
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
अवलोकन
टीएफएल Premade सकल समारोह मॉडल त्वरित और आसान तरीके टीएफएल निर्माण करने के लिए कर रहे हैं tf.keras.model जटिल एकत्रीकरण कार्यों सीखने के लिए उदाहरणों। यह मार्गदर्शिका टीएफएल प्रेमाडे एग्रीगेट फंक्शन मॉडल के निर्माण और उसे प्रशिक्षित/परीक्षण करने के लिए आवश्यक कदमों की रूपरेखा तैयार करती है।
सेट अप
TF जाली पैकेज स्थापित करना:
pip install -q tensorflow-lattice pydot
आवश्यक पैकेज आयात करना:
import tensorflow as tf
import collections
import logging
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
पहेलियाँ डेटासेट डाउनलोड करना:
train_dataframe = pd.read_csv(
'https://raw.githubusercontent.com/wbakst/puzzles_data/master/train.csv')
train_dataframe.head()
test_dataframe = pd.read_csv(
'https://raw.githubusercontent.com/wbakst/puzzles_data/master/test.csv')
test_dataframe.head()
सुविधाओं और लेबलों को निकालें और कनवर्ट करें
# Features:
# - star_rating rating out of 5 stars (1-5)
# - word_count number of words in the review
# - is_amazon 1 = reviewed on amazon; 0 = reviewed on artifact website
# - includes_photo if the review includes a photo of the puzzle
# - num_helpful number of people that found this review helpful
# - num_reviews total number of reviews for this puzzle (we construct)
#
# This ordering of feature names will be the exact same order that we construct
# our model to expect.
feature_names = [
'star_rating', 'word_count', 'is_amazon', 'includes_photo', 'num_helpful',
'num_reviews'
]
def extract_features(dataframe, label_name):
# First we extract flattened features.
flattened_features = {
feature_name: dataframe[feature_name].values.astype(float)
for feature_name in feature_names[:-1]
}
# Construct mapping from puzzle name to feature.
star_rating = collections.defaultdict(list)
word_count = collections.defaultdict(list)
is_amazon = collections.defaultdict(list)
includes_photo = collections.defaultdict(list)
num_helpful = collections.defaultdict(list)
labels = {}
# Extract each review.
for i in range(len(dataframe)):
row = dataframe.iloc[i]
puzzle_name = row['puzzle_name']
star_rating[puzzle_name].append(float(row['star_rating']))
word_count[puzzle_name].append(float(row['word_count']))
is_amazon[puzzle_name].append(float(row['is_amazon']))
includes_photo[puzzle_name].append(float(row['includes_photo']))
num_helpful[puzzle_name].append(float(row['num_helpful']))
labels[puzzle_name] = float(row[label_name])
# Organize data into list of list of features.
names = list(star_rating.keys())
star_rating = [star_rating[name] for name in names]
word_count = [word_count[name] for name in names]
is_amazon = [is_amazon[name] for name in names]
includes_photo = [includes_photo[name] for name in names]
num_helpful = [num_helpful[name] for name in names]
num_reviews = [[len(ratings)] * len(ratings) for ratings in star_rating]
labels = [labels[name] for name in names]
# Flatten num_reviews
flattened_features['num_reviews'] = [len(reviews) for reviews in num_reviews]
# Convert data into ragged tensors.
star_rating = tf.ragged.constant(star_rating)
word_count = tf.ragged.constant(word_count)
is_amazon = tf.ragged.constant(is_amazon)
includes_photo = tf.ragged.constant(includes_photo)
num_helpful = tf.ragged.constant(num_helpful)
num_reviews = tf.ragged.constant(num_reviews)
labels = tf.constant(labels)
# Now we can return our extracted data.
return (star_rating, word_count, is_amazon, includes_photo, num_helpful,
num_reviews), labels, flattened_features
train_xs, train_ys, flattened_features = extract_features(train_dataframe, 'Sales12-18MonthsAgo')
test_xs, test_ys, _ = extract_features(test_dataframe, 'SalesLastSixMonths')
# Let's define our label minimum and maximum.
min_label, max_label = float(np.min(train_ys)), float(np.max(train_ys))
min_label, max_label = float(np.min(train_ys)), float(np.max(train_ys))
इस गाइड में प्रशिक्षण के लिए उपयोग किए जाने वाले डिफ़ॉल्ट मान सेट करना:
LEARNING_RATE = 0.1
BATCH_SIZE = 128
NUM_EPOCHS = 500
MIDDLE_DIM = 3
MIDDLE_LATTICE_SIZE = 2
MIDDLE_KEYPOINTS = 16
OUTPUT_KEYPOINTS = 8
फ़ीचर कॉन्फिग
फ़ीचर अंशांकन और प्रति-सुविधा विन्यास का उपयोग कर स्थापित कर रहे हैं tfl.configs.FeatureConfig । फ़ीचर विन्यास दिष्टता बाधाओं, प्रति-सुविधा नियमितीकरण (देखें शामिल tfl.configs.RegularizerConfig ), और जाली मॉडल के लिए जाली आकार।
ध्यान दें कि हमें किसी भी सुविधा के लिए फीचर कॉन्फिग को पूरी तरह से निर्दिष्ट करना होगा जिसे हम अपने मॉडल को पहचानना चाहते हैं। अन्यथा मॉडल के पास यह जानने का कोई तरीका नहीं होगा कि ऐसी सुविधा मौजूद है। एकत्रीकरण मॉडल के लिए, इन सुविधाओं को स्वचालित रूप से माना जाएगा और ठीक से रैग्ड के रूप में संभाला जाएगा।
गणना मात्रा
हालांकि के लिए डिफ़ॉल्ट सेटिंग pwl_calibration_input_keypoints में tfl.configs.FeatureConfig 'quantiles', पूर्व बनाया मॉडल के लिए है हम स्वयं इनपुट keypoints परिभाषित करने के लिए किया है। ऐसा करने के लिए, हम पहले मात्राओं की गणना के लिए अपने स्वयं के सहायक कार्य को परिभाषित करते हैं।
def compute_quantiles(features,
num_keypoints=10,
clip_min=None,
clip_max=None,
missing_value=None):
# Clip min and max if desired.
if clip_min is not None:
features = np.maximum(features, clip_min)
features = np.append(features, clip_min)
if clip_max is not None:
features = np.minimum(features, clip_max)
features = np.append(features, clip_max)
# Make features unique.
unique_features = np.unique(features)
# Remove missing values if specified.
if missing_value is not None:
unique_features = np.delete(unique_features,
np.where(unique_features == missing_value))
# Compute and return quantiles over unique non-missing feature values.
return np.quantile(
unique_features,
np.linspace(0., 1., num=num_keypoints),
interpolation='nearest').astype(float)
हमारे फ़ीचर कॉन्फिग को परिभाषित करना
अब जब हम अपनी मात्राओं की गणना कर सकते हैं, तो हम प्रत्येक सुविधा के लिए एक फीचर कॉन्फिगरेशन को परिभाषित करते हैं जिसे हम चाहते हैं कि हमारा मॉडल इनपुट के रूप में ले।
# Feature configs are used to specify how each feature is calibrated and used.
feature_configs = [
tfl.configs.FeatureConfig(
name='star_rating',
lattice_size=2,
monotonicity='increasing',
pwl_calibration_num_keypoints=5,
pwl_calibration_input_keypoints=compute_quantiles(
flattened_features['star_rating'], num_keypoints=5),
),
tfl.configs.FeatureConfig(
name='word_count',
lattice_size=2,
monotonicity='increasing',
pwl_calibration_num_keypoints=5,
pwl_calibration_input_keypoints=compute_quantiles(
flattened_features['word_count'], num_keypoints=5),
),
tfl.configs.FeatureConfig(
name='is_amazon',
lattice_size=2,
num_buckets=2,
),
tfl.configs.FeatureConfig(
name='includes_photo',
lattice_size=2,
num_buckets=2,
),
tfl.configs.FeatureConfig(
name='num_helpful',
lattice_size=2,
monotonicity='increasing',
pwl_calibration_num_keypoints=5,
pwl_calibration_input_keypoints=compute_quantiles(
flattened_features['num_helpful'], num_keypoints=5),
# Larger num_helpful indicating more trust in star_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="star_rating", trust_type="trapezoid"),
],
),
tfl.configs.FeatureConfig(
name='num_reviews',
lattice_size=2,
monotonicity='increasing',
pwl_calibration_num_keypoints=5,
pwl_calibration_input_keypoints=compute_quantiles(
flattened_features['num_reviews'], num_keypoints=5),
)
]
कुल समारोह मॉडल
एक टीएफएल पूर्व बनाया मॉडल का निर्माण करने के लिए, पहले से एक मॉडल विन्यास का निर्माण tfl.configs । एक समग्र समारोह मॉडल का उपयोग कर निर्माण किया है tfl.configs.AggregateFunctionConfig । यह टुकड़े-टुकड़े-रैखिक और श्रेणीबद्ध अंशांकन लागू करता है, इसके बाद रैग्ड इनपुट के प्रत्येक आयाम पर एक जाली मॉडल होता है। यह तब प्रत्येक आयाम के लिए आउटपुट पर एक एकत्रीकरण परत लागू करता है। इसके बाद एक वैकल्पिक आउटपुट पीसवाइज-लीनियर कैलिब्रेशन होता है।
# Model config defines the model structure for the aggregate function model.
aggregate_function_model_config = tfl.configs.AggregateFunctionConfig(
feature_configs=feature_configs,
middle_dimension=MIDDLE_DIM,
middle_lattice_size=MIDDLE_LATTICE_SIZE,
middle_calibration=True,
middle_calibration_num_keypoints=MIDDLE_KEYPOINTS,
middle_monotonicity='increasing',
output_min=min_label,
output_max=max_label,
output_calibration=True,
output_calibration_num_keypoints=OUTPUT_KEYPOINTS,
output_initialization=np.linspace(
min_label, max_label, num=OUTPUT_KEYPOINTS))
# An AggregateFunction premade model constructed from the given model config.
aggregate_function_model = tfl.premade.AggregateFunction(
aggregate_function_model_config)
# Let's plot our model.
tf.keras.utils.plot_model(
aggregate_function_model, show_layer_names=False, rankdir='LR')
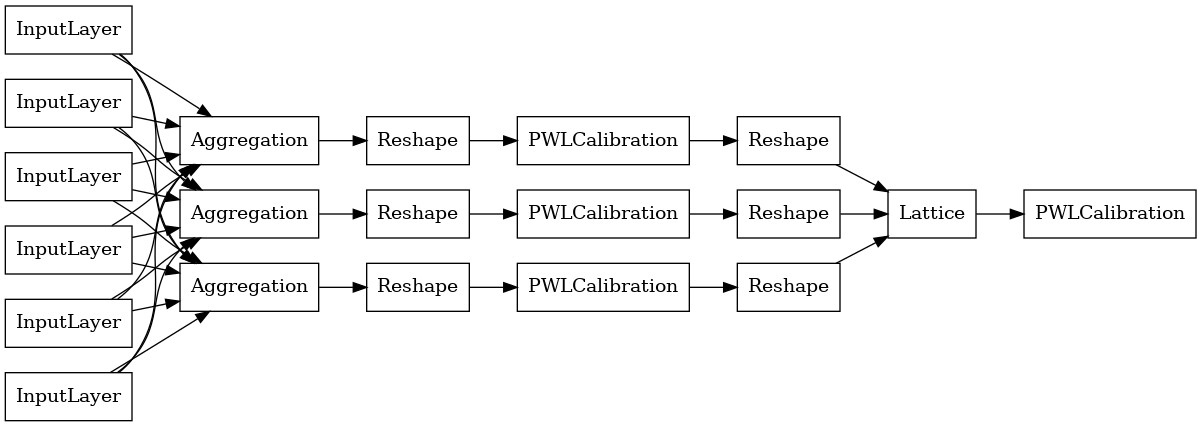
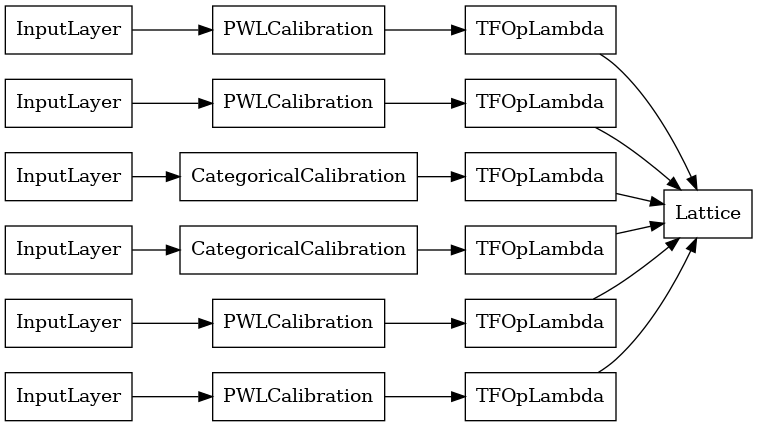
प्रत्येक एकत्रीकरण परत का आउटपुट रैग्ड इनपुट पर कैलिब्रेटेड जाली का औसत आउटपुट होता है। यहाँ पहली एकत्रीकरण परत के अंदर उपयोग किया जाने वाला मॉडल है:
aggregation_layers = [
layer for layer in aggregate_function_model.layers
if isinstance(layer, tfl.layers.Aggregation)
]
tf.keras.utils.plot_model(
aggregation_layers[0].model, show_layer_names=False, rankdir='LR')
अब, किसी अन्य के साथ के रूप में tf.keras.Model , हम संकलन और हमारे डेटा मॉडल फिट।
aggregate_function_model.compile(
loss='mae',
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE))
aggregate_function_model.fit(
train_xs, train_ys, epochs=NUM_EPOCHS, batch_size=BATCH_SIZE, verbose=False)
<tensorflow.python.keras.callbacks.History at 0x7fee7d3033c8>
अपने मॉडल को प्रशिक्षित करने के बाद, हम अपने परीक्षण सेट पर इसका मूल्यांकन कर सकते हैं।
print('Test Set Evaluation...')
print(aggregate_function_model.evaluate(test_xs, test_ys))
Test Set Evaluation... 7/7 [==============================] - 2s 3ms/step - loss: 53.4633 53.4632682800293