
Hak Cipta 2021 The TF-Agents Authors.
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
pengantar
Contoh ini menunjukkan bagaimana untuk melatih lunak Aktor Critic agen di Minitaur lingkungan.
Jika Anda telah bekerja melalui DQN CoLab ini harus merasa sangat akrab. Perubahan penting termasuk:
- Mengubah agen dari DQN ke SAC.
- Pelatihan Minitaur yang merupakan lingkungan yang jauh lebih kompleks daripada CartPole. Lingkungan Minitaur bertujuan untuk melatih robot berkaki empat untuk bergerak maju.
- Menggunakan TF-Agents Actor-Learner API untuk Pembelajaran Penguatan terdistribusi.
API mendukung pengumpulan data terdistribusi menggunakan buffer replay pengalaman dan penampung variabel (server parameter) dan pelatihan terdistribusi di beberapa perangkat. API dirancang sangat sederhana dan modular. Kami memanfaatkan Reverb untuk kedua penyangga memutar ulang dan variabel kontainer dan API TF DistributionStrategy untuk pelatihan didistribusikan pada GPU dan TPUs.
Jika Anda belum menginstal dependensi berikut, jalankan:
sudo apt-get updatesudo apt-get install -y xvfb ffmpegpip install 'imageio==2.4.0'pip install matplotlibpip install tf-agents[reverb]pip install pybullet
Mempersiapkan
Pertama kita akan mengimpor berbagai alat yang kita butuhkan.
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import os
import reverb
import tempfile
import PIL.Image
import tensorflow as tf
from tf_agents.agents.ddpg import critic_network
from tf_agents.agents.sac import sac_agent
from tf_agents.agents.sac import tanh_normal_projection_network
from tf_agents.environments import suite_pybullet
from tf_agents.metrics import py_metrics
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import greedy_policy
from tf_agents.policies import py_tf_eager_policy
from tf_agents.policies import random_py_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.train import actor
from tf_agents.train import learner
from tf_agents.train import triggers
from tf_agents.train.utils import spec_utils
from tf_agents.train.utils import strategy_utils
from tf_agents.train.utils import train_utils
tempdir = tempfile.gettempdir()
Hyperparameter
env_name = "MinitaurBulletEnv-v0" # @param {type:"string"}
# Use "num_iterations = 1e6" for better results (2 hrs)
# 1e5 is just so this doesn't take too long (1 hr)
num_iterations = 100000 # @param {type:"integer"}
initial_collect_steps = 10000 # @param {type:"integer"}
collect_steps_per_iteration = 1 # @param {type:"integer"}
replay_buffer_capacity = 10000 # @param {type:"integer"}
batch_size = 256 # @param {type:"integer"}
critic_learning_rate = 3e-4 # @param {type:"number"}
actor_learning_rate = 3e-4 # @param {type:"number"}
alpha_learning_rate = 3e-4 # @param {type:"number"}
target_update_tau = 0.005 # @param {type:"number"}
target_update_period = 1 # @param {type:"number"}
gamma = 0.99 # @param {type:"number"}
reward_scale_factor = 1.0 # @param {type:"number"}
actor_fc_layer_params = (256, 256)
critic_joint_fc_layer_params = (256, 256)
log_interval = 5000 # @param {type:"integer"}
num_eval_episodes = 20 # @param {type:"integer"}
eval_interval = 10000 # @param {type:"integer"}
policy_save_interval = 5000 # @param {type:"integer"}
Lingkungan
Lingkungan di RL mewakili tugas atau masalah yang kami coba selesaikan. Lingkungan standar dapat dengan mudah dibuat di TF-Agen menggunakan suites . Kami memiliki berbagai suites untuk memuat lingkungan dari sumber-sumber seperti OpenAI Gym, Atari, DM Control, dll, diberi nama lingkungan tali.
Sekarang mari kita memuat lingkungan Minituar dari suite Pybullet.
env = suite_pybullet.load(env_name)
env.reset()
PIL.Image.fromarray(env.render())
pybullet build time: Oct 11 2021 20:59:00
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/gym/spaces/box.py:74: UserWarning: WARN: Box bound precision lowered by casting to float32
"Box bound precision lowered by casting to {}".format(self.dtype)
current_dir=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_envs/bullet
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data

Dalam lingkungan ini tujuannya adalah agar agen melatih kebijakan yang akan mengendalikan robot Minitaur dan membuatnya bergerak maju secepat mungkin. Episode 1000 langkah terakhir dan pengembaliannya akan menjadi jumlah hadiah sepanjang episode.
Penampilan Mari kita lihat informasi lingkungan menyediakan sebagai observation yang kebijakan akan digunakan untuk menghasilkan actions .
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(28,), dtype=dtype('float32'), name='observation', minimum=[ -3.1515927 -3.1515927 -3.1515927 -3.1515927 -3.1515927
-3.1515927 -3.1515927 -3.1515927 -167.72488 -167.72488
-167.72488 -167.72488 -167.72488 -167.72488 -167.72488
-167.72488 -5.71 -5.71 -5.71 -5.71
-5.71 -5.71 -5.71 -5.71 -1.01
-1.01 -1.01 -1.01 ], maximum=[ 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927
3.1515927 3.1515927 167.72488 167.72488 167.72488 167.72488
167.72488 167.72488 167.72488 167.72488 5.71 5.71
5.71 5.71 5.71 5.71 5.71 5.71
1.01 1.01 1.01 1.01 ])
Action Spec:
BoundedArraySpec(shape=(8,), dtype=dtype('float32'), name='action', minimum=-1.0, maximum=1.0)
Pengamatannya cukup kompleks. Kami menerima 28 nilai yang mewakili sudut, kecepatan, dan torsi untuk semua motor. Sebagai imbalannya lingkungan mengharapkan 8 nilai untuk tindakan antara [-1, 1] . Ini adalah sudut motor yang diinginkan.
Biasanya kami membuat dua lingkungan: satu untuk mengumpulkan data selama pelatihan dan satu untuk evaluasi. Lingkungan ditulis dalam python murni dan menggunakan array numpy, yang dikonsumsi langsung oleh API Pembelajar Aktor.
collect_env = suite_pybullet.load(env_name)
eval_env = suite_pybullet.load(env_name)
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data
Strategi Distribusi
Kami menggunakan API DistributionStrategy untuk mengaktifkan menjalankan komputasi langkah kereta di beberapa perangkat seperti beberapa GPU atau TPU menggunakan paralelisme data. Langkah kereta:
- Menerima sekumpulan data pelatihan
- Membaginya di seluruh perangkat
- Menghitung langkah maju
- Menggabungkan dan menghitung MEAN kerugian
- Menghitung langkah mundur dan melakukan pembaruan variabel gradien
Dengan TF-Agents Learner API dan DistributionStrategy API, cukup mudah untuk beralih antara menjalankan langkah kereta di GPU (menggunakan MirroredStrategy) ke TPU (menggunakan TPUStrategy) tanpa mengubah logika pelatihan apa pun di bawah ini.
Mengaktifkan GPU
Jika Anda ingin mencoba menjalankan GPU, Anda harus mengaktifkan GPU untuk notebook terlebih dahulu:
- Arahkan ke Edit→Pengaturan Notebook
- Pilih GPU dari tarik-turun Akselerator Perangkat Keras
Memilih strategi
Gunakan strategy_utils untuk menghasilkan strategi. Di bawah tenda, melewati parameter:
-
use_gpu = Falsekembalitf.distribute.get_strategy(), yang menggunakan CPU -
use_gpu = Truekembalitf.distribute.MirroredStrategy(), yang menggunakan semua GPU yang terlihat TensorFlow pada satu mesin
use_gpu = True
strategy = strategy_utils.get_strategy(tpu=False, use_gpu=use_gpu)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
Semua variabel dan Agen harus dibuat di bawah strategy.scope() , seperti yang Anda lihat di bawah ini.
Agen
Untuk membuat Agen SAC, pertama-tama kita perlu membuat jaringan yang akan dilatihnya. SAC adalah agen aktor-kritikus, jadi kita akan membutuhkan dua jaringan.
Kritikus akan memberi kita perkiraan nilai Q(s,a) . Artinya, ia akan menerima sebagai masukan pengamatan dan tindakan, dan itu akan memberi kita perkiraan seberapa baik tindakan itu untuk keadaan tertentu.
observation_spec, action_spec, time_step_spec = (
spec_utils.get_tensor_specs(collect_env))
with strategy.scope():
critic_net = critic_network.CriticNetwork(
(observation_spec, action_spec),
observation_fc_layer_params=None,
action_fc_layer_params=None,
joint_fc_layer_params=critic_joint_fc_layer_params,
kernel_initializer='glorot_uniform',
last_kernel_initializer='glorot_uniform')
Kami akan menggunakan kritikus ini untuk melatih actor jaringan yang akan memungkinkan kita untuk menghasilkan tindakan yang diberikan pengamatan.
The ActorNetwork akan memprediksi parameter untuk tanh-tergencet MultivariateNormalDiag distribusi. Distribusi ini kemudian akan dijadikan sampel, dikondisikan pada pengamatan saat ini, kapan pun kita perlu menghasilkan tindakan.
with strategy.scope():
actor_net = actor_distribution_network.ActorDistributionNetwork(
observation_spec,
action_spec,
fc_layer_params=actor_fc_layer_params,
continuous_projection_net=(
tanh_normal_projection_network.TanhNormalProjectionNetwork))
Dengan jaringan ini, sekarang kita dapat membuat instance agen.
with strategy.scope():
train_step = train_utils.create_train_step()
tf_agent = sac_agent.SacAgent(
time_step_spec,
action_spec,
actor_network=actor_net,
critic_network=critic_net,
actor_optimizer=tf.keras.optimizers.Adam(
learning_rate=actor_learning_rate),
critic_optimizer=tf.keras.optimizers.Adam(
learning_rate=critic_learning_rate),
alpha_optimizer=tf.keras.optimizers.Adam(
learning_rate=alpha_learning_rate),
target_update_tau=target_update_tau,
target_update_period=target_update_period,
td_errors_loss_fn=tf.math.squared_difference,
gamma=gamma,
reward_scale_factor=reward_scale_factor,
train_step_counter=train_step)
tf_agent.initialize()
Buffer Putar Ulang
Dalam rangka untuk melacak data yang dikumpulkan dari lingkungan, kita akan menggunakan Reverb , sistem ulangan efisien, extensible, dan mudah digunakan oleh Deepmind. Ini menyimpan data pengalaman yang dikumpulkan oleh Aktor dan dikonsumsi oleh Pelajar selama pelatihan.
Dalam tutorial ini, ini adalah kurang penting dibandingkan max_size - tetapi dalam pengaturan didistribusikan dengan koleksi async dan pelatihan, Anda mungkin akan ingin bereksperimen dengan rate_limiters.SampleToInsertRatio , menggunakan suatu tempat samples_per_insert antara 2 dan 1000. Sebagai contoh:
rate_limiter=reverb.rate_limiters.SampleToInsertRatio(samples_per_insert=3.0, min_size_to_sample=3, error_buffer=3.0)
table_name = 'uniform_table'
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1))
reverb_server = reverb.Server([table])
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpl579aohk. [reverb/cc/platform/tfrecord_checkpointer.cc:386] Loading latest checkpoint from /tmp/tmpl579aohk [reverb/cc/platform/default/server.cc:71] Started replay server on port 15652
Replay buffer dibangun menggunakan spesifikasi menggambarkan tensor yang akan disimpan, yang dapat diperoleh dari agen menggunakan tf_agent.collect_data_spec .
Karena Agen SAC kebutuhan baik saat ini dan observasi di sebelah menghitung kerugian, kami menetapkan sequence_length=2 .
reverb_replay = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
sequence_length=2,
table_name=table_name,
local_server=reverb_server)
Sekarang kita menghasilkan kumpulan data TensorFlow dari buffer pemutaran ulang Reverb. Kami akan meneruskan ini kepada Pelajar untuk mengambil contoh pengalaman untuk pelatihan.
dataset = reverb_replay.as_dataset(
sample_batch_size=batch_size, num_steps=2).prefetch(50)
experience_dataset_fn = lambda: dataset
Kebijakan
Dalam TF-Agen, kebijakan mewakili gagasan standar kebijakan di RL: diberi time_step menghasilkan suatu tindakan atau distribusi melalui tindakan. Metode utama adalah policy_step = policy.step(time_step) di mana policy_step adalah bernama tuple PolicyStep(action, state, info) . The policy_step.action adalah action yang akan diterapkan untuk lingkungan, state mewakili negara untuk stateful (RNN) kebijakan dan info mungkin berisi informasi tambahan seperti probabilitas log tindakan.
Agen berisi dua kebijakan:
-
agent.policy- kebijakan utama yang digunakan untuk evaluasi dan penyebaran. -
agent.collect_policy- Kebijakan kedua yang digunakan untuk pengumpulan data.
tf_eval_policy = tf_agent.policy
eval_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_eval_policy, use_tf_function=True)
tf_collect_policy = tf_agent.collect_policy
collect_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_collect_policy, use_tf_function=True)
Kebijakan dapat dibuat secara independen dari agen. Misalnya, gunakan tf_agents.policies.random_py_policy untuk membuat kebijakan yang secara acak akan memilih tindakan untuk setiap time_step.
random_policy = random_py_policy.RandomPyPolicy(
collect_env.time_step_spec(), collect_env.action_spec())
Aktor
Aktor mengelola interaksi antara kebijakan dan lingkungan.
- Komponen Aktor mengandung sebuah contoh dari lingkungan (sebagai
py_environment) dan salinan dari variabel kebijakan. - Setiap pekerja Aktor menjalankan urutan langkah pengumpulan data yang diberikan nilai lokal dari variabel kebijakan.
- Update variabel dilakukan secara eksplisit menggunakan variabel misalnya wadah klien dalam naskah pelatihan sebelum memanggil
actor.run(). - Pengalaman yang diamati ditulis ke dalam buffer replay di setiap langkah pengumpulan data.
Saat Aktor menjalankan langkah pengumpulan data, mereka melewati lintasan (status, tindakan, hadiah) ke pengamat, yang menyimpan dan menulisnya ke sistem replay Reverb.
Kami menyimpan lintasan untuk frame [(t0, t1) (t1, t2) (t2, t3), ...] karena stride_length=1 .
rb_observer = reverb_utils.ReverbAddTrajectoryObserver(
reverb_replay.py_client,
table_name,
sequence_length=2,
stride_length=1)
Kami membuat Aktor dengan kebijakan acak dan mengumpulkan pengalaman untuk menyemai buffer replay.
initial_collect_actor = actor.Actor(
collect_env,
random_policy,
train_step,
steps_per_run=initial_collect_steps,
observers=[rb_observer])
initial_collect_actor.run()
Instansiasi Aktor dengan kebijakan pengumpulan untuk mengumpulkan lebih banyak pengalaman selama pelatihan.
env_step_metric = py_metrics.EnvironmentSteps()
collect_actor = actor.Actor(
collect_env,
collect_policy,
train_step,
steps_per_run=1,
metrics=actor.collect_metrics(10),
summary_dir=os.path.join(tempdir, learner.TRAIN_DIR),
observers=[rb_observer, env_step_metric])
Buat Aktor yang akan digunakan untuk mengevaluasi kebijakan selama pelatihan. Kami lulus dalam actor.eval_metrics(num_eval_episodes) untuk log metrik kemudian.
eval_actor = actor.Actor(
eval_env,
eval_policy,
train_step,
episodes_per_run=num_eval_episodes,
metrics=actor.eval_metrics(num_eval_episodes),
summary_dir=os.path.join(tempdir, 'eval'),
)
peserta didik
Komponen Pelajar berisi agen dan melakukan pembaruan langkah gradien ke variabel kebijakan menggunakan data pengalaman dari buffer replay. Setelah satu atau beberapa langkah pelatihan, Pembelajar dapat mendorong sekumpulan nilai variabel baru ke wadah variabel.
saved_model_dir = os.path.join(tempdir, learner.POLICY_SAVED_MODEL_DIR)
# Triggers to save the agent's policy checkpoints.
learning_triggers = [
triggers.PolicySavedModelTrigger(
saved_model_dir,
tf_agent,
train_step,
interval=policy_save_interval),
triggers.StepPerSecondLogTrigger(train_step, interval=1000),
]
agent_learner = learner.Learner(
tempdir,
train_step,
tf_agent,
experience_dataset_fn,
triggers=learning_triggers,
strategy=strategy)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' 2021-12-01 12:19:19.139118: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/policy/assets INFO:tensorflow:Assets written to: /tmp/policies/policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:561: UserWarning: Encoding a StructuredValue with type tf_agents.policies.greedy_policy.DeterministicWithLogProb_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered. "imported and registered." % type_spec_class_name) INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function
Metrik dan Evaluasi
Kami dipakai Aktor eval dengan actor.eval_metrics di atas, yang menciptakan metrik paling umum digunakan selama evaluasi kebijakan:
- Pengembalian rata-rata. Pengembaliannya adalah jumlah hadiah yang diperoleh saat menjalankan kebijakan di lingkungan untuk sebuah episode, dan kami biasanya menghitung rata-rata ini selama beberapa episode.
- Durasi episode rata-rata.
Kami menjalankan Aktor untuk menghasilkan metrik ini.
def get_eval_metrics():
eval_actor.run()
results = {}
for metric in eval_actor.metrics:
results[metric.name] = metric.result()
return results
metrics = get_eval_metrics()
def log_eval_metrics(step, metrics):
eval_results = (', ').join(
'{} = {:.6f}'.format(name, result) for name, result in metrics.items())
print('step = {0}: {1}'.format(step, eval_results))
log_eval_metrics(0, metrics)
step = 0: AverageReturn = -0.963870, AverageEpisodeLength = 204.100006
Check out modul metrik untuk implementasi standar lainnya dari metrik yang berbeda.
Melatih agen
Loop pelatihan melibatkan pengumpulan data dari lingkungan dan mengoptimalkan jaringan agen. Sepanjang jalan, kami sesekali akan mengevaluasi kebijakan agen untuk melihat bagaimana kinerja kami.
try:
%%time
except:
pass
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = get_eval_metrics()["AverageReturn"]
returns = [avg_return]
for _ in range(num_iterations):
# Training.
collect_actor.run()
loss_info = agent_learner.run(iterations=1)
# Evaluating.
step = agent_learner.train_step_numpy
if eval_interval and step % eval_interval == 0:
metrics = get_eval_metrics()
log_eval_metrics(step, metrics)
returns.append(metrics["AverageReturn"])
if log_interval and step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, loss_info.loss.numpy()))
rb_observer.close()
reverb_server.stop()
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. step = 5000: loss = -50.77360153198242 step = 10000: AverageReturn = -0.734191, AverageEpisodeLength = 299.399994 step = 10000: loss = -57.17308044433594 step = 15000: loss = -31.02552032470703 step = 20000: AverageReturn = -1.243302, AverageEpisodeLength = 432.200012 step = 20000: loss = -20.673084259033203 step = 25000: loss = -12.919441223144531 step = 30000: AverageReturn = -0.205654, AverageEpisodeLength = 280.049988 step = 30000: loss = -5.420497417449951 step = 35000: loss = -4.320608139038086 step = 40000: AverageReturn = -1.193502, AverageEpisodeLength = 378.000000 step = 40000: loss = -4.375732421875 step = 45000: loss = -3.0430049896240234 step = 50000: AverageReturn = -1.299686, AverageEpisodeLength = 482.549988 step = 50000: loss = -0.8907612562179565 step = 55000: loss = 1.2096503973007202 step = 60000: AverageReturn = -0.949927, AverageEpisodeLength = 365.899994 step = 60000: loss = 1.8157628774642944 step = 65000: loss = -4.9070353507995605 step = 70000: AverageReturn = -0.644635, AverageEpisodeLength = 506.399994 step = 70000: loss = -0.33166465163230896 step = 75000: loss = -0.41273507475852966 step = 80000: AverageReturn = 0.331935, AverageEpisodeLength = 604.299988 step = 80000: loss = 1.5354682207107544 step = 85000: loss = -2.058459997177124 step = 90000: AverageReturn = 0.292840, AverageEpisodeLength = 520.450012 step = 90000: loss = 1.2136361598968506 step = 95000: loss = -1.810737133026123 step = 100000: AverageReturn = 0.835265, AverageEpisodeLength = 515.349976 step = 100000: loss = -2.6997461318969727 [reverb/cc/platform/default/server.cc:84] Shutting down replay server
visualisasi
Plot
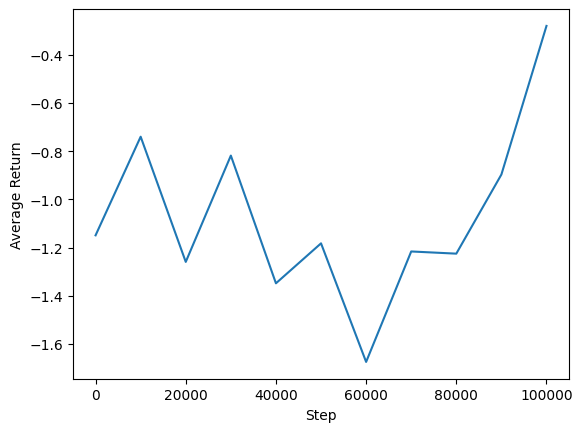
Kami dapat memplot pengembalian rata-rata vs langkah global untuk melihat kinerja agen kami. Dalam Minitaur , fungsi reward didasarkan pada seberapa jauh minitaur yang berjalan di 1000 langkah dan menghukum pengeluaran energi.
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim()
(-1.4064332604408265, 0.9420127034187317)
Video
Sangat membantu untuk memvisualisasikan kinerja agen dengan memberikan lingkungan pada setiap langkah. Sebelum itu, mari kita buat dulu fungsi untuk menyematkan video di colab ini.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
Kode berikut memvisualisasikan kebijakan agen untuk beberapa episode:
num_episodes = 3
video_filename = 'sac_minitaur.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_env.render())
while not time_step.is_last():
action_step = eval_actor.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_env.render())
embed_mp4(video_filename)