
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Dalam contoh ini Anda akan mengeksplorasi hasil McClean, 2019 yang mengatakan bahwa tidak sembarang struktur jaringan saraf kuantum akan berhasil dengan baik dalam hal pembelajaran. Secara khusus Anda akan melihat bahwa keluarga besar sirkuit kuantum acak tertentu tidak berfungsi sebagai jaringan saraf kuantum yang baik, karena mereka memiliki gradien yang menghilang hampir di mana-mana. Dalam contoh ini Anda tidak akan melatih model apa pun untuk masalah pembelajaran tertentu, tetapi berfokus pada masalah yang lebih sederhana dalam memahami perilaku gradien.
Mempersiapkan
pip install tensorflow==2.7.0
Instal TensorFlow Quantum:
pip install tensorflow-quantum
# Update package resources to account for version changes.
import importlib, pkg_resources
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
Sekarang impor TensorFlow dan dependensi modul:
import tensorflow as tf
import tensorflow_quantum as tfq
import cirq
import sympy
import numpy as np
# visualization tools
%matplotlib inline
import matplotlib.pyplot as plt
from cirq.contrib.svg import SVGCircuit
np.random.seed(1234)
2022-02-04 12:15:43.355568: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
1. Ringkasan
Sirkuit kuantum acak dengan banyak blok yang terlihat seperti ini (\(R_{P}(\theta)\) adalah rotasi Pauli acak):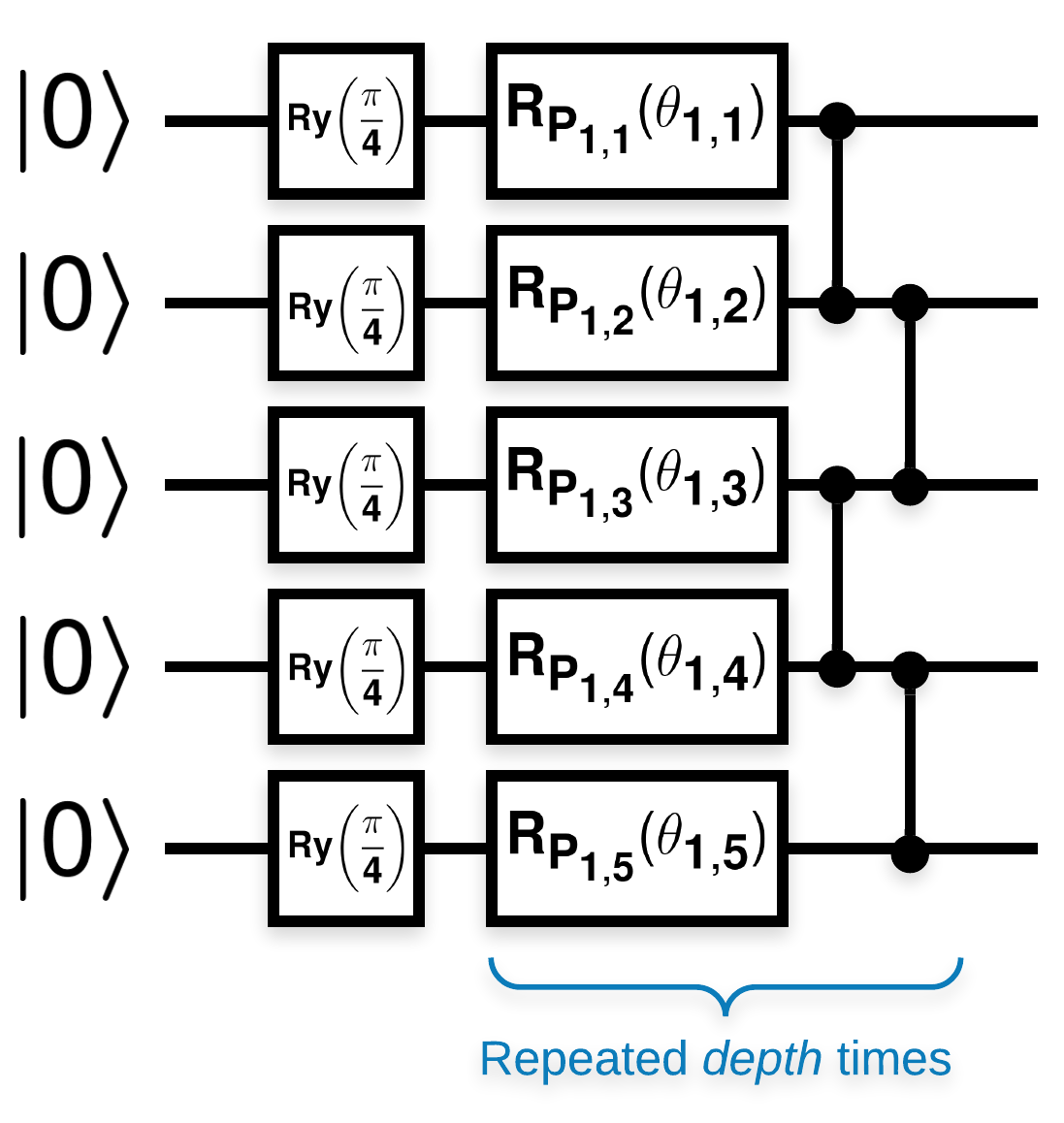
Dimana jika \(f(x)\) didefinisikan sebagai nilai ekspektasi wrt \(Z_{a}Z_{b}\) untuk setiap qubit \(a\) dan \(b\), maka ada masalah bahwa \(f'(x)\) memiliki mean yang sangat dekat dengan 0 dan tidak berbeda jauh. Anda akan melihat ini di bawah ini:
2. Membangkitkan sirkuit acak
Konstruksi dari kertas mudah diikuti. Berikut ini mengimplementasikan fungsi sederhana yang menghasilkan sirkuit kuantum acak—kadang-kadang disebut sebagai jaringan saraf kuantum (QNN)—dengan kedalaman tertentu pada sekumpulan qubit:
def generate_random_qnn(qubits, symbol, depth):
"""Generate random QNN's with the same structure from McClean et al."""
circuit = cirq.Circuit()
for qubit in qubits:
circuit += cirq.ry(np.pi / 4.0)(qubit)
for d in range(depth):
# Add a series of single qubit rotations.
for i, qubit in enumerate(qubits):
random_n = np.random.uniform()
random_rot = np.random.uniform(
) * 2.0 * np.pi if i != 0 or d != 0 else symbol
if random_n > 2. / 3.:
# Add a Z.
circuit += cirq.rz(random_rot)(qubit)
elif random_n > 1. / 3.:
# Add a Y.
circuit += cirq.ry(random_rot)(qubit)
else:
# Add a X.
circuit += cirq.rx(random_rot)(qubit)
# Add CZ ladder.
for src, dest in zip(qubits, qubits[1:]):
circuit += cirq.CZ(src, dest)
return circuit
generate_random_qnn(cirq.GridQubit.rect(1, 3), sympy.Symbol('theta'), 2)
Penulis menyelidiki gradien parameter tunggal \(\theta_{1,1}\). Mari kita ikuti dengan menempatkan sympy.Symbol di sirkuit di mana \(\theta_{1,1}\) akan berada. Karena penulis tidak menganalisis statistik untuk simbol lain di sirkuit, mari kita ganti dengan nilai acak sekarang daripada nanti.
3. Menjalankan sirkuit
Hasilkan beberapa sirkuit ini bersama dengan yang dapat diamati untuk menguji klaim bahwa gradien tidak terlalu bervariasi. Pertama, menghasilkan batch sirkuit acak. Pilih ZZ acak yang dapat diamati dan hitung gradien dan variansnya menggunakan TensorFlow Quantum.
3.1 Perhitungan varians batch
Mari kita tulis fungsi pembantu yang menghitung varians dari gradien yang dapat diamati pada sekumpulan sirkuit:
def process_batch(circuits, symbol, op):
"""Compute the variance of a batch of expectations w.r.t. op on each circuit that
contains `symbol`. Note that this method sets up a new compute graph every time it is
called so it isn't as performant as possible."""
# Setup a simple layer to batch compute the expectation gradients.
expectation = tfq.layers.Expectation()
# Prep the inputs as tensors
circuit_tensor = tfq.convert_to_tensor(circuits)
values_tensor = tf.convert_to_tensor(
np.random.uniform(0, 2 * np.pi, (n_circuits, 1)).astype(np.float32))
# Use TensorFlow GradientTape to track gradients.
with tf.GradientTape() as g:
g.watch(values_tensor)
forward = expectation(circuit_tensor,
operators=op,
symbol_names=[symbol],
symbol_values=values_tensor)
# Return variance of gradients across all circuits.
grads = g.gradient(forward, values_tensor)
grad_var = tf.math.reduce_std(grads, axis=0)
return grad_var.numpy()[0]
3.1 Siapkan dan jalankan
Pilih jumlah sirkuit acak yang akan dihasilkan bersama dengan kedalamannya dan jumlah qubit yang harus mereka kerjakan. Kemudian gambarkan hasilnya.
n_qubits = [2 * i for i in range(2, 7)
] # Ranges studied in paper are between 2 and 24.
depth = 50 # Ranges studied in paper are between 50 and 500.
n_circuits = 200
theta_var = []
for n in n_qubits:
# Generate the random circuits and observable for the given n.
qubits = cirq.GridQubit.rect(1, n)
symbol = sympy.Symbol('theta')
circuits = [
generate_random_qnn(qubits, symbol, depth) for _ in range(n_circuits)
]
op = cirq.Z(qubits[0]) * cirq.Z(qubits[1])
theta_var.append(process_batch(circuits, symbol, op))
plt.semilogy(n_qubits, theta_var)
plt.title('Gradient Variance in QNNs')
plt.xlabel('n_qubits')
plt.xticks(n_qubits)
plt.ylabel('$\\partial \\theta$ variance')
plt.show()
WARNING:tensorflow:5 out of the last 5 calls to <function Adjoint.differentiate_analytic at 0x7f9e3b5c68c0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
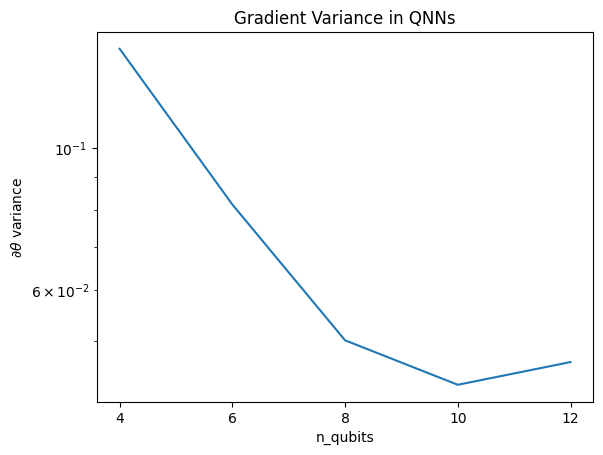
Plot ini menunjukkan bahwa untuk masalah pembelajaran mesin kuantum, Anda tidak bisa begitu saja menebak ansatz QNN acak dan berharap yang terbaik. Beberapa struktur harus ada dalam rangkaian model agar gradien bervariasi ke titik di mana pembelajaran dapat terjadi.
4. Heuristik
Heuristik yang menarik oleh Grant, 2019 memungkinkan seseorang untuk memulai sangat dekat dengan acak, tetapi tidak cukup. Menggunakan sirkuit yang sama seperti McClean et al., penulis mengusulkan teknik inisialisasi yang berbeda untuk parameter kontrol klasik untuk menghindari dataran tinggi yang tandus. Teknik inisialisasi memulai beberapa lapisan dengan parameter kontrol yang benar-benar acak—tetapi, pada lapisan yang segera menyusul, pilih parameter sedemikian rupa sehingga transformasi awal yang dibuat oleh beberapa lapisan pertama dibatalkan. Penulis menyebutnya sebagai blok identitas .
Keuntungan dari heuristik ini adalah bahwa dengan mengubah hanya satu parameter, semua blok lain di luar blok saat ini akan tetap menjadi identitas—dan sinyal gradien datang jauh lebih kuat dari sebelumnya. Ini memungkinkan pengguna untuk memilih dan memilih variabel dan blok mana yang akan dimodifikasi untuk mendapatkan sinyal gradien yang kuat. Heuristik ini tidak mencegah pengguna jatuh ke dataran tinggi yang tandus selama fase pelatihan (dan membatasi pembaruan yang sepenuhnya simultan), ini hanya menjamin bahwa Anda dapat memulai di luar dataran tinggi.
4.1 Konstruksi QNN baru
Sekarang buat fungsi untuk menghasilkan QNN blok identitas. Implementasi ini sedikit berbeda dari yang dari kertas. Untuk saat ini, lihat perilaku gradien dari satu parameter sehingga konsisten dengan McClean et al, sehingga beberapa penyederhanaan dapat dilakukan.
Untuk menghasilkan blok identitas dan melatih model, umumnya Anda memerlukan \(U1(\theta_{1a}) U1(\theta_{1b})^{\dagger}\) dan bukan \(U1(\theta_1) U1(\theta_1)^{\dagger}\). Awalnya \(\theta_{1a}\) dan \(\theta_{1b}\) adalah sudut yang sama tetapi mereka dipelajari secara independen. Jika tidak, Anda akan selalu mendapatkan identitas bahkan setelah pelatihan. Pilihan jumlah blok identitas bersifat empiris. Semakin dalam blok, semakin kecil varians di tengah blok. Tetapi pada awal dan akhir blok, varians dari gradien parameter harus besar.
def generate_identity_qnn(qubits, symbol, block_depth, total_depth):
"""Generate random QNN's with the same structure from Grant et al."""
circuit = cirq.Circuit()
# Generate initial block with symbol.
prep_and_U = generate_random_qnn(qubits, symbol, block_depth)
circuit += prep_and_U
# Generate dagger of initial block without symbol.
U_dagger = (prep_and_U[1:])**-1
circuit += cirq.resolve_parameters(
U_dagger, param_resolver={symbol: np.random.uniform() * 2 * np.pi})
for d in range(total_depth - 1):
# Get a random QNN.
prep_and_U_circuit = generate_random_qnn(
qubits,
np.random.uniform() * 2 * np.pi, block_depth)
# Remove the state-prep component
U_circuit = prep_and_U_circuit[1:]
# Add U
circuit += U_circuit
# Add U^dagger
circuit += U_circuit**-1
return circuit
generate_identity_qnn(cirq.GridQubit.rect(1, 3), sympy.Symbol('theta'), 2, 2)
4.2 Perbandingan
Di sini Anda dapat melihat bahwa heuristik memang membantu menjaga varians gradien agar tidak menghilang dengan cepat:
block_depth = 10
total_depth = 5
heuristic_theta_var = []
for n in n_qubits:
# Generate the identity block circuits and observable for the given n.
qubits = cirq.GridQubit.rect(1, n)
symbol = sympy.Symbol('theta')
circuits = [
generate_identity_qnn(qubits, symbol, block_depth, total_depth)
for _ in range(n_circuits)
]
op = cirq.Z(qubits[0]) * cirq.Z(qubits[1])
heuristic_theta_var.append(process_batch(circuits, symbol, op))
plt.semilogy(n_qubits, theta_var)
plt.semilogy(n_qubits, heuristic_theta_var)
plt.title('Heuristic vs. Random')
plt.xlabel('n_qubits')
plt.xticks(n_qubits)
plt.ylabel('$\\partial \\theta$ variance')
plt.show()
WARNING:tensorflow:6 out of the last 6 calls to <function Adjoint.differentiate_analytic at 0x7f9e3b5c68c0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
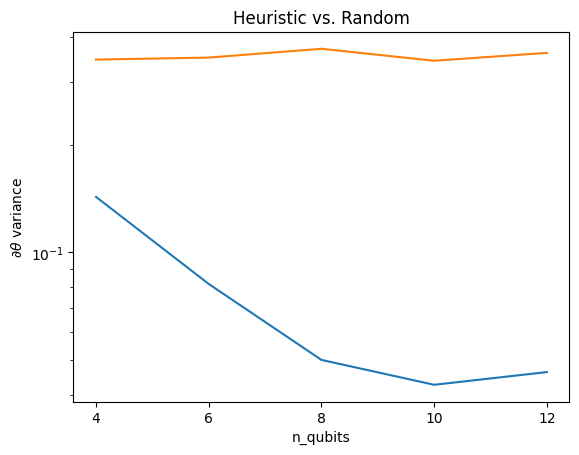
Ini adalah peningkatan besar dalam mendapatkan sinyal gradien yang lebih kuat dari (dekat) QNN acak.