
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Tutorial ini adalah bagian kedua dari seri dua bagian yang menunjukkan bagaimana menerapkan jenis kustom dari algoritma federasi di TFF menggunakan Federated Inti (FC) , yang berfungsi sebagai dasar untuk Federasi Belajar (FL) lapisan ( tff.learning ) .
Kami mendorong Anda untuk pertama kali membaca bagian pertama dari seri ini , yang memperkenalkan beberapa konsep kunci dan abstraksi pemrograman yang digunakan di sini.
Bagian kedua dari seri ini menggunakan mekanisme yang diperkenalkan di bagian pertama untuk mengimplementasikan versi sederhana dari algoritma pelatihan dan evaluasi gabungan.
Kami mendorong Anda untuk meninjau klasifikasi citra dan generasi teks tutorial untuk tingkat yang lebih tinggi dan pengenalan lebih lembut untuk TFF Federasi Belajar API, karena mereka akan membantu Anda menempatkan konsep yang kita jelaskan di sini dalam konteks.
Sebelum kita mulai
Sebelum kita mulai, coba jalankan contoh "Hello World" berikut untuk memastikan lingkungan Anda telah diatur dengan benar. Jika tidak bekerja, silakan merujuk ke Instalasi panduan untuk petunjuk.
!pip install --quiet --upgrade tensorflow-federated-nightly
!pip install --quiet --upgrade nest-asyncio
import nest_asyncio
nest_asyncio.apply()
import collections
import numpy as np
import tensorflow as tf
import tensorflow_federated as tff
# Must use the Python context because it
# supports tff.sequence_* intrinsics.
executor_factory = tff.framework.local_executor_factory(
support_sequence_ops=True)
execution_context = tff.framework.ExecutionContext(
executor_fn=executor_factory)
tff.framework.set_default_context(execution_context)
@tff.federated_computation
def hello_world():
return 'Hello, World!'
hello_world()
b'Hello, World!'
Menerapkan Rata-rata Federasi
Seperti dalam Federasi Belajar untuk Gambar Klasifikasi , kita akan menggunakan contoh MNIST, tapi karena ini dimaksudkan sebagai tutorial tingkat rendah, kita akan bypass API Keras dan tff.simulation , menulis kode model yang baku, dan membangun sebuah kumpulan data gabungan dari awal.
Menyiapkan kumpulan data gabungan
Demi demonstrasi, kami akan mensimulasikan skenario di mana kami memiliki data dari 10 pengguna, dan masing-masing pengguna menyumbangkan pengetahuan bagaimana mengenali digit yang berbeda. Ini adalah tentang non iid karena mendapat.
Pertama, mari muat data MNIST standar:
mnist_train, mnist_test = tf.keras.datasets.mnist.load_data()
[(x.dtype, x.shape) for x in mnist_train]
[(dtype('uint8'), (60000, 28, 28)), (dtype('uint8'), (60000,))]
Data datang sebagai array Numpy, satu dengan gambar dan lainnya dengan label digit, keduanya dengan dimensi pertama melewati masing-masing contoh. Mari kita tulis fungsi pembantu yang memformatnya dengan cara yang kompatibel dengan cara kita memasukkan urutan federasi ke dalam perhitungan TFF, yaitu, sebagai daftar daftar - daftar terluar yang berkisar pada pengguna (digit), yang dalam berkisar pada kumpulan data dalam urutan setiap klien. Seperti adat, kita akan menyusun setiap batch sebagai sepasang tensor bernama x dan y , masing-masing dengan dimensi batch yang terkemuka. Sementara itu, kami juga akan meratakan setiap gambar menjadi vektor 784-elemen dan rescale piksel dalam ke dalam 0..1 jangkauan, sehingga kita tidak perlu kekacauan logika model dengan konversi data.
NUM_EXAMPLES_PER_USER = 1000
BATCH_SIZE = 100
def get_data_for_digit(source, digit):
output_sequence = []
all_samples = [i for i, d in enumerate(source[1]) if d == digit]
for i in range(0, min(len(all_samples), NUM_EXAMPLES_PER_USER), BATCH_SIZE):
batch_samples = all_samples[i:i + BATCH_SIZE]
output_sequence.append({
'x':
np.array([source[0][i].flatten() / 255.0 for i in batch_samples],
dtype=np.float32),
'y':
np.array([source[1][i] for i in batch_samples], dtype=np.int32)
})
return output_sequence
federated_train_data = [get_data_for_digit(mnist_train, d) for d in range(10)]
federated_test_data = [get_data_for_digit(mnist_test, d) for d in range(10)]
Sebagai cek kewarasan cepat, tampilan mari di Y tensor dalam batch terakhir dari data yang disumbangkan oleh klien kelima (yang sesuai dengan digit 5 ).
federated_train_data[5][-1]['y']
array([5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5,
5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5,
5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5,
5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5,
5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5], dtype=int32)
Untuk memastikannya, mari kita lihat juga gambar yang sesuai dengan elemen terakhir dari kumpulan itu.
from matplotlib import pyplot as plt
plt.imshow(federated_train_data[5][-1]['x'][-1].reshape(28, 28), cmap='gray')
plt.grid(False)
plt.show()
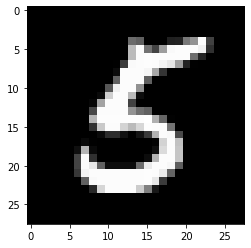
Saat menggabungkan TensorFlow dan TFF
Dalam tutorial ini, untuk kekompakan kami segera menghiasi fungsi yang memperkenalkan TensorFlow logika dengan tff.tf_computation . Namun, untuk logika yang lebih kompleks, ini bukan pola yang kami sarankan. Men-debug TensorFlow sudah bisa menjadi tantangan, dan men-debug TensorFlow setelah sepenuhnya diserialisasi dan kemudian diimpor ulang tentu kehilangan beberapa metadata dan membatasi interaktivitas, membuat debug menjadi lebih sulit.
Oleh karena itu, kami sangat menyarankan menulis logika TF kompleks sebagai fungsi Python berdiri sendiri (yaitu, tanpa tff.tf_computation dekorasi). Dengan cara ini logika TensorFlow dapat dikembangkan dan diuji menggunakan TF praktik terbaik dan alat-alat (seperti modus bersemangat), sebelum serialisasi perhitungan untuk TFF (misalnya, dengan menerapkan tff.tf_computation dengan fungsi Python sebagai argumen).
Mendefinisikan fungsi kerugian
Sekarang setelah kita memiliki data, mari kita definisikan fungsi kerugian yang dapat kita gunakan untuk pelatihan. Pertama, mari kita definisikan tipe input sebagai TFF bernama Tuple. Karena ukuran batch data mungkin bervariasi, kami menetapkan dimensi batch untuk None untuk menunjukkan bahwa ukuran dimensi ini tidak diketahui.
BATCH_SPEC = collections.OrderedDict(
x=tf.TensorSpec(shape=[None, 784], dtype=tf.float32),
y=tf.TensorSpec(shape=[None], dtype=tf.int32))
BATCH_TYPE = tff.to_type(BATCH_SPEC)
str(BATCH_TYPE)
'<x=float32[?,784],y=int32[?]>'
Anda mungkin bertanya-tanya mengapa kita tidak bisa mendefinisikan tipe Python biasa. Ingat diskusi di bagian 1 , di mana kita menjelaskan bahwa sementara kita dapat mengekspresikan logika perhitungan TFF menggunakan Python, di bawah perhitungan kap TFF tidak Python. Simbol BATCH_TYPE didefinisikan di atas merupakan tipe TFF spesifikasi abstrak. Hal ini penting untuk membedakan jenis TFF abstrak ini dari beton jenis representasi Python, misalnya, wadah seperti dict atau collections.namedtuple yang dapat digunakan untuk mewakili jenis TFF dalam tubuh fungsi Python. Tidak seperti Python, TFF memiliki abstrak tipe konstruktor tunggal tff.StructType untuk tupel-seperti kontainer, dengan unsur-unsur yang dapat secara individual bernama atau kiri yang tidak disebutkan namanya. Tipe ini juga digunakan untuk memodelkan parameter formal komputasi, karena komputasi TFF secara formal hanya dapat mendeklarasikan satu parameter dan satu hasil - Anda akan segera melihat contohnya.
Sekarang mari kita menentukan jenis TFF parameter model, lagi sebagai tuple TFF bernama bobot dan bias.
MODEL_SPEC = collections.OrderedDict(
weights=tf.TensorSpec(shape=[784, 10], dtype=tf.float32),
bias=tf.TensorSpec(shape=[10], dtype=tf.float32))
MODEL_TYPE = tff.to_type(MODEL_SPEC)
print(MODEL_TYPE)
<weights=float32[784,10],bias=float32[10]>
Dengan definisi tersebut di tempat, sekarang kita dapat menentukan kerugian untuk model tertentu, lebih dari satu batch. Perhatikan penggunaan @tf.function dekorator dalam @tff.tf_computation dekorator. Hal ini memungkinkan kita untuk menulis TF menggunakan Python seperti semantik meskipun berada di dalam sebuah tf.Graph konteks yang diciptakan oleh tff.tf_computation dekorator.
# NOTE: `forward_pass` is defined separately from `batch_loss` so that it can
# be later called from within another tf.function. Necessary because a
# @tf.function decorated method cannot invoke a @tff.tf_computation.
@tf.function
def forward_pass(model, batch):
predicted_y = tf.nn.softmax(
tf.matmul(batch['x'], model['weights']) + model['bias'])
return -tf.reduce_mean(
tf.reduce_sum(
tf.one_hot(batch['y'], 10) * tf.math.log(predicted_y), axis=[1]))
@tff.tf_computation(MODEL_TYPE, BATCH_TYPE)
def batch_loss(model, batch):
return forward_pass(model, batch)
Seperti yang diharapkan, perhitungan batch_loss kembali float32 kerugian diberikan model dan batch data tunggal. Perhatikan bagaimana MODEL_TYPE dan BATCH_TYPE telah disatukan menjadi 2-tupel dari parameter formal; Anda dapat mengenali jenis batch_loss sebagai (<MODEL_TYPE,BATCH_TYPE> -> float32) .
str(batch_loss.type_signature)
'(<model=<weights=float32[784,10],bias=float32[10]>,batch=<x=float32[?,784],y=int32[?]>> -> float32)'
Sebagai pemeriksaan kewarasan, mari kita buat model awal yang diisi dengan nol dan hitung kerugian atas kumpulan data yang kita visualisasikan di atas.
initial_model = collections.OrderedDict(
weights=np.zeros([784, 10], dtype=np.float32),
bias=np.zeros([10], dtype=np.float32))
sample_batch = federated_train_data[5][-1]
batch_loss(initial_model, sample_batch)
2.3025851
Perhatikan bahwa kita memberi makan perhitungan TFF dengan model awal didefinisikan sebagai dict , meskipun tubuh fungsi Python yang mendefinisikan mengkonsumsi parameter model sebagai model['weight'] dan model['bias'] . Argumen dari panggilan untuk batch_loss tidak hanya dilewatkan ke tubuh fungsi itu.
Apa yang terjadi ketika kita memanggil batch_loss ? Python tubuh batch_loss telah ditelusuri dan serial di sel atas di mana itu didefinisikan. TFF bertindak sebagai pemanggil untuk batch_loss pada perhitungan waktu definisi, dan sebagai target dari doa pada saat batch_loss dipanggil. Dalam kedua peran, TFF berfungsi sebagai jembatan antara sistem tipe abstrak TFF dan tipe representasi Python. Pada saat doa, TFF akan menerima paling standar jenis kontainer Python ( dict , list , tuple , collections.namedtuple , dll) sebagai representasi konkret tupel TFF abstrak. Juga, meskipun seperti disebutkan di atas, perhitungan TFF secara formal hanya menerima satu parameter, Anda dapat menggunakan sintaks panggilan Python yang sudah dikenal dengan argumen posisional dan/atau kata kunci jika tipe parameternya adalah Tuple - ini berfungsi seperti yang diharapkan.
Penurunan gradien pada satu batch
Sekarang, mari kita definisikan komputasi yang menggunakan fungsi kerugian ini untuk melakukan satu langkah penurunan gradien. Perhatikan bagaimana dalam mendefinisikan fungsi ini, kita menggunakan batch_loss sebagai subkomponen. Anda dapat meminta perhitungan dibangun dengan tff.tf_computation dalam tubuh perhitungan lain, meskipun biasanya ini tidak perlu - seperti disebutkan di atas, karena serialisasi kehilangan beberapa informasi debugging, seringkali lebih untuk perhitungan yang lebih kompleks untuk menulis dan menguji semua TensorFlow yang tanpa tff.tf_computation dekorator.
@tff.tf_computation(MODEL_TYPE, BATCH_TYPE, tf.float32)
def batch_train(initial_model, batch, learning_rate):
# Define a group of model variables and set them to `initial_model`. Must
# be defined outside the @tf.function.
model_vars = collections.OrderedDict([
(name, tf.Variable(name=name, initial_value=value))
for name, value in initial_model.items()
])
optimizer = tf.keras.optimizers.SGD(learning_rate)
@tf.function
def _train_on_batch(model_vars, batch):
# Perform one step of gradient descent using loss from `batch_loss`.
with tf.GradientTape() as tape:
loss = forward_pass(model_vars, batch)
grads = tape.gradient(loss, model_vars)
optimizer.apply_gradients(
zip(tf.nest.flatten(grads), tf.nest.flatten(model_vars)))
return model_vars
return _train_on_batch(model_vars, batch)
str(batch_train.type_signature)
'(<initial_model=<weights=float32[784,10],bias=float32[10]>,batch=<x=float32[?,784],y=int32[?]>,learning_rate=float32> -> <weights=float32[784,10],bias=float32[10]>)'
Ketika Anda memanggil fungsi Python dihiasi dengan tff.tf_computation dalam tubuh fungsi lain seperti, logika perhitungan TFF dalam tertanam (dasarnya, inline) dalam logika yang luar. Seperti disebutkan di atas, jika Anda menulis kedua perhitungan, kemungkinan lebih baik untuk membuat fungsi batin ( batch_loss dalam hal ini) Python biasa atau tf.function daripada tff.tf_computation . Namun, di sini kita menggambarkan bahwa memanggil satu tff.tf_computation dalam dasarnya lagi bekerja seperti yang diharapkan. Hal ini mungkin diperlukan jika, misalnya, Anda tidak memiliki kode Python mendefinisikan batch_loss , tetapi hanya representasi TFF serial nya.
Sekarang, mari kita terapkan fungsi ini beberapa kali ke model awal untuk melihat apakah kerugiannya berkurang.
model = initial_model
losses = []
for _ in range(5):
model = batch_train(model, sample_batch, 0.1)
losses.append(batch_loss(model, sample_batch))
losses
[0.19690023, 0.13176313, 0.10113225, 0.08273812, 0.070301384]
Penurunan gradien pada urutan data lokal
Sekarang, karena batch_train muncul untuk bekerja, mari kita menulis fungsi pelatihan serupa local_train bahwa mengkonsumsi seluruh urutan semua batch dari satu pengguna bukan hanya batch tunggal. Perhitungan baru akan perlu sekarang mengkonsumsi tff.SequenceType(BATCH_TYPE) bukan BATCH_TYPE .
LOCAL_DATA_TYPE = tff.SequenceType(BATCH_TYPE)
@tff.federated_computation(MODEL_TYPE, tf.float32, LOCAL_DATA_TYPE)
def local_train(initial_model, learning_rate, all_batches):
@tff.tf_computation(LOCAL_DATA_TYPE, tf.float32)
def _insert_learning_rate_to_sequence(dataset, learning_rate):
return dataset.map(lambda x: (x, learning_rate))
batches_with_learning_rate = _insert_learning_rate_to_sequence(all_batches, learning_rate)
# Mapping function to apply to each batch.
@tff.federated_computation(MODEL_TYPE, batches_with_learning_rate.type_signature.element)
def batch_fn(model, batch_with_lr):
batch, lr = batch_with_lr
return batch_train(model, batch, lr)
return tff.sequence_reduce(batches_with_learning_rate, initial_model, batch_fn)
str(local_train.type_signature)
'(<initial_model=<weights=float32[784,10],bias=float32[10]>,learning_rate=float32,all_batches=<x=float32[?,784],y=int32[?]>*> -> <weights=float32[784,10],bias=float32[10]>)'
Ada beberapa detail yang terkubur di bagian kode yang singkat ini, mari kita bahas satu per satu.
Pertama, sementara kita bisa menerapkan logika ini sepenuhnya di TensorFlow, mengandalkan tf.data.Dataset.reduce untuk memproses urutan sama dengan bagaimana kita sudah melakukannya sebelumnya, kami telah memilih waktu ini untuk mengekspresikan logika dalam bahasa lem , sebagai tff.federated_computation . Kami telah menggunakan operator Federasi tff.sequence_reduce untuk melakukan pengurangan.
Operator tff.sequence_reduce digunakan mirip dengan tf.data.Dataset.reduce . Anda dapat menganggapnya sebagai dasarnya sama dengan tf.data.Dataset.reduce , tetapi untuk penggunaan di dalam perhitungan federasi, yang seperti yang Anda mungkin ingat, tidak dapat berisi kode TensorFlow. Ini adalah operator template dengan parameter formal 3-tupel yang terdiri dari urutan T -typed elemen, keadaan awal dari pengurangan (kami akan menyebutnya secara abstrak sebagai nol) dari beberapa jenis U , dan operator pengurangan ketik (<U,T> -> U) yang alter keadaan reduksi dengan mengolah elemen tunggal. Hasilnya adalah keadaan akhir reduksi, setelah memproses semua elemen secara berurutan. Dalam contoh kita, status reduksi adalah model yang dilatih pada awalan data, dan elemennya adalah kumpulan data.
Kedua, catatan bahwa kita telah kembali digunakan satu perhitungan ( batch_train ) sebagai komponen dalam lain ( local_train ), tetapi tidak secara langsung. Kita tidak bisa menggunakannya sebagai operator reduksi karena membutuhkan parameter tambahan - learning rate. Untuk mengatasi ini, kita mendefinisikan tertanam perhitungan Federasi batch_fn yang mengikat ke local_train 's parameter learning_rate di tubuhnya. Hal ini diperbolehkan untuk perhitungan anak yang didefinisikan dengan cara ini untuk menangkap parameter formal dari induknya selama perhitungan anak tidak dipanggil di luar tubuh induknya. Anda dapat menganggap pola ini sebagai setara dengan functools.partial di Python.
Implikasi praktis menangkap learning_rate cara ini, tentu saja, bahwa nilai learning rate yang sama digunakan di seluruh batch.
Sekarang, mari kita coba fungsi pelatihan yang baru ditetapkan lokal di seluruh urutan data dari pengguna yang sama yang berkontribusi sampel bets (digit 5 ).
locally_trained_model = local_train(initial_model, 0.1, federated_train_data[5])
Apa itu bekerja? Untuk menjawab pertanyaan ini, kita perlu melakukan evaluasi.
Evaluasi lokal
Inilah salah satu cara untuk menerapkan evaluasi lokal dengan menjumlahkan kerugian di semua kumpulan data (kita bisa saja menghitung rata-ratanya dengan baik; kita akan membiarkannya sebagai latihan untuk pembaca).
@tff.federated_computation(MODEL_TYPE, LOCAL_DATA_TYPE)
def local_eval(model, all_batches):
@tff.tf_computation(MODEL_TYPE, LOCAL_DATA_TYPE)
def _insert_model_to_sequence(model, dataset):
return dataset.map(lambda x: (model, x))
model_plus_data = _insert_model_to_sequence(model, all_batches)
@tff.tf_computation(tf.float32, batch_loss.type_signature.result)
def tff_add(accumulator, arg):
return accumulator + arg
return tff.sequence_reduce(
tff.sequence_map(
batch_loss,
model_plus_data), 0., tff_add)
str(local_eval.type_signature)
'(<model=<weights=float32[784,10],bias=float32[10]>,all_batches=<x=float32[?,784],y=int32[?]>*> -> float32)'
Sekali lagi, ada beberapa elemen baru yang diilustrasikan oleh kode ini, mari kita bahas satu per satu.
Pertama, kami telah menggunakan dua operator federasi baru untuk memproses urutan: tff.sequence_map yang mengambil fungsi pemetaan T->U dan urutan T , dan memancarkan urutan U diperoleh dengan menerapkan fungsi pemetaan pointwise, dan tff.sequence_sum bahwa hanya menambahkan semua elemen. Di sini, kami memetakan setiap kumpulan data ke nilai kerugian, dan kemudian menambahkan nilai kerugian yang dihasilkan untuk menghitung total kerugian.
Perhatikan bahwa kita bisa lagi digunakan tff.sequence_reduce , tapi ini tidak akan menjadi pilihan terbaik - proses reduksi, menurut definisi, berurutan, sedangkan pemetaan dan jumlah dapat dihitung secara paralel. Ketika diberi pilihan, yang terbaik adalah tetap menggunakan operator yang tidak membatasi pilihan implementasi, sehingga ketika perhitungan TFF kami dikompilasi di masa mendatang untuk diterapkan ke lingkungan tertentu, seseorang dapat memanfaatkan semua peluang potensial untuk waktu yang lebih cepat. , lebih terukur, eksekusi lebih hemat sumber daya.
Kedua, catatan bahwa sama seperti di local_train , fungsi komponen kita perlu ( batch_loss ) mengambil lebih banyak parameter dari apa operator federasi ( tff.sequence_map ) mengharapkan, jadi kami lagi menentukan parsial, kali ini inline dengan langsung membungkus lambda sebagai tff.federated_computation . Menggunakan pembungkus inline dengan fungsi sebagai argumen adalah cara yang direkomendasikan untuk menggunakan tff.tf_computation untuk menanamkan TensorFlow logika dalam TFF.
Sekarang, mari kita lihat apakah pelatihan kita berhasil.
print('initial_model loss =', local_eval(initial_model,
federated_train_data[5]))
print('locally_trained_model loss =',
local_eval(locally_trained_model, federated_train_data[5]))
initial_model loss = 23.025854 locally_trained_model loss = 0.43484688
Memang, kerugiannya berkurang. Tapi apa yang terjadi jika kita mengevaluasinya pada data pengguna lain?
print('initial_model loss =', local_eval(initial_model,
federated_train_data[0]))
print('locally_trained_model loss =',
local_eval(locally_trained_model, federated_train_data[0]))
initial_model loss = 23.025854 locally_trained_model loss = 74.50075
Seperti yang diharapkan, keadaan menjadi lebih buruk. Model ini dilatih untuk mengenali 5 , dan telah pernah melihat 0 . Hal ini menimbulkan pertanyaan - bagaimana dampak pelatihan lokal terhadap kualitas model dari perspektif global?
Evaluasi gabungan
Ini adalah titik dalam perjalanan kami di mana kami akhirnya kembali ke tipe federasi dan komputasi federasi - topik yang kami mulai. Berikut adalah sepasang definisi tipe TFF untuk model yang berasal dari server, dan data yang tersisa di klien.
SERVER_MODEL_TYPE = tff.type_at_server(MODEL_TYPE)
CLIENT_DATA_TYPE = tff.type_at_clients(LOCAL_DATA_TYPE)
Dengan semua definisi yang diperkenalkan sejauh ini, mengekspresikan evaluasi gabungan di TFF adalah satu baris - kami mendistribusikan model ke klien, membiarkan setiap klien menjalankan evaluasi lokal pada bagian data lokalnya, dan kemudian meratakan kerugiannya. Inilah salah satu cara untuk menulis ini.
@tff.federated_computation(SERVER_MODEL_TYPE, CLIENT_DATA_TYPE)
def federated_eval(model, data):
return tff.federated_mean(
tff.federated_map(local_eval, [tff.federated_broadcast(model), data]))
Kita sudah melihat contoh tff.federated_mean dan tff.federated_map dalam skenario sederhana, dan pada tingkat intuitif, mereka bekerja seperti yang diharapkan, tapi ada lebih banyak di bagian kode dari memenuhi mata, jadi mari kita pergi dengan hati-hati.
Pertama, istirahat Mari kita turun biarkan setiap klien Tanyakan evaluasi lokal pada bagian lokal dari bagian data. Seperti yang Anda ingat dari bagian-bagian sebelumnya, local_eval memiliki tanda tangan jenis bentuk (<MODEL_TYPE, LOCAL_DATA_TYPE> -> float32) .
Operator federasi tff.federated_map adalah template yang menerima sebagai parameter 2-tupel yang terdiri dari fungsi pemetaan beberapa jenis T->U dan nilai federasi tipe {T}@CLIENTS (yaitu, dengan konstituen anggota jenis yang sama sebagai parameter dari fungsi pemetaan), dan kembali hasil dari jenis {U}@CLIENTS .
Karena kita makan local_eval sebagai fungsi pemetaan untuk menerapkan pada basis per-klien, argumen kedua harus dari jenis Federasi {<MODEL_TYPE, LOCAL_DATA_TYPE>}@CLIENTS , yaitu, dalam nomenklatur bagian sebelumnya, mestinya menjadi tupel federasi. Setiap klien harus memegang set lengkap argumen untuk local_eval sebagai konstituen anggota. Sebaliknya, kita makan itu 2-elemen Python list . Apa yang sedang terjadi disini?
Memang, ini adalah contoh dari jenis cor implisit di TFF, mirip dengan jenis gips implisit Anda mungkin temui di tempat lain, misalnya, ketika Anda memberi makan int ke fungsi yang menerima float . Pengecoran implisit jarang digunakan pada saat ini, tetapi kami berencana untuk membuatnya lebih meresap di TFF sebagai cara untuk meminimalkan boilerplate.
Para pemain implisit yang diterapkan dalam hal ini adalah kesetaraan antara tupel federasi dari bentuk {<X,Y>}@Z , dan tupel dari federasi nilai <{X}@Z,{Y}@Z> . Sementara secara resmi, kedua adalah jenis tanda tangan yang berbeda, melihat dari sudut pandang programmer, masing-masing perangkat dalam Z memegang dua unit data X dan Y . Apa yang terjadi di sini adalah tidak seperti zip di Python, dan memang, kami menawarkan sebuah operator tff.federated_zip yang memungkinkan Anda untuk melakukan konversi tersebut secara eksplisit. Ketika tff.federated_map bertemu dengan tuple sebagai argumen kedua, itu hanya memanggil tff.federated_zip untuk Anda.
Diberikan di atas, Anda sekarang harus mampu mengenali ekspresi tff.federated_broadcast(model) sebagai mewakili nilai TFF jenis {MODEL_TYPE}@CLIENTS , dan data sebagai nilai TFF jenis {LOCAL_DATA_TYPE}@CLIENTS (atau hanya CLIENT_DATA_TYPE ) , dua mendapatkan disaring bersama-sama melalui implisit tff.federated_zip untuk membentuk argumen kedua untuk tff.federated_map .
Operator tff.federated_broadcast , seperti yang Anda harapkan, hanya transfer data dari server ke klien.
Sekarang, mari kita lihat bagaimana pelatihan lokal kita mempengaruhi kerugian rata-rata dalam sistem.
print('initial_model loss =', federated_eval(initial_model,
federated_train_data))
print('locally_trained_model loss =',
federated_eval(locally_trained_model, federated_train_data))
initial_model loss = 23.025852 locally_trained_model loss = 54.432625
Memang, seperti yang diharapkan, kerugiannya meningkat. Untuk meningkatkan model bagi semua pengguna, kita perlu melatih data semua orang.
Pelatihan gabungan
Cara paling sederhana untuk menerapkan pelatihan gabungan adalah dengan melatih secara lokal, dan kemudian membuat rata-rata modelnya. Ini menggunakan blok bangunan dan pola yang sama yang telah kita bahas, seperti yang Anda lihat di bawah.
SERVER_FLOAT_TYPE = tff.type_at_server(tf.float32)
@tff.federated_computation(SERVER_MODEL_TYPE, SERVER_FLOAT_TYPE,
CLIENT_DATA_TYPE)
def federated_train(model, learning_rate, data):
return tff.federated_mean(
tff.federated_map(local_train, [
tff.federated_broadcast(model),
tff.federated_broadcast(learning_rate), data
]))
Perhatikan bahwa dalam pelaksanaan fitur lengkap dari Federasi Averaging disediakan oleh tff.learning , daripada rata-rata model, kami lebih memilih untuk rata-rata Model delta, untuk sejumlah alasan, misalnya, kemampuan untuk klip update norma-norma, untuk kompresi, dll .
Mari kita lihat apakah latihan itu berhasil dengan menjalankan beberapa putaran latihan dan membandingkan rata-rata kerugian sebelum dan sesudahnya.
model = initial_model
learning_rate = 0.1
for round_num in range(5):
model = federated_train(model, learning_rate, federated_train_data)
learning_rate = learning_rate * 0.9
loss = federated_eval(model, federated_train_data)
print('round {}, loss={}'.format(round_num, loss))
round 0, loss=21.60552215576172 round 1, loss=20.365678787231445 round 2, loss=19.27480125427246 round 3, loss=18.311111450195312 round 4, loss=17.45725440979004
Untuk kelengkapan, sekarang mari kita juga menjalankan data uji untuk mengonfirmasi bahwa model kita dapat digeneralisasi dengan baik.
print('initial_model test loss =',
federated_eval(initial_model, federated_test_data))
print('trained_model test loss =', federated_eval(model, federated_test_data))
initial_model test loss = 22.795593 trained_model test loss = 17.278767
Ini mengakhiri tutorial kami.
Tentu saja, contoh sederhana kami tidak mencerminkan sejumlah hal yang perlu Anda lakukan dalam skenario yang lebih realistis - misalnya, kami belum menghitung metrik selain kerugian. Kami mendorong Anda untuk mempelajari pelaksanaan dari rata-rata federasi di tff.learning sebagai contoh yang lebih lengkap, dan sebagai cara untuk menunjukkan beberapa praktek coding kami ingin mendorong.