
यह ट्यूटोरियल आपको दिखाता है कि प्राकृतिक भाषा पाठ को वर्गीकृत करने के लिए TensorFlow Lite का उपयोग करके एंड्रॉइड एप्लिकेशन कैसे बनाया जाए। यह एप्लिकेशन एक भौतिक एंड्रॉइड डिवाइस के लिए डिज़ाइन किया गया है, लेकिन यह डिवाइस एमुलेटर पर भी चल सकता है।
उदाहरण एप्लिकेशन टेक्स्ट को सकारात्मक या नकारात्मक के रूप में वर्गीकृत करने के लिए टेन्सरफ्लो लाइट का उपयोग करता है, टेक्स्ट वर्गीकरण मशीन लर्निंग मॉडल के निष्पादन को सक्षम करने के लिए प्राकृतिक भाषा (एनएल) के लिए टास्क लाइब्रेरी का उपयोग करता है।
यदि आप किसी मौजूदा प्रोजेक्ट को अपडेट कर रहे हैं, तो आप उदाहरण एप्लिकेशन को संदर्भ या टेम्पलेट के रूप में उपयोग कर सकते हैं। किसी मौजूदा एप्लिकेशन में टेक्स्ट वर्गीकरण जोड़ने के निर्देशों के लिए, अपने एप्लिकेशन को अपडेट करना और संशोधित करना देखें।
पाठ वर्गीकरण सिंहावलोकन
टेक्स्ट वर्गीकरण ओपन-एंडेड टेक्स्ट को पूर्वनिर्धारित श्रेणियों का एक सेट निर्दिष्ट करने का मशीन सीखने का कार्य है। एक पाठ वर्गीकरण मॉडल को प्राकृतिक भाषा पाठ के एक संग्रह पर प्रशिक्षित किया जाता है, जहां शब्दों या वाक्यांशों को मैन्युअल रूप से वर्गीकृत किया जाता है।
प्रशिक्षित मॉडल टेक्स्ट को इनपुट के रूप में प्राप्त करता है और टेक्स्ट को ज्ञात वर्गों के सेट के अनुसार वर्गीकृत करने का प्रयास करता है जिसे वर्गीकृत करने के लिए उसे प्रशिक्षित किया गया था। उदाहरण के लिए, इस उदाहरण में मॉडल पाठ का एक टुकड़ा स्वीकार करते हैं और यह निर्धारित करते हैं कि पाठ की भावना सकारात्मक है या नकारात्मक। पाठ के प्रत्येक स्निपेट के लिए, पाठ वर्गीकरण मॉडल एक स्कोर आउटपुट करता है जो पाठ के सकारात्मक या नकारात्मक के रूप में सही ढंग से वर्गीकृत होने के विश्वास को इंगित करता है।
इस ट्यूटोरियल में मॉडल कैसे तैयार किए जाते हैं, इस बारे में अधिक जानकारी के लिए, TensorFlow Lite मॉडल मेकर ट्यूटोरियल के साथ टेक्स्ट वर्गीकरण देखें।
मॉडल और डेटासेट
यह ट्यूटोरियल उन मॉडलों का उपयोग करता है जिन्हें SST-2 (स्टैनफोर्ड सेंटीमेंट ट्रीबैंक) डेटासेट का उपयोग करके प्रशिक्षित किया गया था। एसएसटी-2 में प्रशिक्षण के लिए 67,349 मूवी समीक्षाएं और परीक्षण के लिए 872 मूवी समीक्षाएं शामिल हैं, प्रत्येक समीक्षा को सकारात्मक या नकारात्मक के रूप में वर्गीकृत किया गया है। इस ऐप में उपयोग किए गए मॉडल को TensorFlow Lite मॉडल मेकर टूल का उपयोग करके प्रशिक्षित किया गया था।
उदाहरण एप्लिकेशन निम्नलिखित पूर्व-प्रशिक्षित मॉडल का उपयोग करता है:
औसत वर्ड वेक्टर (
NLClassifier) - टास्क लाइब्रेरी काNLClassifierइनपुट टेक्स्ट को विभिन्न श्रेणियों में वर्गीकृत करता है, और अधिकांश टेक्स्ट वर्गीकरण मॉडल को संभाल सकता है।मोबाइलबीईआरटी (
BertNLClassifier) - टास्क लाइब्रेरी काBertNLClassifierएनएलक्लासिफायर के समान है, लेकिन उन मामलों के लिए तैयार किया गया है जिनके लिए आउट-ऑफ-ग्राफ वर्डपीस और सेंटेंसपीस टोकनाइजेशन की आवश्यकता होती है।
उदाहरण ऐप सेटअप करें और चलाएं
टेक्स्ट वर्गीकरण एप्लिकेशन को सेटअप करने के लिए, GitHub से उदाहरण ऐप डाउनलोड करें और इसे Android Studio का उपयोग करके चलाएं।
सिस्टम आवश्यकताएं
- एंड्रॉइड स्टूडियो संस्करण 2021.1.1 (भौंरा) या उच्चतर।
- एंड्रॉइड एसडीके संस्करण 31 या उच्चतर
- डेवलपर मोड सक्षम या एंड्रॉइड एमुलेटर के साथ एसडीके 21 (एंड्रॉइड 7.0 - नूगट) के न्यूनतम ओएस संस्करण वाला एंड्रॉइड डिवाइस।
उदाहरण कोड प्राप्त करें
उदाहरण कोड की एक स्थानीय प्रतिलिपि बनाएँ। आप एंड्रॉइड स्टूडियो में एक प्रोजेक्ट बनाने और उदाहरण एप्लिकेशन चलाने के लिए इस कोड का उपयोग करेंगे।
उदाहरण कोड को क्लोन और सेटअप करने के लिए:
- Git रिपॉजिटरी
git clone https://github.com/tensorflow/examples.git
क्लोन करें - वैकल्पिक रूप से, अपने git इंस्टेंस को विरल चेकआउट का उपयोग करने के लिए कॉन्फ़िगर करें, ताकि आपके पास केवल टेक्स्ट वर्गीकरण उदाहरण ऐप के लिए फ़ाइलें हों:
cd examples git sparse-checkout init --cone git sparse-checkout set lite/examples/text_classification/android
प्रोजेक्ट आयात करें और चलाएं
डाउनलोड किए गए उदाहरण कोड से एक प्रोजेक्ट बनाएं, प्रोजेक्ट बनाएं और फिर उसे चलाएं।
उदाहरण कोड प्रोजेक्ट आयात करने और बनाने के लिए:
- एंड्रॉइड स्टूडियो प्रारंभ करें।
- एंड्रॉइड स्टूडियो से, फ़ाइल > नया > प्रोजेक्ट आयात करें चुनें।
- बिल्ड.ग्रेडल फ़ाइल (
.../examples/lite/examples/text_classification/android/build.gradle) वाली उदाहरण कोड निर्देशिका पर नेविगेट करें और उस निर्देशिका का चयन करें। - यदि एंड्रॉइड स्टूडियो ग्रैडल सिंक का अनुरोध करता है, तो ठीक चुनें।
- सुनिश्चित करें कि आपका एंड्रॉइड डिवाइस आपके कंप्यूटर से कनेक्ट है और डेवलपर मोड सक्षम है। हरे
Runतीर पर क्लिक करें।
यदि आप सही निर्देशिका का चयन करते हैं, तो एंड्रॉइड स्टूडियो एक नया प्रोजेक्ट बनाता है और उसे बनाता है। आपके कंप्यूटर की गति और यदि आपने अन्य परियोजनाओं के लिए एंड्रॉइड स्टूडियो का उपयोग किया है, तो इस प्रक्रिया में कुछ मिनट लग सकते हैं। जब निर्माण पूरा हो जाता है, तो एंड्रॉइड स्टूडियो बिल्ड आउटपुट स्थिति पैनल में एक BUILD SUCCESSFUL संदेश प्रदर्शित करता है।
प्रोजेक्ट चलाने के लिए:
- एंड्रॉइड स्टूडियो से, रन > रन… का चयन करके प्रोजेक्ट चलाएं।
- ऐप का परीक्षण करने के लिए एक संलग्न एंड्रॉइड डिवाइस (या एमुलेटर) का चयन करें।
एप्लिकेशन का उपयोग करना
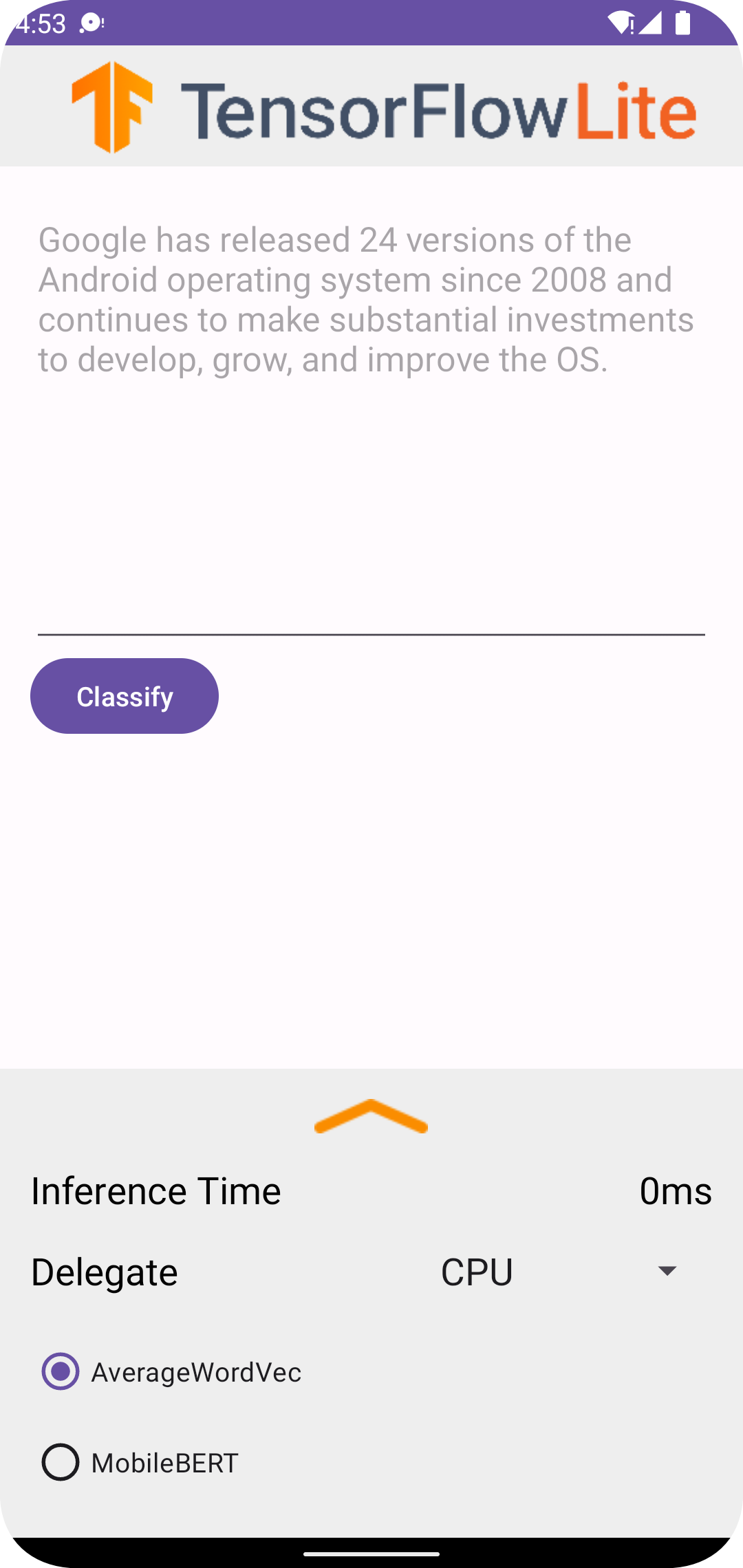
एंड्रॉइड स्टूडियो में प्रोजेक्ट चलाने के बाद, एप्लिकेशन स्वचालित रूप से कनेक्टेड डिवाइस या डिवाइस एमुलेटर पर खुल जाएगा।
टेक्स्ट क्लासिफायरियर का उपयोग करने के लिए:
- टेक्स्ट बॉक्स में टेक्स्ट का एक स्निपेट दर्ज करें।
- प्रतिनिधि ड्रॉप-डाउन से,
CPUयाNNAPIमें से किसी एक को चुनें। -
AverageWordVecयाMobileBERTमें से किसी एक को चुनकर एक मॉडल निर्दिष्ट करें। - वर्गीकृत करें चुनें.
एप्लिकेशन एक सकारात्मक स्कोर और एक नकारात्मक स्कोर आउटपुट करता है। इन दोनों अंकों का योग 1 होगा, और यह इस संभावना को मापता है कि इनपुट टेक्स्ट की भावना सकारात्मक या नकारात्मक है। अधिक संख्या आत्मविश्वास के उच्च स्तर को दर्शाती है।
अब आपके पास एक क्रियाशील पाठ वर्गीकरण अनुप्रयोग है। यह बेहतर ढंग से समझने के लिए कि उदाहरण एप्लिकेशन कैसे काम करता है, और अपने उत्पादन अनुप्रयोगों में टेक्स्ट वर्गीकरण सुविधाओं को कैसे कार्यान्वित करें, निम्नलिखित अनुभागों का उपयोग करें:
एप्लिकेशन कैसे काम करता है - उदाहरण एप्लिकेशन की संरचना और मुख्य फ़ाइलों का पूर्वाभ्यास।
अपने एप्लिकेशन को संशोधित करें - मौजूदा एप्लिकेशन में टेक्स्ट वर्गीकरण जोड़ने पर निर्देश।
उदाहरण ऐप कैसे काम करता है
एप्लिकेशन टेक्स्ट वर्गीकरण मॉडल को लागू करने के लिए प्राकृतिक भाषा (एनएल) पैकेज के लिए टास्क लाइब्रेरी का उपयोग करता है। दो मॉडल, औसत वर्ड वेक्टर और MobileBERT, को TensorFlow Lite मॉडल मेकर का उपयोग करके प्रशिक्षित किया गया था। एप्लिकेशन एनएनएपीआई प्रतिनिधि का उपयोग करके हार्डवेयर त्वरण के विकल्प के साथ, डिफ़ॉल्ट रूप से सीपीयू पर चलता है।
निम्नलिखित फ़ाइलों और निर्देशिकाओं में इस पाठ वर्गीकरण एप्लिकेशन के लिए महत्वपूर्ण कोड शामिल हैं:
- TextClassificationHelper.kt - टेक्स्ट क्लासिफायर को आरंभ करता है और मॉडल और प्रतिनिधि चयन को संभालता है।
- MainActivity.kt -
TextClassificationHelperऔरResultsAdapterकॉल करने सहित एप्लिकेशन को कार्यान्वित करता है। - ResultsAdapter.kt - परिणामों को संभालता है और प्रारूपित करता है।
अपना आवेदन संशोधित करें
निम्नलिखित अनुभाग उदाहरण ऐप में दिखाए गए मॉडल को चलाने के लिए आपके स्वयं के एंड्रॉइड ऐप को संशोधित करने के मुख्य चरणों की व्याख्या करते हैं। ये निर्देश उदाहरण ऐप को संदर्भ बिंदु के रूप में उपयोग करते हैं। आपके अपने ऐप के लिए आवश्यक विशिष्ट परिवर्तन उदाहरण ऐप से भिन्न हो सकते हैं।
एक Android प्रोजेक्ट खोलें या बनाएं
आपको इन बाकी निर्देशों के साथ पालन करने के लिए एंड्रॉइड स्टूडियो में एक एंड्रॉइड डेवलपमेंट प्रोजेक्ट की आवश्यकता है। किसी मौजूदा प्रोजेक्ट को खोलने या नया प्रोजेक्ट बनाने के लिए नीचे दिए गए निर्देशों का पालन करें।
मौजूदा Android विकास प्रोजेक्ट खोलने के लिए:
- एंड्रॉइड स्टूडियो में, फ़ाइल > खोलें चुनें और एक मौजूदा प्रोजेक्ट चुनें।
एक बुनियादी Android विकास प्रोजेक्ट बनाने के लिए:
- एक बुनियादी प्रोजेक्ट बनाने के लिए एंड्रॉइड स्टूडियो में दिए गए निर्देशों का पालन करें।
एंड्रॉइड स्टूडियो का उपयोग करने के बारे में अधिक जानकारी के लिए, एंड्रॉइड स्टूडियो दस्तावेज़ देखें।
प्रोजेक्ट निर्भरताएँ जोड़ें
अपने स्वयं के एप्लिकेशन में, आपको TensorFlow Lite मशीन लर्निंग मॉडल चलाने के लिए विशिष्ट प्रोजेक्ट निर्भरताएं जोड़नी होंगी, और उपयोगिता फ़ंक्शंस तक पहुंच प्राप्त करनी होगी जो स्ट्रिंग जैसे डेटा को टेंसर डेटा प्रारूप में परिवर्तित करते हैं जिसे आपके द्वारा उपयोग किए जा रहे मॉडल द्वारा संसाधित किया जा सकता है।
निम्नलिखित निर्देश बताते हैं कि अपने स्वयं के एंड्रॉइड ऐप प्रोजेक्ट में आवश्यक प्रोजेक्ट और मॉड्यूल निर्भरता कैसे जोड़ें।
मॉड्यूल निर्भरताएँ जोड़ने के लिए:
TensorFlow Lite का उपयोग करने वाले मॉड्यूल में, निम्नलिखित निर्भरताओं को शामिल करने के लिए मॉड्यूल की
build.gradleफ़ाइल को अपडेट करें।उदाहरण एप्लिकेशन में, निर्भरताएं ऐप/बिल्ड.ग्रेडल में स्थित हैं:
dependencies { ... implementation 'org.tensorflow:tensorflow-lite-task-text:0.4.0' }प्रोजेक्ट में टेक्स्ट टास्क लाइब्रेरी (
tensorflow-lite-task-text) शामिल होनी चाहिए।यदि आप ग्राफिक्स प्रोसेसिंग यूनिट (जीपीयू) पर चलाने के लिए इस ऐप को संशोधित करना चाहते हैं, तो जीपीयू लाइब्रेरी (
tensorflow-lite-gpu-delegate-plugin) ऐप को जीपीयू पर चलाने के लिए बुनियादी ढांचा प्रदान करती है, और डेलीगेट (tensorflow-lite-gpu) अनुकूलता सूची प्रदान करता है। इस ऐप को GPU पर चलाना इस ट्यूटोरियल के दायरे से बाहर है।एंड्रॉइड स्टूडियो में, चयन करके प्रोजेक्ट निर्भरता को सिंक करें: फ़ाइल > ग्रैडल फ़ाइलों के साथ प्रोजेक्ट सिंक करें ।
एमएल मॉडल प्रारंभ करें
अपने एंड्रॉइड ऐप में, आपको मॉडल के साथ पूर्वानुमान चलाने से पहले मापदंडों के साथ TensorFlow Lite मशीन लर्निंग मॉडल को आरंभ करना होगा।
TensorFlow Lite मॉडल को *.tflite फ़ाइल के रूप में संग्रहीत किया जाता है। मॉडल फ़ाइल में भविष्यवाणी तर्क होता है और आम तौर पर भविष्यवाणी परिणामों की व्याख्या करने के तरीके के बारे में मेटाडेटा शामिल होता है, जैसे भविष्यवाणी वर्ग के नाम। आमतौर पर, मॉडल फ़ाइलें आपके विकास प्रोजेक्ट की src/main/assets निर्देशिका में संग्रहीत की जाती हैं, जैसा कि कोड उदाहरण में है:
-
<project>/src/main/assets/mobilebert.tflite -
<project>/src/main/assets/wordvec.tflite
सुविधा और कोड पठनीयता के लिए, उदाहरण एक साथी ऑब्जेक्ट घोषित करता है जो मॉडल के लिए सेटिंग्स को परिभाषित करता है।
अपने ऐप में मॉडल आरंभ करने के लिए:
मॉडल के लिए सेटिंग्स परिभाषित करने के लिए एक सहयोगी ऑब्जेक्ट बनाएं। उदाहरण एप्लिकेशन में, यह ऑब्जेक्ट TextClassificationHelper.kt में स्थित है:
companion object { const val DELEGATE_CPU = 0 const val DELEGATE_NNAPI = 1 const val WORD_VEC = "wordvec.tflite" const val MOBILEBERT = "mobilebert.tflite" }एक क्लासिफायर ऑब्जेक्ट बनाकर मॉडल के लिए सेटिंग्स बनाएं, और
BertNLClassifierयाNLClassifierका उपयोग करके एक TensorFlow Lite ऑब्जेक्ट बनाएं।उदाहरण एप्लिकेशन में, यह TextClassificationHelper.kt के भीतर
initClassifierफ़ंक्शन में स्थित है:fun initClassifier() { ... if( currentModel == MOBILEBERT ) { ... bertClassifier = BertNLClassifier.createFromFileAndOptions( context, MOBILEBERT, options) } else if (currentModel == WORD_VEC) { ... nlClassifier = NLClassifier.createFromFileAndOptions( context, WORD_VEC, options) } }
हार्डवेयर त्वरण सक्षम करें (वैकल्पिक)
अपने ऐप में TensorFlow Lite मॉडल को आरंभ करते समय, आपको मॉडल की भविष्यवाणी गणनाओं को तेज़ करने के लिए हार्डवेयर त्वरण सुविधाओं का उपयोग करने पर विचार करना चाहिए। टेन्सरफ्लो लाइट प्रतिनिधि सॉफ्टवेयर मॉड्यूल हैं जो मोबाइल डिवाइस पर विशेष प्रोसेसिंग हार्डवेयर, जैसे ग्राफिक्स प्रोसेसिंग यूनिट (जीपीयू) या टेन्सर प्रोसेसिंग यूनिट (टीपीयू) का उपयोग करके मशीन लर्निंग मॉडल के निष्पादन में तेजी लाते हैं।
अपने ऐप में हार्डवेयर त्वरण सक्षम करने के लिए:
एप्लिकेशन द्वारा उपयोग किए जाने वाले प्रतिनिधि को परिभाषित करने के लिए एक वेरिएबल बनाएं। उदाहरण एप्लिकेशन में, यह वेरिएबल TextClassificationHelper.kt के आरंभ में स्थित है:
var currentDelegate: Int = 0एक प्रतिनिधि चयनकर्ता बनाएँ. उदाहरण एप्लिकेशन में, प्रतिनिधि चयनकर्ता TextClassificationHelper.kt के भीतर
initClassifierफ़ंक्शन में स्थित है:val baseOptionsBuilder = BaseOptions.builder() when (currentDelegate) { DELEGATE_CPU -> { // Default } DELEGATE_NNAPI -> { baseOptionsBuilder.useNnapi() } }
TensorFlow Lite मॉडल चलाने के लिए प्रतिनिधियों का उपयोग करने की अनुशंसा की जाती है, लेकिन इसकी आवश्यकता नहीं है। TensorFlow Lite के साथ डेलीगेट्स का उपयोग करने के बारे में अधिक जानकारी के लिए, TensorFlow Lite डेलीगेट्स देखें।
मॉडल के लिए डेटा तैयार करें
आपके एंड्रॉइड ऐप में, आपका कोड मौजूदा डेटा जैसे कच्चे टेक्स्ट को टेन्सर डेटा प्रारूप में परिवर्तित करके व्याख्या के लिए मॉडल को डेटा प्रदान करता है जिसे आपके मॉडल द्वारा संसाधित किया जा सकता है। टेंसर में जो डेटा आप किसी मॉडल को पास करते हैं, उसमें विशिष्ट आयाम या आकार होना चाहिए, जो मॉडल को प्रशिक्षित करने के लिए उपयोग किए गए डेटा के प्रारूप से मेल खाता हो।
यह टेक्स्ट वर्गीकरण ऐप एक स्ट्रिंग को इनपुट के रूप में स्वीकार करता है, और मॉडल विशेष रूप से अंग्रेजी भाषा कॉर्पस पर प्रशिक्षित होते हैं। अनुमान के दौरान विशेष वर्णों और गैर-अंग्रेजी शब्दों को नजरअंदाज कर दिया जाता है।
मॉडल को टेक्स्ट डेटा प्रदान करने के लिए:
सुनिश्चित करें कि
initClassifierफ़ंक्शन में प्रतिनिधि और मॉडल के लिए कोड शामिल है, जैसा कि एमएल मॉडल प्रारंभ करें और हार्डवेयर त्वरण सक्षम करें अनुभाग में बताया गया है।initClassifierफ़ंक्शन को कॉल करने के लिएinitब्लॉक का उपयोग करें। उदाहरण एप्लिकेशन में,initTextClassificationHelper.kt में स्थित है:init { initClassifier() }
पूर्वानुमान चलाएँ
अपने एंड्रॉइड ऐप में, एक बार जब आप BertNLClassifier या NLClassifier ऑब्जेक्ट को इनिशियलाइज़ कर लेते हैं, तो आप मॉडल को "सकारात्मक" या "नकारात्मक" के रूप में वर्गीकृत करने के लिए इनपुट टेक्स्ट फीड करना शुरू कर सकते हैं।
पूर्वानुमान चलाने के लिए:
एक
classifyफ़ंक्शन बनाएं, जो चयनित क्लासिफायरियर (currentModel) का उपयोग करता है और इनपुट टेक्स्ट (inferenceTime) को वर्गीकृत करने में लगने वाले समय को मापता है। उदाहरण एप्लिकेशन में,classifyफ़ंक्शन TextClassificationHelper.kt में स्थित है:fun classify(text: String) { executor = ScheduledThreadPoolExecutor(1) executor.execute { val results: List<Category> // inferenceTime is the amount of time, in milliseconds, that it takes to // classify the input text. var inferenceTime = SystemClock.uptimeMillis() // Use the appropriate classifier based on the selected model if(currentModel == MOBILEBERT) { results = bertClassifier.classify(text) } else { results = nlClassifier.classify(text) } inferenceTime = SystemClock.uptimeMillis() - inferenceTime listener.onResult(results, inferenceTime) } }परिणामों को
classifyसे श्रोता ऑब्जेक्ट तक पास करें।fun classify(text: String) { ... listener.onResult(results, inferenceTime) }
मॉडल आउटपुट संभालें
आपके द्वारा पाठ की एक पंक्ति इनपुट करने के बाद, मॉडल 'सकारात्मक' और 'नकारात्मक' श्रेणियों के लिए 0 और 1 के बीच एक पूर्वानुमान स्कोर तैयार करता है, जिसे फ़्लोट के रूप में व्यक्त किया जाता है।
मॉडल से पूर्वानुमान परिणाम प्राप्त करने के लिए:
आउटपुट को संभालने के लिए श्रोता ऑब्जेक्ट के लिए एक
onResultफ़ंक्शन बनाएं। उदाहरण एप्लिकेशन में, श्रोता ऑब्जेक्ट MainActivity.kt में स्थित हैprivate val listener = object : TextClassificationHelper.TextResultsListener { override fun onResult(results: List<Category>, inferenceTime: Long) { runOnUiThread { activityMainBinding.bottomSheetLayout.inferenceTimeVal.text = String.format("%d ms", inferenceTime) adapter.resultsList = results.sortedByDescending { it.score } adapter.notifyDataSetChanged() } } ... }त्रुटियों को संभालने के लिए श्रोता ऑब्जेक्ट में
onErrorफ़ंक्शन जोड़ें:private val listener = object : TextClassificationHelper.TextResultsListener { ... override fun onError(error: String) { Toast.makeText(this@MainActivity, error, Toast.LENGTH_SHORT).show() } }
एक बार जब मॉडल भविष्यवाणी परिणामों का एक सेट लौटा देता है, तो आपका एप्लिकेशन आपके उपयोगकर्ता को परिणाम प्रस्तुत करके या अतिरिक्त तर्क निष्पादित करके उन भविष्यवाणियों पर कार्य कर सकता है। उदाहरण एप्लिकेशन उपयोगकर्ता इंटरफ़ेस में पूर्वानुमान स्कोर सूचीबद्ध करता है।
अगले कदम
- TensorFlow Lite मॉडल मेकर ट्यूटोरियल के साथ टेक्स्ट वर्गीकरण के साथ मॉडलों को शुरू से ही प्रशिक्षित और कार्यान्वित करें।
- TensorFlow के लिए और अधिक टेक्स्ट प्रोसेसिंग टूल खोजें।
- TensorFlow हब पर अन्य BERT मॉडल डाउनलोड करें।
- उदाहरणों में TensorFlow Lite के विभिन्न उपयोगों का अन्वेषण करें।
- मॉडल अनुभाग में TensorFlow Lite के साथ मशीन लर्निंग मॉडल का उपयोग करने के बारे में अधिक जानें।
- TensorFlow Lite डेवलपर गाइड में अपने मोबाइल एप्लिकेशन में मशीन लर्निंग लागू करने के बारे में और जानें।