
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
Вероятностный анализ основных компонентов (РС) представляет собой метод сокращения размерности , которая анализирует данные через нижний размерное скрытое пространство ( Чаевой и Бишоп тысячи девятьсот девяносто девять ). Он часто используется, когда в данных отсутствуют значения или для многомерного масштабирования.
Импорт
import functools
import warnings
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import tensorflow.compat.v2 as tf
import tensorflow_probability as tfp
from tensorflow_probability import bijectors as tfb
from tensorflow_probability import distributions as tfd
tf.enable_v2_behavior()
plt.style.use("ggplot")
warnings.filterwarnings('ignore')
Модель
Рассмотрим множество данных \(\mathbf{X} = \{\mathbf{x}_n\}\) из \(N\) точек, где каждая точка данных является \(D\)-мерном, $ \ mathbf {х} _n \ в \ mathbb {R} ^ D\(. We aim to represent each \)\ mathbf {х} _n $ под скрытой переменной \(\mathbf{z}_n \in \mathbb{R}^K\) с меньшей размерности, $ K <D\(. The set of principal axes \)\ mathbf {W} $ относится скрытые переменные к данным.
В частности, мы предполагаем, что каждая скрытая переменная имеет нормальное распределение,
\[ \begin{equation*} \mathbf{z}_n \sim N(\mathbf{0}, \mathbf{I}). \end{equation*} \]
Соответствующая точка данных создается с помощью проекции,
\[ \begin{equation*} \mathbf{x}_n \mid \mathbf{z}_n \sim N(\mathbf{W}\mathbf{z}_n, \sigma^2\mathbf{I}), \end{equation*} \]
где матрица \(\mathbf{W}\in\mathbb{R}^{D\times K}\) известны как главные оси. В вероятностной PCA, мы , как правило , заинтересованы в оценке главных осей \(\mathbf{W}\) , а термин шум\(\sigma^2\).
Вероятностный PCA обобщает классический PCA. За исключением скрытой переменной, распределение каждой точки данных выглядит следующим образом:
\[ \begin{equation*} \mathbf{x}_n \sim N(\mathbf{0}, \mathbf{W}\mathbf{W}^\top + \sigma^2\mathbf{I}). \end{equation*} \]
Классическая PCA является частным случаем вероятностного PCA , когда ковариация шума становится бесконечно малым, \(\sigma^2 \to 0\).
Мы настроили нашу модель ниже. В нашем анализе мы предполагаем \(\sigma\) известно, и вместо оценки точки \(\mathbf{W}\) в качестве параметра модели, мы размещаем перед над ним для того , чтобы вывести распределение по главным осям. Мы выражаем модель как TFP JointDistribution, в частности, мы будем использовать JointDistributionCoroutineAutoBatched .
def probabilistic_pca(data_dim, latent_dim, num_datapoints, stddv_datapoints):
w = yield tfd.Normal(loc=tf.zeros([data_dim, latent_dim]),
scale=2.0 * tf.ones([data_dim, latent_dim]),
name="w")
z = yield tfd.Normal(loc=tf.zeros([latent_dim, num_datapoints]),
scale=tf.ones([latent_dim, num_datapoints]),
name="z")
x = yield tfd.Normal(loc=tf.matmul(w, z),
scale=stddv_datapoints,
name="x")
num_datapoints = 5000
data_dim = 2
latent_dim = 1
stddv_datapoints = 0.5
concrete_ppca_model = functools.partial(probabilistic_pca,
data_dim=data_dim,
latent_dim=latent_dim,
num_datapoints=num_datapoints,
stddv_datapoints=stddv_datapoints)
model = tfd.JointDistributionCoroutineAutoBatched(concrete_ppca_model)
Данные
Мы можем использовать модель для генерации данных путем выборки из совместного предварительного распределения.
actual_w, actual_z, x_train = model.sample()
print("Principal axes:")
print(actual_w)
Principal axes: tf.Tensor( [[ 2.2801023] [-1.1619819]], shape=(2, 1), dtype=float32)
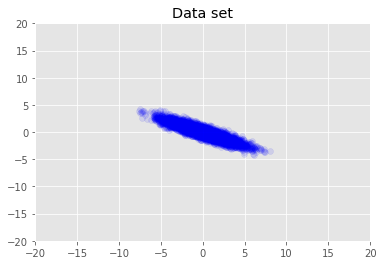
Визуализируем набор данных.
plt.scatter(x_train[0, :], x_train[1, :], color='blue', alpha=0.1)
plt.axis([-20, 20, -20, 20])
plt.title("Data set")
plt.show()
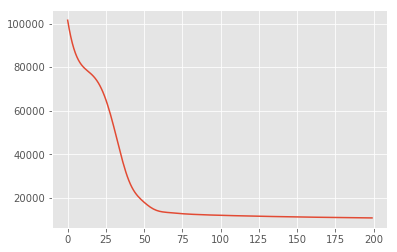
Максимум апостериорного вывода
Сначала мы ищем точечную оценку скрытых переменных, которая максимизирует апостериорную плотность вероятности. Это известно как максимум апостериорного (MAP) вывод, и делается путем вычисления значений \(\mathbf{W}\) и \(\mathbf{Z}\) , которые максимизируют заднюю плотность \(p(\mathbf{W}, \mathbf{Z} \mid \mathbf{X}) \propto p(\mathbf{W}, \mathbf{Z}, \mathbf{X})\).
w = tf.Variable(tf.random.normal([data_dim, latent_dim]))
z = tf.Variable(tf.random.normal([latent_dim, num_datapoints]))
target_log_prob_fn = lambda w, z: model.log_prob((w, z, x_train))
losses = tfp.math.minimize(
lambda: -target_log_prob_fn(w, z),
optimizer=tf.optimizers.Adam(learning_rate=0.05),
num_steps=200)
plt.plot(losses)
[<matplotlib.lines.Line2D at 0x7f19897a42e8>]
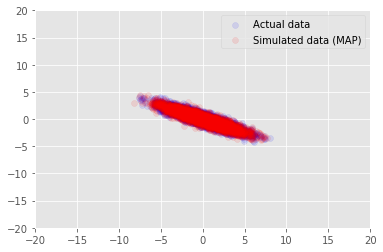
Мы можем использовать эту модель для выборки данных для выведенных значений для \(\mathbf{W}\) и \(\mathbf{Z}\), и сравнить с фактическим набором данных мы кондиционированными на.
print("MAP-estimated axes:")
print(w)
_, _, x_generated = model.sample(value=(w, z, None))
plt.scatter(x_train[0, :], x_train[1, :], color='blue', alpha=0.1, label='Actual data')
plt.scatter(x_generated[0, :], x_generated[1, :], color='red', alpha=0.1, label='Simulated data (MAP)')
plt.legend()
plt.axis([-20, 20, -20, 20])
plt.show()
MAP-estimated axes:
<tf.Variable 'Variable:0' shape=(2, 1) dtype=float32, numpy=
array([[ 2.9135954],
[-1.4826864]], dtype=float32)>
Вариационный вывод
MAP можно использовать для поиска режима (или одного из режимов) апостериорного распределения, но он не дает никаких других сведений об этом. Далее мы используем вариационное умозаключение, где задняя distribtion \(p(\mathbf{W}, \mathbf{Z} \mid \mathbf{X})\) аппроксимируется с помощью вариационной распределения \(q(\mathbf{W}, \mathbf{Z})\) параметризуется \(\boldsymbol{\lambda}\). Цель состоит в том, чтобы найти в вариациях параметров \(\boldsymbol{\lambda}\) , что свести к минимуму расхождения между KL д и задним, \(\mathrm{KL}(q(\mathbf{W}, \mathbf{Z}) \mid\mid p(\mathbf{W}, \mathbf{Z} \mid \mathbf{X}))\), или , что эквивалентно, что максимизирует доказательства нижней границы, \(\mathbb{E}_{q(\mathbf{W},\mathbf{Z};\boldsymbol{\lambda})}\left[ \log p(\mathbf{W},\mathbf{Z},\mathbf{X}) - \log q(\mathbf{W},\mathbf{Z}; \boldsymbol{\lambda}) \right]\).
qw_mean = tf.Variable(tf.random.normal([data_dim, latent_dim]))
qz_mean = tf.Variable(tf.random.normal([latent_dim, num_datapoints]))
qw_stddv = tfp.util.TransformedVariable(1e-4 * tf.ones([data_dim, latent_dim]),
bijector=tfb.Softplus())
qz_stddv = tfp.util.TransformedVariable(
1e-4 * tf.ones([latent_dim, num_datapoints]),
bijector=tfb.Softplus())
def factored_normal_variational_model():
qw = yield tfd.Normal(loc=qw_mean, scale=qw_stddv, name="qw")
qz = yield tfd.Normal(loc=qz_mean, scale=qz_stddv, name="qz")
surrogate_posterior = tfd.JointDistributionCoroutineAutoBatched(
factored_normal_variational_model)
losses = tfp.vi.fit_surrogate_posterior(
target_log_prob_fn,
surrogate_posterior=surrogate_posterior,
optimizer=tf.optimizers.Adam(learning_rate=0.05),
num_steps=200)
print("Inferred axes:")
print(qw_mean)
print("Standard Deviation:")
print(qw_stddv)
plt.plot(losses)
plt.show()
Inferred axes:
<tf.Variable 'Variable:0' shape=(2, 1) dtype=float32, numpy=
array([[ 2.4168603],
[-1.2236133]], dtype=float32)>
Standard Deviation:
<TransformedVariable: dtype=float32, shape=[2, 1], fn="softplus", numpy=
array([[0.0042499 ],
[0.00598824]], dtype=float32)>
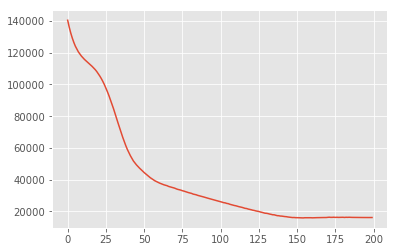
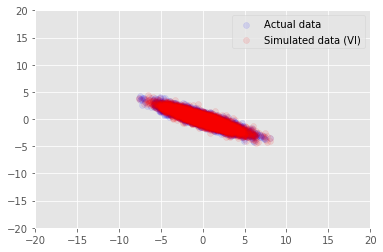
posterior_samples = surrogate_posterior.sample(50)
_, _, x_generated = model.sample(value=(posterior_samples))
# It's a pain to plot all 5000 points for each of our 50 posterior samples, so
# let's subsample to get the gist of the distribution.
x_generated = tf.reshape(tf.transpose(x_generated, [1, 0, 2]), (2, -1))[:, ::47]
plt.scatter(x_train[0, :], x_train[1, :], color='blue', alpha=0.1, label='Actual data')
plt.scatter(x_generated[0, :], x_generated[1, :], color='red', alpha=0.1, label='Simulated data (VI)')
plt.legend()
plt.axis([-20, 20, -20, 20])
plt.show()
Благодарности
Этот учебник был изначально написан на Эдварде 1.0 ( источник ). Мы благодарим всех участников за написание и исправление этой версии.
использованная литература
[1]: Майкл Э. Типпинг и Кристофер М. Бишоп. Вероятностный анализ главных компонент. Журнал Королевского статистического общества: Серия B (Статистическая методология), 61 (3): 611-622, 1999.