
| | |  GitHub에서 소스 보기 GitHub에서 소스 보기 | |
이 튜토리얼은 일부 클라이언트 매개 변수는 서버에서 집계되지 않습니다 일부 지역 연합 학습을 탐구한다. 이는 사용자별 매개변수가 있는 모델(예: 행렬 분해 모델)과 통신 제한 설정에서 훈련하는 데 유용합니다. 우리는에 소개 된 개념을 토대로 이미지 분류를위한 연합 학습 튜토리얼; 이 튜토리얼에서, 우리는 높은 수준의 API를 소개 tff.learning 연합 훈련 및 평가.
우리는 부분적으로 지역 연합 학습 동기를 부여하는 것으로 시작 행렬 인수 분해 . 우리는 기술 연합 재건 , 규모의 부분적 지역 연합 학습을위한 실제적인 알고리즘을. MovieLens 1M 데이터 세트를 준비하고 부분적으로 로컬 모델을 구축하고 훈련 및 평가합니다.
!pip install --quiet --upgrade tensorflow-federated-nightly
!pip install --quiet --upgrade nest-asyncio
import nest_asyncio
nest_asyncio.apply()
import collections
import functools
import io
import os
import requests
import zipfile
from typing import List, Optional, Tuple
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_federated as tff
np.random.seed(42)
배경: 행렬 분해
행렬 인수 분해는 권장 사항을 학습 및 사용자 상호 작용을 기반으로 항목에 대한 표현을 삽입하는 역사적으로 인기있는 기술이었다. 정식 예제는이 곳, 영화 추천입니다 \(n\) 사용자와 \(m\) 영화, 사용자가 어떤 영화를 평가했다. 특정 사용자에게 평가 기록과 유사한 사용자의 평가를 사용하여 사용자가 보지 않은 영화에 대한 사용자의 평가를 예측합니다. 등급을 예측할 수 있는 모델이 있다면 사용자가 즐길 수 있는 새 영화를 쉽게 추천할 수 있습니다.
이 작업을 위해, 그것은으로 사용자의 등급을 나타내는 유용 \(n \times m\) 매트릭스 \(R\):

이 행렬은 일반적으로 사용자가 데이터세트에서 영화의 작은 부분만 보기 때문에 일반적으로 희소합니다. 매트릭스 분해의 출력은 두 매트릭스이다 :는 \(n \times k\) 매트릭스 \(U\) 나타내는 \(k\)각 사용자 차원 사용자 묻어을하고 \(m \times k\) 매트릭스 \(I\) 나타내는 \(k\)각 항목 차원 부품 묻어있다. 간단한 교육 목표는 사용자와 항목 묻어의 내적 관찰 평가의 예측 있는지 확인하는 것입니다 \(O\):
\[argmin_{U,I} \sum_{(u, i) \in O} (R_{ui} - U_u I_i^T)^2\]
이는 관찰된 등급과 해당 사용자의 내적 및 항목 임베딩을 통해 예측된 등급 간의 평균 제곱 오차를 최소화하는 것과 같습니다. 이 해석하는 또 다른 방법은이 것을 보장입니다 \(R \approx UI^T\) 알려진 등급에 대한, 따라서 "행렬 인수 분해". 이것이 혼란스럽더라도 걱정하지 마십시오. 튜토리얼의 나머지 부분에서 행렬 분해의 세부 사항을 알 필요가 없습니다.
MovieLens 데이터 탐색
의는로드 시작하자 MovieLens 100 만 3706 영화에 6040 사용자로부터 1,000,209 영화 등급으로 구성 데이터를.
def download_movielens_data(dataset_path):
"""Downloads and copies MovieLens data to local /tmp directory."""
if dataset_path.startswith('http'):
r = requests.get(dataset_path)
z = zipfile.ZipFile(io.BytesIO(r.content))
z.extractall(path='/tmp')
else:
tf.io.gfile.makedirs('/tmp/ml-1m/')
for filename in ['ratings.dat', 'movies.dat', 'users.dat']:
tf.io.gfile.copy(
os.path.join(dataset_path, filename),
os.path.join('/tmp/ml-1m/', filename),
overwrite=True)
download_movielens_data('http://files.grouplens.org/datasets/movielens/ml-1m.zip')
def load_movielens_data(
data_directory: str = "/tmp",
) -> Tuple[pd.DataFrame, pd.DataFrame]:
"""Loads pandas DataFrames for ratings, movies, users from data directory."""
# Load pandas DataFrames from data directory. Assuming data is formatted as
# specified in http://files.grouplens.org/datasets/movielens/ml-1m-README.txt.
ratings_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "ratings.dat"),
sep="::",
names=["UserID", "MovieID", "Rating", "Timestamp"], engine="python")
movies_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "movies.dat"),
sep="::",
names=["MovieID", "Title", "Genres"], engine="python")
# Create dictionaries mapping from old IDs to new (remapped) IDs for both
# MovieID and UserID. Use the movies and users present in ratings_df to
# determine the mapping, since movies and users without ratings are unneeded.
movie_mapping = {
old_movie: new_movie for new_movie, old_movie in enumerate(
ratings_df.MovieID.astype("category").cat.categories)
}
user_mapping = {
old_user: new_user for new_user, old_user in enumerate(
ratings_df.UserID.astype("category").cat.categories)
}
# Map each DataFrame consistently using the now-fixed mapping.
ratings_df.MovieID = ratings_df.MovieID.map(movie_mapping)
ratings_df.UserID = ratings_df.UserID.map(user_mapping)
movies_df.MovieID = movies_df.MovieID.map(movie_mapping)
# Remove nulls resulting from some movies being in movies_df but not
# ratings_df.
movies_df = movies_df[pd.notnull(movies_df.MovieID)]
return ratings_df, movies_df
등급 및 영화 데이터가 포함된 두 개의 Pandas DataFrames를 로드하고 탐색해 보겠습니다.
ratings_df, movies_df = load_movielens_data()
각 등급 예에는 1-5의 등급, 해당 UserID, 해당 MovieID 및 타임스탬프가 있음을 알 수 있습니다.
ratings_df.head()
각 영화에는 제목과 잠재적으로 여러 장르가 있습니다.
movies_df.head()
데이터 세트의 기본 통계를 이해하는 것은 항상 좋은 생각입니다.
print('Num users:', len(set(ratings_df.UserID)))
print('Num movies:', len(set(ratings_df.MovieID)))
Num users: 6040 Num movies: 3706
ratings = ratings_df.Rating.tolist()
plt.hist(ratings, bins=5)
plt.xticks([1, 2, 3, 4, 5])
plt.ylabel('Count')
plt.xlabel('Rating')
plt.show()
print('Average rating:', np.mean(ratings))
print('Median rating:', np.median(ratings))
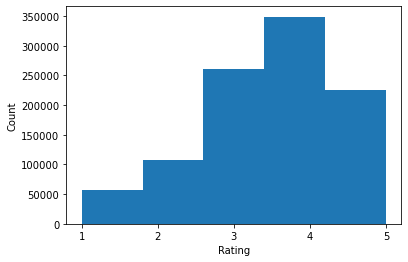
Average rating: 3.581564453029317 Median rating: 4.0
우리는 또한 가장 인기 있는 영화 장르를 그릴 수 있습니다.
movie_genres_list = movies_df.Genres.tolist()
# Count the number of times each genre describes a movie.
genre_count = collections.defaultdict(int)
for genres in movie_genres_list:
curr_genres_list = genres.split('|')
for genre in curr_genres_list:
genre_count[genre] += 1
genre_name_list, genre_count_list = zip(*genre_count.items())
plt.figure(figsize=(11, 11))
plt.pie(genre_count_list, labels=genre_name_list)
plt.title('MovieLens Movie Genres')
plt.show()
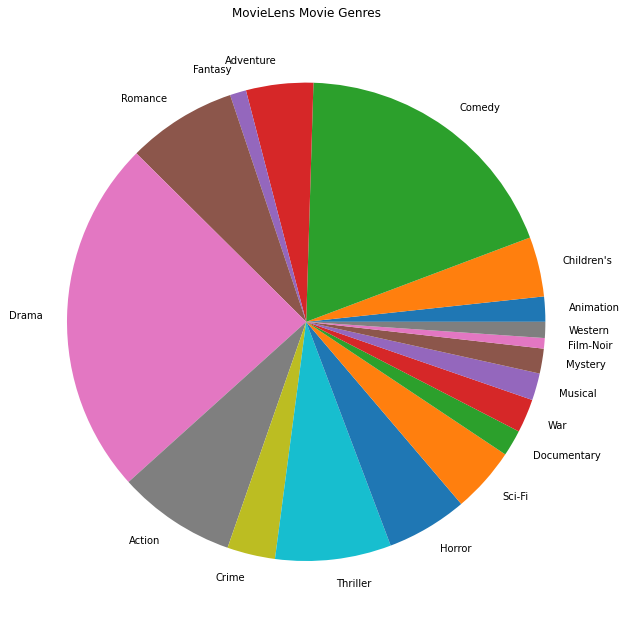
이 데이터는 자연스럽게 다른 사용자의 평가로 분할되므로 클라이언트 간에 데이터가 약간 이질적일 것으로 예상됩니다. 아래에는 다양한 사용자에게 가장 일반적으로 등급이 매겨진 영화 장르가 표시됩니다. 우리는 사용자들 사이에 상당한 차이를 관찰할 수 있습니다.
def print_top_genres_for_user(ratings_df, movies_df, user_id):
"""Prints top movie genres for user with ID user_id."""
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
movie_ids = user_ratings_df.MovieID
genre_count = collections.Counter()
for movie_id in movie_ids:
genres_string = movies_df[movies_df.MovieID == movie_id].Genres.tolist()[0]
for genre in genres_string.split('|'):
genre_count[genre] += 1
print(f'\nFor user {user_id}:')
for (genre, freq) in genre_count.most_common(5):
print(f'{genre} was rated {freq} times')
print_top_genres_for_user(ratings_df, movies_df, user_id=0)
print_top_genres_for_user(ratings_df, movies_df, user_id=10)
print_top_genres_for_user(ratings_df, movies_df, user_id=19)
For user 0: Drama was rated 21 times Children's was rated 20 times Animation was rated 18 times Musical was rated 14 times Comedy was rated 14 times For user 10: Comedy was rated 84 times Drama was rated 54 times Romance was rated 22 times Thriller was rated 18 times Action was rated 9 times For user 19: Action was rated 17 times Sci-Fi was rated 9 times Thriller was rated 9 times Drama was rated 6 times Crime was rated 5 times
MovieLens 데이터 전처리
우리는 지금의 목록으로 MovieLens 데이터 집합을 준비합니다 tf.data.Dataset 의 TFF 사용하기 위해 각 사용자의 데이터를 나타내는.
우리는 두 가지 기능을 구현합니다:
-
create_tf_datasets: 우리의 평가 DataFrame 소요되며 사용자 분할의 목록 생성tf.data.Dataset들. -
split_tf_datasets다음 발 / 테스트 세트는 훈련 도중 보이지 않는 사용자 만 등급이 포함되어 있으므로, 데이터 세트 및 사용자에 의해 기차 / 발 / 테스트로 분할을 목록을합니다. 보이지 않는 사용자가 사용자 묻어을 가지고 있지 않기 때문에 일반적으로 표준 중앙 행렬 인수 분해에 우리는 실제로 발 / 테스트 세트를 본 사용자에서 열린 아웃 등급이 포함되도록 분할합니다. 우리의 경우 FL에서 행렬 분해를 활성화하는 데 사용하는 접근 방식이 보이지 않는 사용자에 대한 사용자 임베딩을 빠르게 재구성할 수도 있다는 것을 나중에 알게 될 것입니다.
def create_tf_datasets(ratings_df: pd.DataFrame,
batch_size: int = 1,
max_examples_per_user: Optional[int] = None,
max_clients: Optional[int] = None) -> List[tf.data.Dataset]:
"""Creates TF Datasets containing the movies and ratings for all users."""
num_users = len(set(ratings_df.UserID))
# Optionally limit to `max_clients` to speed up data loading.
if max_clients is not None:
num_users = min(num_users, max_clients)
def rating_batch_map_fn(rating_batch):
"""Maps a rating batch to an OrderedDict with tensor values."""
# Each example looks like: {x: movie_id, y: rating}.
# We won't need the UserID since each client will only look at their own
# data.
return collections.OrderedDict([
("x", tf.cast(rating_batch[:, 1:2], tf.int64)),
("y", tf.cast(rating_batch[:, 2:3], tf.float32))
])
tf_datasets = []
for user_id in range(num_users):
# Get subset of ratings_df belonging to a particular user.
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
tf_dataset = tf.data.Dataset.from_tensor_slices(user_ratings_df)
# Define preprocessing operations.
tf_dataset = tf_dataset.take(max_examples_per_user).shuffle(
buffer_size=max_examples_per_user, seed=42).batch(batch_size).map(
rating_batch_map_fn,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
tf_datasets.append(tf_dataset)
return tf_datasets
def split_tf_datasets(
tf_datasets: List[tf.data.Dataset],
train_fraction: float = 0.8,
val_fraction: float = 0.1,
) -> Tuple[List[tf.data.Dataset], List[tf.data.Dataset], List[tf.data.Dataset]]:
"""Splits a list of user TF datasets into train/val/test by user.
"""
np.random.seed(42)
np.random.shuffle(tf_datasets)
train_idx = int(len(tf_datasets) * train_fraction)
val_idx = int(len(tf_datasets) * (train_fraction + val_fraction))
# Note that the val and test data contains completely different users, not
# just unseen ratings from train users.
return (tf_datasets[:train_idx], tf_datasets[train_idx:val_idx],
tf_datasets[val_idx:])
# We limit the number of clients to speed up dataset creation. Feel free to pass
# max_clients=None to load all clients' data.
tf_datasets = create_tf_datasets(
ratings_df=ratings_df,
batch_size=5,
max_examples_per_user=300,
max_clients=2000)
# Split the ratings into training/val/test by client.
tf_train_datasets, tf_val_datasets, tf_test_datasets = split_tf_datasets(
tf_datasets,
train_fraction=0.8,
val_fraction=0.1)
빠른 확인으로 훈련 데이터 배치를 인쇄할 수 있습니다. 각각의 개별 예제에는 "x" 키 아래에 MovieID가 있고 "y" 키 아래에 등급이 포함되어 있음을 알 수 있습니다. 각 사용자는 자신의 데이터만 볼 수 있으므로 UserID가 필요하지 않습니다.
print(next(iter(tf_train_datasets[0])))
OrderedDict([('x', <tf.Tensor: shape=(5, 1), dtype=int64, numpy=
array([[1907],
[2891],
[1574],
[2785],
[2775]])>), ('y', <tf.Tensor: shape=(5, 1), dtype=float32, numpy=
array([[3.],
[3.],
[3.],
[4.],
[3.]], dtype=float32)>)])
사용자당 평점 수를 보여주는 히스토그램을 그릴 수 있습니다.
def count_examples(curr_count, batch):
return curr_count + tf.size(batch['x'])
num_examples_list = []
# Compute number of examples for every other user.
for i in range(0, len(tf_train_datasets), 2):
num_examples = tf_train_datasets[i].reduce(tf.constant(0), count_examples).numpy()
num_examples_list.append(num_examples)
plt.hist(num_examples_list, bins=10)
plt.ylabel('Count')
plt.xlabel('Number of Examples')
plt.show()
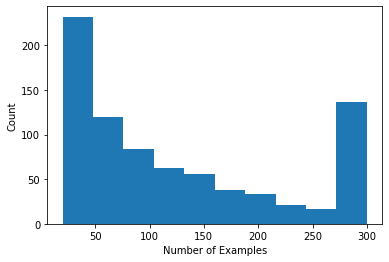
데이터를 로드하고 탐색했으므로 이제 행렬 분해를 연합 학습에 적용하는 방법에 대해 논의하겠습니다. 그 과정에서 우리는 부분적으로 지역 연합 학습에 동기를 부여할 것입니다.
FL에 행렬 분해 도입
행렬 인수분해는 전통적으로 중앙 집중식 설정에서 사용되었지만 특히 연합 학습과 관련이 있습니다. 사용자 평가는 별도의 클라이언트 장치에 있을 수 있으며 데이터를 중앙 집중화하지 않고 사용자 및 항목에 대한 임베딩 및 권장 사항을 배우고 싶을 수 있습니다. 각 사용자는 해당 사용자 임베딩을 가지고 있으므로 각 클라이언트가 사용자 임베딩을 저장하는 것은 당연합니다. 이는 모든 사용자 임베딩을 저장하는 중앙 서버보다 훨씬 더 잘 확장됩니다.
행렬 분해를 FL로 가져오기 위한 한 가지 제안은 다음과 같습니다.
- 서버 저장 및 아이템 매트릭스 전송 \(I\) 샘플링 클라이언트 각 라운드
- 클라이언트는 항목 매트릭스를 업데이트하고 개인 사용자는 내장 \(U_u\) 위의 목적에 SGD를 사용하여
- 업데이트 \(I\) 의 서버 복사본 업데이트 서버에 집계됩니다 \(I\) 다음 라운드에 대한
이 방법은, 일부 클라이언트 매개 변수는 서버에서 집계되지 않습니다 - 즉 부분적으로 지역이다. 이 접근 방식은 매력적이지만 클라이언트가 라운드 전반에 걸쳐 상태, 즉 사용자 임베딩을 유지해야 합니다. 상태 저장 연합 알고리즘은 기기 간 FL 설정에 덜 적합합니다. 이러한 설정에서 인구 규모는 종종 각 라운드에 참여하는 클라이언트의 수보다 훨씬 더 크며 클라이언트는 일반적으로 교육 프로세스 중에 최대 한 번만 참여합니다. 클라이언트가 자주 샘플링 할 때 초기화되지 않을 수 있습니다 상태에 의존하는 외에, 상태 기반 알고리즘으로 인해 상태가 점점 부실에 대한 상호 장치 설정에서 성능 저하가 발생할 수 있습니다. 중요하게도, 행렬 분해 설정에서 상태 저장 알고리즘은 보이지 않는 모든 클라이언트가 훈련된 사용자 임베딩을 놓치게 하고 대규모 훈련에서는 대부분의 사용자가 보이지 않을 수 있습니다. 기기 간에서의 무 FL 알고리즘 동기에 대한 자세한 내용은, 참조 왕 외. 2021년 초 3.1.1 및 Reddi 등. 2020년 초 5.1 .
연합 재구성 ( 외. Singhal이 2021가 ) 상기 방법에 무 대안이다. 핵심 아이디어는 라운드에 걸쳐 사용자 임베딩을 저장하는 대신 클라이언트가 필요할 때 사용자 임베딩을 재구성한다는 것입니다. FedRecon을 행렬 인수분해에 적용하면 다음과 같이 훈련이 진행됩니다.
- 서버 저장 및 아이템 매트릭스 전송 \(I\) 샘플링 클라이언트 각 라운드
- 각 클라이언트는 정지 \(I\) 하고 자신의 사용자 내장 훈련 \(U_u\) SGD 하나 이상의 단계를 사용하여 (재건)
- 각 클라이언트는 정지 \(U_u\) 와 기차 \(I\) SGD 중 하나 이상의 단계를 사용하여
- 업데이트 \(I\) 의 서버 복사본 업데이트, 사용자에 걸쳐 집계됩니다 \(I\) 다음 라운드에 대한
이 접근 방식에서는 클라이언트가 라운드 동안 상태를 유지할 필요가 없습니다. 저자는 또한 이 방법이 보이지 않는 클라이언트(4.2절, 그림 3 및 표 1)에 대한 사용자 임베딩의 빠른 재구성으로 이어져 훈련에 참여하지 않는 대다수의 클라이언트가 훈련된 모델을 가질 수 있도록 한다는 것을 논문에서 보여줍니다. , 이러한 클라이언트에 대한 권장 사항을 활성화합니다.
모델 정의
다음으로 클라이언트 장치에서 훈련할 로컬 행렬 분해 모델을 정의합니다. 이 모델은 전체 항목의 행렬이 포함됩니다 \(I\) 과 단일 사용자 매입 \(U_u\) 클라이언트에 대한 \(u\). 클라이언트가 전체 사용자 행렬 저장하는 데 필요하지 않습니다 \(U\).
다음을 정의합니다.
-
UserEmbedding: 단일 나타내는 간단한 Keras 층num_latent_factors차원 사용자 임베딩. -
get_matrix_factorization_model: 리턴하는 기능tff.learning.reconstruction.Model층은 전 세계적으로 서버에서 집계하고있는 층이 지역을 유지하는 포함하여 모델 로직을 포함. Federated Reconstruction 교육 프로세스를 초기화하려면 이 추가 정보가 필요합니다. 여기서 우리는 생산tff.learning.reconstruction.Model사용하여 Keras 모델에서tff.learning.reconstruction.from_keras_model. 유사tff.learning.Model, 우리는 또한 사용자 정의 구현할 수tff.learning.reconstruction.Model클래스 인터페이스를 구현하여.
class UserEmbedding(tf.keras.layers.Layer):
"""Keras layer representing an embedding for a single user, used below."""
def __init__(self, num_latent_factors, **kwargs):
super().__init__(**kwargs)
self.num_latent_factors = num_latent_factors
def build(self, input_shape):
self.embedding = self.add_weight(
shape=(1, self.num_latent_factors),
initializer='uniform',
dtype=tf.float32,
name='UserEmbeddingKernel')
super().build(input_shape)
def call(self, inputs):
return self.embedding
def compute_output_shape(self):
return (1, self.num_latent_factors)
def get_matrix_factorization_model(
num_items: int,
num_latent_factors: int) -> tff.learning.reconstruction.Model:
"""Defines a Keras matrix factorization model."""
# Layers with variables will be partitioned into global and local layers.
# We'll pass this to `tff.learning.reconstruction.from_keras_model`.
global_layers = []
local_layers = []
# Extract the item embedding.
item_input = tf.keras.layers.Input(shape=[1], name='Item')
item_embedding_layer = tf.keras.layers.Embedding(
num_items,
num_latent_factors,
name='ItemEmbedding')
global_layers.append(item_embedding_layer)
flat_item_vec = tf.keras.layers.Flatten(name='FlattenItems')(
item_embedding_layer(item_input))
# Extract the user embedding.
user_embedding_layer = UserEmbedding(
num_latent_factors,
name='UserEmbedding')
local_layers.append(user_embedding_layer)
# The item_input never gets used by the user embedding layer,
# but this allows the model to directly use the user embedding.
flat_user_vec = user_embedding_layer(item_input)
# Compute the dot product between the user embedding, and the item one.
pred = tf.keras.layers.Dot(
1, normalize=False, name='Dot')([flat_user_vec, flat_item_vec])
input_spec = collections.OrderedDict(
x=tf.TensorSpec(shape=[None, 1], dtype=tf.int64),
y=tf.TensorSpec(shape=[None, 1], dtype=tf.float32))
model = tf.keras.Model(inputs=item_input, outputs=pred)
return tff.learning.reconstruction.from_keras_model(
keras_model=model,
global_layers=global_layers,
local_layers=local_layers,
input_spec=input_spec)
연합 평균화의 인터페이스와 똑같이, 연합 재건을위한 인터페이스는 기대 model_fn 인수 반환하는 A를 tff.learning.reconstruction.Model .
# This will be used to produce our training process.
# User and item embeddings will be 50-dimensional.
model_fn = functools.partial(
get_matrix_factorization_model,
num_items=3706,
num_latent_factors=50)
우리는 다음을 정의합니다 loss_fn 및 metrics_fn , loss_fn 모델을 훈련하는 데 사용할 Keras 손실을 반환 인수가없는 기능이며, metrics_fn 평가 Keras 메트릭의 목록을 반환하는 인수가없는 기능입니다. 이는 훈련 및 평가 계산을 구축하는 데 필요합니다.
위에서 언급한 것처럼 평균 제곱 오차를 손실로 사용합니다. 평가를 위해 평가 정확도를 사용합니다(모델의 예측 내적이 가장 가까운 정수로 반올림되면 레이블 평가와 얼마나 자주 일치합니까?).
class RatingAccuracy(tf.keras.metrics.Mean):
"""Keras metric computing accuracy of reconstructed ratings."""
def __init__(self,
name: str = 'rating_accuracy',
**kwargs):
super().__init__(name=name, **kwargs)
def update_state(self,
y_true: tf.Tensor,
y_pred: tf.Tensor,
sample_weight: Optional[tf.Tensor] = None):
absolute_diffs = tf.abs(y_true - y_pred)
# A [batch_size, 1] tf.bool tensor indicating correctness within the
# threshold for each example in a batch. A 0.5 threshold corresponds
# to correctness when predictions are rounded to the nearest whole
# number.
example_accuracies = tf.less_equal(absolute_diffs, 0.5)
super().update_state(example_accuracies, sample_weight=sample_weight)
loss_fn = lambda: tf.keras.losses.MeanSquaredError()
metrics_fn = lambda: [RatingAccuracy()]
교육 및 평가
이제 교육 프로세스를 정의하는 데 필요한 모든 것이 준비되었습니다. 로부터 한 가지 중요한 차이점 연합 평균화 인터페이스는 우리가 지금 전달한다는 것이다 reconstruction_optimizer_fn (우리의 경우, 사용자에 묻어) 지역 파라미터를 복원 할 때 사용된다. 그것은 사용하는 일반적으로 합리적 SGD 유사한로, 여기에 또는 약간 속도를 학습 최적화 클라이언트보다 속도를 학습 낮 춥니 다. 아래에서 작동 구성을 제공합니다. 이것은 주의 깊게 조정되지 않았으므로 다른 값으로 자유롭게 플레이하십시오.
아웃 확인 문서 자세한 내용과 옵션을.
# We'll use this by doing:
# state = training_process.initialize()
# state, metrics = training_process.next(state, federated_train_data)
training_process = tff.learning.reconstruction.build_training_process(
model_fn=model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(1.0),
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.5),
reconstruction_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.1))
훈련된 글로벌 모델을 평가하기 위한 계산을 정의할 수도 있습니다.
# We'll use this by doing:
# eval_metrics = evaluation_computation(state.model, tf_val_datasets)
# where `state` is the state from the training process above.
evaluation_computation = tff.learning.reconstruction.build_federated_evaluation(
model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
reconstruction_optimizer_fn=functools.partial(
tf.keras.optimizers.SGD, 0.1))
훈련 프로세스 상태를 초기화하고 검사할 수 있습니다. 가장 중요한 것은 이 서버 상태가 항목 변수(현재 무작위로 초기화됨)만 저장하고 사용자 임베딩은 저장하지 않는다는 점입니다.
state = training_process.initialize()
print(state.model)
print('Item variables shape:', state.model.trainable[0].shape)
ModelWeights(trainable=[array([[-0.02840446, 0.01196523, -0.01864688, ..., 0.03020107,
0.00121176, 0.00146852],
[ 0.01330637, 0.04741272, -0.01487445, ..., -0.03352419,
0.0104811 , 0.03506917],
[-0.04132779, 0.04883525, -0.04799002, ..., 0.00246904,
0.00586842, 0.01506213],
...,
[ 0.0216659 , 0.00734354, 0.00471039, ..., 0.01596491,
-0.00220431, -0.01559857],
[-0.00319657, -0.01740328, 0.02808609, ..., -0.00501985,
-0.03850871, -0.03844522],
[ 0.03791947, -0.00035037, 0.04217024, ..., 0.00365371,
0.00283421, 0.00897921]], dtype=float32)], non_trainable=[])
Item variables shape: (3706, 50)
유효성 검사 클라이언트에서 무작위로 초기화된 모델을 평가할 수도 있습니다. 연합 재건 평가에는 다음이 포함됩니다.
- 서버는 상품 매트릭스 전송 \(I\) 샘플링 평가 클라이언트
- 각 클라이언트는 정지 \(I\) 하고 자신의 사용자 내장 훈련 \(U_u\) SGD 하나 이상의 단계를 사용하여 (재건)
- 서버 사용하여 각 클라이언트 손실 계산 및 통계 \(I\) 및 재구성 \(U_u\) 로컬 데이터의 보이지 않는 부분
- 손실 및 메트릭은 전체 손실 및 메트릭을 계산하기 위해 사용자 전반에 걸쳐 평균화됩니다.
1단계와 2단계는 훈련과 동일합니다. 이 연결은 메타 학습, 또는 학습하는 방법을 학습의 한 형태에 우리가 리드를 평가 같은 방법으로 훈련하기 때문에 중요하다. 이 경우 모델은 로컬 변수(사용자 임베딩)의 성능을 재구성하는 전역 변수(항목 행렬)를 학습하는 방법을 학습하고 있습니다. 이에 대한 자세한 내용은 참조 절을. 4.2 용지.
공정한 평가를 위해 클라이언트 로컬 데이터의 분리된 부분을 사용하여 2단계와 3단계를 수행하는 것도 중요합니다. 기본적으로 훈련 프로세스와 평가 계산 모두 재구성을 위해 다른 모든 예제를 사용하고 재구성 후 나머지 절반을 사용합니다. 이 동작은 사용하여 사용자 정의 할 수 있습니다 dataset_split_fn 인수를 (우리는 나중에 더이를 살펴볼 것이다).
# We shouldn't expect good evaluation results here, since we haven't trained
# yet!
eval_metrics = evaluation_computation(state.model, tf_val_datasets)
print('Initial Eval:', eval_metrics['eval'])
Initial Eval: OrderedDict([('loss', 14.340279), ('rating_accuracy', 0.0)])
다음으로 훈련 라운드를 실행해 볼 수 있습니다. 좀 더 현실감 있게 만들기 위해 라운드당 50명의 클라이언트를 교체 없이 무작위로 샘플링합니다. 우리는 훈련을 한 라운드만 수행하기 때문에 여전히 훈련 지표가 좋지 않을 것으로 예상해야 합니다.
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train metrics:', metrics['train'])
Train metrics: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.317455)])
이제 여러 라운드에 걸쳐 훈련하도록 훈련 루프를 설정해 보겠습니다.
NUM_ROUNDS = 20
train_losses = []
train_accs = []
state = training_process.initialize()
# This may take a couple minutes to run.
for i in range(NUM_ROUNDS):
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train round {i}:', metrics['train'])
train_losses.append(metrics['train']['loss'])
train_accs.append(metrics['train']['rating_accuracy'])
eval_metrics = evaluation_computation(state.model, tf_val_datasets)
print('Final Eval:', eval_metrics['eval'])
Train round 0: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.7013445)])
Train round 1: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.459233)])
Train round 2: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.52466)])
Train round 3: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.087793)])
Train round 4: OrderedDict([('rating_accuracy', 0.011243612), ('loss', 11.110232)])
Train round 5: OrderedDict([('rating_accuracy', 0.06366048), ('loss', 8.267054)])
Train round 6: OrderedDict([('rating_accuracy', 0.12331288), ('loss', 5.2693872)])
Train round 7: OrderedDict([('rating_accuracy', 0.14264487), ('loss', 5.1511016)])
Train round 8: OrderedDict([('rating_accuracy', 0.21046545), ('loss', 3.8246362)])
Train round 9: OrderedDict([('rating_accuracy', 0.21320973), ('loss', 3.303812)])
Train round 10: OrderedDict([('rating_accuracy', 0.21651311), ('loss', 3.4864292)])
Train round 11: OrderedDict([('rating_accuracy', 0.23476052), ('loss', 3.0105433)])
Train round 12: OrderedDict([('rating_accuracy', 0.21981856), ('loss', 3.1807854)])
Train round 13: OrderedDict([('rating_accuracy', 0.27683082), ('loss', 2.3382564)])
Train round 14: OrderedDict([('rating_accuracy', 0.26080742), ('loss', 2.7009728)])
Train round 15: OrderedDict([('rating_accuracy', 0.2733109), ('loss', 2.2993557)])
Train round 16: OrderedDict([('rating_accuracy', 0.29282996), ('loss', 2.5278995)])
Train round 17: OrderedDict([('rating_accuracy', 0.30204678), ('loss', 2.060092)])
Train round 18: OrderedDict([('rating_accuracy', 0.2940266), ('loss', 2.0976772)])
Train round 19: OrderedDict([('rating_accuracy', 0.3086304), ('loss', 2.0626144)])
Final Eval: OrderedDict([('loss', 1.9961331), ('rating_accuracy', 0.30322924)])
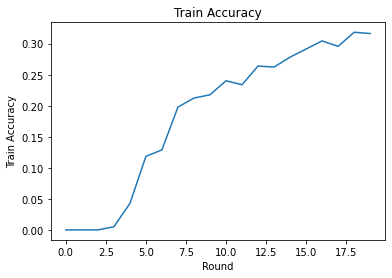
라운드에 걸쳐 훈련 손실과 정확도를 플롯할 수 있습니다. 이 노트북의 하이퍼파라미터는 신중하게 조정되지 않았으므로 이러한 결과를 개선하기 위해 라운드당 다른 클라이언트, 학습률, 라운드 수 및 총 클라이언트 수를 자유롭게 시도하십시오.
plt.plot(range(NUM_ROUNDS), train_losses)
plt.ylabel('Train Loss')
plt.xlabel('Round')
plt.title('Train Loss')
plt.show()
plt.plot(range(NUM_ROUNDS), train_accs)
plt.ylabel('Train Accuracy')
plt.xlabel('Round')
plt.title('Train Accuracy')
plt.show()
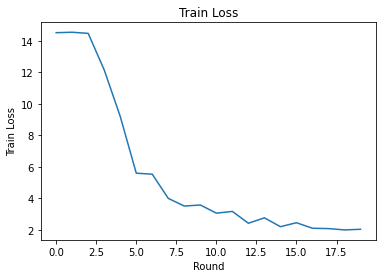
마지막으로 조정이 끝나면 보이지 않는 테스트 세트에 대한 메트릭을 계산할 수 있습니다.
eval_metrics = evaluation_computation(state.model, tf_test_datasets)
print('Final Test:', eval_metrics['eval'])
Final Test: OrderedDict([('loss', 1.9566978), ('rating_accuracy', 0.30792442)])
추가 탐색
이 노트북을 완성하는 동안 수고하셨습니다. 우리는 부분적으로 지역 연합 학습을 더 자세히 탐색하기 위해 다음 연습을 제안합니다.
Federated Averaging의 일반적인 구현은 데이터에 대해 여러 로컬 패스(에포크)를 수행합니다(여러 배치에 걸쳐 데이터에 대해 하나의 패스를 수행하는 것 외에도). 연합 재건의 경우 재건 및 재건 후 교육을 위해 별도로 단계 수를 제어할 수 있습니다. 통과
dataset_split_fn교육 및 평가 계산 빌더에 인수하는 것은 모두 복원 및 사후 재건 데이터 세트를 통해 단계 및 신 (新) 시대의 수를 제어 할 수 있습니다. 연습으로 50단계로 제한되는 3개의 로컬 에포크 재건 훈련과 50단계로 제한되는 1개의 로컬 재건 후 훈련을 수행해 보십시오. 힌트 : 당신이 찾을 수tff.learning.reconstruction.build_dataset_split_fn도움. 이 작업을 수행한 후에는 이러한 하이퍼파라미터와 학습률 및 배치 크기와 같은 기타 관련 매개변수를 조정하여 더 나은 결과를 얻으십시오.연합 재건 훈련 및 평가의 기본 동작은 재건 및 재건 후 각각에 대해 클라이언트의 로컬 데이터를 반으로 나누는 것입니다. 클라이언트에 로컬 데이터가 거의 없는 경우 교육 과정에서만 재구성 및 사후 재구성을 위해 데이터를 재사용하는 것이 합리적일 수 있습니다(평가용이 아닌 경우 불공정한 평가로 이어짐). , 교육 과정이 변화를 만드는 보장 시도
dataset_split_fn평가를 여전히 복원 및 사후 재건 데이터 해체를 유지합니다. 힌트 :tff.learning.reconstruction.simple_dataset_split_fn유용 할 수 있습니다.위, 우리는 생산
tff.learning.Model사용하여 Keras 모델에서tff.learning.reconstruction.from_keras_model. 우리는 또한 순수한 TensorFlow 2.0을 사용하여 사용자 정의 모델을 구현할 수있는 모델 인터페이스를 구현 . 수정 시도get_matrix_factorization_model구축하고 확장하는 클래스 반환tff.learning.reconstruction.Model메서드를 구현을. 힌트 : 소스 코드tff.learning.reconstruction.from_keras_model연장의 일례 제공tff.learning.reconstruction.Model클래스. 받는 사람도 참조 EMNIST 이미지 분류 튜토리얼의 사용자 정의 모델을 구현 확장에 유사한 운동에 대한tff.learning.Model.이 튜토리얼에서는 사용자 임베딩을 서버로 전송하면 사용자 기본 설정이 쉽게 누출되는 행렬 분해의 맥락에서 부분적으로 로컬 연합 학습에 동기를 부여했습니다. 또한 다른 설정에서 Federated Reconstruction을 적용하여 더 많은 개인 모델을 훈련할 수 있습니다(모델의 일부가 각 사용자에게 완전히 로컬이기 때문에). 통신을 줄이면서(로컬 매개변수가 서버로 전송되지 않기 때문에). 일반적으로 여기에 제공된 인터페이스를 사용하여 일반적으로 완전히 전역적으로 훈련되는 연합 모델을 사용하고 대신 해당 변수를 전역 변수와 지역 변수로 분할할 수 있습니다. 탐구 예 연합 재건 용지는 개인 다음 단어 예측이다 : 여기, 각 사용자가, 밖으로의 어휘 단어를 단어 묻어의 자체 로컬 세트가 캡처 사용자의 속어로 모델을 활성화하고 추가 통신없이 개인화를 얻을 수 있습니다. 연습으로 Federated Reconstruction과 함께 사용할 다른 모델(Keras 모델 또는 사용자 지정 TensorFlow 2.0 모델로)을 구현해 보십시오. 제안: 개인 사용자 임베딩을 사용하여 EMNIST 분류 모델을 구현합니다. 여기서 개인 사용자 임베딩은 모델의 마지막 Dense 레이어 이전에 CNN 이미지 기능에 연결됩니다. 이 튜토리얼의 코드 (예를 들어 대부분 재사용 할 수
UserEmbedding클래스)와 이미지 분류 자습서를 .
당신은 아직도 일부 지역 연합 학습에 찾고있는 경우, 체크 아웃 연합 재건 종이 및 오픈 소스 실험 코드를 .