
開始使用
TensorFlow Hub 是預先訓練模型的全方位存放區,這些模型可供微調,也可在任何地方部署。您可以下載經過經過訓練的最新模型,且只需要使用 tensorflow_hub 程式庫中極少量的程式碼就能作業。
下列教學課程應可協助您摸索 TF Hub 的模型,並依照個人需求加以應用。互動式教學課程可讓您修改這些模型,並執行變更後的結果。如要練習修改模型,請按一下互動式教學課程頂端的 [Run in Google Colab] (在 Google Colab 中執行) 按鈕。
適合新手
如果您不熟悉機器學習和 TensorFlow,可以先概略瞭解如何將圖片和文字分類、偵測圖片中的物件,或將自己的圖片轉換為著名藝術品的風格:

圖片分類
以預先訓練的圖片分類工具為基礎,建構可分辨花朵的 Keras 模型。
使用 BERT 將文字分類
使用 BERT 建構 Keras 模型,藉此處理文字分類情緒分析工作。風格轉換
讓類神經網路以畢卡索、梵谷或是您自己圖片的風格重新繪製圖片。
物件偵測
使用 FasterRCNN 或 SSD 等模型偵測圖片中的物件。適用於經驗豐富的開發人員
查看更多進階教學課程,瞭解如何使用 TensorFlow Hub 中的自然語言處理技術、圖片、音訊和影片模型。
自然語言處理教學課程
使用 TensorFlow Hub 中的模型完成常見的自然語言處理工作。左側導覽列中列出了所有可用的自然語言處理教學課程。
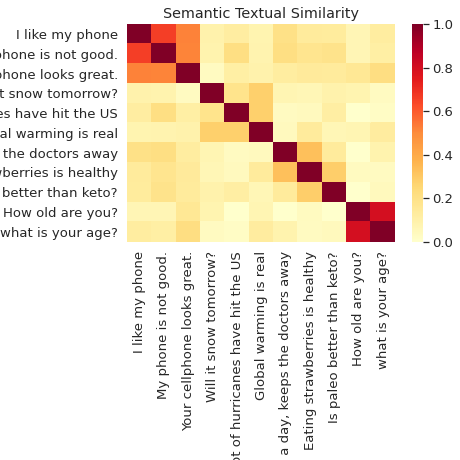
語意相似度
使用 Universal Sentence Encoder 分類句子並比較語意。
針對 TPU 使用 BERT
使用 BERT 處理透過 TPU 執行的 GLUE 基準工作。Multilingual Universal Sentence Encoder Q&A
使用 Multilingual Universal Sentence Encoder Q&A 模型,回答 SQuAD 資料集中的跨語言問題。圖片教學課程
探索如何使用 GAN、超高解析度模型等內容。左側導覽列中列出了所有可用的圖片教學課程。



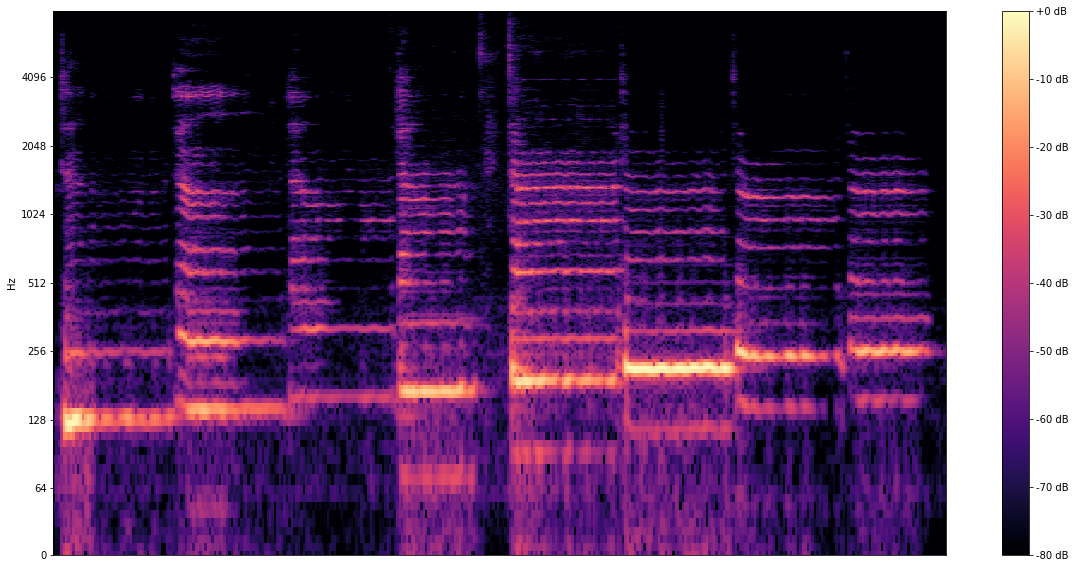
音訊教學課程
透過這些教學課程,瞭解如何使用經過訓練的模型處理音訊資料,包括進行音調辨識和聲音分類。

影片教學課程
試著使用經過訓練的機器學習模型處理影片資料,藉此進行動作辨識、影片畫面內插等工作。


