
Pembelajaran Terstruktur Neural (NSL) berfokus pada pelatihan jaringan saraf dalam dengan memanfaatkan sinyal terstruktur (jika tersedia) bersama dengan masukan fitur. Seperti yang diperkenalkan oleh Bui dkk. (WSDM'18) , sinyal terstruktur ini digunakan untuk mengatur pelatihan jaringan saraf, memaksa model mempelajari prediksi yang akurat (dengan meminimalkan kerugian yang diawasi), sekaligus menjaga kesamaan struktural masukan (dengan meminimalkan kerugian tetangga). , lihat gambar di bawah). Teknik ini bersifat umum dan dapat diterapkan pada arsitektur saraf arbitrer (seperti NN Feed-forward, NN Konvolusional, dan NN Berulang).
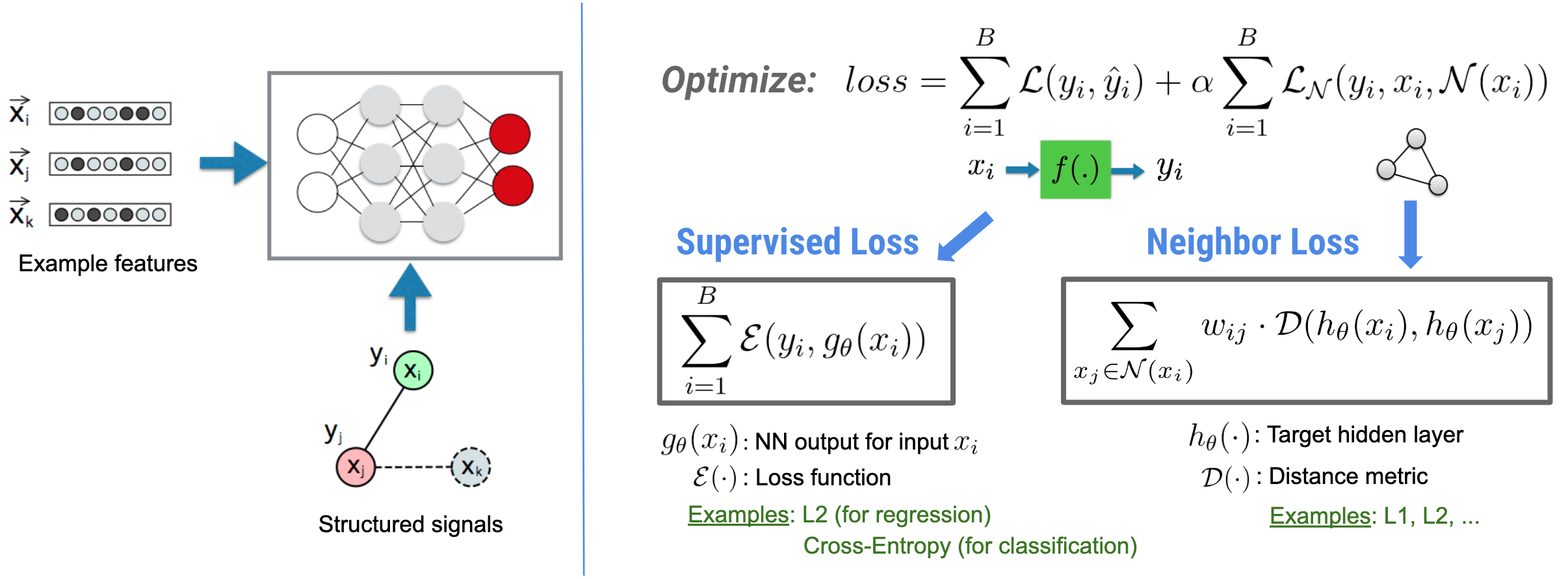
Perhatikan bahwa persamaan kerugian tetangga yang digeneralisasi bersifat fleksibel dan dapat memiliki bentuk lain selain yang diilustrasikan di atas. Misalnya kita juga bisa memilih\(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) menjadi kerugian tetangga, yang menghitung jarak antara kebenaran dasar \(y_i\)dan prediksi dari tetangga \(g_\theta(x_j)\). Ini biasanya digunakan dalam pembelajaran permusuhan (Goodfellow et al., ICLR'15) . Oleh karena itu, NSL menggeneralisasi ke Neural Graph Learning jika tetangga secara eksplisit diwakili oleh grafik, dan ke Adversarial Learning jika tetangga secara implisit disebabkan oleh gangguan permusuhan.
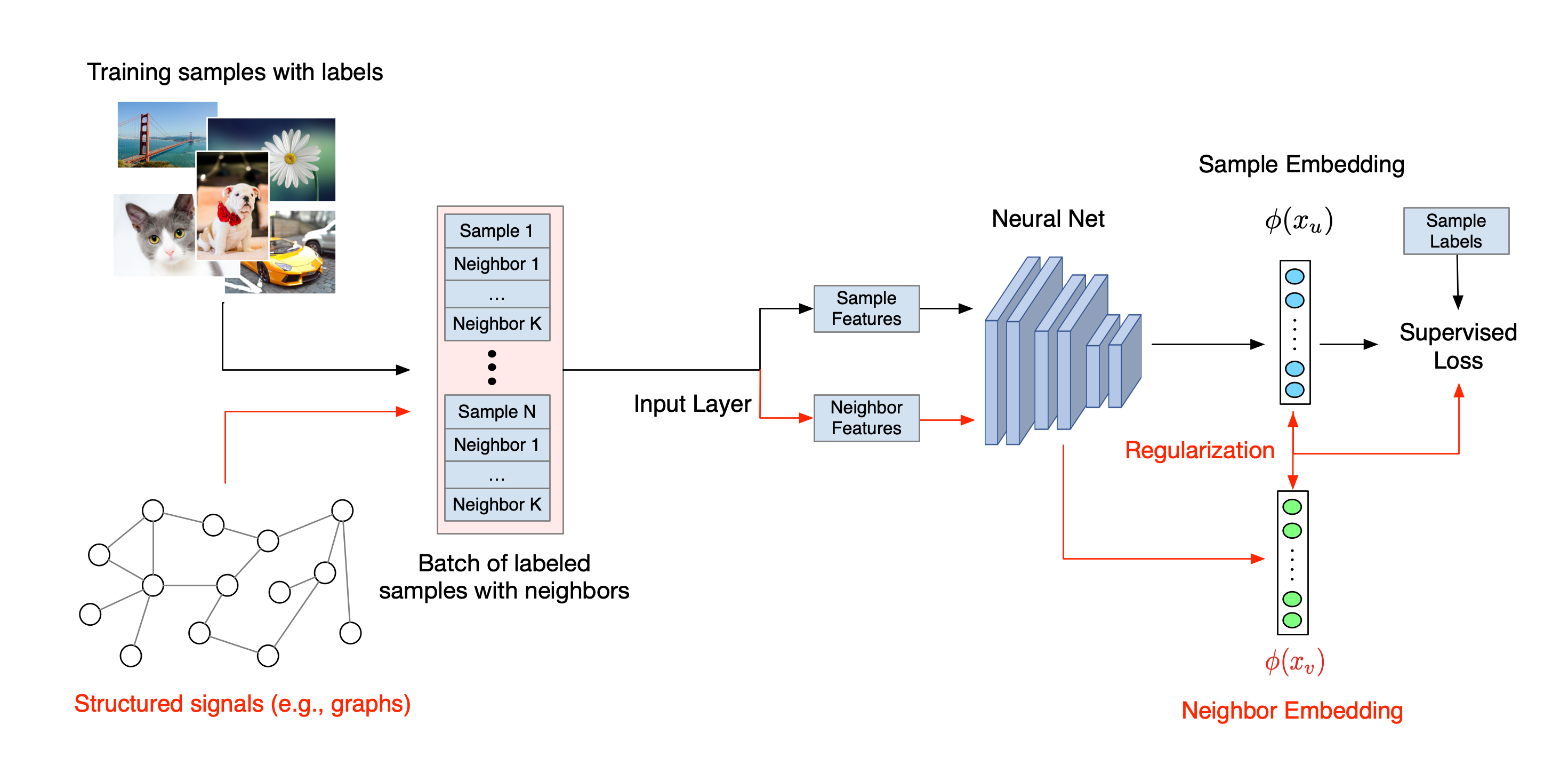
Alur kerja keseluruhan untuk Neural Structured Learning diilustrasikan di bawah ini. Panah hitam mewakili alur kerja pelatihan konvensional dan panah merah mewakili alur kerja baru yang diperkenalkan oleh NSL untuk memanfaatkan sinyal terstruktur. Pertama, sampel pelatihan diperluas untuk menyertakan sinyal terstruktur. Ketika sinyal-sinyal terstruktur tidak diberikan secara eksplisit, maka sinyal-sinyal tersebut dapat dikonstruksi atau diinduksi (yang terakhir ini berlaku untuk pembelajaran adversarial). Selanjutnya, sampel pelatihan yang ditambah (termasuk sampel asli dan sampel tetangganya yang terkait) dimasukkan ke jaringan saraf untuk menghitung penyematannya. Jarak antara penyematan sampel dan penyematan tetangganya dihitung dan digunakan sebagai kerugian tetangga, yang diperlakukan sebagai istilah regularisasi dan ditambahkan ke kerugian akhir. Untuk regularisasi berbasis tetangga secara eksplisit, kami biasanya menghitung kerugian tetangga sebagai jarak antara penyematan sampel dan penyematan tetangga. Namun, setiap lapisan jaringan saraf dapat digunakan untuk menghitung kerugian tetangga. Di sisi lain, untuk regularisasi berbasis tetangga yang diinduksi (adversarial), kami menghitung kerugian tetangga sebagai jarak antara prediksi keluaran dari tetangga permusuhan yang diinduksi dan label kebenaran dasar.
Mengapa menggunakan NSL?
NSL memberikan keuntungan sebagai berikut:
- Akurasi lebih tinggi : sinyal terstruktur di antara sampel dapat memberikan informasi yang tidak selalu tersedia dalam input fitur; oleh karena itu, pendekatan pelatihan bersama (dengan sinyal dan fitur terstruktur) telah terbukti mengungguli banyak metode yang ada (yang hanya mengandalkan pelatihan dengan fitur) pada berbagai tugas, seperti klasifikasi dokumen dan klasifikasi maksud semantik ( Bui dkk. ., WSDM'18 & Kipf dkk., ICLR'17 ).
- Kekokohan : model yang dilatih dengan contoh-contoh permusuhan telah terbukti kuat terhadap gangguan permusuhan yang dirancang untuk menyesatkan prediksi atau klasifikasi model ( Goodfellow dkk., ICLR'15 & Miyato dkk., ICLR'16 ). Jika jumlah sampel pelatihan sedikit, pelatihan dengan contoh adversarial juga membantu meningkatkan akurasi model ( Tsipras et al., ICLR'19 ).
- Diperlukan lebih sedikit data berlabel : NSL memungkinkan jaringan saraf memanfaatkan data berlabel dan tidak berlabel, yang memperluas paradigma pembelajaran ke pembelajaran semi-supervisi . Secara khusus, NSL memungkinkan jaringan untuk berlatih menggunakan data berlabel seperti dalam pengaturan yang diawasi, dan pada saat yang sama mendorong jaringan untuk mempelajari representasi tersembunyi serupa untuk "sampel tetangga" yang mungkin memiliki label atau tidak. Teknik ini menunjukkan harapan besar untuk meningkatkan akurasi model ketika jumlah data berlabel relatif kecil ( Bui et al., WSDM'18 & Miyato et al., ICLR'16 ).
Tutorial Langkah demi Langkah
Untuk mendapatkan pengalaman langsung dengan Neural Structured Learning, kami memiliki tutorial yang mencakup berbagai skenario di mana sinyal terstruktur dapat diberikan, dikonstruksi, atau diinduksi secara eksplisit. Berikut beberapa di antaranya:
Regularisasi grafik untuk klasifikasi dokumen menggunakan grafik natural . Dalam tutorial ini, kita mengeksplorasi penggunaan regularisasi grafik untuk mengklasifikasikan dokumen yang membentuk grafik natural (organik).
Regularisasi grafik untuk klasifikasi sentimen menggunakan grafik yang disintesis . Dalam tutorial ini, kami mendemonstrasikan penggunaan regularisasi grafik untuk mengklasifikasikan sentimen ulasan film dengan membangun (mensintesis) sinyal terstruktur.
Pembelajaran permusuhan untuk klasifikasi gambar . Dalam tutorial ini, kita mengeksplorasi penggunaan pembelajaran adversarial (di mana sinyal terstruktur diinduksi) untuk mengklasifikasikan gambar yang berisi digit numerik.
Contoh dan tutorial lainnya dapat ditemukan di direktori contoh repositori GitHub kami.
,Pembelajaran Terstruktur Neural (NSL) berfokus pada pelatihan jaringan saraf dalam dengan memanfaatkan sinyal terstruktur (jika tersedia) bersama dengan masukan fitur. Seperti yang diperkenalkan oleh Bui dkk. (WSDM'18) , sinyal terstruktur ini digunakan untuk mengatur pelatihan jaringan saraf, memaksa model mempelajari prediksi yang akurat (dengan meminimalkan kerugian yang diawasi), sekaligus menjaga kesamaan struktural masukan (dengan meminimalkan kerugian tetangga). , lihat gambar di bawah). Teknik ini bersifat umum dan dapat diterapkan pada arsitektur saraf arbitrer (seperti NN Feed-forward, NN Konvolusional, dan NN Berulang).
Perhatikan bahwa persamaan kerugian tetangga yang digeneralisasi bersifat fleksibel dan dapat memiliki bentuk lain selain yang diilustrasikan di atas. Misalnya kita juga bisa memilih\(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) menjadi kerugian tetangga, yang menghitung jarak antara kebenaran dasar \(y_i\)dan prediksi dari tetangga \(g_\theta(x_j)\). Ini biasanya digunakan dalam pembelajaran permusuhan (Goodfellow et al., ICLR'15) . Oleh karena itu, NSL menggeneralisasi ke Neural Graph Learning jika tetangga secara eksplisit diwakili oleh grafik, dan ke Adversarial Learning jika tetangga secara implisit disebabkan oleh gangguan permusuhan.
Alur kerja keseluruhan untuk Neural Structured Learning diilustrasikan di bawah ini. Panah hitam mewakili alur kerja pelatihan konvensional dan panah merah mewakili alur kerja baru yang diperkenalkan oleh NSL untuk memanfaatkan sinyal terstruktur. Pertama, sampel pelatihan diperluas untuk menyertakan sinyal terstruktur. Ketika sinyal-sinyal terstruktur tidak diberikan secara eksplisit, maka sinyal-sinyal tersebut dapat dikonstruksi atau diinduksi (yang terakhir ini berlaku untuk pembelajaran adversarial). Selanjutnya, sampel pelatihan yang ditambah (termasuk sampel asli dan sampel tetangganya yang terkait) dimasukkan ke jaringan saraf untuk menghitung penyematannya. Jarak antara penyematan sampel dan penyematan tetangganya dihitung dan digunakan sebagai kerugian tetangga, yang diperlakukan sebagai istilah regularisasi dan ditambahkan ke kerugian akhir. Untuk regularisasi berbasis tetangga secara eksplisit, kami biasanya menghitung kerugian tetangga sebagai jarak antara penyematan sampel dan penyematan tetangga. Namun, setiap lapisan jaringan saraf dapat digunakan untuk menghitung kerugian tetangga. Di sisi lain, untuk regularisasi berbasis tetangga yang diinduksi (adversarial), kami menghitung kerugian tetangga sebagai jarak antara prediksi keluaran dari tetangga permusuhan yang diinduksi dan label kebenaran dasar.
Mengapa menggunakan NSL?
NSL memberikan keuntungan sebagai berikut:
- Akurasi lebih tinggi : sinyal terstruktur di antara sampel dapat memberikan informasi yang tidak selalu tersedia dalam input fitur; oleh karena itu, pendekatan pelatihan bersama (dengan sinyal dan fitur terstruktur) telah terbukti mengungguli banyak metode yang ada (yang hanya mengandalkan pelatihan dengan fitur) pada berbagai tugas, seperti klasifikasi dokumen dan klasifikasi maksud semantik ( Bui dkk. ., WSDM'18 & Kipf dkk., ICLR'17 ).
- Kekokohan : model yang dilatih dengan contoh-contoh permusuhan telah terbukti kuat terhadap gangguan permusuhan yang dirancang untuk menyesatkan prediksi atau klasifikasi model ( Goodfellow dkk., ICLR'15 & Miyato dkk., ICLR'16 ). Jika jumlah sampel pelatihan sedikit, pelatihan dengan contoh adversarial juga membantu meningkatkan akurasi model ( Tsipras et al., ICLR'19 ).
- Diperlukan lebih sedikit data berlabel : NSL memungkinkan jaringan saraf memanfaatkan data berlabel dan tidak berlabel, yang memperluas paradigma pembelajaran ke pembelajaran semi-supervisi . Secara khusus, NSL memungkinkan jaringan untuk berlatih menggunakan data berlabel seperti dalam pengaturan yang diawasi, dan pada saat yang sama mendorong jaringan untuk mempelajari representasi tersembunyi serupa untuk "sampel tetangga" yang mungkin memiliki label atau tidak. Teknik ini menunjukkan harapan besar untuk meningkatkan akurasi model ketika jumlah data berlabel relatif kecil ( Bui et al., WSDM'18 & Miyato et al., ICLR'16 ).
Tutorial Langkah demi Langkah
Untuk mendapatkan pengalaman langsung dengan Neural Structured Learning, kami memiliki tutorial yang mencakup berbagai skenario di mana sinyal terstruktur dapat diberikan, dikonstruksi, atau diinduksi secara eksplisit. Berikut beberapa di antaranya:
Regularisasi grafik untuk klasifikasi dokumen menggunakan grafik natural . Dalam tutorial ini, kita mengeksplorasi penggunaan regularisasi grafik untuk mengklasifikasikan dokumen yang membentuk grafik natural (organik).
Regularisasi grafik untuk klasifikasi sentimen menggunakan grafik yang disintesis . Dalam tutorial ini, kami mendemonstrasikan penggunaan regularisasi grafik untuk mengklasifikasikan sentimen ulasan film dengan membangun (mensintesis) sinyal terstruktur.
Pembelajaran permusuhan untuk klasifikasi gambar . Dalam tutorial ini, kita mengeksplorasi penggunaan pembelajaran adversarial (di mana sinyal terstruktur diinduksi) untuk mengklasifikasikan gambar yang berisi digit numerik.
Contoh dan tutorial lainnya dapat ditemukan di direktori contoh repositori GitHub kami.
,Pembelajaran Terstruktur Neural (NSL) berfokus pada pelatihan jaringan saraf dalam dengan memanfaatkan sinyal terstruktur (jika tersedia) bersama dengan masukan fitur. Seperti yang diperkenalkan oleh Bui dkk. (WSDM'18) , sinyal terstruktur ini digunakan untuk mengatur pelatihan jaringan saraf, memaksa model mempelajari prediksi yang akurat (dengan meminimalkan kerugian yang diawasi), sekaligus menjaga kesamaan struktural masukan (dengan meminimalkan kerugian tetangga). , lihat gambar di bawah). Teknik ini bersifat umum dan dapat diterapkan pada arsitektur saraf arbitrer (seperti NN Feed-forward, NN Konvolusional, dan NN Berulang).
Perhatikan bahwa persamaan kerugian tetangga yang digeneralisasi bersifat fleksibel dan dapat memiliki bentuk lain selain yang diilustrasikan di atas. Misalnya kita juga bisa memilih\(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) menjadi kerugian tetangga, yang menghitung jarak antara kebenaran dasar \(y_i\)dan prediksi dari tetangga \(g_\theta(x_j)\). Ini biasanya digunakan dalam pembelajaran permusuhan (Goodfellow et al., ICLR'15) . Oleh karena itu, NSL menggeneralisasi ke Pembelajaran Grafik Neural jika tetangga secara eksplisit diwakili oleh grafik, dan ke Pembelajaran Adversarial jika tetangga secara implisit disebabkan oleh gangguan permusuhan.
Alur kerja keseluruhan untuk Neural Structured Learning diilustrasikan di bawah ini. Panah hitam mewakili alur kerja pelatihan konvensional dan panah merah mewakili alur kerja baru yang diperkenalkan oleh NSL untuk memanfaatkan sinyal terstruktur. Pertama, sampel pelatihan diperluas untuk menyertakan sinyal terstruktur. Ketika sinyal terstruktur tidak diberikan secara eksplisit, sinyal tersebut dapat dikonstruksi atau diinduksi (yang terakhir ini berlaku untuk pembelajaran adversarial). Selanjutnya, sampel pelatihan yang ditambah (termasuk sampel asli dan sampel tetangganya yang terkait) dimasukkan ke jaringan saraf untuk menghitung penyematannya. Jarak antara penyematan sampel dan penyematan tetangganya dihitung dan digunakan sebagai kerugian tetangga, yang diperlakukan sebagai istilah regularisasi dan ditambahkan ke kerugian akhir. Untuk regularisasi berbasis tetangga secara eksplisit, kami biasanya menghitung kerugian tetangga sebagai jarak antara penyematan sampel dan penyematan tetangga. Namun, setiap lapisan jaringan saraf dapat digunakan untuk menghitung kerugian tetangga. Di sisi lain, untuk regularisasi berbasis tetangga yang diinduksi (adversarial), kami menghitung kerugian tetangga sebagai jarak antara prediksi keluaran dari tetangga permusuhan yang diinduksi dan label kebenaran dasar.
Mengapa menggunakan NSL?
NSL memberikan keuntungan sebagai berikut:
- Akurasi lebih tinggi : sinyal terstruktur di antara sampel dapat memberikan informasi yang tidak selalu tersedia dalam input fitur; oleh karena itu, pendekatan pelatihan bersama (dengan sinyal dan fitur terstruktur) telah terbukti mengungguli banyak metode yang ada (yang hanya mengandalkan pelatihan dengan fitur) pada berbagai tugas, seperti klasifikasi dokumen dan klasifikasi maksud semantik ( Bui dkk. ., WSDM'18 & Kipf dkk., ICLR'17 ).
- Kekokohan : model yang dilatih dengan contoh-contoh permusuhan telah terbukti kuat terhadap gangguan permusuhan yang dirancang untuk menyesatkan prediksi atau klasifikasi model ( Goodfellow dkk., ICLR'15 & Miyato dkk., ICLR'16 ). Jika jumlah sampel pelatihan sedikit, pelatihan dengan contoh adversarial juga membantu meningkatkan akurasi model ( Tsipras et al., ICLR'19 ).
- Diperlukan lebih sedikit data berlabel : NSL memungkinkan jaringan saraf memanfaatkan data berlabel dan tidak berlabel, yang memperluas paradigma pembelajaran ke pembelajaran semi-supervisi . Secara khusus, NSL memungkinkan jaringan untuk berlatih menggunakan data berlabel seperti dalam pengaturan yang diawasi, dan pada saat yang sama mendorong jaringan untuk mempelajari representasi tersembunyi serupa untuk "sampel tetangga" yang mungkin memiliki label atau tidak. Teknik ini menunjukkan harapan besar untuk meningkatkan akurasi model ketika jumlah data berlabel relatif kecil ( Bui et al., WSDM'18 & Miyato et al., ICLR'16 ).
Tutorial Langkah demi Langkah
Untuk mendapatkan pengalaman langsung dengan Neural Structured Learning, kami memiliki tutorial yang mencakup berbagai skenario di mana sinyal terstruktur dapat diberikan, dikonstruksi, atau diinduksi secara eksplisit. Berikut beberapa di antaranya:
Regularisasi grafik untuk klasifikasi dokumen menggunakan grafik natural . Dalam tutorial ini, kita mengeksplorasi penggunaan regularisasi grafik untuk mengklasifikasikan dokumen yang membentuk grafik natural (organik).
Regularisasi grafik untuk klasifikasi sentimen menggunakan grafik yang disintesis . Dalam tutorial ini, kami mendemonstrasikan penggunaan regularisasi grafik untuk mengklasifikasikan sentimen ulasan film dengan membangun (mensintesis) sinyal terstruktur.
Pembelajaran permusuhan untuk klasifikasi gambar . Dalam tutorial ini, kita mengeksplorasi penggunaan pembelajaran adversarial (di mana sinyal terstruktur diinduksi) untuk mengklasifikasikan gambar yang berisi digit numerik.
Contoh dan tutorial lainnya dapat ditemukan di direktori contoh repositori GitHub kami.