
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | | |
Ringkasan
Ini review film mengklasifikasikan notebook sebagai positif atau negatif menggunakan teks review. Ini adalah contoh dari klasifikasi biner, jenis yang penting dan banyak yang berlaku masalah pembelajaran mesin.
Kami akan mendemonstrasikan penggunaan regularisasi graf di buku catatan ini dengan membuat graf dari input yang diberikan. Resep umum untuk membangun model graph-regularized menggunakan framework Neural Structured Learning (NSL) ketika input tidak mengandung grafik eksplisit adalah sebagai berikut:
- Buat penyematan untuk setiap sampel teks di input. Hal ini dapat dilakukan dengan menggunakan model pra-terlatih seperti word2vec , putar , Bert dll
- Buat grafik berdasarkan embeddings ini dengan menggunakan metrik kesamaan seperti jarak 'L2', jarak 'cosinus', dll. Node dalam grafik sesuai dengan sampel dan tepi dalam grafik sesuai dengan kesamaan antara pasangan sampel.
- Hasilkan data pelatihan dari grafik dan fitur sampel yang disintesis di atas. Data pelatihan yang dihasilkan akan berisi fitur-fitur tetangga di samping fitur-fitur simpul asli.
- Buat jaringan saraf sebagai model dasar menggunakan API sekuensial, fungsional, atau subkelas Keras.
- Bungkus model dasar dengan kelas pembungkus GraphRegularization, yang disediakan oleh kerangka kerja NSL, untuk membuat model Keras grafik baru. Model baru ini akan menyertakan kerugian regularisasi grafik sebagai istilah regularisasi dalam tujuan pelatihannya.
- Melatih dan mengevaluasi model graf Keras.
Persyaratan
- Instal paket Pembelajaran Terstruktur Neural.
- Instal tensorflow-hub.
pip install --quiet neural-structured-learningpip install --quiet tensorflow-hub
Ketergantungan dan impor
import matplotlib.pyplot as plt
import numpy as np
import neural_structured_learning as nsl
import tensorflow as tf
import tensorflow_hub as hub
# Resets notebook state
tf.keras.backend.clear_session()
print("Version: ", tf.__version__)
print("Eager mode: ", tf.executing_eagerly())
print("Hub version: ", hub.__version__)
print(
"GPU is",
"available" if tf.config.list_physical_devices("GPU") else "NOT AVAILABLE")
Version: 2.8.0-rc0 Eager mode: True Hub version: 0.12.0 GPU is NOT AVAILABLE 2022-01-05 12:28:32.113752: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
kumpulan data IMDB
The IMDB dataset berisi teks dari 50.000 ulasan film dari Internet Movie Database . Ini dibagi menjadi 25.000 ulasan untuk pelatihan dan 25.000 ulasan untuk pengujian. Pelatihan dan pengujian set seimbang, yang berarti mengandung jumlah yang sama dari ulasan positif dan negatif.
Dalam tutorial ini, kita akan menggunakan versi praproses dari dataset IMDB.
Unduh kumpulan data IMDB yang telah diproses sebelumnya
Dataset IMDB dikemas dengan TensorFlow. Itu sudah diproses sebelumnya sehingga ulasan (urutan kata) telah dikonversi ke urutan bilangan bulat, di mana setiap bilangan bulat mewakili kata tertentu dalam kamus.
Kode berikut mengunduh dataset IMDB (atau menggunakan salinan cache jika sudah diunduh):
imdb = tf.keras.datasets.imdb
(pp_train_data, pp_train_labels), (pp_test_data, pp_test_labels) = (
imdb.load_data(num_words=10000))
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz 17465344/17464789 [==============================] - 0s 0us/step 17473536/17464789 [==============================] - 0s 0us/step
Argumen num_words=10000 membuat atas 10.000 kata yang paling sering terjadi dalam data pelatihan. Kata-kata langka dibuang untuk menjaga ukuran kosa kata dikelola.
Jelajahi datanya
Mari luangkan waktu sejenak untuk memahami format data. Kumpulan data sudah diproses sebelumnya: setiap contoh adalah larik bilangan bulat yang mewakili kata-kata ulasan film. Setiap label adalah nilai bilangan bulat dari 0 atau 1, di mana 0 adalah ulasan negatif, dan 1 adalah ulasan positif.
print('Training entries: {}, labels: {}'.format(
len(pp_train_data), len(pp_train_labels)))
training_samples_count = len(pp_train_data)
Training entries: 25000, labels: 25000
Teks ulasan telah dikonversi ke bilangan bulat, di mana setiap bilangan bulat mewakili kata tertentu dalam kamus. Begini tampilan ulasan pertama:
print(pp_train_data[0])
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
Ulasan film mungkin berbeda panjangnya. Kode di bawah ini menunjukkan jumlah kata dalam ulasan pertama dan kedua. Karena input ke jaringan saraf harus sama panjangnya, kita harus menyelesaikannya nanti.
len(pp_train_data[0]), len(pp_train_data[1])
(218, 189)
Ubah bilangan bulat kembali menjadi kata-kata
Mungkin berguna untuk mengetahui cara mengonversi bilangan bulat kembali ke teks yang sesuai. Di sini, kita akan membuat fungsi pembantu untuk mengkueri objek kamus yang berisi pemetaan integer ke string:
def build_reverse_word_index():
# A dictionary mapping words to an integer index
word_index = imdb.get_word_index()
# The first indices are reserved
word_index = {k: (v + 3) for k, v in word_index.items()}
word_index['<PAD>'] = 0
word_index['<START>'] = 1
word_index['<UNK>'] = 2 # unknown
word_index['<UNUSED>'] = 3
return dict((value, key) for (key, value) in word_index.items())
reverse_word_index = build_reverse_word_index()
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb_word_index.json 1646592/1641221 [==============================] - 0s 0us/step 1654784/1641221 [==============================] - 0s 0us/step
Sekarang kita dapat menggunakan decode_review fungsi untuk menampilkan teks untuk review pertama:
decode_review(pp_train_data[0])
"<START> this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert <UNK> is an amazing actor and now the same being director <UNK> father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for <UNK> and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also <UNK> to the two little boy's that played the <UNK> of norman and paul they were just brilliant children are often left out of the <UNK> list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all"
Konstruksi grafik
Konstruksi grafik melibatkan pembuatan embeddings untuk sampel teks dan kemudian menggunakan fungsi kesamaan untuk membandingkan embeddings.
Sebelum melangkah lebih jauh, kita buat dulu direktori untuk menyimpan artefak yang dibuat oleh tutorial ini.
mkdir -p /tmp/imdb
Buat penyematan sampel
Kami akan menggunakan pretrained putar embeddings untuk membuat embeddings di tf.train.Example format untuk setiap sampel di input. Kami akan menyimpan embeddings yang dihasilkan dalam TFRecord format yang bersama dengan fitur tambahan yang mewakili ID masing-masing sampel. Ini penting dan akan memungkinkan kami mencocokkan penyematan sampel dengan node yang sesuai dalam grafik nanti.
pretrained_embedding = 'https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1'
hub_layer = hub.KerasLayer(
pretrained_embedding, input_shape=[], dtype=tf.string, trainable=True)
def _int64_feature(value):
"""Returns int64 tf.train.Feature."""
return tf.train.Feature(int64_list=tf.train.Int64List(value=value.tolist()))
def _bytes_feature(value):
"""Returns bytes tf.train.Feature."""
return tf.train.Feature(
bytes_list=tf.train.BytesList(value=[value.encode('utf-8')]))
def _float_feature(value):
"""Returns float tf.train.Feature."""
return tf.train.Feature(float_list=tf.train.FloatList(value=value.tolist()))
def create_embedding_example(word_vector, record_id):
"""Create tf.Example containing the sample's embedding and its ID."""
text = decode_review(word_vector)
# Shape = [batch_size,].
sentence_embedding = hub_layer(tf.reshape(text, shape=[-1,]))
# Flatten the sentence embedding back to 1-D.
sentence_embedding = tf.reshape(sentence_embedding, shape=[-1])
features = {
'id': _bytes_feature(str(record_id)),
'embedding': _float_feature(sentence_embedding.numpy())
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_embeddings(word_vectors, output_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(output_path) as writer:
for word_vector in word_vectors:
example = create_embedding_example(word_vector, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features containing embeddings for training data in
# TFRecord format.
create_embeddings(pp_train_data, '/tmp/imdb/embeddings.tfr', 0)
25000
Buat grafik
Sekarang kita memiliki sampel embeddings, kita akan menggunakannya untuk membangun grafik kesamaan, yaitu, node dalam grafik ini akan sesuai dengan sampel dan tepi dalam grafik ini akan sesuai dengan kesamaan antara pasangan node.
Pembelajaran Terstruktur Neural menyediakan perpustakaan pembuatan grafik untuk membuat grafik berdasarkan penyematan sampel. Menggunakan kesamaan kosinus sebagai ukuran kesamaan untuk membandingkan embeddings dan membangun tepi antara mereka. Hal ini juga memungkinkan kita untuk menentukan ambang kesamaan, yang dapat digunakan untuk membuang tepi yang berbeda dari grafik akhir. Dalam contoh ini, menggunakan 0,99 sebagai ambang kesamaan dan 12345 sebagai benih acak, kita mendapatkan grafik yang memiliki 429.415 tepi dua arah. Di sini kita menggunakan dukungan grafik pembangun untuk wilayah sensitif hashing (LSH) untuk mempercepat pembangunan grafik. Untuk rincian tentang menggunakan dukungan LSH grafik pembangun, lihat build_graph_from_config dokumentasi API.
graph_builder_config = nsl.configs.GraphBuilderConfig(
similarity_threshold=0.99, lsh_splits=32, lsh_rounds=15, random_seed=12345)
nsl.tools.build_graph_from_config(['/tmp/imdb/embeddings.tfr'],
'/tmp/imdb/graph_99.tsv',
graph_builder_config)
Setiap tepi dua arah diwakili oleh dua tepi berarah dalam file TSV keluaran, sehingga file tersebut berisi 429.415 * 2 = 858.830 total baris:
wc -l /tmp/imdb/graph_99.tsv
858830 /tmp/imdb/graph_99.tsv
Fitur sampel
Kami membuat fitur sampel untuk masalah kita menggunakan tf.train.Example Format dan bertahan mereka dalam TFRecord Format. Setiap sampel akan mencakup tiga fitur berikut:
- id: The simpul ID sampel.
- kata: Sebuah daftar int64 berisi ID kata.
- label: Sebuah tunggal int64 mengidentifikasi kelas target review.
def create_example(word_vector, label, record_id):
"""Create tf.Example containing the sample's word vector, label, and ID."""
features = {
'id': _bytes_feature(str(record_id)),
'words': _int64_feature(np.asarray(word_vector)),
'label': _int64_feature(np.asarray([label])),
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_records(word_vectors, labels, record_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(record_path) as writer:
for word_vector, label in zip(word_vectors, labels):
example = create_example(word_vector, label, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features (word vectors and labels) for training and test
# data in TFRecord format.
next_record_id = create_records(pp_train_data, pp_train_labels,
'/tmp/imdb/train_data.tfr', 0)
create_records(pp_test_data, pp_test_labels, '/tmp/imdb/test_data.tfr',
next_record_id)
50000
Menambah data pelatihan dengan tetangga grafik
Karena kami memiliki fitur sampel dan grafik yang disintesis, kami dapat menghasilkan data pelatihan yang diperbesar untuk Pembelajaran Terstruktur Neural. Kerangka kerja NSL menyediakan perpustakaan untuk menggabungkan grafik dan fitur sampel untuk menghasilkan data pelatihan akhir untuk regularisasi grafik. Data pelatihan yang dihasilkan akan mencakup fitur sampel asli serta fitur tetangga yang sesuai.
Dalam tutorial ini, kami mempertimbangkan tepi tidak berarah dan menggunakan maksimal 3 tetangga per sampel untuk menambah data pelatihan dengan tetangga grafik.
nsl.tools.pack_nbrs(
'/tmp/imdb/train_data.tfr',
'',
'/tmp/imdb/graph_99.tsv',
'/tmp/imdb/nsl_train_data.tfr',
add_undirected_edges=True,
max_nbrs=3)
Model dasar
Kami sekarang siap untuk membangun model dasar tanpa regularisasi grafik. Untuk membangun model ini, kita bisa menggunakan embedding yang digunakan dalam membangun grafik, atau kita bisa mempelajari embedding baru bersama-sama dengan tugas klasifikasi. Untuk tujuan notebook ini, kami akan melakukan yang terakhir.
Variabel global
NBR_FEATURE_PREFIX = 'NL_nbr_'
NBR_WEIGHT_SUFFIX = '_weight'
Hyperparameter
Kami akan menggunakan contoh HParams untuk inclue berbagai hyperparameters dan konstanta yang digunakan untuk pelatihan dan evaluasi. Kami jelaskan secara singkat masing-masing di bawah ini:
num_classes: Ada 2 kelas - positif dan negatif.
max_seq_length: ini adalah jumlah maksimum kata dianggap dari setiap review film dalam contoh ini.
vocab_size: ini adalah ukuran kosa kata dipertimbangkan untuk contoh ini.
distance_type: Ini adalah jarak metrik yang digunakan untuk mengatur sampel dengan tetangga-tetangganya.
graph_regularization_multiplier: ini mengontrol berat relatif istilah grafik regularisasi di fungsi kerugian secara keseluruhan.
num_neighbors: Jumlah tetangga digunakan untuk grafik regularisasi. Nilai ini harus kurang dari atau sama dengan
max_nbrsargumen yang digunakan di atas saat menjalankannsl.tools.pack_nbrs.num_fc_units: Jumlah unit di lapisan sepenuhnya terhubung dari jaringan saraf.
train_epochs: Jumlah zaman pelatihan.
Ukuran Batch digunakan untuk pelatihan dan evaluasi: batch_size.
eval_steps: Jumlah batch untuk proses sebelum deeming evaluasi selesai. Jika diatur ke
None, semua contoh dalam tes set dievaluasi.
class HParams(object):
"""Hyperparameters used for training."""
def __init__(self):
### dataset parameters
self.num_classes = 2
self.max_seq_length = 256
self.vocab_size = 10000
### neural graph learning parameters
self.distance_type = nsl.configs.DistanceType.L2
self.graph_regularization_multiplier = 0.1
self.num_neighbors = 2
### model architecture
self.num_embedding_dims = 16
self.num_lstm_dims = 64
self.num_fc_units = 64
### training parameters
self.train_epochs = 10
self.batch_size = 128
### eval parameters
self.eval_steps = None # All instances in the test set are evaluated.
HPARAMS = HParams()
Siapkan datanya
Ulasan—array bilangan bulat—harus dikonversi ke tensor sebelum dimasukkan ke dalam jaringan saraf. Konversi ini dapat dilakukan dengan beberapa cara:
Mengkonversi array ke dalam vektor dari
0s dan1s menunjukkan kata kejadian, mirip dengan pengkodean satu-panas. Sebagai contoh, urutan[3, 5]akan menjadi10000vektor berdimensi yang semua nol kecuali untuk indeks3dan5, yang adalah orang-orang. Kemudian, membuat lapisan pertama dalam jaringan kami-aDenselapisan-yang dapat menangani floating data titik vektor. Pendekatan ini memori intensif, meskipun, membutuhkannum_words * num_reviewsukuran matriks.Atau, kita bisa pad array sehingga mereka semua memiliki panjang yang sama, kemudian membuat tensor integer bentuk
max_length * num_reviews. Kita dapat menggunakan lapisan embedding yang mampu menangani bentuk ini sebagai lapisan pertama dalam jaringan kita.
Dalam tutorial ini, kita akan menggunakan pendekatan kedua.
Karena review film harus sama panjang, kita akan menggunakan pad_sequence fungsi didefinisikan di bawah untuk membakukan panjang.
def make_dataset(file_path, training=False):
"""Creates a `tf.data.TFRecordDataset`.
Args:
file_path: Name of the file in the `.tfrecord` format containing
`tf.train.Example` objects.
training: Boolean indicating if we are in training mode.
Returns:
An instance of `tf.data.TFRecordDataset` containing the `tf.train.Example`
objects.
"""
def pad_sequence(sequence, max_seq_length):
"""Pads the input sequence (a `tf.SparseTensor`) to `max_seq_length`."""
pad_size = tf.maximum([0], max_seq_length - tf.shape(sequence)[0])
padded = tf.concat(
[sequence.values,
tf.fill((pad_size), tf.cast(0, sequence.dtype))],
axis=0)
# The input sequence may be larger than max_seq_length. Truncate down if
# necessary.
return tf.slice(padded, [0], [max_seq_length])
def parse_example(example_proto):
"""Extracts relevant fields from the `example_proto`.
Args:
example_proto: An instance of `tf.train.Example`.
Returns:
A pair whose first value is a dictionary containing relevant features
and whose second value contains the ground truth labels.
"""
# The 'words' feature is a variable length word ID vector.
feature_spec = {
'words': tf.io.VarLenFeature(tf.int64),
'label': tf.io.FixedLenFeature((), tf.int64, default_value=-1),
}
# We also extract corresponding neighbor features in a similar manner to
# the features above during training.
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
nbr_weight_key = '{}{}{}'.format(NBR_FEATURE_PREFIX, i,
NBR_WEIGHT_SUFFIX)
feature_spec[nbr_feature_key] = tf.io.VarLenFeature(tf.int64)
# We assign a default value of 0.0 for the neighbor weight so that
# graph regularization is done on samples based on their exact number
# of neighbors. In other words, non-existent neighbors are discounted.
feature_spec[nbr_weight_key] = tf.io.FixedLenFeature(
[1], tf.float32, default_value=tf.constant([0.0]))
features = tf.io.parse_single_example(example_proto, feature_spec)
# Since the 'words' feature is a variable length word vector, we pad it to a
# constant maximum length based on HPARAMS.max_seq_length
features['words'] = pad_sequence(features['words'], HPARAMS.max_seq_length)
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
features[nbr_feature_key] = pad_sequence(features[nbr_feature_key],
HPARAMS.max_seq_length)
labels = features.pop('label')
return features, labels
dataset = tf.data.TFRecordDataset([file_path])
if training:
dataset = dataset.shuffle(10000)
dataset = dataset.map(parse_example)
dataset = dataset.batch(HPARAMS.batch_size)
return dataset
train_dataset = make_dataset('/tmp/imdb/nsl_train_data.tfr', True)
test_dataset = make_dataset('/tmp/imdb/test_data.tfr')
Bangun modelnya
Jaringan saraf dibuat dengan menumpuk lapisan—ini membutuhkan dua keputusan arsitektur utama:
- Berapa banyak lapisan yang akan digunakan dalam model?
- Berapa banyak unit tersembunyi untuk digunakan untuk setiap lapisan?
Dalam contoh ini, data input terdiri dari larik indeks-kata. Label yang akan diprediksi adalah 0 atau 1.
Kami akan menggunakan LSTM dua arah sebagai model dasar kami dalam tutorial ini.
# This function exists as an alternative to the bi-LSTM model used in this
# notebook.
def make_feed_forward_model():
"""Builds a simple 2 layer feed forward neural network."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size, 16)(inputs)
pooling_layer = tf.keras.layers.GlobalAveragePooling1D()(embedding_layer)
dense_layer = tf.keras.layers.Dense(16, activation='relu')(pooling_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
def make_bilstm_model():
"""Builds a bi-directional LSTM model."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size,
HPARAMS.num_embedding_dims)(
inputs)
lstm_layer = tf.keras.layers.Bidirectional(
tf.keras.layers.LSTM(HPARAMS.num_lstm_dims))(
embedding_layer)
dense_layer = tf.keras.layers.Dense(
HPARAMS.num_fc_units, activation='relu')(
lstm_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
# Feel free to use an architecture of your choice.
model = make_bilstm_model()
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
words (InputLayer) [(None, 256)] 0
embedding (Embedding) (None, 256, 16) 160000
bidirectional (Bidirectiona (None, 128) 41472
l)
dense (Dense) (None, 64) 8256
dense_1 (Dense) (None, 1) 65
=================================================================
Total params: 209,793
Trainable params: 209,793
Non-trainable params: 0
_________________________________________________________________
Lapisan secara efektif ditumpuk secara berurutan untuk membangun pengklasifikasi:
- Lapisan pertama adalah
Inputlapisan yang mengambil kosakata integer-dikodekan. - Lapisan berikutnya adalah
Embeddinglapisan, yang mengambil kosakata integer-dikodekan dan terlihat up vektor embedding untuk setiap kata-indeks. Vektor-vektor ini dipelajari sebagai model kereta. Vektor menambahkan dimensi ke larik keluaran. Dimensi yang dihasilkan adalah:(batch, sequence, embedding). - Selanjutnya, lapisan LSTM dua arah mengembalikan vektor keluaran dengan panjang tetap untuk setiap contoh.
- Vektor output tetap-panjang ini disalurkan melalui sepenuhnya-terhubung (
Dense) layer dengan 64 unit tersembunyi. - Lapisan terakhir terhubung secara padat dengan simpul keluaran tunggal. Menggunakan
sigmoidfungsi aktivasi, nilai ini adalah pelampung antara 0 dan 1, yang mewakili probabilitas, atau tingkat kepercayaan.
Unit tersembunyi
Model di atas memiliki dua menengah atau "tersembunyi" lapisan, antara input dan output, dan tidak termasuk Embedding lapisan. Jumlah output (unit, node, atau neuron) adalah dimensi ruang representasional untuk lapisan. Dengan kata lain, jumlah kebebasan yang diperbolehkan jaringan saat mempelajari representasi internal.
Jika sebuah model memiliki lebih banyak unit tersembunyi (ruang representasi berdimensi lebih tinggi), dan/atau lebih banyak lapisan, maka jaringan dapat mempelajari representasi yang lebih kompleks. Namun, ini membuat jaringan lebih mahal secara komputasi dan dapat menyebabkan mempelajari pola yang tidak diinginkan—pola yang meningkatkan kinerja pada data pelatihan tetapi tidak pada data pengujian. Ini disebut overfitting.
Fungsi kerugian dan pengoptimal
Sebuah model membutuhkan fungsi kerugian dan pengoptimal untuk pelatihan. Karena ini adalah masalah klasifikasi biner dan model output probabilitas (satu unit lapisan dengan aktivasi sigmoid), kita akan menggunakan binary_crossentropy fungsi kerugian.
model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
Buat set validasi
Saat pelatihan, kami ingin memeriksa keakuratan model pada data yang belum pernah dilihat sebelumnya. Membuat validasi set dengan menetapkan terpisah sebagian kecil dari data pelatihan asli. (Mengapa tidak menggunakan set pengujian sekarang? Tujuan kami adalah mengembangkan dan menyempurnakan model kami hanya dengan menggunakan data pelatihan, kemudian menggunakan data uji sekali saja untuk mengevaluasi akurasi kami).
Dalam tutorial ini, kami mengambil sekitar 10% dari sampel pelatihan awal (10% dari 25000) sebagai data berlabel untuk pelatihan dan sisanya sebagai data validasi. Karena pemisahan kereta/pengujian awal adalah 50/50 (masing-masing 25000 sampel), pemisahan kereta/validasi/pengujian efektif yang kita miliki sekarang adalah 5/45/50.
Perhatikan bahwa 'train_dataset' telah di-batch dan diacak.
validation_fraction = 0.9
validation_size = int(validation_fraction *
int(training_samples_count / HPARAMS.batch_size))
print(validation_size)
validation_dataset = train_dataset.take(validation_size)
train_dataset = train_dataset.skip(validation_size)
175
Latih modelnya
Latih model dalam batch mini. Saat pelatihan, pantau kehilangan dan akurasi model pada set validasi:
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
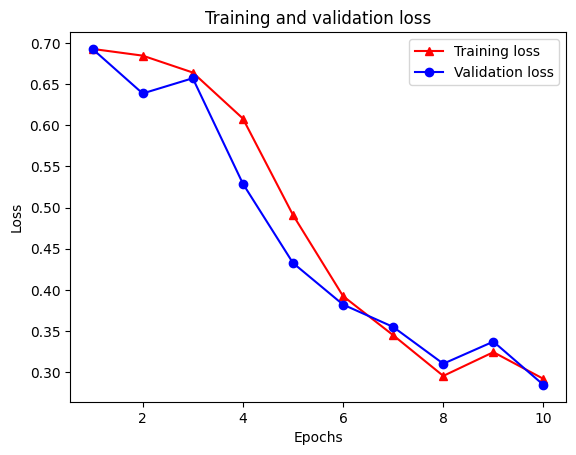
Epoch 1/10 /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/engine/functional.py:559: UserWarning: Input dict contained keys ['NL_nbr_0_words', 'NL_nbr_1_words', 'NL_nbr_0_weight', 'NL_nbr_1_weight'] which did not match any model input. They will be ignored by the model. inputs = self._flatten_to_reference_inputs(inputs) 21/21 [==============================] - 22s 889ms/step - loss: 0.6932 - accuracy: 0.5065 - val_loss: 0.6928 - val_accuracy: 0.5004 Epoch 2/10 21/21 [==============================] - 17s 841ms/step - loss: 0.6918 - accuracy: 0.5000 - val_loss: 0.6843 - val_accuracy: 0.4988 Epoch 3/10 21/21 [==============================] - 17s 839ms/step - loss: 0.6677 - accuracy: 0.5069 - val_loss: 0.5976 - val_accuracy: 0.6507 Epoch 4/10 21/21 [==============================] - 17s 836ms/step - loss: 0.5579 - accuracy: 0.6912 - val_loss: 0.4801 - val_accuracy: 0.7974 Epoch 5/10 21/21 [==============================] - 17s 837ms/step - loss: 0.4377 - accuracy: 0.7965 - val_loss: 0.3678 - val_accuracy: 0.8372 Epoch 6/10 21/21 [==============================] - 17s 836ms/step - loss: 0.3526 - accuracy: 0.8408 - val_loss: 0.4261 - val_accuracy: 0.8283 Epoch 7/10 21/21 [==============================] - 17s 835ms/step - loss: 0.4090 - accuracy: 0.8273 - val_loss: 0.3961 - val_accuracy: 0.8346 Epoch 8/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3105 - accuracy: 0.8842 - val_loss: 0.2976 - val_accuracy: 0.8813 Epoch 9/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3335 - accuracy: 0.8673 - val_loss: 0.3373 - val_accuracy: 0.8537 Epoch 10/10 21/21 [==============================] - 17s 837ms/step - loss: 0.3104 - accuracy: 0.8765 - val_loss: 0.2804 - val_accuracy: 0.8902
Evaluasi modelnya
Sekarang, mari kita lihat bagaimana kinerja model tersebut. Dua nilai akan dikembalikan. Loss (angka yang mewakili kesalahan kami, nilai yang lebih rendah lebih baik), dan akurasi.
results = model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(results)
196/196 [==============================] - 16s 76ms/step - loss: 0.3695 - accuracy: 0.8389 [0.3694916367530823, 0.838919997215271]
Buat grafik akurasi/kerugian dari waktu ke waktu
model.fit() mengembalikan History obyek yang berisi kamus dengan segala sesuatu yang terjadi selama pelatihan:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
Ada empat entri: satu untuk setiap metrik yang dipantau selama pelatihan dan validasi. Kita dapat menggunakan ini untuk memplot kerugian pelatihan dan validasi untuk perbandingan, serta akurasi pelatihan dan validasi:
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
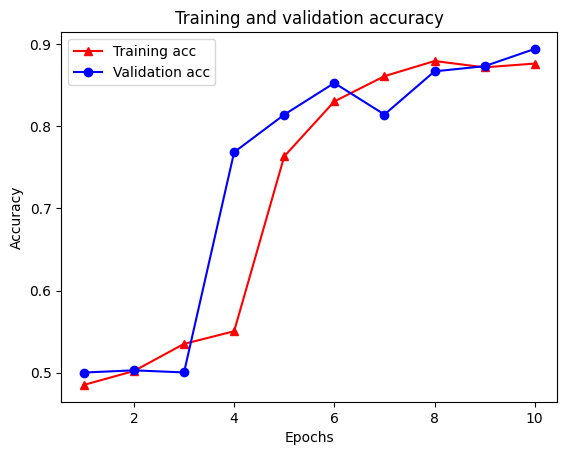
Perhatikan hilangnya pelatihan menurun dengan setiap zaman dan akurasi pelatihan meningkat dengan setiap zaman. Ini diharapkan saat menggunakan optimasi penurunan gradien—ini harus meminimalkan kuantitas yang diinginkan pada setiap iterasi.
Regularisasi grafik
Kami sekarang siap untuk mencoba regularisasi graf menggunakan model dasar yang kami bangun di atas. Kami akan menggunakan GraphRegularization kelas wrapper disediakan oleh kerangka Belajar Neural Terstruktur untuk membungkus dasar (bi-LSTM) Model untuk memasukkan grafik regularisasi. Langkah-langkah selanjutnya untuk melatih dan mengevaluasi model grafik-reguler serupa dengan model dasar.
Buat model yang diregulasi grafik
Untuk menilai manfaat tambahan dari regularisasi grafik, kami akan membuat contoh model dasar baru. Hal ini karena model telah dilatih selama beberapa iterasi, dan menggunakan kembali model yang dilatih ini untuk membuat model grafik-regularized tidak akan menjadi perbandingan yang adil untuk model .
# Build a new base LSTM model.
base_reg_model = make_bilstm_model()
# Wrap the base model with graph regularization.
graph_reg_config = nsl.configs.make_graph_reg_config(
max_neighbors=HPARAMS.num_neighbors,
multiplier=HPARAMS.graph_regularization_multiplier,
distance_type=HPARAMS.distance_type,
sum_over_axis=-1)
graph_reg_model = nsl.keras.GraphRegularization(base_reg_model,
graph_reg_config)
graph_reg_model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
Latih modelnya
graph_reg_history = graph_reg_model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
Epoch 1/10
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:446: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape_1:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape:0", shape=(None, 1), dtype=float32), dense_shape=Tensor("gradient_tape/GraphRegularization/graph_loss/Cast:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
21/21 [==============================] - 28s 1s/step - loss: 0.6928 - accuracy: 0.5131 - scaled_graph_loss: 4.3840e-05 - val_loss: 0.6923 - val_accuracy: 0.4997
Epoch 2/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6852 - accuracy: 0.5158 - scaled_graph_loss: 0.0021 - val_loss: 0.6818 - val_accuracy: 0.4996
Epoch 3/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6698 - accuracy: 0.5123 - scaled_graph_loss: 0.0021 - val_loss: 0.6534 - val_accuracy: 0.5001
Epoch 4/10
21/21 [==============================] - 20s 959ms/step - loss: 0.6194 - accuracy: 0.6285 - scaled_graph_loss: 0.0284 - val_loss: 0.5297 - val_accuracy: 0.7955
Epoch 5/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5805 - accuracy: 0.7346 - scaled_graph_loss: 0.0545 - val_loss: 0.5601 - val_accuracy: 0.6349
Epoch 6/10
21/21 [==============================] - 19s 934ms/step - loss: 0.5509 - accuracy: 0.7662 - scaled_graph_loss: 0.0654 - val_loss: 0.4899 - val_accuracy: 0.7538
Epoch 7/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5326 - accuracy: 0.7877 - scaled_graph_loss: 0.0701 - val_loss: 0.4395 - val_accuracy: 0.7923
Epoch 8/10
21/21 [==============================] - 20s 940ms/step - loss: 0.5157 - accuracy: 0.8258 - scaled_graph_loss: 0.0811 - val_loss: 0.4585 - val_accuracy: 0.7909
Epoch 9/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5063 - accuracy: 0.8388 - scaled_graph_loss: 0.0868 - val_loss: 0.4272 - val_accuracy: 0.8433
Epoch 10/10
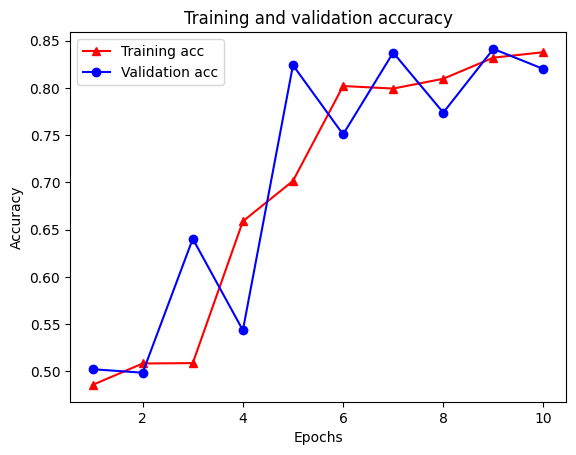
21/21 [==============================] - 19s 934ms/step - loss: 0.5053 - accuracy: 0.8438 - scaled_graph_loss: 0.0858 - val_loss: 0.4485 - val_accuracy: 0.7680
Evaluasi modelnya
graph_reg_results = graph_reg_model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(graph_reg_results)
196/196 [==============================] - 16s 76ms/step - loss: 0.4890 - accuracy: 0.7246 [0.4889770448207855, 0.7246000170707703]
Buat grafik akurasi/kerugian dari waktu ke waktu
graph_reg_history_dict = graph_reg_history.history
graph_reg_history_dict.keys()
dict_keys(['loss', 'accuracy', 'scaled_graph_loss', 'val_loss', 'val_accuracy'])
Ada lima entri total dalam kamus: kehilangan pelatihan, akurasi pelatihan, kehilangan grafik pelatihan, kehilangan validasi, dan akurasi validasi. Kita bisa memplot mereka semua bersama-sama untuk perbandingan. Perhatikan bahwa kerugian grafik hanya dihitung selama pelatihan.
acc = graph_reg_history_dict['accuracy']
val_acc = graph_reg_history_dict['val_accuracy']
loss = graph_reg_history_dict['loss']
graph_loss = graph_reg_history_dict['scaled_graph_loss']
val_loss = graph_reg_history_dict['val_loss']
epochs = range(1, len(acc) + 1)
plt.clf() # clear figure
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-gD" is for solid green line with diamond markers.
plt.plot(epochs, graph_loss, '-gD', label='Training graph loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()

plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
Kekuatan pembelajaran semi-diawasi
Pembelajaran semi-diawasi dan lebih khusus lagi, regularisasi grafik dalam konteks tutorial ini, bisa sangat berguna ketika jumlah data pelatihan kecil. Kurangnya data pelatihan dikompensasikan dengan memanfaatkan kesamaan di antara sampel pelatihan, yang tidak mungkin dilakukan dalam pembelajaran terawasi tradisional.
Kami mendefinisikan rasio pengawasan sebagai rasio melatih sampel dengan jumlah total sampel yang meliputi pelatihan, validasi, dan sampel uji. Dalam buku catatan ini, kami telah menggunakan rasio pengawasan 0,05 (yaitu, 5% dari data berlabel) untuk melatih baik model dasar maupun model yang diregulasi grafik. Kami mengilustrasikan dampak rasio pengawasan pada akurasi model dalam sel di bawah ini.
# Accuracy values for both the Bi-LSTM model and the feed forward NN model have
# been precomputed for the following supervision ratios.
supervision_ratios = [0.3, 0.15, 0.05, 0.03, 0.02, 0.01, 0.005]
model_tags = ['Bi-LSTM model', 'Feed Forward NN model']
base_model_accs = [[84, 84, 83, 80, 65, 52, 50], [87, 86, 76, 74, 67, 52, 51]]
graph_reg_model_accs = [[84, 84, 83, 83, 65, 63, 50],
[87, 86, 80, 75, 67, 52, 50]]
plt.clf() # clear figure
fig, axes = plt.subplots(1, 2)
fig.set_size_inches((12, 5))
for ax, model_tag, base_model_acc, graph_reg_model_acc in zip(
axes, model_tags, base_model_accs, graph_reg_model_accs):
# "-r^" is for solid red line with triangle markers.
ax.plot(base_model_acc, '-r^', label='Base model')
# "-gD" is for solid green line with diamond markers.
ax.plot(graph_reg_model_acc, '-gD', label='Graph-regularized model')
ax.set_title(model_tag)
ax.set_xlabel('Supervision ratio')
ax.set_ylabel('Accuracy(%)')
ax.set_ylim((25, 100))
ax.set_xticks(range(len(supervision_ratios)))
ax.set_xticklabels(supervision_ratios)
ax.legend(loc='best')
plt.show()
<Figure size 432x288 with 0 Axes>
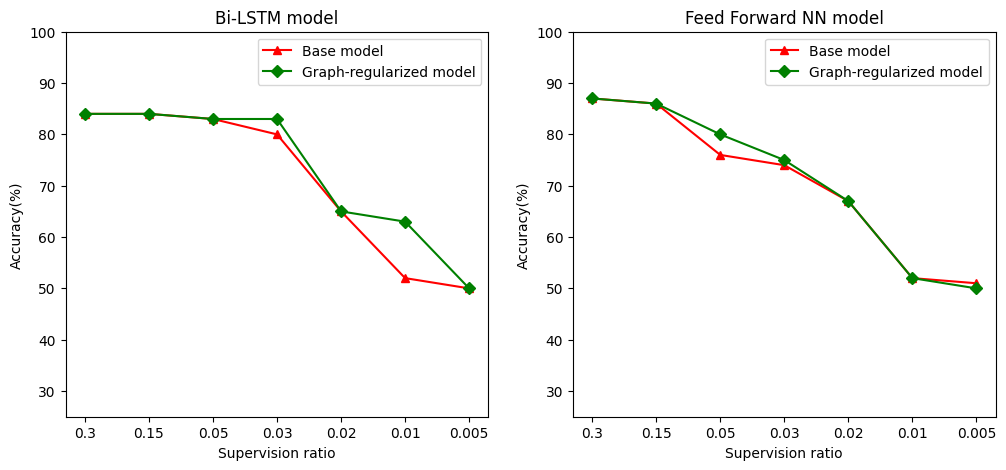
Dapat diamati bahwa ketika rasio pengawasan menurun, akurasi model juga menurun. Hal ini berlaku baik untuk model dasar maupun untuk model yang diregulasi graf, terlepas dari arsitektur model yang digunakan. Namun, perhatikan bahwa model yang diregulasi grafik berkinerja lebih baik daripada model dasar untuk kedua arsitektur. Secara khusus, untuk model Bi-LSTM, ketika rasio pengawasan adalah 0,01, akurasi model grafik-regularized adalah ~ 20% lebih tinggi dari model dasar. Ini terutama karena pembelajaran semi-diawasi untuk model yang diregulasi grafik, di mana kesamaan struktural di antara sampel pelatihan digunakan selain sampel pelatihan itu sendiri.
Kesimpulan
Kami telah mendemonstrasikan penggunaan regularisasi grafik menggunakan kerangka kerja Neural Structured Learning (NSL) bahkan ketika input tidak berisi grafik eksplisit. Kami mempertimbangkan tugas klasifikasi sentimen ulasan film IMDB yang kami sintesiskan grafik kesamaan berdasarkan penyematan ulasan. Kami mendorong pengguna untuk bereksperimen lebih lanjut dengan memvariasikan hyperparameter, jumlah pengawasan, dan dengan menggunakan arsitektur model yang berbeda.