
| | |  Ver fonte no GitHub Ver fonte no GitHub |
A API tf.data permite que você crie pipelines de entrada complexos a partir de peças simples e reutilizáveis. Por exemplo, o pipeline para um modelo de imagem pode agregar dados de arquivos em um sistema de arquivos distribuído, aplicar perturbações aleatórias a cada imagem e mesclar imagens selecionadas aleatoriamente em um lote para treinamento. O pipeline para um modelo de texto pode envolver a extração de símbolos de dados de texto bruto, convertendo-os em identificadores incorporados com uma tabela de pesquisa e agrupando em lote sequências de diferentes comprimentos. A API tf.data possibilita lidar com grandes quantidades de dados, ler de diferentes formatos de dados e realizar transformações complexas.
A API tf.data apresenta uma abstração tf.data.Dataset que representa uma sequência de elementos, na qual cada elemento consiste em um ou mais componentes. Por exemplo, em um pipeline de imagem, um elemento pode ser um único exemplo de treinamento, com um par de componentes de tensor representando a imagem e seu rótulo.
Há duas maneiras distintas de criar um conjunto de dados:
Uma fonte de dados constrói um
Dataseta partir de dados armazenados na memória ou em um ou mais arquivos.Uma transformação de dados constrói um conjunto de dados a partir de um ou mais objetos
tf.data.Dataset.
import tensorflow as tf
import pathlib
import os
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
np.set_printoptions(precision=4)
Mecânica básica
Para criar um pipeline de entrada, você deve começar com uma fonte de dados. Por exemplo, para construir um Dataset a partir de dados na memória, você pode usar tf.data.Dataset.from_tensors() ou tf.data.Dataset.from_tensor_slices() . Como alternativa, se seus dados de entrada estiverem armazenados em um arquivo no formato TFRecord recomendado, você poderá usar tf.data.TFRecordDataset() .
Depois de ter um objeto Dataset , você pode transformá -lo em um novo Dataset encadeando chamadas de método no objeto tf.data.Dataset . Por exemplo, você pode aplicar transformações por elemento, como Dataset.map() , e transformações de vários elementos, como Dataset.batch() . Consulte a documentação de tf.data.Dataset para obter uma lista completa de transformações.
O objeto Dataset é um iterável do Python. Isso torna possível consumir seus elementos usando um loop for:
dataset = tf.data.Dataset.from_tensor_slices([8, 3, 0, 8, 2, 1])
dataset
<TensorSliceDataset element_spec=TensorSpec(shape=(), dtype=tf.int32, name=None)>
for elem in dataset:
print(elem.numpy())
8 3 0 8 2 1
Ou criando explicitamente um iterador Python usando iter e consumindo seus elementos usando next :
it = iter(dataset)
print(next(it).numpy())
8
Como alternativa, os elementos do conjunto de dados podem ser consumidos usando a transformação de reduce , que reduz todos os elementos para produzir um único resultado. O exemplo a seguir ilustra como usar a transformação de reduce para calcular a soma de um conjunto de dados de inteiros.
print(dataset.reduce(0, lambda state, value: state + value).numpy())
22
Estrutura do conjunto de dados
Um conjunto de dados produz uma sequência de elementos , onde cada elemento é a mesma estrutura (aninhada) de componentes . Componentes individuais da estrutura podem ser de qualquer tipo representável por tf.TypeSpec , incluindo tf.Tensor , tf.sparse.SparseTensor , tf.RaggedTensor , tf.TensorArray ou tf.data.Dataset .
As construções Python que podem ser usadas para expressar a estrutura (aninhada) de elementos incluem tuple , dict , NamedTuple e OrderedDict . Em particular, list não é uma construção válida para expressar a estrutura dos elementos do conjunto de dados. Isso ocorre porque os primeiros usuários de tf.data sentiam fortemente que entradas de list (por exemplo, passadas para tf.data.Dataset.from_tensors ) eram automaticamente empacotadas como tensores e saídas de list (por exemplo, valores de retorno de funções definidas pelo usuário) sendo coagidas em uma tuple . Como consequência, se você quiser que uma entrada de list seja tratada como uma estrutura, você precisa convertê-la em tuple e se você quiser que uma saída de list seja um único componente, então você precisa empacotá-la explicitamente usando tf.stack .
A propriedade Dataset.element_spec permite inspecionar o tipo de cada componente do elemento. A propriedade retorna uma estrutura aninhada de objetos tf.TypeSpec , correspondendo à estrutura do elemento, que pode ser um único componente, uma tupla de componentes ou uma tupla aninhada de componentes. Por exemplo:
dataset1 = tf.data.Dataset.from_tensor_slices(tf.random.uniform([4, 10]))
dataset1.element_spec
TensorSpec(shape=(10,), dtype=tf.float32, name=None)
dataset2 = tf.data.Dataset.from_tensor_slices(
(tf.random.uniform([4]),
tf.random.uniform([4, 100], maxval=100, dtype=tf.int32)))
dataset2.element_spec
(TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None))
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
dataset3.element_spec
(TensorSpec(shape=(10,), dtype=tf.float32, name=None), (TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None)))
# Dataset containing a sparse tensor.
dataset4 = tf.data.Dataset.from_tensors(tf.SparseTensor(indices=[[0, 0], [1, 2]], values=[1, 2], dense_shape=[3, 4]))
dataset4.element_spec
SparseTensorSpec(TensorShape([3, 4]), tf.int32)
# Use value_type to see the type of value represented by the element spec
dataset4.element_spec.value_type
tensorflow.python.framework.sparse_tensor.SparseTensor
As transformações de Dataset suportam datasets de qualquer estrutura. Ao usar as Dataset.map() e Dataset.filter() , que aplicam uma função a cada elemento, a estrutura do elemento determina os argumentos da função:
dataset1 = tf.data.Dataset.from_tensor_slices(
tf.random.uniform([4, 10], minval=1, maxval=10, dtype=tf.int32))
dataset1
<TensorSliceDataset element_spec=TensorSpec(shape=(10,), dtype=tf.int32, name=None)>
for z in dataset1:
print(z.numpy())
[3 3 7 5 9 8 4 2 3 7] [8 9 6 7 5 6 1 6 2 3] [9 8 4 4 8 7 1 5 6 7] [5 9 5 4 2 5 7 8 8 8]
dataset2 = tf.data.Dataset.from_tensor_slices(
(tf.random.uniform([4]),
tf.random.uniform([4, 100], maxval=100, dtype=tf.int32)))
dataset2
<TensorSliceDataset element_spec=(TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None))>
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
dataset3
<ZipDataset element_spec=(TensorSpec(shape=(10,), dtype=tf.int32, name=None), (TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None)))>
for a, (b,c) in dataset3:
print('shapes: {a.shape}, {b.shape}, {c.shape}'.format(a=a, b=b, c=c))
shapes: (10,), (), (100,) shapes: (10,), (), (100,) shapes: (10,), (), (100,) shapes: (10,), (), (100,)
Lendo dados de entrada
Consumindo matrizes NumPy
Consulte Carregando matrizes NumPy para obter mais exemplos.
Se todos os dados de entrada couberem na memória, a maneira mais simples de criar um Dataset a partir deles é convertê-los em objetos tf.Tensor e usar Dataset.from_tensor_slices() .
train, test = tf.keras.datasets.fashion_mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step 40960/29515 [=========================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step 26435584/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 16384/5148 [===============================================================================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step 4431872/4422102 [==============================] - 0s 0us/step
images, labels = train
images = images/255
dataset = tf.data.Dataset.from_tensor_slices((images, labels))
dataset
<TensorSliceDataset element_spec=(TensorSpec(shape=(28, 28), dtype=tf.float64, name=None), TensorSpec(shape=(), dtype=tf.uint8, name=None))>
Consumindo geradores Python
Outra fonte de dados comum que pode ser facilmente ingerida como um tf.data.Dataset é o gerador python.
def count(stop):
i = 0
while i<stop:
yield i
i += 1
for n in count(5):
print(n)
0 1 2 3 4
O construtor Dataset.from_generator converte o gerador python em um tf.data.Dataset totalmente funcional.
O construtor recebe um callable como entrada, não um iterador. Isso permite que ele reinicie o gerador quando chegar ao fim. Ele recebe um argumento opcional args , que é passado como argumentos do callable.
O argumento output_types é necessário porque tf.data cria um tf.Graph internamente e as arestas do gráfico requerem um tf.dtype .
ds_counter = tf.data.Dataset.from_generator(count, args=[25], output_types=tf.int32, output_shapes = (), )
for count_batch in ds_counter.repeat().batch(10).take(10):
print(count_batch.numpy())
[0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 0 1 2 3 4] [ 5 6 7 8 9 10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24] [0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 0 1 2 3 4] [ 5 6 7 8 9 10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24]
O argumento output_shapes não é obrigatório , mas é altamente recomendado, pois muitas operações do TensorFlow não suportam tensores com uma classificação desconhecida. Se o comprimento de um determinado eixo for desconhecido ou variável, defina-o como None em output_shapes .
Também é importante observar que output_shapes e output_types seguem as mesmas regras de aninhamento que outros métodos de conjunto de dados.
Aqui está um gerador de exemplo que demonstra ambos os aspectos, ele retorna tuplas de arrays, onde o segundo array é um vetor com comprimento desconhecido.
def gen_series():
i = 0
while True:
size = np.random.randint(0, 10)
yield i, np.random.normal(size=(size,))
i += 1
for i, series in gen_series():
print(i, ":", str(series))
if i > 5:
break
0 : [0.3939] 1 : [ 0.9282 -0.0158 1.0096 0.7155 0.0491 0.6697 -0.2565 0.487 ] 2 : [-0.4831 0.37 -1.3918 -0.4786 0.7425 -0.3299] 3 : [ 0.1427 -1.0438 0.821 -0.8766 -0.8369 0.4168] 4 : [-1.4984 -1.8424 0.0337 0.0941 1.3286 -1.4938] 5 : [-1.3158 -1.2102 2.6887 -1.2809] 6 : []
A primeira saída é um int32 o segundo é um float32 .
O primeiro item é um escalar, forma () , e o segundo é um vetor de comprimento desconhecido, forma (None,)
ds_series = tf.data.Dataset.from_generator(
gen_series,
output_types=(tf.int32, tf.float32),
output_shapes=((), (None,)))
ds_series
<FlatMapDataset element_spec=(TensorSpec(shape=(), dtype=tf.int32, name=None), TensorSpec(shape=(None,), dtype=tf.float32, name=None))>
Agora ele pode ser usado como um tf.data.Dataset normal. Observe que ao agrupar um conjunto de dados com uma forma variável, você precisa usar Dataset.padded_batch .
ds_series_batch = ds_series.shuffle(20).padded_batch(10)
ids, sequence_batch = next(iter(ds_series_batch))
print(ids.numpy())
print()
print(sequence_batch.numpy())
[ 8 10 18 1 5 19 22 17 21 25] [[-0.6098 0.1366 -2.15 -0.9329 0. 0. ] [ 1.0295 -0.033 -0.0388 0. 0. 0. ] [-0.1137 0.3552 0.4363 -0.2487 -1.1329 0. ] [ 0. 0. 0. 0. 0. 0. ] [-1.0466 0.624 -1.7705 1.4214 0.9143 -0.62 ] [-0.9502 1.7256 0.5895 0.7237 1.5397 0. ] [ 0.3747 1.2967 0. 0. 0. 0. ] [-0.4839 0.292 -0.7909 -0.7535 0.4591 -1.3952] [-0.0468 0.0039 -1.1185 -1.294 0. 0. ] [-0.1679 -0.3375 0. 0. 0. 0. ]]
Para um exemplo mais realista, tente agrupar preprocessing.image.ImageDataGenerator como um tf.data.Dataset .
Primeiro baixe os dados:
flowers = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz 228818944/228813984 [==============================] - 10s 0us/step 228827136/228813984 [==============================] - 10s 0us/step
Crie a image.ImageDataGenerator
img_gen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255, rotation_range=20)
images, labels = next(img_gen.flow_from_directory(flowers))
Found 3670 images belonging to 5 classes.
print(images.dtype, images.shape)
print(labels.dtype, labels.shape)
float32 (32, 256, 256, 3) float32 (32, 5)
ds = tf.data.Dataset.from_generator(
lambda: img_gen.flow_from_directory(flowers),
output_types=(tf.float32, tf.float32),
output_shapes=([32,256,256,3], [32,5])
)
ds.element_spec
(TensorSpec(shape=(32, 256, 256, 3), dtype=tf.float32, name=None), TensorSpec(shape=(32, 5), dtype=tf.float32, name=None))
for images, label in ds.take(1):
print('images.shape: ', images.shape)
print('labels.shape: ', labels.shape)
Found 3670 images belonging to 5 classes. images.shape: (32, 256, 256, 3) labels.shape: (32, 5)
Consumindo dados do TFRecord
Consulte Carregando TFRecords para obter um exemplo de ponta a ponta.
A API tf.data oferece suporte a vários formatos de arquivo para que você possa processar grandes conjuntos de dados que não cabem na memória. Por exemplo, o formato de arquivo TFRecord é um formato binário simples orientado a registros que muitos aplicativos do TensorFlow usam para dados de treinamento. A classe tf.data.TFRecordDataset permite transmitir o conteúdo de um ou mais arquivos TFRecord como parte de um pipeline de entrada.
Aqui está um exemplo usando o arquivo de teste do French Street Name Signs (FSNS).
# Creates a dataset that reads all of the examples from two files.
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001 7905280/7904079 [==============================] - 1s 0us/step 7913472/7904079 [==============================] - 1s 0us/step
O argumento filenames para o inicializador TFRecordDataset pode ser uma string, uma lista de strings ou um tf.Tensor de strings. Portanto, se você tiver dois conjuntos de arquivos para fins de treinamento e validação, poderá criar um método de fábrica que produz o conjunto de dados, usando nomes de arquivos como argumento de entrada:
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
dataset
<TFRecordDatasetV2 element_spec=TensorSpec(shape=(), dtype=tf.string, name=None)>
Muitos projetos do TensorFlow usam registros tf.train.Example serializados em seus arquivos TFRecord. Eles precisam ser decodificados antes de serem inspecionados:
raw_example = next(iter(dataset))
parsed = tf.train.Example.FromString(raw_example.numpy())
parsed.features.feature['image/text']
bytes_list {
value: "Rue Perreyon"
}
Consumindo dados de texto
Consulte Carregando texto para um exemplo de ponta a ponta.
Muitos conjuntos de dados são distribuídos como um ou mais arquivos de texto. O tf.data.TextLineDataset fornece uma maneira fácil de extrair linhas de um ou mais arquivos de texto. Dado um ou mais nomes de arquivo, um TextLineDataset produzirá um elemento com valor de string por linha desses arquivos.
directory_url = 'https://storage.googleapis.com/download.tensorflow.org/data/illiad/'
file_names = ['cowper.txt', 'derby.txt', 'butler.txt']
file_paths = [
tf.keras.utils.get_file(file_name, directory_url + file_name)
for file_name in file_names
]
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/cowper.txt 819200/815980 [==============================] - 0s 0us/step 827392/815980 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/derby.txt 811008/809730 [==============================] - 0s 0us/step 819200/809730 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/butler.txt 811008/807992 [==============================] - 0s 0us/step 819200/807992 [==============================] - 0s 0us/step
dataset = tf.data.TextLineDataset(file_paths)
Aqui estão as primeiras linhas do primeiro arquivo:
for line in dataset.take(5):
print(line.numpy())
b"\xef\xbb\xbfAchilles sing, O Goddess! Peleus' son;" b'His wrath pernicious, who ten thousand woes' b"Caused to Achaia's host, sent many a soul" b'Illustrious into Ades premature,' b'And Heroes gave (so stood the will of Jove)'
Para alternar linhas entre arquivos, use Dataset.interleave . Isso torna mais fácil embaralhar arquivos juntos. Aqui estão a primeira, segunda e terceira linhas de cada tradução:
files_ds = tf.data.Dataset.from_tensor_slices(file_paths)
lines_ds = files_ds.interleave(tf.data.TextLineDataset, cycle_length=3)
for i, line in enumerate(lines_ds.take(9)):
if i % 3 == 0:
print()
print(line.numpy())
b"\xef\xbb\xbfAchilles sing, O Goddess! Peleus' son;" b"\xef\xbb\xbfOf Peleus' son, Achilles, sing, O Muse," b'\xef\xbb\xbfSing, O goddess, the anger of Achilles son of Peleus, that brought' b'His wrath pernicious, who ten thousand woes' b'The vengeance, deep and deadly; whence to Greece' b'countless ills upon the Achaeans. Many a brave soul did it send' b"Caused to Achaia's host, sent many a soul" b'Unnumbered ills arose; which many a soul' b'hurrying down to Hades, and many a hero did it yield a prey to dogs and'
Por padrão, um TextLineDataset produz cada linha de cada arquivo, o que pode não ser desejável, por exemplo, se o arquivo começar com uma linha de cabeçalho ou contiver comentários. Essas linhas podem ser removidas usando as Dataset.skip() ou Dataset.filter() . Aqui, você pula a primeira linha e depois filtra para encontrar apenas sobreviventes.
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic_lines = tf.data.TextLineDataset(titanic_file)
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 32768/30874 [===============================] - 0s 0us/step 40960/30874 [=======================================] - 0s 0us/step
for line in titanic_lines.take(10):
print(line.numpy())
b'survived,sex,age,n_siblings_spouses,parch,fare,class,deck,embark_town,alone' b'0,male,22.0,1,0,7.25,Third,unknown,Southampton,n' b'1,female,38.0,1,0,71.2833,First,C,Cherbourg,n' b'1,female,26.0,0,0,7.925,Third,unknown,Southampton,y' b'1,female,35.0,1,0,53.1,First,C,Southampton,n' b'0,male,28.0,0,0,8.4583,Third,unknown,Queenstown,y' b'0,male,2.0,3,1,21.075,Third,unknown,Southampton,n' b'1,female,27.0,0,2,11.1333,Third,unknown,Southampton,n' b'1,female,14.0,1,0,30.0708,Second,unknown,Cherbourg,n' b'1,female,4.0,1,1,16.7,Third,G,Southampton,n'
def survived(line):
return tf.not_equal(tf.strings.substr(line, 0, 1), "0")
survivors = titanic_lines.skip(1).filter(survived)
for line in survivors.take(10):
print(line.numpy())
b'1,female,38.0,1,0,71.2833,First,C,Cherbourg,n' b'1,female,26.0,0,0,7.925,Third,unknown,Southampton,y' b'1,female,35.0,1,0,53.1,First,C,Southampton,n' b'1,female,27.0,0,2,11.1333,Third,unknown,Southampton,n' b'1,female,14.0,1,0,30.0708,Second,unknown,Cherbourg,n' b'1,female,4.0,1,1,16.7,Third,G,Southampton,n' b'1,male,28.0,0,0,13.0,Second,unknown,Southampton,y' b'1,female,28.0,0,0,7.225,Third,unknown,Cherbourg,y' b'1,male,28.0,0,0,35.5,First,A,Southampton,y' b'1,female,38.0,1,5,31.3875,Third,unknown,Southampton,n'
Consumindo dados CSV
Consulte Carregando arquivos CSV e Carregando Pandas DataFrames para obter mais exemplos.
O formato de arquivo CSV é um formato popular para armazenar dados tabulares em texto simples.
Por exemplo:
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
df = pd.read_csv(titanic_file)
df.head()
Se seus dados cabem na memória, o mesmo método Dataset.from_tensor_slices funciona em dicionários, permitindo que esses dados sejam facilmente importados:
titanic_slices = tf.data.Dataset.from_tensor_slices(dict(df))
for feature_batch in titanic_slices.take(1):
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived' : 0 'sex' : b'male' 'age' : 22.0 'n_siblings_spouses': 1 'parch' : 0 'fare' : 7.25 'class' : b'Third' 'deck' : b'unknown' 'embark_town' : b'Southampton' 'alone' : b'n'
Uma abordagem mais escalável é carregar do disco conforme necessário.
O módulo tf.data fornece métodos para extrair registros de um ou mais arquivos CSV que atendem à RFC 4180 .
A função experimental.make_csv_dataset é a interface de alto nível para leitura de conjuntos de arquivos csv. Ele suporta inferência de tipo de coluna e muitos outros recursos, como lotes e embaralhamento, para simplificar o uso.
titanic_batches = tf.data.experimental.make_csv_dataset(
titanic_file, batch_size=4,
label_name="survived")
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
print("features:")
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived': [1 0 0 0] features: 'sex' : [b'female' b'female' b'male' b'male'] 'age' : [32. 28. 37. 50.] 'n_siblings_spouses': [0 3 0 0] 'parch' : [0 1 1 0] 'fare' : [13. 25.4667 29.7 13. ] 'class' : [b'Second' b'Third' b'First' b'Second'] 'deck' : [b'unknown' b'unknown' b'C' b'unknown'] 'embark_town' : [b'Southampton' b'Southampton' b'Cherbourg' b'Southampton'] 'alone' : [b'y' b'n' b'n' b'y']
Você pode usar o argumento select_columns se precisar apenas de um subconjunto de colunas.
titanic_batches = tf.data.experimental.make_csv_dataset(
titanic_file, batch_size=4,
label_name="survived", select_columns=['class', 'fare', 'survived'])
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived': [0 1 1 0] 'fare' : [ 7.05 15.5 26.25 8.05] 'class' : [b'Third' b'Third' b'Second' b'Third']
Há também uma classe experimental.CsvDataset de nível inferior que fornece um controle mais refinado. Ele não suporta inferência de tipo de coluna. Em vez disso, você deve especificar o tipo de cada coluna.
titanic_types = [tf.int32, tf.string, tf.float32, tf.int32, tf.int32, tf.float32, tf.string, tf.string, tf.string, tf.string]
dataset = tf.data.experimental.CsvDataset(titanic_file, titanic_types , header=True)
for line in dataset.take(10):
print([item.numpy() for item in line])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 38.0, 1, 0, 71.2833, b'First', b'C', b'Cherbourg', b'n'] [1, b'female', 26.0, 0, 0, 7.925, b'Third', b'unknown', b'Southampton', b'y'] [1, b'female', 35.0, 1, 0, 53.1, b'First', b'C', b'Southampton', b'n'] [0, b'male', 28.0, 0, 0, 8.4583, b'Third', b'unknown', b'Queenstown', b'y'] [0, b'male', 2.0, 3, 1, 21.075, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 27.0, 0, 2, 11.1333, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 14.0, 1, 0, 30.0708, b'Second', b'unknown', b'Cherbourg', b'n'] [1, b'female', 4.0, 1, 1, 16.7, b'Third', b'G', b'Southampton', b'n'] [0, b'male', 20.0, 0, 0, 8.05, b'Third', b'unknown', b'Southampton', b'y']
Se algumas colunas estiverem vazias, essa interface de baixo nível permitirá que você forneça valores padrão em vez de tipos de coluna.
%%writefile missing.csv
1,2,3,4
,2,3,4
1,,3,4
1,2,,4
1,2,3,
,,,
Writing missing.csv
# Creates a dataset that reads all of the records from two CSV files, each with
# four float columns which may have missing values.
record_defaults = [999,999,999,999]
dataset = tf.data.experimental.CsvDataset("missing.csv", record_defaults)
dataset = dataset.map(lambda *items: tf.stack(items))
dataset
<MapDataset element_spec=TensorSpec(shape=(4,), dtype=tf.int32, name=None)>
for line in dataset:
print(line.numpy())
[1 2 3 4] [999 2 3 4] [ 1 999 3 4] [ 1 2 999 4] [ 1 2 3 999] [999 999 999 999]
Por padrão, um CsvDataset produz todas as colunas de todas as linhas do arquivo, o que pode não ser desejável, por exemplo, se o arquivo iniciar com uma linha de cabeçalho que deve ser ignorada ou se algumas colunas não forem necessárias na entrada. Essas linhas e campos podem ser removidos com os argumentos header e select_cols respectivamente.
# Creates a dataset that reads all of the records from two CSV files with
# headers, extracting float data from columns 2 and 4.
record_defaults = [999, 999] # Only provide defaults for the selected columns
dataset = tf.data.experimental.CsvDataset("missing.csv", record_defaults, select_cols=[1, 3])
dataset = dataset.map(lambda *items: tf.stack(items))
dataset
<MapDataset element_spec=TensorSpec(shape=(2,), dtype=tf.int32, name=None)>
for line in dataset:
print(line.numpy())
[2 4] [2 4] [999 4] [2 4] [ 2 999] [999 999]
Consumindo conjuntos de arquivos
Existem muitos conjuntos de dados distribuídos como um conjunto de arquivos, onde cada arquivo é um exemplo.
flowers_root = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
flowers_root = pathlib.Path(flowers_root)
O diretório raiz contém um diretório para cada classe:
for item in flowers_root.glob("*"):
print(item.name)
sunflowers daisy LICENSE.txt roses tulips dandelion
Os arquivos em cada diretório de classe são exemplos:
list_ds = tf.data.Dataset.list_files(str(flowers_root/'*/*'))
for f in list_ds.take(5):
print(f.numpy())
b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/5018120483_cc0421b176_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/8642679391_0805b147cb_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/8266310743_02095e782d_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/tulips/13176521023_4d7cc74856_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/19437578578_6ab1b3c984.jpg'
Leia os dados usando a função tf.io.read_file e extraia o rótulo do caminho, retornando os pares (image, label) :
def process_path(file_path):
label = tf.strings.split(file_path, os.sep)[-2]
return tf.io.read_file(file_path), label
labeled_ds = list_ds.map(process_path)
for image_raw, label_text in labeled_ds.take(1):
print(repr(image_raw.numpy()[:100]))
print()
print(label_text.numpy())
b'\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\x01\x00\x00\x01\x00\x01\x00\x00\xff\xe2\x0cXICC_PROFILE\x00\x01\x01\x00\x00\x0cHLino\x02\x10\x00\x00mntrRGB XYZ \x07\xce\x00\x02\x00\t\x00\x06\x001\x00\x00acspMSFT\x00\x00\x00\x00IEC sRGB\x00\x00\x00\x00\x00\x00' b'daisy'
Elementos do conjunto de dados em lote
Agrupamento simples
A forma mais simples de lotes empilha n elementos consecutivos de um conjunto de dados em um único elemento. A transformação Dataset.batch() faz exatamente isso, com as mesmas restrições do operador tf.stack() , aplicadas a cada componente dos elementos: ou seja, para cada componente i , todos os elementos devem ter um tensor da mesma forma exata.
inc_dataset = tf.data.Dataset.range(100)
dec_dataset = tf.data.Dataset.range(0, -100, -1)
dataset = tf.data.Dataset.zip((inc_dataset, dec_dataset))
batched_dataset = dataset.batch(4)
for batch in batched_dataset.take(4):
print([arr.numpy() for arr in batch])
[array([0, 1, 2, 3]), array([ 0, -1, -2, -3])] [array([4, 5, 6, 7]), array([-4, -5, -6, -7])] [array([ 8, 9, 10, 11]), array([ -8, -9, -10, -11])] [array([12, 13, 14, 15]), array([-12, -13, -14, -15])]
Enquanto tf.data tenta propagar informações de forma, as configurações padrão de Dataset.batch resultam em um tamanho de lote desconhecido porque o último lote pode não estar cheio. Observe os None s na forma:
batched_dataset
<BatchDataset element_spec=(TensorSpec(shape=(None,), dtype=tf.int64, name=None), TensorSpec(shape=(None,), dtype=tf.int64, name=None))>
Use o argumento drop_remainder para ignorar esse último lote e obter a propagação de forma completa:
batched_dataset = dataset.batch(7, drop_remainder=True)
batched_dataset
<BatchDataset element_spec=(TensorSpec(shape=(7,), dtype=tf.int64, name=None), TensorSpec(shape=(7,), dtype=tf.int64, name=None))>
Tensores de lote com preenchimento
A receita acima funciona para tensores que têm todos o mesmo tamanho. No entanto, muitos modelos (por exemplo, modelos de sequência) trabalham com dados de entrada que podem ter tamanhos variados (por exemplo, sequências de diferentes comprimentos). Para lidar com esse caso, a transformação Dataset.padded_batch permite agrupar tensores de formato diferente especificando uma ou mais dimensões nas quais eles podem ser preenchidos.
dataset = tf.data.Dataset.range(100)
dataset = dataset.map(lambda x: tf.fill([tf.cast(x, tf.int32)], x))
dataset = dataset.padded_batch(4, padded_shapes=(None,))
for batch in dataset.take(2):
print(batch.numpy())
print()
[[0 0 0] [1 0 0] [2 2 0] [3 3 3]] [[4 4 4 4 0 0 0] [5 5 5 5 5 0 0] [6 6 6 6 6 6 0] [7 7 7 7 7 7 7]]
A transformação Dataset.padded_batch permite definir diferentes preenchimentos para cada dimensão de cada componente e pode ser de comprimento variável (representado por None no exemplo acima) ou de comprimento constante. Também é possível substituir o valor de preenchimento, cujo padrão é 0.
Fluxos de trabalho de treinamento
Processando várias épocas
A API tf.data oferece duas maneiras principais de processar várias épocas dos mesmos dados.
A maneira mais simples de iterar em um conjunto de dados em várias épocas é usar a transformação Dataset.repeat() . Primeiro, crie um conjunto de dados do Titanic:
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic_lines = tf.data.TextLineDataset(titanic_file)
def plot_batch_sizes(ds):
batch_sizes = [batch.shape[0] for batch in ds]
plt.bar(range(len(batch_sizes)), batch_sizes)
plt.xlabel('Batch number')
plt.ylabel('Batch size')
A aplicação da transformação Dataset.repeat() sem argumentos repetirá a entrada indefinidamente.
A transformação Dataset.repeat concatena seus argumentos sem sinalizar o fim de uma época e o início da próxima época. Por causa disso, um Dataset.batch aplicado após Dataset.repeat produzirá lotes que ultrapassam os limites da época:
titanic_batches = titanic_lines.repeat(3).batch(128)
plot_batch_sizes(titanic_batches)
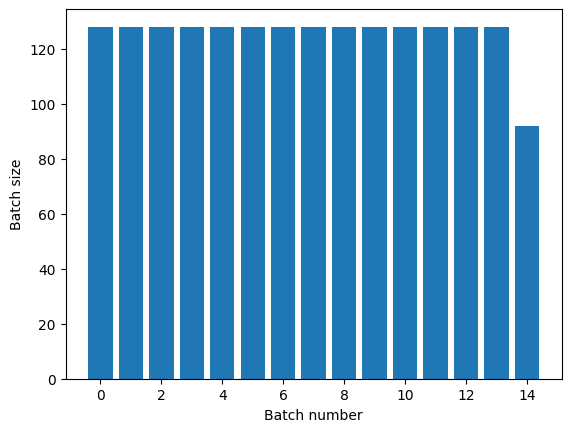
Se você precisar de separação de época clara, coloque Dataset.batch antes da repetição:
titanic_batches = titanic_lines.batch(128).repeat(3)
plot_batch_sizes(titanic_batches)
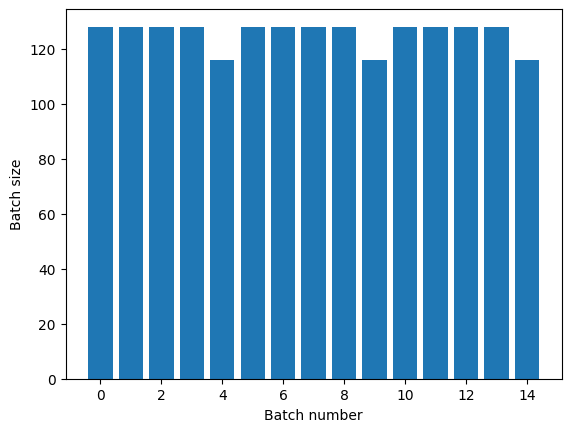
Se você deseja realizar um cálculo personalizado (por exemplo, para coletar estatísticas) no final de cada época, é mais simples reiniciar a iteração do conjunto de dados em cada época:
epochs = 3
dataset = titanic_lines.batch(128)
for epoch in range(epochs):
for batch in dataset:
print(batch.shape)
print("End of epoch: ", epoch)
(128,) (128,) (128,) (128,) (116,) End of epoch: 0 (128,) (128,) (128,) (128,) (116,) End of epoch: 1 (128,) (128,) (128,) (128,) (116,) End of epoch: 2
Embaralhando aleatoriamente os dados de entrada
A transformação Dataset.shuffle() mantém um buffer de tamanho fixo e escolhe o próximo elemento de maneira uniforme e aleatória desse buffer.
Adicione um índice ao conjunto de dados para que você possa ver o efeito:
lines = tf.data.TextLineDataset(titanic_file)
counter = tf.data.experimental.Counter()
dataset = tf.data.Dataset.zip((counter, lines))
dataset = dataset.shuffle(buffer_size=100)
dataset = dataset.batch(20)
dataset
<BatchDataset element_spec=(TensorSpec(shape=(None,), dtype=tf.int64, name=None), TensorSpec(shape=(None,), dtype=tf.string, name=None))>
Como buffer_size é 100 e o tamanho do lote é 20, o primeiro lote não contém elementos com índice superior a 120.
n,line_batch = next(iter(dataset))
print(n.numpy())
[ 52 94 22 70 63 96 56 102 38 16 27 104 89 43 41 68 42 61 112 8]
Assim como com Dataset.batch , a ordem relativa a Dataset.repeat importante.
Dataset.shuffle não sinaliza o fim de uma época até que o buffer aleatório esteja vazio. Portanto, um shuffle colocado antes de uma repetição mostrará todos os elementos de uma época antes de passar para a próxima:
dataset = tf.data.Dataset.zip((counter, lines))
shuffled = dataset.shuffle(buffer_size=100).batch(10).repeat(2)
print("Here are the item ID's near the epoch boundary:\n")
for n, line_batch in shuffled.skip(60).take(5):
print(n.numpy())
Here are the item ID's near the epoch boundary: [509 595 537 550 555 591 480 627 482 519] [522 619 538 581 569 608 531 558 461 496] [548 489 379 607 611 622 234 525] [ 59 38 4 90 73 84 27 51 107 12] [77 72 91 60 7 62 92 47 70 67]
shuffle_repeat = [n.numpy().mean() for n, line_batch in shuffled]
plt.plot(shuffle_repeat, label="shuffle().repeat()")
plt.ylabel("Mean item ID")
plt.legend()
<matplotlib.legend.Legend at 0x7f7e7061c650>
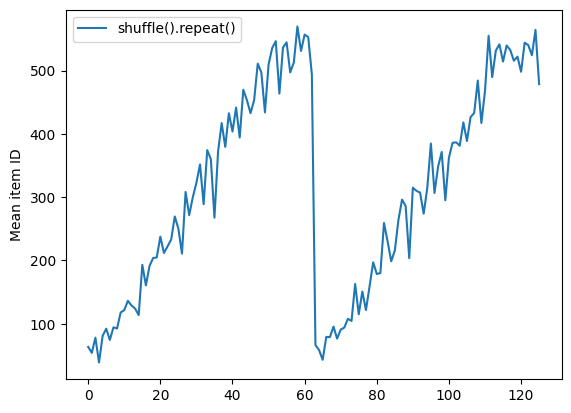
Mas uma repetição antes de um embaralhamento mistura os limites da época:
dataset = tf.data.Dataset.zip((counter, lines))
shuffled = dataset.repeat(2).shuffle(buffer_size=100).batch(10)
print("Here are the item ID's near the epoch boundary:\n")
for n, line_batch in shuffled.skip(55).take(15):
print(n.numpy())
Here are the item ID's near the epoch boundary: [ 6 8 528 604 13 492 308 441 569 475] [ 5 626 615 568 20 554 520 454 10 607] [510 542 0 363 32 446 395 588 35 4] [ 7 15 28 23 39 559 585 49 252 556] [581 617 25 43 26 548 29 460 48 41] [ 19 64 24 300 612 611 36 63 69 57] [287 605 21 512 442 33 50 68 608 47] [625 90 91 613 67 53 606 344 16 44] [453 448 89 45 465 2 31 618 368 105] [565 3 586 114 37 464 12 627 30 621] [ 82 117 72 75 84 17 571 610 18 600] [107 597 575 88 623 86 101 81 456 102] [122 79 51 58 80 61 367 38 537 113] [ 71 78 598 152 143 620 100 158 133 130] [155 151 144 135 146 121 83 27 103 134]
repeat_shuffle = [n.numpy().mean() for n, line_batch in shuffled]
plt.plot(shuffle_repeat, label="shuffle().repeat()")
plt.plot(repeat_shuffle, label="repeat().shuffle()")
plt.ylabel("Mean item ID")
plt.legend()
<matplotlib.legend.Legend at 0x7f7e706013d0>
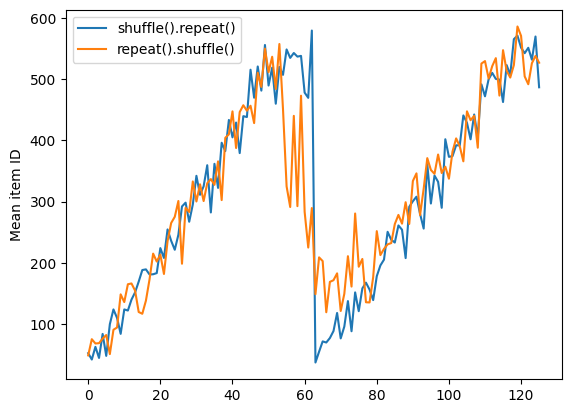
Dados de pré-processamento
A transformação Dataset.map(f) produz um novo conjunto de dados aplicando uma determinada função f a cada elemento do conjunto de dados de entrada. Ele é baseado na função map() que é comumente aplicada a listas (e outras estruturas) em linguagens de programação funcionais. A função f pega os objetos tf.Tensor que representam um único elemento na entrada e retorna os objetos tf.Tensor que representarão um único elemento no novo conjunto de dados. Sua implementação usa operações padrão do TensorFlow para transformar um elemento em outro.
Esta seção abrange exemplos comuns de como usar Dataset.map() .
Decodificando dados de imagem e redimensionando-os
Ao treinar uma rede neural em dados de imagem do mundo real, muitas vezes é necessário converter imagens de tamanhos diferentes para um tamanho comum, para que possam ser agrupadas em um tamanho fixo.
Reconstrua o conjunto de dados de nomes de arquivos de flores:
list_ds = tf.data.Dataset.list_files(str(flowers_root/'*/*'))
Escreva uma função que manipule os elementos do conjunto de dados.
# Reads an image from a file, decodes it into a dense tensor, and resizes it
# to a fixed shape.
def parse_image(filename):
parts = tf.strings.split(filename, os.sep)
label = parts[-2]
image = tf.io.read_file(filename)
image = tf.io.decode_jpeg(image)
image = tf.image.convert_image_dtype(image, tf.float32)
image = tf.image.resize(image, [128, 128])
return image, label
Teste se funciona.
file_path = next(iter(list_ds))
image, label = parse_image(file_path)
def show(image, label):
plt.figure()
plt.imshow(image)
plt.title(label.numpy().decode('utf-8'))
plt.axis('off')
show(image, label)

Mapeie-o sobre o conjunto de dados.
images_ds = list_ds.map(parse_image)
for image, label in images_ds.take(2):
show(image, label)


Aplicando a lógica arbitrária do Python
Por motivos de desempenho, use as operações do TensorFlow para pré-processar seus dados sempre que possível. No entanto, às vezes é útil chamar bibliotecas externas do Python ao analisar seus dados de entrada. Você pode usar a operação tf.py_function() em uma transformação Dataset.map() .
Por exemplo, se você deseja aplicar uma rotação aleatória, o módulo tf.image possui apenas tf.image.rot90 , o que não é muito útil para aumento de imagem.
Para demonstrar tf.py_function , tente usar a função scipy.ndimage.rotate :
import scipy.ndimage as ndimage
def random_rotate_image(image):
image = ndimage.rotate(image, np.random.uniform(-30, 30), reshape=False)
return image
image, label = next(iter(images_ds))
image = random_rotate_image(image)
show(image, label)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

Para usar esta função com Dataset.map aplicam-se as mesmas advertências que com Dataset.from_generator , você precisa descrever as formas e os tipos de retorno ao aplicar a função:
def tf_random_rotate_image(image, label):
im_shape = image.shape
[image,] = tf.py_function(random_rotate_image, [image], [tf.float32])
image.set_shape(im_shape)
return image, label
rot_ds = images_ds.map(tf_random_rotate_image)
for image, label in rot_ds.take(2):
show(image, label)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).


Analisando mensagens de buffer de protocolo tf.Example
Muitos pipelines de entrada extraem mensagens de buffer de protocolo tf.train.Example de um formato TFRecord. Cada registro tf.train.Example contém um ou mais "recursos", e o pipeline de entrada normalmente converte esses recursos em tensores.
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
dataset
<TFRecordDatasetV2 element_spec=TensorSpec(shape=(), dtype=tf.string, name=None)>
Você pode trabalhar com protos tf.train.Example fora de um tf.data.Dataset para entender os dados:
raw_example = next(iter(dataset))
parsed = tf.train.Example.FromString(raw_example.numpy())
feature = parsed.features.feature
raw_img = feature['image/encoded'].bytes_list.value[0]
img = tf.image.decode_png(raw_img)
plt.imshow(img)
plt.axis('off')
_ = plt.title(feature["image/text"].bytes_list.value[0])

raw_example = next(iter(dataset))
def tf_parse(eg):
example = tf.io.parse_example(
eg[tf.newaxis], {
'image/encoded': tf.io.FixedLenFeature(shape=(), dtype=tf.string),
'image/text': tf.io.FixedLenFeature(shape=(), dtype=tf.string)
})
return example['image/encoded'][0], example['image/text'][0]
img, txt = tf_parse(raw_example)
print(txt.numpy())
print(repr(img.numpy()[:20]), "...")
b'Rue Perreyon' b'\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x02X' ...
decoded = dataset.map(tf_parse)
decoded
<MapDataset element_spec=(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.string, name=None))>
image_batch, text_batch = next(iter(decoded.batch(10)))
image_batch.shape
TensorShape([10])
Janelas de séries temporais
Para obter um exemplo de série temporal de ponta a ponta, consulte: Previsão de série temporal .
Os dados da série temporal geralmente são organizados com o eixo do tempo intacto.
Use um Dataset.range simples para demonstrar:
range_ds = tf.data.Dataset.range(100000)
Normalmente, os modelos baseados neste tipo de dados vão querer uma fatia de tempo contígua.
A abordagem mais simples seria agrupar os dados:
Usando batch
batches = range_ds.batch(10, drop_remainder=True)
for batch in batches.take(5):
print(batch.numpy())
[0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] [40 41 42 43 44 45 46 47 48 49]
Ou para fazer previsões densas um passo no futuro, você pode mudar os recursos e rótulos um passo em relação ao outro:
def dense_1_step(batch):
# Shift features and labels one step relative to each other.
return batch[:-1], batch[1:]
predict_dense_1_step = batches.map(dense_1_step)
for features, label in predict_dense_1_step.take(3):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8] => [1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18] => [11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28] => [21 22 23 24 25 26 27 28 29]
Para prever uma janela inteira em vez de um deslocamento fixo, você pode dividir os lotes em duas partes:
batches = range_ds.batch(15, drop_remainder=True)
def label_next_5_steps(batch):
return (batch[:-5], # Inputs: All except the last 5 steps
batch[-5:]) # Labels: The last 5 steps
predict_5_steps = batches.map(label_next_5_steps)
for features, label in predict_5_steps.take(3):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8 9] => [10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24] => [25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] => [40 41 42 43 44]
Para permitir alguma sobreposição entre os recursos de um lote e os rótulos de outro, use Dataset.zip :
feature_length = 10
label_length = 3
features = range_ds.batch(feature_length, drop_remainder=True)
labels = range_ds.batch(feature_length).skip(1).map(lambda labels: labels[:label_length])
predicted_steps = tf.data.Dataset.zip((features, labels))
for features, label in predicted_steps.take(5):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8 9] => [10 11 12] [10 11 12 13 14 15 16 17 18 19] => [20 21 22] [20 21 22 23 24 25 26 27 28 29] => [30 31 32] [30 31 32 33 34 35 36 37 38 39] => [40 41 42] [40 41 42 43 44 45 46 47 48 49] => [50 51 52]
Usando window
Enquanto o uso Dataset.batch funciona, há situações em que você pode precisar de um controle mais preciso. O método Dataset.window lhe dá total controle, mas requer alguns cuidados: ele retorna um Dataset de Datasets . Consulte Estrutura do conjunto de dados para obter detalhes.
window_size = 5
windows = range_ds.window(window_size, shift=1)
for sub_ds in windows.take(5):
print(sub_ds)
<_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)>
O método Dataset.flat_map pode pegar um conjunto de conjuntos de dados e nivelá-lo em um único conjunto de dados:
for x in windows.flat_map(lambda x: x).take(30):
print(x.numpy(), end=' ')
0 1 2 3 4 1 2 3 4 5 2 3 4 5 6 3 4 5 6 7 4 5 6 7 8 5 6 7 8 9
Em quase todos os casos, você desejará fazer o .batch do conjunto de dados primeiro:
def sub_to_batch(sub):
return sub.batch(window_size, drop_remainder=True)
for example in windows.flat_map(sub_to_batch).take(5):
print(example.numpy())
[0 1 2 3 4] [1 2 3 4 5] [2 3 4 5 6] [3 4 5 6 7] [4 5 6 7 8]
Agora, você pode ver que o argumento shift controla o quanto cada janela se move.
Juntando isso, você pode escrever esta função:
def make_window_dataset(ds, window_size=5, shift=1, stride=1):
windows = ds.window(window_size, shift=shift, stride=stride)
def sub_to_batch(sub):
return sub.batch(window_size, drop_remainder=True)
windows = windows.flat_map(sub_to_batch)
return windows
ds = make_window_dataset(range_ds, window_size=10, shift = 5, stride=3)
for example in ds.take(10):
print(example.numpy())
[ 0 3 6 9 12 15 18 21 24 27] [ 5 8 11 14 17 20 23 26 29 32] [10 13 16 19 22 25 28 31 34 37] [15 18 21 24 27 30 33 36 39 42] [20 23 26 29 32 35 38 41 44 47] [25 28 31 34 37 40 43 46 49 52] [30 33 36 39 42 45 48 51 54 57] [35 38 41 44 47 50 53 56 59 62] [40 43 46 49 52 55 58 61 64 67] [45 48 51 54 57 60 63 66 69 72]
Então é fácil extrair rótulos, como antes:
dense_labels_ds = ds.map(dense_1_step)
for inputs,labels in dense_labels_ds.take(3):
print(inputs.numpy(), "=>", labels.numpy())
[ 0 3 6 9 12 15 18 21 24] => [ 3 6 9 12 15 18 21 24 27] [ 5 8 11 14 17 20 23 26 29] => [ 8 11 14 17 20 23 26 29 32] [10 13 16 19 22 25 28 31 34] => [13 16 19 22 25 28 31 34 37]
Reamostragem
Ao trabalhar com um conjunto de dados muito desequilibrado de classe, convém reamostrar o conjunto de dados. tf.data fornece dois métodos para fazer isso. O conjunto de dados de fraude de cartão de crédito é um bom exemplo desse tipo de problema.
zip_path = tf.keras.utils.get_file(
origin='https://storage.googleapis.com/download.tensorflow.org/data/creditcard.zip',
fname='creditcard.zip',
extract=True)
csv_path = zip_path.replace('.zip', '.csv')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/creditcard.zip 69156864/69155632 [==============================] - 2s 0us/step 69165056/69155632 [==============================] - 2s 0us/step
creditcard_ds = tf.data.experimental.make_csv_dataset(
csv_path, batch_size=1024, label_name="Class",
# Set the column types: 30 floats and an int.
column_defaults=[float()]*30+[int()])
Agora, verifique a distribuição das classes, ela é altamente distorcida:
def count(counts, batch):
features, labels = batch
class_1 = labels == 1
class_1 = tf.cast(class_1, tf.int32)
class_0 = labels == 0
class_0 = tf.cast(class_0, tf.int32)
counts['class_0'] += tf.reduce_sum(class_0)
counts['class_1'] += tf.reduce_sum(class_1)
return counts
counts = creditcard_ds.take(10).reduce(
initial_state={'class_0': 0, 'class_1': 0},
reduce_func = count)
counts = np.array([counts['class_0'].numpy(),
counts['class_1'].numpy()]).astype(np.float32)
fractions = counts/counts.sum()
print(fractions)
[0.9956 0.0044]
Uma abordagem comum para treinar com um conjunto de dados desequilibrado é balanceá-lo. tf.data inclui alguns métodos que permitem esse fluxo de trabalho:
Amostragem de conjuntos de dados
Uma abordagem para reamostrar um conjunto de dados é usar sample_from_datasets . Isso é mais aplicável quando você tem um data.Dataset separado para cada classe.
Aqui, basta usar o filtro para gerá-los a partir dos dados de fraude de cartão de crédito:
negative_ds = (
creditcard_ds
.unbatch()
.filter(lambda features, label: label==0)
.repeat())
positive_ds = (
creditcard_ds
.unbatch()
.filter(lambda features, label: label==1)
.repeat())
for features, label in positive_ds.batch(10).take(1):
print(label.numpy())
[1 1 1 1 1 1 1 1 1 1]
Para usar tf.data.Dataset.sample_from_datasets , passe os conjuntos de dados e o peso de cada um:
balanced_ds = tf.data.Dataset.sample_from_datasets(
[negative_ds, positive_ds], [0.5, 0.5]).batch(10)
Agora, o conjunto de dados produz exemplos de cada classe com probabilidade de 50/50:
for features, labels in balanced_ds.take(10):
print(labels.numpy())
[1 0 1 0 1 0 1 1 1 1] [0 0 1 1 0 1 1 1 1 1] [1 1 1 1 0 0 1 0 1 0] [1 1 1 0 1 0 0 1 1 1] [0 1 0 1 1 1 0 1 1 0] [0 1 0 0 0 1 0 0 0 0] [1 1 1 1 1 0 0 1 1 0] [0 0 0 1 0 1 1 1 0 0] [0 0 1 1 1 1 0 1 1 1] [1 0 0 1 1 1 1 0 1 1]
Reamostragem de rejeição
Um problema com a abordagem Dataset.sample_from_datasets acima é que ela precisa de um tf.data.Dataset separado por classe. Você pode usar Dataset.filter para criar esses dois conjuntos de dados, mas isso faz com que todos os dados sejam carregados duas vezes.
O método data.Dataset.rejection_resample pode ser aplicado a um conjunto de dados para rebalanceá-lo, carregando-o apenas uma vez. Os elementos serão removidos do conjunto de dados para alcançar o equilíbrio.
data.Dataset.rejection_resample recebe um argumento class_func . Esse class_func é aplicado a cada elemento do conjunto de dados e é usado para determinar a qual classe um exemplo pertence para fins de balanceamento.
O objetivo aqui é equilibrar a distribuição da etiqueta, e os elementos de creditcard_ds já são pares (features, label) . Então o class_func só precisa retornar esses rótulos:
def class_func(features, label):
return label
O método de reamostragem lida com exemplos individuais, portanto, nesse caso, você deve unbatch o lote do conjunto de dados antes de aplicar esse método.
O método precisa de uma distribuição alvo e, opcionalmente, uma estimativa de distribuição inicial como entrada.
resample_ds = (
creditcard_ds
.unbatch()
.rejection_resample(class_func, target_dist=[0.5,0.5],
initial_dist=fractions)
.batch(10))
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/data/ops/dataset_ops.py:5797: Print (from tensorflow.python.ops.logging_ops) is deprecated and will be removed after 2018-08-20. Instructions for updating: Use tf.print instead of tf.Print. Note that tf.print returns a no-output operator that directly prints the output. Outside of defuns or eager mode, this operator will not be executed unless it is directly specified in session.run or used as a control dependency for other operators. This is only a concern in graph mode. Below is an example of how to ensure tf.print executes in graph mode:
O método rejection_resample retorna (class, example) pares onde a class é a saída do class_func . Nesse caso, o example já era um par (feature, label) , então use map para descartar a cópia extra dos rótulos:
balanced_ds = resample_ds.map(lambda extra_label, features_and_label: features_and_label)
Agora, o conjunto de dados produz exemplos de cada classe com probabilidade de 50/50:
for features, labels in balanced_ds.take(10):
print(labels.numpy())
Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] [0 1 1 1 0 1 1 0 1 1] [1 1 0 1 0 0 0 0 1 1] [1 1 1 1 0 0 0 0 1 1] [1 0 0 1 0 0 1 0 1 1] [1 0 0 0 0 1 0 0 0 0] [1 0 0 1 1 0 1 1 1 0] [1 1 0 0 0 0 0 0 0 1] [0 0 1 0 0 0 1 0 1 1] [0 1 0 1 0 1 0 0 0 1] [0 0 0 0 0 0 0 0 1 1]
Ponto de verificação do iterador
O Tensorflow oferece suporte a pontos de verificação para que, quando o processo de treinamento for reiniciado, ele possa restaurar o ponto de verificação mais recente para recuperar a maior parte de seu progresso. Além de verificar as variáveis do modelo, você também pode verificar o progresso do iterador do conjunto de dados. Isso pode ser útil se você tiver um grande conjunto de dados e não quiser iniciar o conjunto de dados desde o início em cada reinicialização. Observe, no entanto, que os pontos de verificação do iterador podem ser grandes, uma vez que transformações como shuffle e prefetch -busca requerem elementos de buffer dentro do iterador.
Para incluir seu iterador em um ponto de verificação, passe o iterador para o construtor tf.train.Checkpoint .
range_ds = tf.data.Dataset.range(20)
iterator = iter(range_ds)
ckpt = tf.train.Checkpoint(step=tf.Variable(0), iterator=iterator)
manager = tf.train.CheckpointManager(ckpt, '/tmp/my_ckpt', max_to_keep=3)
print([next(iterator).numpy() for _ in range(5)])
save_path = manager.save()
print([next(iterator).numpy() for _ in range(5)])
ckpt.restore(manager.latest_checkpoint)
print([next(iterator).numpy() for _ in range(5)])
[0, 1, 2, 3, 4] [5, 6, 7, 8, 9] [5, 6, 7, 8, 9]
Usando tf.data com tf.keras
A API tf.keras simplifica muitos aspectos da criação e execução de modelos de aprendizado de máquina. Suas APIs .fit() e .evaluate() e .predict() suportam conjuntos de dados como entradas. Aqui está um conjunto de dados rápido e configuração de modelo:
train, test = tf.keras.datasets.fashion_mnist.load_data()
images, labels = train
images = images/255.0
labels = labels.astype(np.int32)
fmnist_train_ds = tf.data.Dataset.from_tensor_slices((images, labels))
fmnist_train_ds = fmnist_train_ds.shuffle(5000).batch(32)
model = tf.keras.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Passar um conjunto de dados de pares (feature, label) é tudo o que é necessário para Model.fit e Model.evaluate :
model.fit(fmnist_train_ds, epochs=2)
Epoch 1/2 1875/1875 [==============================] - 4s 2ms/step - loss: 0.5984 - accuracy: 0.7973 Epoch 2/2 1875/1875 [==============================] - 4s 2ms/step - loss: 0.4607 - accuracy: 0.8430 <keras.callbacks.History at 0x7f7e70283110>
Se você passar um conjunto de dados infinito, por exemplo, chamando Dataset.repeat() , você só precisa passar também o argumento steps_per_epoch :
model.fit(fmnist_train_ds.repeat(), epochs=2, steps_per_epoch=20)
Epoch 1/2 20/20 [==============================] - 0s 2ms/step - loss: 0.4574 - accuracy: 0.8672 Epoch 2/2 20/20 [==============================] - 0s 2ms/step - loss: 0.4216 - accuracy: 0.8562 <keras.callbacks.History at 0x7f7e144948d0>
Para avaliação, você pode passar o número de etapas de avaliação:
loss, accuracy = model.evaluate(fmnist_train_ds)
print("Loss :", loss)
print("Accuracy :", accuracy)
1875/1875 [==============================] - 4s 2ms/step - loss: 0.4350 - accuracy: 0.8524 Loss : 0.4350026249885559 Accuracy : 0.8524333238601685
Para conjuntos de dados longos, defina o número de etapas a serem avaliadas:
loss, accuracy = model.evaluate(fmnist_train_ds.repeat(), steps=10)
print("Loss :", loss)
print("Accuracy :", accuracy)
10/10 [==============================] - 0s 2ms/step - loss: 0.4345 - accuracy: 0.8687 Loss : 0.43447819352149963 Accuracy : 0.8687499761581421
Os rótulos não são necessários ao chamar Model.predict .
predict_ds = tf.data.Dataset.from_tensor_slices(images).batch(32)
result = model.predict(predict_ds, steps = 10)
print(result.shape)
(320, 10)
Mas os rótulos são ignorados se você passar um conjunto de dados que os contenha:
result = model.predict(fmnist_train_ds, steps = 10)
print(result.shape)
(320, 10)