat URL-nya. Titik akhir adalah segala sesuatu di URL yang dimulai dengan https:// , hingga, dan termasuk , googleusercontent.com .
ENDPOINT='' # Enter YOUR ENDPOINT here.
Notebook kemudian menetapkan nama unik untuk image Docker kustom:
# Docker image name for the pipeline image
CUSTOM_TFX_IMAGE='gcr.io/' + GCP_PROJECT_ID + '/tfx-pipeline'
6. Salin template ke direktori proyek Anda
Edit sel buku catatan berikutnya untuk menetapkan nama alur Anda. Dalam tutorial ini kita akan menggunakan my_pipeline .
PIPELINE_NAME="my_pipeline"
PROJECT_DIR=os.path.join(os.path.expanduser("~"),"imported",PIPELINE_NAME)
Notebook kemudian menggunakan tfx CLI untuk menyalin templat alur. Tutorial ini menggunakan dataset Chicago Taxi untuk melakukan klasifikasi biner, sehingga template menetapkan model ke taxi :
!tfx template copy \
--pipeline-name={PIPELINE_NAME} \
--destination-path={PROJECT_DIR} \
--model=taxi
Notebook kemudian mengubah konteks CWD-nya ke direktori proyek:
%cd {PROJECT_DIR}
Telusuri file alur
Di sisi kiri Notebook Cloud AI Platform, Anda akan melihat browser file. Seharusnya ada direktori dengan nama saluran Anda ( my_pipeline ). Buka dan lihat filenya. (Anda juga dapat membukanya dan mengeditnya dari lingkungan buku catatan.)
# You can also list the files from the shellls
Perintah tfx template copy di atas membuat perancah dasar file yang membangun saluran pipa. Ini termasuk kode sumber Python, data sampel, dan buku catatan Jupyter. Ini dimaksudkan untuk contoh khusus ini. Untuk saluran pipa Anda sendiri, ini adalah file pendukung yang dibutuhkan saluran pipa Anda.
Berikut adalah deskripsi singkat tentang file Python.
-
pipeline- Direktori ini berisi definisi pipeline-
configs.py— mendefinisikan konstanta umum untuk runner pipeline -
pipeline.py— mendefinisikan komponen TFX dan pipeline
-
-
models- Direktori ini berisi definisi model ML.-
features.pyfeatures_test.py— mendefinisikan fitur untuk model -
preprocessing.py/preprocessing_test.py— mendefinisikan tugas prapemrosesan menggunakantf::Transform -
estimator- Direktori ini berisi model berbasis Estimator.-
constants.py— mendefinisikan konstanta model -
model.py/model_test.py— mendefinisikan model DNN menggunakan estimator TF
-
-
keras- Direktori ini berisi model berbasis Keras.-
constants.py— mendefinisikan konstanta model -
model.py/model_test.py— mendefinisikan model DNN menggunakan Keras
-
-
-
beam_runner.py/kubeflow_runner.py— menentukan runner untuk setiap mesin orkestrasi
7. Jalankan pipeline TFX pertama Anda di Kubeflow
Notebook akan menjalankan alur menggunakan perintah tfx run CLI.
Hubungkan ke penyimpanan
Pipeline yang berjalan akan membuat artefak yang harus disimpan di ML-Metadata . Artefak mengacu pada payload, yaitu file yang harus disimpan dalam sistem file atau penyimpanan blok. Untuk tutorial ini, kita akan menggunakan GCS untuk menyimpan payload metadata, menggunakan bucket yang dibuat secara otomatis selama penyiapan. Namanya adalah <your-project-id>-kubeflowpipelines-default .
Buat saluran pipa
Notebook akan mengunggah data sampel kita ke bucket GCS sehingga kita dapat menggunakannya dalam pipeline nanti.
gsutil cp data/data.csv gs://{GOOGLE_CLOUD_PROJECT}-kubeflowpipelines-default/tfx-template/data/taxi/data.csv Notebook kemudian menggunakan perintah tfx pipeline create untuk membuat alur.
!tfx pipeline create \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT} \
--build-image
Saat membuat pipeline, Dockerfile akan dibuat untuk membuat image Docker. Jangan lupa untuk menambahkan file-file ini ke sistem kontrol sumber Anda (misalnya, git) bersama dengan file sumber lainnya.
Jalankan alurnya
Notebook kemudian menggunakan perintah tfx run create untuk memulai eksekusi alur Anda. Anda juga akan melihat proses ini tercantum di bawah Eksperimen di Dasbor Kubeflow Pipelines.
tfx run create --pipeline-name={PIPELINE_NAME} --endpoint={ENDPOINT}Anda dapat melihat pipeline Anda dari Dashboard Kubeflow Pipelines.
8. Validasi data Anda
Tugas pertama dalam ilmu data atau proyek ML apa pun adalah memahami dan membersihkan data.
- Pahami tipe data untuk setiap fitur
- Cari anomali dan nilai yang hilang
- Pahami distribusi untuk setiap fitur
Komponen


- ContohGen menyerap dan membagi kumpulan data masukan.
- StatisticsGen menghitung statistik untuk kumpulan data.
- SchemaGen SchemaGen memeriksa statistik dan membuat skema data.
- ContohValidator mencari anomali dan nilai yang hilang dalam kumpulan data.
Di editor file lab Jupyter:
Di pipeline / pipeline.py , hapus komentar pada baris yang menambahkan komponen berikut ke pipeline Anda:
# components.append(statistics_gen)
# components.append(schema_gen)
# components.append(example_validator)
( ExampleGen sudah diaktifkan ketika file templat disalin.)
Perbarui alur dan jalankan kembali
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Periksa pipanya
Untuk Kubeflow Orchestrator, kunjungi dasbor KFP dan temukan output pipeline di halaman untuk menjalankan pipeline Anda. Klik tab "Eksperimen" di sebelah kiri, dan "Semua berjalan" di halaman Eksperimen. Anda seharusnya dapat menemukan proses dengan nama alur Anda.
Contoh yang lebih maju
Contoh yang disajikan di sini sebenarnya hanya dimaksudkan untuk membantu Anda memulai. Untuk contoh lebih lanjut, lihat Colab Validasi Data TensorFlow .
Untuk informasi selengkapnya tentang penggunaan TFDV untuk menjelajahi dan memvalidasi kumpulan data, lihat contoh di tensorflow.org .
9. Rekayasa fitur
Anda dapat meningkatkan kualitas prediktif data dan/atau mengurangi dimensi dengan rekayasa fitur.
- Persilangan fitur
- Kosakata
- Penyematan
- PCA
- Pengkodean kategoris
Salah satu keuntungan menggunakan TFX adalah Anda akan menulis kode transformasi satu kali, dan transformasi yang dihasilkan akan konsisten antara pelatihan dan penyajian.
Komponen

- Transform melakukan rekayasa fitur pada kumpulan data.
Di editor file lab Jupyter:
Di pipeline / pipeline.py , temukan dan hapus komentar pada baris yang menambahkan Transform ke pipeline.
# components.append(transform)
Perbarui alur dan jalankan kembali
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Periksa keluaran pipa
Untuk Kubeflow Orchestrator, kunjungi dasbor KFP dan temukan output pipeline di halaman untuk menjalankan pipeline Anda. Klik tab "Eksperimen" di sebelah kiri, dan "Semua berjalan" di halaman Eksperimen. Anda seharusnya dapat menemukan proses dengan nama alur Anda.
Contoh yang lebih maju
Contoh yang disajikan di sini sebenarnya hanya dimaksudkan untuk membantu Anda memulai. Untuk contoh lebih lanjut, lihat TensorFlow Transform Colab .
10. Pelatihan
Latih model TensorFlow dengan data Anda yang bagus, bersih, dan telah diubah.
- Sertakan transformasi dari langkah sebelumnya agar diterapkan secara konsisten
- Simpan hasilnya sebagai SavedModel untuk produksi
- Visualisasikan dan jelajahi proses pelatihan menggunakan TensorBoard
- Simpan juga EvalSavedModel untuk analisis performa model
Komponen
- Pelatih melatih model TensorFlow.
Di editor file lab Jupyter:
Di pipeline / pipeline.py , temukan dan hapus komentar yang menambahkan Trainer ke pipeline:
# components.append(trainer)
Perbarui alur dan jalankan kembali
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Periksa keluaran pipa
Untuk Kubeflow Orchestrator, kunjungi dasbor KFP dan temukan output pipeline di halaman untuk menjalankan pipeline Anda. Klik tab "Eksperimen" di sebelah kiri, dan "Semua berjalan" di halaman Eksperimen. Anda seharusnya dapat menemukan proses dengan nama alur Anda.
Contoh yang lebih maju
Contoh yang disajikan di sini sebenarnya hanya dimaksudkan untuk membantu Anda memulai. Untuk contoh lebih lanjut, lihat Tutorial TensorBoard .
11. Menganalisis kinerja model
Memahami lebih dari sekedar metrik tingkat atas.
- Pengguna merasakan performa model hanya untuk kueri mereka
- Performa buruk pada bagian data dapat disembunyikan oleh metrik tingkat atas
- Keadilan model itu penting
- Seringkali bagian utama dari pengguna atau data sangatlah penting, dan mungkin berukuran kecil
- Performa dalam kondisi kritis namun tidak biasa
- Performa untuk audiens utama seperti influencer
- Jika Anda mengganti model yang sedang diproduksi, pastikan terlebih dahulu model baru tersebut lebih baik
Komponen
- Evaluator melakukan analisis mendalam terhadap hasil pelatihan.
Di editor file lab Jupyter:
Di pipeline / pipeline.py , temukan dan hapus komentar pada baris yang menambahkan Evaluator ke pipeline:
components.append(evaluator)
Perbarui alur dan jalankan kembali
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Periksa keluaran pipa
Untuk Kubeflow Orchestrator, kunjungi dasbor KFP dan temukan output pipeline di halaman untuk menjalankan pipeline Anda. Klik tab "Eksperimen" di sebelah kiri, dan "Semua berjalan" di halaman Eksperimen. Anda seharusnya dapat menemukan proses dengan nama alur Anda.
12. Melayani model
Jika model baru sudah siap, buatlah demikian.
- Pusher menyebarkan SavedModels ke lokasi terkenal
Target penerapan menerima model baru dari lokasi terkenal
- Penyajian TensorFlow
- TensorFlow Lite
- TensorFlow JS
- Pusat TensorFlow
Komponen
- Pusher menyebarkan model ke infrastruktur layanan.
Di editor file lab Jupyter:
Di pipeline / pipeline.py , temukan dan hapus komentar pada baris yang menambahkan Pusher ke pipeline:
# components.append(pusher)
Periksa keluaran pipa
Untuk Kubeflow Orchestrator, kunjungi dasbor KFP dan temukan output pipeline di halaman untuk menjalankan pipeline Anda. Klik tab "Eksperimen" di sebelah kiri, dan "Semua berjalan" di halaman Eksperimen. Anda seharusnya dapat menemukan proses dengan nama alur Anda.
Target penerapan yang tersedia
Anda sekarang telah melatih dan memvalidasi model Anda, dan model Anda sekarang siap untuk diproduksi. Anda kini dapat men-deploy model ke salah satu target penerapan TensorFlow, termasuk:
- TensorFlow Serving , untuk menyajikan model Anda di server atau server farm dan memproses permintaan inferensi REST dan/atau gRPC.
- TensorFlow Lite , untuk menyertakan model Anda dalam aplikasi seluler asli Android atau iOS, atau dalam aplikasi Raspberry Pi, IoT, atau mikrokontroler.
- TensorFlow.js , untuk menjalankan model Anda di browser web atau aplikasi Node.JS.
Contoh lebih lanjut
Contoh yang disajikan di atas sebenarnya hanya dimaksudkan untuk membantu Anda memulai. Berikut adalah beberapa contoh integrasi dengan layanan Cloud lainnya.
Pertimbangan sumber daya Kubeflow Pipelines
Bergantung pada persyaratan beban kerja Anda, konfigurasi default untuk penerapan Kubeflow Pipelines Anda mungkin memenuhi kebutuhan Anda atau mungkin tidak. Anda dapat menyesuaikan konfigurasi sumber daya menggunakan pipeline_operator_funcs dalam panggilan Anda ke KubeflowDagRunnerConfig .
pipeline_operator_funcs adalah daftar item OpFunc , yang mengubah semua instance ContainerOp yang dihasilkan dalam spesifikasi pipeline KFP yang dikompilasi dari KubeflowDagRunner .
Misalnya untuk mengkonfigurasi memori kita dapat menggunakan set_memory_request untuk menyatakan jumlah memori yang dibutuhkan. Cara umum untuk melakukannya adalah dengan membuat pembungkus untuk set_memory_request dan menggunakannya untuk menambahkan ke daftar saluran pipa OpFunc s:
def request_more_memory():
def _set_memory_spec(container_op):
container_op.set_memory_request('32G')
return _set_memory_spec
# Then use this opfunc in KubeflowDagRunner
pipeline_op_funcs = kubeflow_dag_runner.get_default_pipeline_operator_funcs()
pipeline_op_funcs.append(request_more_memory())
config = KubeflowDagRunnerConfig(
pipeline_operator_funcs=pipeline_op_funcs,
...
)
kubeflow_dag_runner.KubeflowDagRunner(config=config).run(pipeline)
Fungsi konfigurasi sumber daya serupa meliputi:
-
set_memory_limit -
set_cpu_request -
set_cpu_limit -
set_gpu_limit
Coba BigQueryExampleGen
BigQuery adalah gudang data cloud tanpa server, sangat skalabel, dan hemat biaya. BigQuery dapat digunakan sebagai sumber contoh pelatihan di TFX. Pada langkah ini, kita akan menambahkan BigQueryExampleGen ke pipeline.
Di editor file lab Jupyter:
Klik dua kali untuk membuka pipeline.py . Beri komentar pada CsvExampleGen dan batalkan komentar pada baris yang membuat instance BigQueryExampleGen . Anda juga perlu menghapus komentar pada argumen query fungsi create_pipeline .
Kita perlu menentukan proyek GCP mana yang akan digunakan untuk BigQuery, dan ini dilakukan dengan menyetel --project di beam_pipeline_args saat membuat pipeline.
Klik dua kali untuk membuka configs.py . Batalkan komentar pada definisi BIG_QUERY_WITH_DIRECT_RUNNER_BEAM_PIPELINE_ARGS dan BIG_QUERY_QUERY . Anda harus mengganti id proyek dan nilai wilayah dalam file ini dengan nilai yang benar untuk proyek GCP Anda.
Ubah direktori satu tingkat ke atas. Klik nama direktori di atas daftar file. Nama direktori adalah nama pipeline yaitu my_pipeline jika Anda tidak mengubah nama pipeline.
Klik dua kali untuk membuka kubeflow_runner.py . Batalkan komentar pada dua argumen, query dan beam_pipeline_args , untuk fungsi create_pipeline .
Kini pipeline siap menggunakan BigQuery sebagai sumber contoh. Perbarui alur seperti sebelumnya dan buat eksekusi baru seperti yang kita lakukan pada langkah 5 dan 6.
Perbarui alur dan jalankan kembali
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Coba Aliran Data
Beberapa Komponen TFX menggunakan Apache Beam untuk mengimplementasikan pipeline paralel data, dan ini berarti Anda dapat mendistribusikan beban kerja pemrosesan data menggunakan Google Cloud Dataflow . Pada langkah ini, kita akan mengatur orkestrator Kubeflow untuk menggunakan Dataflow sebagai back-end pemrosesan data untuk Apache Beam.
# Select your project:
gcloud config set project YOUR_PROJECT_ID
# Get a list of services that you can enable in your project:
gcloud services list --available | grep Dataflow
# If you don't see dataflow.googleapis.com listed, that means you haven't been
# granted access to enable the Dataflow API. See your account adminstrator.
# Enable the Dataflow service:
gcloud services enable dataflow.googleapis.com
Klik dua kali pipeline untuk mengubah direktori, dan klik dua kali untuk membuka configs.py . Batalkan komentar pada definisi GOOGLE_CLOUD_REGION , dan DATAFLOW_BEAM_PIPELINE_ARGS .
Ubah direktori satu tingkat ke atas. Klik nama direktori di atas daftar file. Nama direktorinya adalah nama pipeline yaitu my_pipeline jika tidak diubah.
Klik dua kali untuk membuka kubeflow_runner.py . Batalkan komentar beam_pipeline_args . (Pastikan juga untuk mengomentari beam_pipeline_args saat ini yang Anda tambahkan pada Langkah 7.)
Perbarui alur dan jalankan kembali
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Anda dapat menemukan tugas Dataflow Anda di Dataflow di Cloud Console .
Coba Pelatihan dan Prediksi Platform Cloud AI dengan KFP
TFX berinteroperasi dengan beberapa layanan GCP terkelola, seperti Platform Cloud AI untuk Pelatihan dan Prediksi . Anda dapat mengatur komponen Trainer untuk menggunakan Pelatihan Platform Cloud AI, sebuah layanan terkelola untuk melatih model ML. Selain itu, saat model Anda sudah dibuat dan siap untuk ditayangkan, Anda dapat memasukkan model Anda ke Cloud AI Platform Prediction untuk ditayangkan. Pada langkah ini, kami akan mengatur komponen Trainer dan Pusher untuk menggunakan layanan Cloud AI Platform.
Sebelum mengedit file, Anda mungkin harus mengaktifkan AI Platform Training & Prediction API terlebih dahulu.
Klik dua kali pipeline untuk mengubah direktori, dan klik dua kali untuk membuka configs.py . Batalkan komentar pada definisi GOOGLE_CLOUD_REGION , GCP_AI_PLATFORM_TRAINING_ARGS , dan GCP_AI_PLATFORM_SERVING_ARGS . Kita akan menggunakan gambar container yang dibuat khusus untuk melatih model di Pelatihan Platform Cloud AI, jadi kita harus menetapkan masterConfig.imageUri di GCP_AI_PLATFORM_TRAINING_ARGS ke nilai yang sama seperti CUSTOM_TFX_IMAGE di atas.
Ubah direktori satu tingkat ke atas, dan klik dua kali untuk membuka kubeflow_runner.py . Batalkan komentar ai_platform_training_args dan ai_platform_serving_args .
Perbarui alur dan jalankan kembali
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Anda dapat menemukan pekerjaan pelatihan Anda di Pekerjaan Platform Cloud AI . Jika pipeline Anda berhasil diselesaikan, Anda dapat menemukan model Anda di Cloud AI Platform Models .
14. Gunakan data Anda sendiri
Dalam tutorial ini, Anda membuat alur untuk model menggunakan kumpulan data Chicago Taxi. Sekarang coba masukkan data Anda sendiri ke dalam saluran. Data Anda dapat disimpan di mana pun pipeline dapat mengaksesnya, termasuk file Google Cloud Storage, BigQuery, atau CSV.
Anda perlu mengubah definisi alur untuk mengakomodasi data Anda.
Jika data Anda disimpan dalam file
- Ubah
DATA_PATHdikubeflow_runner.py, yang menunjukkan lokasinya.
Jika data Anda disimpan di BigQuery
- Ubah
BIG_QUERY_QUERYdi configs.py menjadi pernyataan kueri Anda. - Tambahkan fitur di
models/features.py. - Ubah
models/preprocessing.pyuntuk mengubah data masukan untuk pelatihan . - Ubah
models/keras/model.pydanmodels/keras/constants.pyuntuk mendeskripsikan model ML Anda .
Pelajari lebih lanjut tentang Pelatih
Lihat Panduan komponen Pelatih untuk detail selengkapnya tentang Alur pelatihan.
Membersihkan
Untuk membersihkan semua resource Google Cloud yang digunakan dalam proyek ini, Anda dapat menghapus proyek Google Cloud yang Anda gunakan untuk tutorial.
Alternatifnya, Anda dapat membersihkan sumber daya individual dengan mengunjungi setiap konsol: - Google Cloud Storage - Google Container Registry - Google Kubernetes Engine