
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Tổng quat
Premade Models là cách nhanh chóng và dễ dàng để xây dựng TFL tf.keras.model trường đối với trường hợp sử dụng điển hình. Hướng dẫn này phác thảo các bước cần thiết để xây dựng Mô hình tạo sẵn TFL và đào tạo / kiểm tra mô hình đó.
Thành lập
Cài đặt gói TF Lattice:
pip install tensorflow-lattice pydot
Nhập các gói bắt buộc:
import tensorflow as tf
import copy
import logging
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
Đặt các giá trị mặc định được sử dụng để đào tạo trong hướng dẫn này:
LEARNING_RATE = 0.01
BATCH_SIZE = 128
NUM_EPOCHS = 500
PREFITTING_NUM_EPOCHS = 10
Tải xuống bộ dữ liệu UCI Statlog (Heart):
heart_csv_file = tf.keras.utils.get_file(
'heart.csv',
'http://storage.googleapis.com/download.tensorflow.org/data/heart.csv')
heart_df = pd.read_csv(heart_csv_file)
thal_vocab_list = ['normal', 'fixed', 'reversible']
heart_df['thal'] = heart_df['thal'].map(
{v: i for i, v in enumerate(thal_vocab_list)})
heart_df = heart_df.astype(float)
heart_train_size = int(len(heart_df) * 0.8)
heart_train_dict = dict(heart_df[:heart_train_size])
heart_test_dict = dict(heart_df[heart_train_size:])
# This ordering of input features should match the feature configs. If no
# feature config relies explicitly on the data (i.e. all are 'quantiles'),
# then you can construct the feature_names list by simply iterating over each
# feature config and extracting it's name.
feature_names = [
'age', 'sex', 'cp', 'chol', 'fbs', 'trestbps', 'thalach', 'restecg',
'exang', 'oldpeak', 'slope', 'ca', 'thal'
]
# Since we have some features that manually construct their input keypoints,
# we need an index mapping of the feature names.
feature_name_indices = {name: index for index, name in enumerate(feature_names)}
label_name = 'target'
heart_train_xs = [
heart_train_dict[feature_name] for feature_name in feature_names
]
heart_test_xs = [heart_test_dict[feature_name] for feature_name in feature_names]
heart_train_ys = heart_train_dict[label_name]
heart_test_ys = heart_test_dict[label_name]
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/heart.csv 16384/13273 [=====================================] - 0s 0us/step 24576/13273 [=======================================================] - 0s 0us/step
Cấu hình tính năng
Tính năng hiệu chỉnh và cấu hình cho mỗi tính năng được thiết lập sử dụng tfl.configs.FeatureConfig . Cấu hình tính năng bao gồm các ràng buộc đơn điệu, quy tắc cho mỗi tính năng (xem tfl.configs.RegularizerConfig ), và kích thước lưới cho các mô hình mạng.
Lưu ý rằng chúng ta phải chỉ định đầy đủ cấu hình tính năng cho bất kỳ tính năng nào mà chúng ta muốn mô hình của mình nhận ra. Nếu không, mô hình sẽ không có cách nào để biết rằng một tính năng như vậy tồn tại.
Xác định cấu hình tính năng của chúng tôi
Bây giờ chúng ta có thể tính toán lượng tử của mình, chúng ta xác định cấu hình tính năng cho từng tính năng mà chúng ta muốn mô hình của mình lấy làm đầu vào.
# Features:
# - age
# - sex
# - cp chest pain type (4 values)
# - trestbps resting blood pressure
# - chol serum cholestoral in mg/dl
# - fbs fasting blood sugar > 120 mg/dl
# - restecg resting electrocardiographic results (values 0,1,2)
# - thalach maximum heart rate achieved
# - exang exercise induced angina
# - oldpeak ST depression induced by exercise relative to rest
# - slope the slope of the peak exercise ST segment
# - ca number of major vessels (0-3) colored by flourosopy
# - thal normal; fixed defect; reversable defect
#
# Feature configs are used to specify how each feature is calibrated and used.
heart_feature_configs = [
tfl.configs.FeatureConfig(
name='age',
lattice_size=3,
monotonicity='increasing',
# We must set the keypoints manually.
pwl_calibration_num_keypoints=5,
pwl_calibration_input_keypoints='quantiles',
pwl_calibration_clip_max=100,
# Per feature regularization.
regularizer_configs=[
tfl.configs.RegularizerConfig(name='calib_wrinkle', l2=0.1),
],
),
tfl.configs.FeatureConfig(
name='sex',
num_buckets=2,
),
tfl.configs.FeatureConfig(
name='cp',
monotonicity='increasing',
# Keypoints that are uniformly spaced.
pwl_calibration_num_keypoints=4,
pwl_calibration_input_keypoints=np.linspace(
np.min(heart_train_xs[feature_name_indices['cp']]),
np.max(heart_train_xs[feature_name_indices['cp']]),
num=4),
),
tfl.configs.FeatureConfig(
name='chol',
monotonicity='increasing',
# Explicit input keypoints initialization.
pwl_calibration_input_keypoints=[126.0, 210.0, 247.0, 286.0, 564.0],
# Calibration can be forced to span the full output range by clamping.
pwl_calibration_clamp_min=True,
pwl_calibration_clamp_max=True,
# Per feature regularization.
regularizer_configs=[
tfl.configs.RegularizerConfig(name='calib_hessian', l2=1e-4),
],
),
tfl.configs.FeatureConfig(
name='fbs',
# Partial monotonicity: output(0) <= output(1)
monotonicity=[(0, 1)],
num_buckets=2,
),
tfl.configs.FeatureConfig(
name='trestbps',
monotonicity='decreasing',
pwl_calibration_num_keypoints=5,
pwl_calibration_input_keypoints='quantiles',
),
tfl.configs.FeatureConfig(
name='thalach',
monotonicity='decreasing',
pwl_calibration_num_keypoints=5,
pwl_calibration_input_keypoints='quantiles',
),
tfl.configs.FeatureConfig(
name='restecg',
# Partial monotonicity: output(0) <= output(1), output(0) <= output(2)
monotonicity=[(0, 1), (0, 2)],
num_buckets=3,
),
tfl.configs.FeatureConfig(
name='exang',
# Partial monotonicity: output(0) <= output(1)
monotonicity=[(0, 1)],
num_buckets=2,
),
tfl.configs.FeatureConfig(
name='oldpeak',
monotonicity='increasing',
pwl_calibration_num_keypoints=5,
pwl_calibration_input_keypoints='quantiles',
),
tfl.configs.FeatureConfig(
name='slope',
# Partial monotonicity: output(0) <= output(1), output(1) <= output(2)
monotonicity=[(0, 1), (1, 2)],
num_buckets=3,
),
tfl.configs.FeatureConfig(
name='ca',
monotonicity='increasing',
pwl_calibration_num_keypoints=4,
pwl_calibration_input_keypoints='quantiles',
),
tfl.configs.FeatureConfig(
name='thal',
# Partial monotonicity:
# output(normal) <= output(fixed)
# output(normal) <= output(reversible)
monotonicity=[('normal', 'fixed'), ('normal', 'reversible')],
num_buckets=3,
# We must specify the vocabulary list in order to later set the
# monotonicities since we used names and not indices.
vocabulary_list=thal_vocab_list,
),
]
Đặt Monotonicities và Keypoints
Tiếp theo, chúng ta cần đảm bảo đặt đúng các đơn nguyên cho các tính năng mà chúng ta đã sử dụng từ vựng tùy chỉnh (chẳng hạn như 'thal' ở trên).
tfl.premade_lib.set_categorical_monotonicities(heart_feature_configs)
Cuối cùng, chúng tôi có thể hoàn thành cấu hình tính năng của mình bằng cách tính toán và thiết lập các điểm chính.
feature_keypoints = tfl.premade_lib.compute_feature_keypoints(
feature_configs=heart_feature_configs, features=heart_train_dict)
tfl.premade_lib.set_feature_keypoints(
feature_configs=heart_feature_configs,
feature_keypoints=feature_keypoints,
add_missing_feature_configs=False)
Mô hình tuyến tính đã hiệu chỉnh
Để xây dựng một mô hình premade TFL, đầu tiên xây dựng một cấu hình mô hình từ tfl.configs . Một mô hình tuyến tính hiệu chuẩn được xây dựng bằng cách sử dụng tfl.configs.CalibratedLinearConfig . Nó áp dụng hiệu chuẩn từng đoạn tuyến tính và phân loại trên các tính năng đầu vào, tiếp theo là kết hợp tuyến tính và hiệu chuẩn tuyến tính từng đoạn tùy chọn đầu ra. Khi sử dụng hiệu chuẩn đầu ra hoặc khi giới hạn đầu ra được chỉ định, lớp tuyến tính sẽ áp dụng giá trị trung bình có trọng số trên các đầu vào đã hiệu chuẩn.
Ví dụ này tạo ra một mô hình tuyến tính đã được hiệu chỉnh trên 5 đối tượng đầu tiên.
# Model config defines the model structure for the premade model.
linear_model_config = tfl.configs.CalibratedLinearConfig(
feature_configs=heart_feature_configs[:5],
use_bias=True,
output_calibration=True,
output_calibration_num_keypoints=10,
# We initialize the output to [-2.0, 2.0] since we'll be using logits.
output_initialization=np.linspace(-2.0, 2.0, num=10),
regularizer_configs=[
# Regularizer for the output calibrator.
tfl.configs.RegularizerConfig(name='output_calib_hessian', l2=1e-4),
])
# A CalibratedLinear premade model constructed from the given model config.
linear_model = tfl.premade.CalibratedLinear(linear_model_config)
# Let's plot our model.
tf.keras.utils.plot_model(linear_model, show_layer_names=False, rankdir='LR')
2022-01-14 12:36:31.295751: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
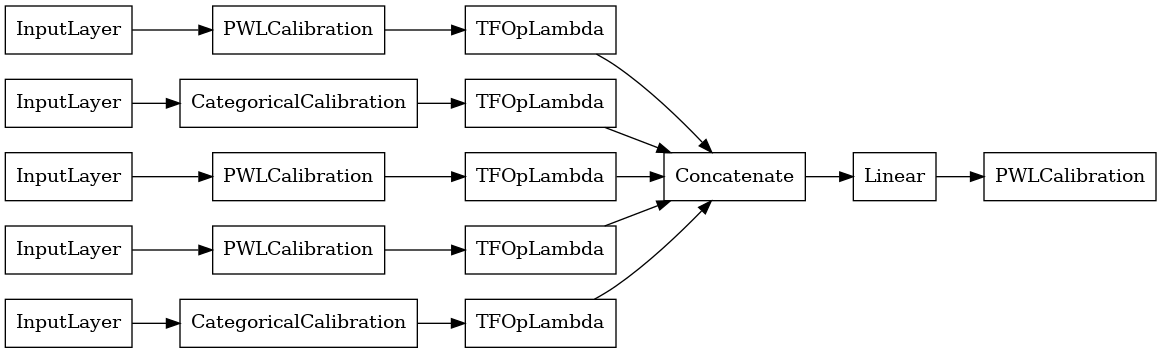
Bây giờ, như với bất kỳ khác tf.keras.Model , chúng tôi biên soạn và phù hợp với mô hình dữ liệu của chúng tôi.
linear_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.AUC(from_logits=True)],
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE))
linear_model.fit(
heart_train_xs[:5],
heart_train_ys,
epochs=NUM_EPOCHS,
batch_size=BATCH_SIZE,
verbose=False)
<keras.callbacks.History at 0x7fe4385f0290>
Sau khi đào tạo mô hình của chúng tôi, chúng tôi có thể đánh giá nó trên bộ thử nghiệm của chúng tôi.
print('Test Set Evaluation...')
print(linear_model.evaluate(heart_test_xs[:5], heart_test_ys))
Test Set Evaluation... 2/2 [==============================] - 0s 3ms/step - loss: 0.4728 - auc: 0.8252 [0.47278329730033875, 0.8251879215240479]
Mô hình mạng đã hiệu chỉnh
Một mô hình mạng hiệu chuẩn được xây dựng bằng tfl.configs.CalibratedLatticeConfig . Mô hình mạng tinh thể đã hiệu chuẩn áp dụng hiệu chuẩn từng đoạn tuyến tính và phân loại trên các tính năng đầu vào, tiếp theo là mô hình mạng tinh thể và hiệu chuẩn tuyến tính từng đoạn tùy chọn đầu ra.
Ví dụ này tạo ra một mô hình mạng tinh thể đã được hiệu chỉnh trên 5 tính năng đầu tiên.
# This is a calibrated lattice model: inputs are calibrated, then combined
# non-linearly using a lattice layer.
lattice_model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=heart_feature_configs[:5],
# We initialize the output to [-2.0, 2.0] since we'll be using logits.
output_initialization=[-2.0, 2.0],
regularizer_configs=[
# Torsion regularizer applied to the lattice to make it more linear.
tfl.configs.RegularizerConfig(name='torsion', l2=1e-2),
# Globally defined calibration regularizer is applied to all features.
tfl.configs.RegularizerConfig(name='calib_hessian', l2=1e-2),
])
# A CalibratedLattice premade model constructed from the given model config.
lattice_model = tfl.premade.CalibratedLattice(lattice_model_config)
# Let's plot our model.
tf.keras.utils.plot_model(lattice_model, show_layer_names=False, rankdir='LR')
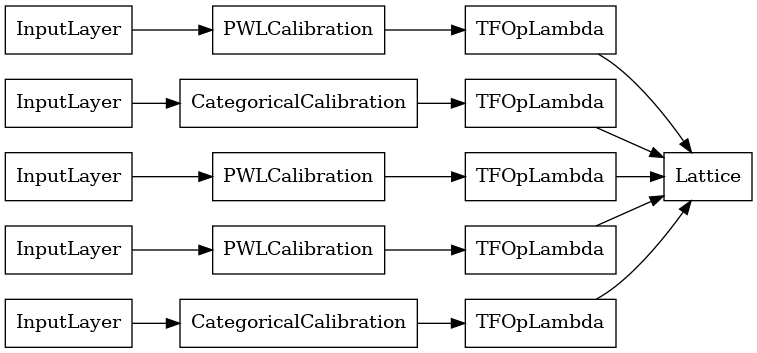
Như trước đây, chúng tôi biên dịch, điều chỉnh và đánh giá mô hình của mình.
lattice_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.AUC(from_logits=True)],
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE))
lattice_model.fit(
heart_train_xs[:5],
heart_train_ys,
epochs=NUM_EPOCHS,
batch_size=BATCH_SIZE,
verbose=False)
print('Test Set Evaluation...')
print(lattice_model.evaluate(heart_test_xs[:5], heart_test_ys))
Test Set Evaluation... 2/2 [==============================] - 1s 3ms/step - loss: 0.4709 - auc_1: 0.8302 [0.4709009826183319, 0.8302004933357239]
Mô hình kết hợp mạng lưới đã hiệu chỉnh
Khi số lượng đối tượng lớn, bạn có thể sử dụng mô hình tổng hợp, mô hình này tạo ra nhiều mạng nhỏ hơn cho các tập hợp con của các đối tượng và tính trung bình sản lượng của chúng thay vì chỉ tạo một mạng khổng lồ duy nhất. Mô hình mạng Ensemble được xây dựng sử dụng tfl.configs.CalibratedLatticeEnsembleConfig . Mô hình tổng hợp mạng tinh thể đã hiệu chuẩn áp dụng hiệu chuẩn từng đoạn tuyến tính và phân loại trên tính năng đầu vào, tiếp theo là một nhóm các mô hình mạng tinh thể và hiệu chuẩn tuyến tính từng đoạn tùy chọn đầu ra.
Khởi tạo Ensemble lưới rõ ràng
Nếu bạn đã biết tập hợp con của các tính năng nào bạn muốn đưa vào mạng của mình, thì bạn có thể đặt các mạng một cách rõ ràng bằng cách sử dụng tên các tính năng. Ví dụ này tạo ra một mô hình tổng thể mạng tinh thể đã được hiệu chuẩn với 5 mạng tinh thể và 3 tính năng trên mỗi mạng tinh thể.
# This is a calibrated lattice ensemble model: inputs are calibrated, then
# combined non-linearly and averaged using multiple lattice layers.
explicit_ensemble_model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
feature_configs=heart_feature_configs,
lattices=[['trestbps', 'chol', 'ca'], ['fbs', 'restecg', 'thal'],
['fbs', 'cp', 'oldpeak'], ['exang', 'slope', 'thalach'],
['restecg', 'age', 'sex']],
num_lattices=5,
lattice_rank=3,
# We initialize the output to [-2.0, 2.0] since we'll be using logits.
output_initialization=[-2.0, 2.0])
# A CalibratedLatticeEnsemble premade model constructed from the given
# model config.
explicit_ensemble_model = tfl.premade.CalibratedLatticeEnsemble(
explicit_ensemble_model_config)
# Let's plot our model.
tf.keras.utils.plot_model(
explicit_ensemble_model, show_layer_names=False, rankdir='LR')
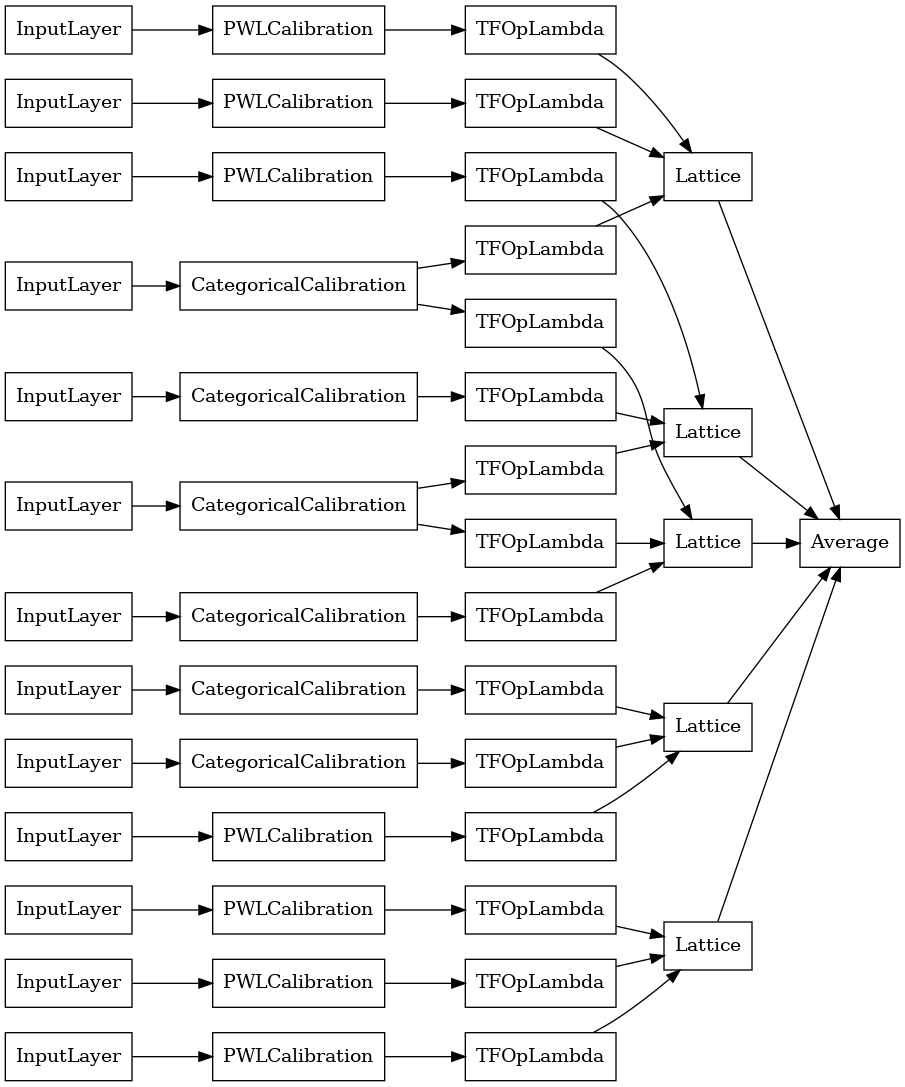
Như trước đây, chúng tôi biên dịch, điều chỉnh và đánh giá mô hình của mình.
explicit_ensemble_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.AUC(from_logits=True)],
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE))
explicit_ensemble_model.fit(
heart_train_xs,
heart_train_ys,
epochs=NUM_EPOCHS,
batch_size=BATCH_SIZE,
verbose=False)
print('Test Set Evaluation...')
print(explicit_ensemble_model.evaluate(heart_test_xs, heart_test_ys))
Test Set Evaluation... 2/2 [==============================] - 1s 4ms/step - loss: 0.3768 - auc_2: 0.8954 [0.3768467903137207, 0.895363450050354]
Hệ thống mạng ngẫu nhiên
Nếu bạn không chắc chắn nên cung cấp tập hợp con của các tính năng nào vào mạng của mình, thì một tùy chọn khác là sử dụng tập hợp con ngẫu nhiên của các tính năng cho mỗi mạng. Ví dụ này tạo ra một mô hình tổng thể mạng tinh thể đã được hiệu chuẩn với 5 mạng tinh thể và 3 tính năng trên mỗi mạng tinh thể.
# This is a calibrated lattice ensemble model: inputs are calibrated, then
# combined non-linearly and averaged using multiple lattice layers.
random_ensemble_model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
feature_configs=heart_feature_configs,
lattices='random',
num_lattices=5,
lattice_rank=3,
# We initialize the output to [-2.0, 2.0] since we'll be using logits.
output_initialization=[-2.0, 2.0],
random_seed=42)
# Now we must set the random lattice structure and construct the model.
tfl.premade_lib.set_random_lattice_ensemble(random_ensemble_model_config)
# A CalibratedLatticeEnsemble premade model constructed from the given
# model config.
random_ensemble_model = tfl.premade.CalibratedLatticeEnsemble(
random_ensemble_model_config)
# Let's plot our model.
tf.keras.utils.plot_model(
random_ensemble_model, show_layer_names=False, rankdir='LR')
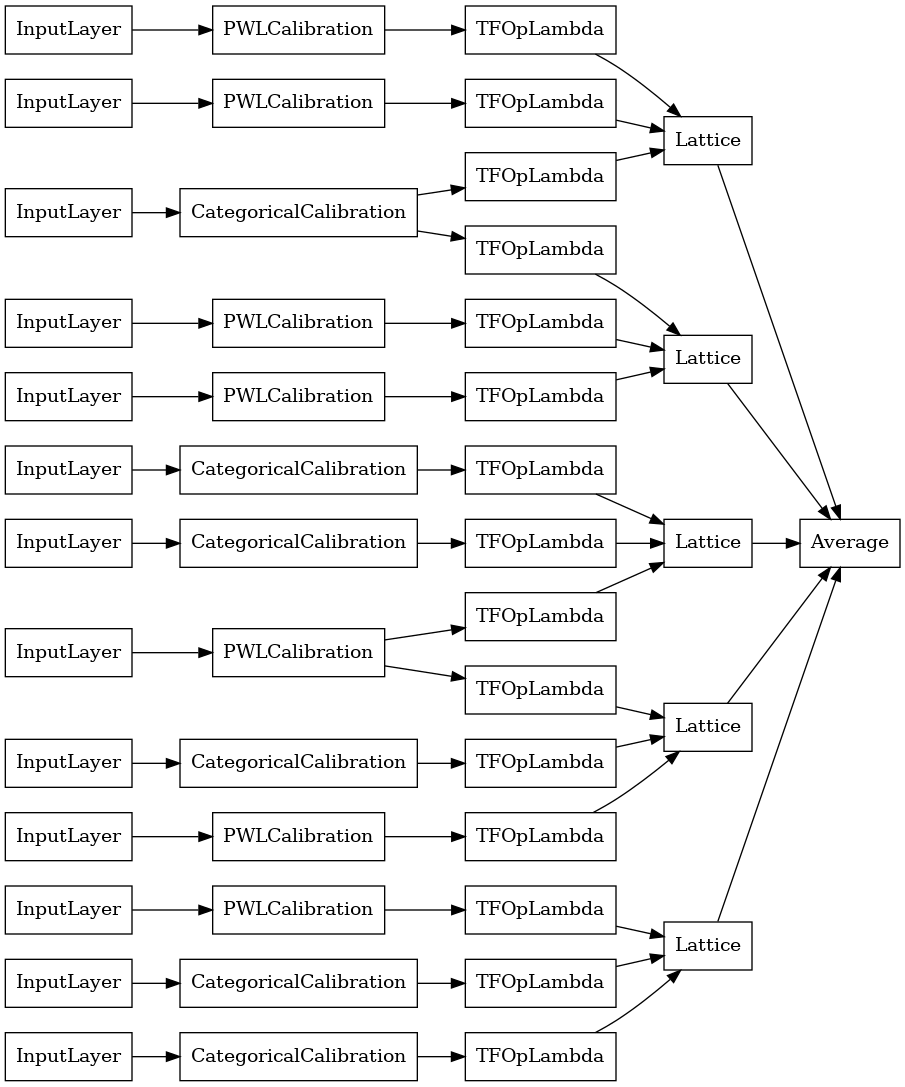
Như trước đây, chúng tôi biên dịch, điều chỉnh và đánh giá mô hình của mình.
random_ensemble_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.AUC(from_logits=True)],
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE))
random_ensemble_model.fit(
heart_train_xs,
heart_train_ys,
epochs=NUM_EPOCHS,
batch_size=BATCH_SIZE,
verbose=False)
print('Test Set Evaluation...')
print(random_ensemble_model.evaluate(heart_test_xs, heart_test_ys))
Test Set Evaluation... 2/2 [==============================] - 1s 4ms/step - loss: 0.3739 - auc_3: 0.8997 [0.3739270567893982, 0.8997493982315063]
Hệ thống mạng ngẫu nhiên lớp RTL
Khi sử dụng một ngẫu nhiên lưới quần, bạn có thể xác định rằng các mô hình sử dụng một đơn tfl.layers.RTL lớp. Chúng tôi lưu ý rằng tfl.layers.RTL chỉ hỗ trợ hạn chế đơn điệu và phải có kích thước lưới tương tự cho tất cả các tính năng và không theo quy tắc mỗi tính năng. Lưu ý rằng việc sử dụng một tfl.layers.RTL lớp cho phép bạn mở rộng để cụm công trình lớn hơn nhiều so với sử dụng riêng biệt tfl.layers.Lattice trường.
Ví dụ này tạo ra một mô hình tổng thể mạng tinh thể đã được hiệu chuẩn với 5 mạng tinh thể và 3 tính năng trên mỗi mạng tinh thể.
# Make sure our feature configs have the same lattice size, no per-feature
# regularization, and only monotonicity constraints.
rtl_layer_feature_configs = copy.deepcopy(heart_feature_configs)
for feature_config in rtl_layer_feature_configs:
feature_config.lattice_size = 2
feature_config.unimodality = 'none'
feature_config.reflects_trust_in = None
feature_config.dominates = None
feature_config.regularizer_configs = None
# This is a calibrated lattice ensemble model: inputs are calibrated, then
# combined non-linearly and averaged using multiple lattice layers.
rtl_layer_ensemble_model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
feature_configs=rtl_layer_feature_configs,
lattices='rtl_layer',
num_lattices=5,
lattice_rank=3,
# We initialize the output to [-2.0, 2.0] since we'll be using logits.
output_initialization=[-2.0, 2.0],
random_seed=42)
# A CalibratedLatticeEnsemble premade model constructed from the given
# model config. Note that we do not have to specify the lattices by calling
# a helper function (like before with random) because the RTL Layer will take
# care of that for us.
rtl_layer_ensemble_model = tfl.premade.CalibratedLatticeEnsemble(
rtl_layer_ensemble_model_config)
# Let's plot our model.
tf.keras.utils.plot_model(
rtl_layer_ensemble_model, show_layer_names=False, rankdir='LR')
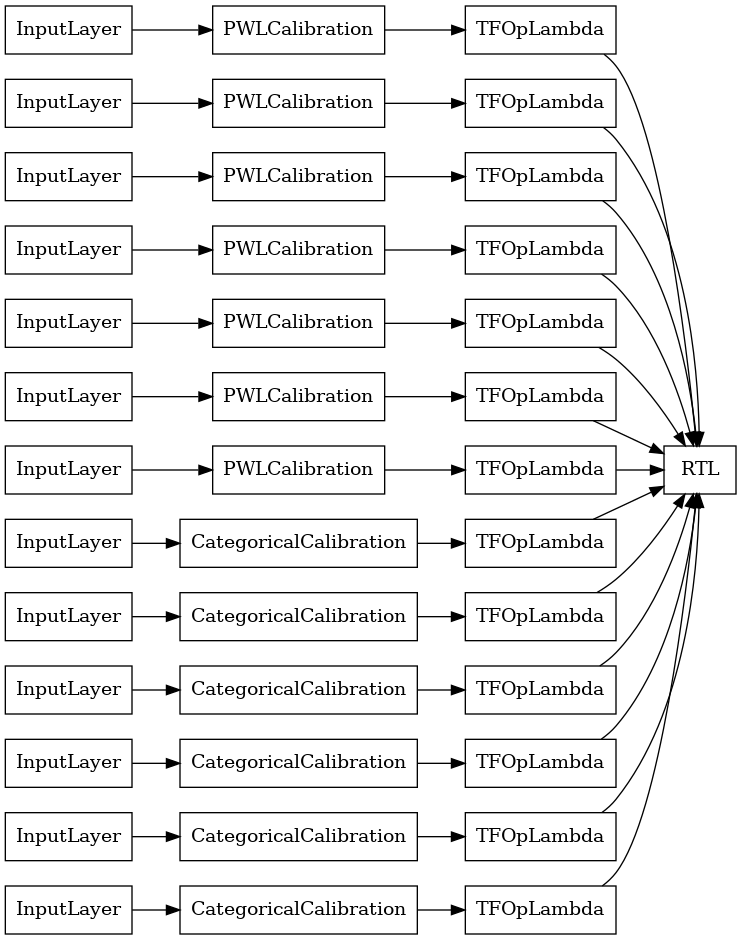
Như trước đây, chúng tôi biên dịch, điều chỉnh và đánh giá mô hình của mình.
rtl_layer_ensemble_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.AUC(from_logits=True)],
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE))
rtl_layer_ensemble_model.fit(
heart_train_xs,
heart_train_ys,
epochs=NUM_EPOCHS,
batch_size=BATCH_SIZE,
verbose=False)
print('Test Set Evaluation...')
print(rtl_layer_ensemble_model.evaluate(heart_test_xs, heart_test_ys))
Test Set Evaluation... 2/2 [==============================] - 0s 3ms/step - loss: 0.3614 - auc_4: 0.9079 [0.36142951250076294, 0.9078947305679321]
Crystals Lattice Ensemble
Premade cũng cung cấp một thuật toán sắp xếp tính năng heuristic, gọi là Crystal . Để sử dụng thuật toán Crystals, trước tiên, chúng tôi đào tạo mô hình prefitting ước tính các tương tác tính năng theo từng cặp. Sau đó, chúng tôi sắp xếp tập hợp cuối cùng sao cho các đối tượng địa lý có nhiều tương tác phi tuyến tính hơn nằm trong cùng một mạng lưới.
Thư viện Premade cung cấp các chức năng trợ giúp để xây dựng cấu hình mô hình chuẩn bị sẵn và trích xuất cấu trúc tinh thể. Lưu ý rằng mô hình prefitting không cần được đào tạo đầy đủ, vì vậy chỉ cần một vài kỷ nguyên là đủ.
Ví dụ này tạo ra một mô hình tổng hợp mạng tinh thể đã được hiệu chuẩn với 5 mạng tinh thể và 3 tính năng trên mỗi mạng tinh thể.
# This is a calibrated lattice ensemble model: inputs are calibrated, then
# combines non-linearly and averaged using multiple lattice layers.
crystals_ensemble_model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
feature_configs=heart_feature_configs,
lattices='crystals',
num_lattices=5,
lattice_rank=3,
# We initialize the output to [-2.0, 2.0] since we'll be using logits.
output_initialization=[-2.0, 2.0],
random_seed=42)
# Now that we have our model config, we can construct a prefitting model config.
prefitting_model_config = tfl.premade_lib.construct_prefitting_model_config(
crystals_ensemble_model_config)
# A CalibratedLatticeEnsemble premade model constructed from the given
# prefitting model config.
prefitting_model = tfl.premade.CalibratedLatticeEnsemble(
prefitting_model_config)
# We can compile and train our prefitting model as we like.
prefitting_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE))
prefitting_model.fit(
heart_train_xs,
heart_train_ys,
epochs=PREFITTING_NUM_EPOCHS,
batch_size=BATCH_SIZE,
verbose=False)
# Now that we have our trained prefitting model, we can extract the crystals.
tfl.premade_lib.set_crystals_lattice_ensemble(crystals_ensemble_model_config,
prefitting_model_config,
prefitting_model)
# A CalibratedLatticeEnsemble premade model constructed from the given
# model config.
crystals_ensemble_model = tfl.premade.CalibratedLatticeEnsemble(
crystals_ensemble_model_config)
# Let's plot our model.
tf.keras.utils.plot_model(
crystals_ensemble_model, show_layer_names=False, rankdir='LR')
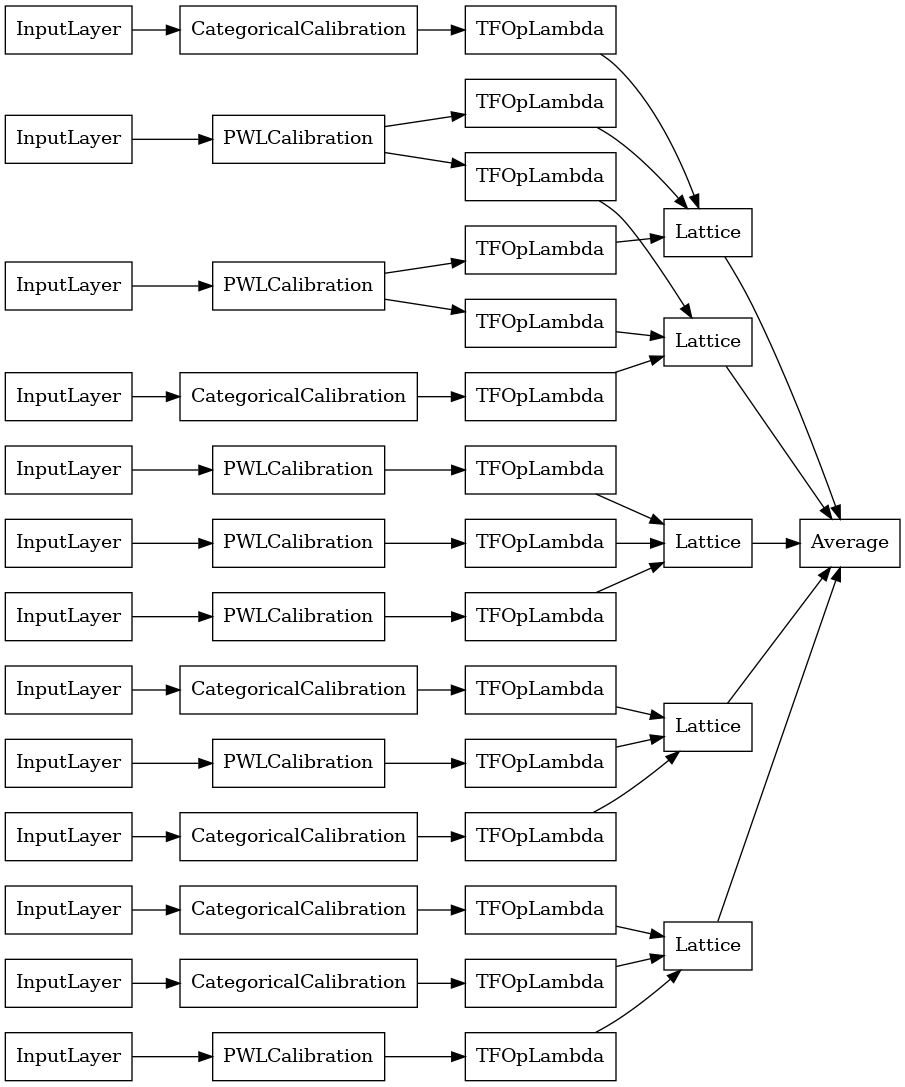
Như trước đây, chúng tôi biên dịch, điều chỉnh và đánh giá mô hình của mình.
crystals_ensemble_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.AUC(from_logits=True)],
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE))
crystals_ensemble_model.fit(
heart_train_xs,
heart_train_ys,
epochs=NUM_EPOCHS,
batch_size=BATCH_SIZE,
verbose=False)
print('Test Set Evaluation...')
print(crystals_ensemble_model.evaluate(heart_test_xs, heart_test_ys))
Test Set Evaluation... 2/2 [==============================] - 1s 3ms/step - loss: 0.3404 - auc_5: 0.9179 [0.34039050340652466, 0.9179198145866394]