
В этом руководстве показано, как создать приложение Android с помощью TensorFlow Lite для классификации текста на естественном языке. Это приложение предназначено для физического устройства Android, но также может работать на эмуляторе устройства.
В примере приложения используется TensorFlow Lite для классификации текста как положительного или отрицательного, используя библиотеку задач для естественного языка (NL), чтобы обеспечить выполнение моделей машинного обучения классификации текста.
Если вы обновляете существующий проект, вы можете использовать пример приложения в качестве ссылки или шаблона. Инструкции о том, как добавить классификацию текста в существующее приложение, см. в разделе Обновление и изменение вашего приложения .
Обзор классификации текста
Классификация текста — это задача машинного обучения, заключающаяся в присвоении набора предопределенных категорий открытому тексту. Модель классификации текста обучается на корпусе текста на естественном языке, где слова или фразы классифицируются вручную.
Обученная модель получает текст в качестве входных данных и пытается классифицировать текст в соответствии с набором известных классов, для классификации которых она была обучена. Например, модели в этом примере принимают фрагмент текста и определяют, является ли тон текста положительным или отрицательным. Для каждого фрагмента текста модель классификации текста выводит оценку, которая указывает на уверенность в том, что текст правильно классифицирован как положительный или отрицательный.
Для получения дополнительной информации о том, как создаются модели в этом руководстве, обратитесь к руководству «Классификация текста с помощью TensorFlow Lite Model Maker» .
Модели и набор данных
В этом руководстве используются модели, обученные с использованием набора данных SST-2 (Stanford Sentiment Treebank). SST-2 содержит 67 349 обзоров фильмов для обучения и 872 обзоров фильмов для тестирования, каждый из которых классифицируется как положительный или отрицательный. Модели, используемые в этом приложении, были обучены с помощью инструмента TensorFlow Lite Model Maker .
В примере приложения используются следующие предварительно обученные модели:
Вектор среднего слова (
NLClassifier).NLClassifierбиблиотеки задач классифицирует входной текст по различным категориям и может обрабатывать большинство моделей классификации текста.MobileBERT (
BertNLClassifier) —BertNLClassifierбиблиотеки задач аналогичен NLClassifier, но предназначен для случаев, когда требуются токенизации Wordpiece и Sentencepiece вне графа.
Установите и запустите пример приложения
Чтобы настроить приложение классификации текста, загрузите пример приложения с GitHub и запустите его с помощью Android Studio .
Системные Требования
- Android Studio версии 2021.1.1 (Bumblebee) или выше.
- Android SDK версии 31 или выше
- Устройство Android с минимальной версией ОС SDK 21 (Android 7.0 – Nougat) с включенным режимом разработчика или эмулятором Android.
Получить пример кода
Создайте локальную копию кода примера. Вы будете использовать этот код для создания проекта в Android Studio и запуска примера приложения.
Чтобы клонировать и настроить пример кода:
- Клонируйте репозиторий git
git clone https://github.com/tensorflow/examples.git
- При желании настройте свой экземпляр git на использование разреженной проверки, чтобы у вас были только файлы для примера приложения классификации текста:
cd examples git sparse-checkout init --cone git sparse-checkout set lite/examples/text_classification/android
Импортируйте и запустите проект
Создайте проект на основе загруженного примера кода, соберите его и запустите.
Чтобы импортировать и построить проект примера кода:
- Запустите Android-студию .
- В Android Studio выберите «Файл» > «Создать» > «Импортировать проект» .
- Перейдите в каталог примера кода, содержащий файл build.gradle (
.../examples/lite/examples/text_classification/android/build.gradle), и выберите этот каталог. - Если Android Studio запрашивает синхронизацию Gradle, выберите «ОК».
- Убедитесь, что ваше устройство Android подключено к компьютеру и включен режим разработчика. Нажмите зеленую стрелку
Run.
Если вы выберете правильный каталог, Android Studio создаст новый проект и соберет его. Этот процесс может занять несколько минут, в зависимости от скорости вашего компьютера и того, использовали ли вы Android Studio для других проектов. По завершении сборки Android Studio отображает сообщение BUILD SUCCESSFUL на панели состояния вывода сборки .
Чтобы запустить проект:
- В Android Studio запустите проект, выбрав «Выполнить» > «Выполнить…» .
- Выберите подключенное устройство Android (или эмулятор), чтобы протестировать приложение.
Использование приложения
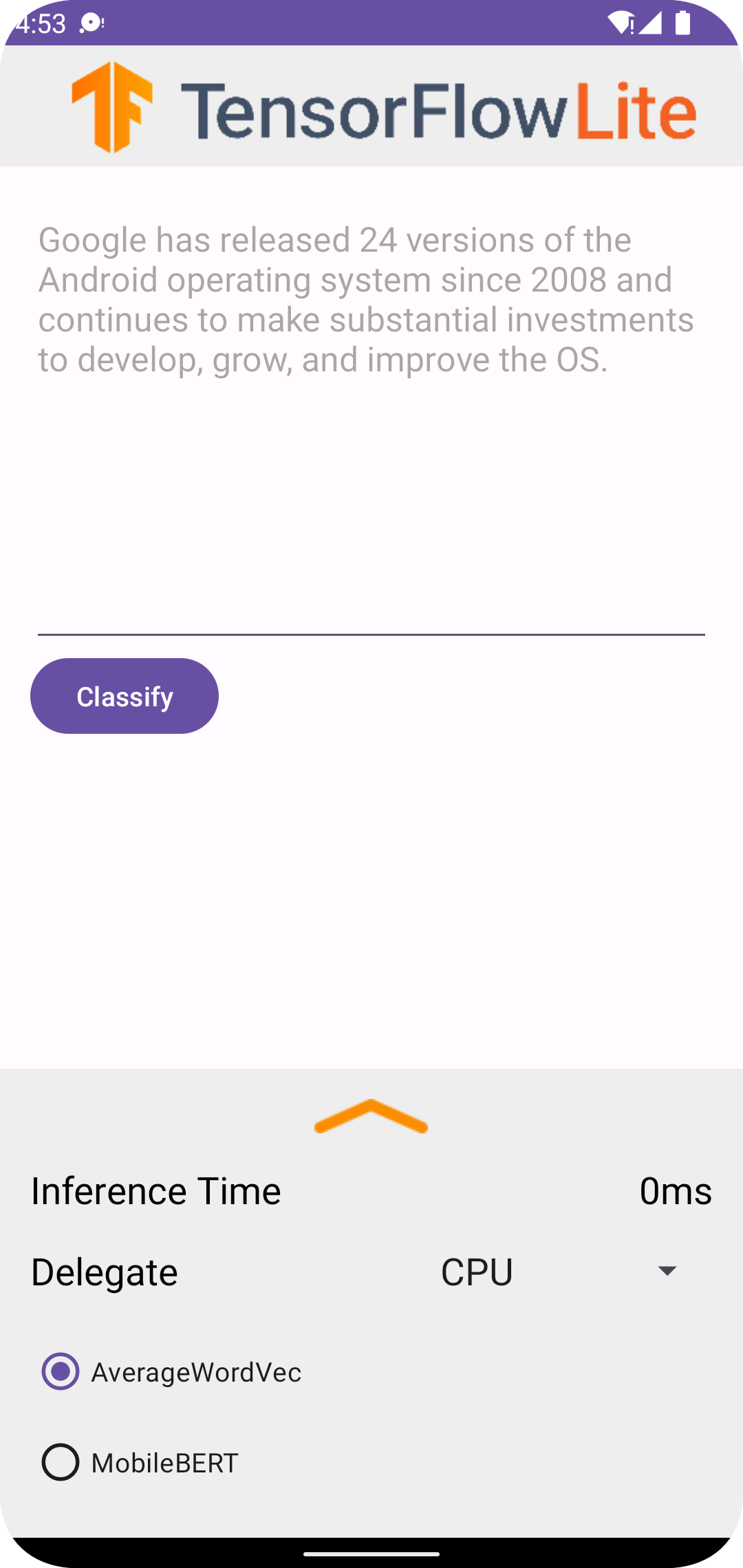
После запуска проекта в Android Studio приложение автоматически откроется на подключенном устройстве или в эмуляторе устройства.
Чтобы использовать классификатор текста:
- Введите фрагмент текста в текстовое поле.
- В раскрывающемся списке «Делегировать» выберите
CPUилиNNAPI. - Укажите модель, выбрав
AverageWordVecилиMobileBERT. - Выберите «Классифицировать» .
Приложение выводит положительную и отрицательную оценку. Сумма этих двух оценок равна 1 и измеряет вероятность того, что тональность входного текста будет положительной или отрицательной. Более высокое число означает более высокий уровень уверенности.
Теперь у вас есть работающее приложение для классификации текста. Используйте следующие разделы, чтобы лучше понять, как работает пример приложения и как реализовать функции классификации текста в ваших рабочих приложениях:
Как работает приложение . Пошаговое описание структуры и ключевых файлов примера приложения.
Измените свое приложение — инструкции по добавлению классификации текста в существующее приложение.
Как работает пример приложения
Приложение использует библиотеку задач для пакета естественного языка (NL) для реализации моделей классификации текста. Две модели, Average Word Vector и MobileBERT, были обучены с помощью TensorFlow Lite Model Maker . По умолчанию приложение работает на ЦП с возможностью аппаратного ускорения с помощью делегата NNAPI.
Следующие файлы и каталоги содержат важный код для этого приложения классификации текста:
- TextClassificationHelper.kt — инициализирует классификатор текста и обрабатывает выбор модели и делегата.
- MainActivity.kt — реализует приложение, включая вызов
TextClassificationHelperResultsAdapter. - ResultAdapter.kt — обрабатывает и форматирует результаты.
Измените свое приложение
В следующих разделах описаны ключевые шаги по изменению вашего собственного приложения Android для запуска модели, показанной в примере приложения. В этих инструкциях в качестве ориентира используется пример приложения. Конкретные изменения, необходимые для вашего собственного приложения, могут отличаться от примера приложения.
Откройте или создайте проект Android
Вам понадобится проект разработки Android в Android Studio, чтобы следовать остальным инструкциям. Следуйте инструкциям ниже, чтобы открыть существующий проект или создать новый.
Чтобы открыть существующий проект разработки Android:
- В Android Studio выберите «Файл» > «Открыть» и выберите существующий проект.
Чтобы создать базовый проект разработки Android:
- Следуйте инструкциям в Android Studio, чтобы создать базовый проект .
Дополнительную информацию об использовании Android Studio см. в документации Android Studio .
Добавить зависимости проекта
В вашем собственном приложении вы должны добавить определенные зависимости проекта для запуска моделей машинного обучения TensorFlow Lite и получить доступ к служебным функциям, которые преобразуют данные, такие как строки, в формат тензорных данных, который может обрабатываться используемой вами моделью.
Следующие инструкции объясняют, как добавить необходимый проект и зависимости модулей в ваш собственный проект приложения Android.
Чтобы добавить зависимости модуля:
В модуле, использующем TensorFlow Lite, обновите файл
build.gradleмодуля, включив в него следующие зависимости.В примере приложения зависимости расположены в app/build.gradle :
dependencies { ... implementation 'org.tensorflow:tensorflow-lite-task-text:0.4.0' }Проект должен включать библиотеку текстовых задач (
tensorflow-lite-task-text).Если вы хотите изменить это приложение для запуска на графическом процессоре (GPU), библиотека GPU (
tensorflow-lite-gpu-delegate-plugin) предоставляет инфраструктуру для запуска приложения на графическом процессоре, а Delegate (tensorflow-lite-gpu) предоставляет список совместимости. Запуск этого приложения на графическом процессоре выходит за рамки данного руководства.В Android Studio синхронизируйте зависимости проекта, выбрав « Файл» > «Синхронизировать проект с файлами Gradle» .
Инициализируйте модели машинного обучения
В своем приложении для Android вы должны инициализировать модель машинного обучения TensorFlow Lite с параметрами, прежде чем выполнять прогнозы с использованием модели.
Модель TensorFlow Lite хранится в виде файла *.tflite . Файл модели содержит логику прогнозирования и обычно включает метаданные о том, как интерпретировать результаты прогнозирования, например имена классов прогнозирования. Обычно файлы модели хранятся в каталоге src/main/assets вашего проекта разработки, как в примере кода:
-
<project>/src/main/assets/mobilebert.tflite -
<project>/src/main/assets/wordvec.tflite
Для удобства и читаемости кода в примере объявляется сопутствующий объект, определяющий параметры модели.
Чтобы инициализировать модель в вашем приложении:
Создайте сопутствующий объект, чтобы определить параметры модели. В примере приложения этот объект находится в TextClassificationHelper.kt :
companion object { const val DELEGATE_CPU = 0 const val DELEGATE_NNAPI = 1 const val WORD_VEC = "wordvec.tflite" const val MOBILEBERT = "mobilebert.tflite" }Создайте настройки модели, создав объект классификатора, и создайте объект TensorFlow Lite, используя либо
BertNLClassifier, либоNLClassifier.В примере приложения это находится в функции
initClassifierв TextClassificationHelper.kt :fun initClassifier() { ... if( currentModel == MOBILEBERT ) { ... bertClassifier = BertNLClassifier.createFromFileAndOptions( context, MOBILEBERT, options) } else if (currentModel == WORD_VEC) { ... nlClassifier = NLClassifier.createFromFileAndOptions( context, WORD_VEC, options) } }
Включить аппаратное ускорение (необязательно)
При инициализации модели TensorFlow Lite в вашем приложении вам следует рассмотреть возможность использования функций аппаратного ускорения, чтобы ускорить прогнозные расчеты модели. Делегаты TensorFlow Lite — это программные модули, которые ускоряют выполнение моделей машинного обучения с использованием специализированного оборудования обработки на мобильном устройстве, такого как графический процессор (GPU) или тензорный процессор (TPU).
Чтобы включить аппаратное ускорение в вашем приложении:
Создайте переменную, чтобы определить делегата, который будет использовать приложение. В примере приложения эта переменная находится в начале TextClassificationHelper.kt :
var currentDelegate: Int = 0Создайте селектор делегата. В примере приложения селектор делегата расположен в функции
initClassifierв TextClassificationHelper.kt :val baseOptionsBuilder = BaseOptions.builder() when (currentDelegate) { DELEGATE_CPU -> { // Default } DELEGATE_NNAPI -> { baseOptionsBuilder.useNnapi() } }
Использование делегатов для запуска моделей TensorFlow Lite рекомендуется, но не обязательно. Дополнительные сведения об использовании делегатов с TensorFlow Lite см. в разделе Делегаты TensorFlow Lite .
Подготовьте данные для модели
В вашем приложении Android ваш код предоставляет данные модели для интерпретации путем преобразования существующих данных, таких как необработанный текст, в формат данных Tensor , который может быть обработан вашей моделью. Данные в тензоре, которые вы передаете в модель, должны иметь определенные размеры или форму, соответствующие формату данных, используемых для обучения модели.
Это приложение для классификации текста принимает в качестве входных данных строку , а модели обучаются исключительно на корпусе английского языка. Специальные символы и неанглийские слова игнорируются во время вывода.
Чтобы предоставить текстовые данные в модель:
Убедитесь, что функция
initClassifierсодержит код делегата и моделей, как описано в разделах «Инициализация моделей ML» и «Включение аппаратного ускорения» .Используйте блок
initдля вызова функцииinitClassifier. В примере приложенияinitнаходится в TextClassificationHelper.kt :init { initClassifier() }
Запуск прогнозов
В вашем приложении Android после инициализации объекта BertNLClassifier или NLClassifier вы можете начать вводить входной текст для модели, чтобы классифицировать ее как «положительную» или «отрицательную».
Чтобы запустить прогнозы:
Создайте функцию
classify, которая использует выбранный классификатор (currentModel) и измеряет время, необходимое для классификации входного текста (inferenceTime). В примере приложения функцияclassifyнаходится в TextClassificationHelper.kt :fun classify(text: String) { executor = ScheduledThreadPoolExecutor(1) executor.execute { val results: List<Category> // inferenceTime is the amount of time, in milliseconds, that it takes to // classify the input text. var inferenceTime = SystemClock.uptimeMillis() // Use the appropriate classifier based on the selected model if(currentModel == MOBILEBERT) { results = bertClassifier.classify(text) } else { results = nlClassifier.classify(text) } inferenceTime = SystemClock.uptimeMillis() - inferenceTime listener.onResult(results, inferenceTime) } }Передайте результаты
classifyобъекту-прослушивателю.fun classify(text: String) { ... listener.onResult(results, inferenceTime) }
Обработка вывода модели
После ввода строки текста модель выдает оценку прогноза, выраженную в виде числа с плавающей запятой, от 0 до 1 для «положительных» и «отрицательных» категорий.
Чтобы получить результаты прогнозирования из модели:
Создайте функцию
onResultдля объекта прослушивателя для обработки вывода. В примере приложения объект прослушивателя расположен в MainActivity.kt.private val listener = object : TextClassificationHelper.TextResultsListener { override fun onResult(results: List<Category>, inferenceTime: Long) { runOnUiThread { activityMainBinding.bottomSheetLayout.inferenceTimeVal.text = String.format("%d ms", inferenceTime) adapter.resultsList = results.sortedByDescending { it.score } adapter.notifyDataSetChanged() } } ... }Добавьте функцию
onErrorк объекту прослушивателя для обработки ошибок:private val listener = object : TextClassificationHelper.TextResultsListener { ... override fun onError(error: String) { Toast.makeText(this@MainActivity, error, Toast.LENGTH_SHORT).show() } }
Как только модель вернет набор результатов прогнозирования, ваше приложение может действовать на основе этих прогнозов, представляя результат вашему пользователю или выполняя дополнительную логику. Пример приложения перечисляет оценки прогнозов в пользовательском интерфейсе.
Следующие шаги
- Обучайте и реализуйте модели с нуля с помощью учебника по классификации текста с помощью TensorFlow Lite Model Maker .
- Узнайте больше об инструментах обработки текста для TensorFlow .
- Загрузите другие модели BERT на TensorFlow Hub .
- Изучите различные варианты использования TensorFlow Lite на примерах .
- Узнайте больше об использовании моделей машинного обучения с TensorFlow Lite в разделе «Модели» .
- Узнайте больше о реализации машинного обучения в вашем мобильном приложении в Руководстве разработчика TensorFlow Lite .