
টেনসরফ্লো ডেটা ভ্যালিডেশন (TFDV) প্রশিক্ষণ এবং পরিবেশন ডেটা বিশ্লেষণ করতে পারে:
বর্ণনামূলক পরিসংখ্যান গণনা,
একটি স্কিমা অনুমান করা,
তথ্য অসঙ্গতি সনাক্ত.
মূল API কার্যকারিতার প্রতিটি অংশকে সমর্থন করে, সুবিধার পদ্ধতিগুলি যা উপরে তৈরি করে এবং নোটবুকের প্রসঙ্গে বলা যেতে পারে।
বর্ণনামূলক ডেটা পরিসংখ্যান গণনা করা
TFDV বর্ণনামূলক পরিসংখ্যান গণনা করতে পারে যা উপস্থিত বৈশিষ্ট্যগুলির পরিপ্রেক্ষিতে ডেটার একটি দ্রুত ওভারভিউ প্রদান করে এবং তাদের মান বিতরণের আকারগুলি। ফ্যাসেট ওভারভিউ- এর মতো টুলগুলি সহজে ব্রাউজ করার জন্য এই পরিসংখ্যানগুলির একটি সংক্ষিপ্ত ভিজ্যুয়ালাইজেশন প্রদান করতে পারে।
উদাহরণস্বরূপ, ধরুন যে path TFRecord বিন্যাসে একটি ফাইলের দিকে নির্দেশ করে (যা tensorflow.Example টাইপের রেকর্ড ধারণ করে। উদাহরণ )। নিম্নলিখিত স্নিপেটটি TFDV ব্যবহার করে পরিসংখ্যানের গণনার চিত্র তুলে ধরে:
stats = tfdv.generate_statistics_from_tfrecord(data_location=path)
প্রত্যাবর্তিত মান একটি DatasetFeatureStatisticsList প্রোটোকল বাফার। উদাহরণ নোটবুকে ফ্যাসেট ওভারভিউ ব্যবহার করে পরিসংখ্যানের একটি ভিজ্যুয়ালাইজেশন রয়েছে:
tfdv.visualize_statistics(stats)
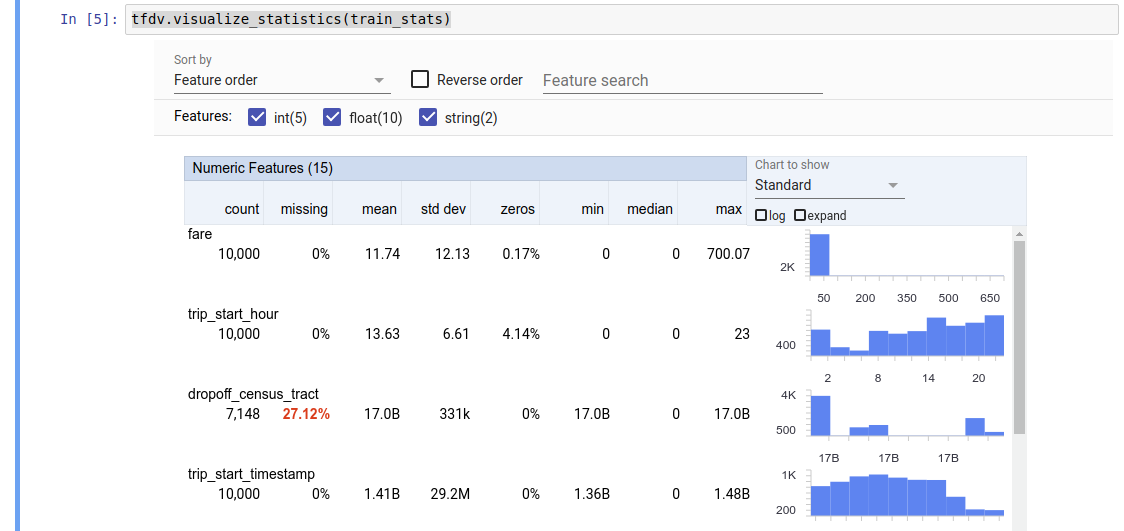
পূর্ববর্তী উদাহরণটি অনুমান করে যে তথ্যটি একটি TFRecord ফাইলে সংরক্ষণ করা হয়েছে। TFDV CSV ইনপুট ফর্ম্যাটকেও সমর্থন করে, অন্যান্য সাধারণ ফর্ম্যাটের জন্য এক্সটেনসিবিলিটি সহ। আপনি এখানে উপলব্ধ ডেটা ডিকোডারগুলি খুঁজে পেতে পারেন। উপরন্তু, TFDV একটি পান্ডাস ডেটাফ্রেম হিসাবে উপস্থাপিত ইন-মেমরি ডেটা সহ ব্যবহারকারীদের জন্য tfdv.generate_statistics_from_dataframe ইউটিলিটি ফাংশন প্রদান করে।
ডেটা পরিসংখ্যানের একটি ডিফল্ট সেট গণনা করার পাশাপাশি, TFDV শব্দার্থিক ডোমেনের জন্য পরিসংখ্যানও গণনা করতে পারে (যেমন, ছবি, পাঠ্য)। শব্দার্থিক ডোমেন পরিসংখ্যানের গণনা সক্ষম করতে, tfdv.generate_statistics_from_tfrecord এ সত্য সেট করে enable_semantic_domain_stats সহ একটি tfdv.StatsOptions অবজেক্ট পাস করুন।
গুগল ক্লাউডে চলছে
অভ্যন্তরীণভাবে, TFDV Apache Beam- এর ডেটা-সমান্তরাল প্রসেসিং ফ্রেমওয়ার্ক ব্যবহার করে বড় ডেটাসেটের উপর পরিসংখ্যানের গণনা স্কেল করতে। যে অ্যাপ্লিকেশনগুলি TFDV-এর সাথে গভীরভাবে একীভূত হতে চায় (যেমন ডেটা-জেনারেশন পাইপলাইনের শেষে পরিসংখ্যান জেনারেশন সংযুক্ত করুন, কাস্টম ফর্ম্যাটে ডেটার জন্য পরিসংখ্যান তৈরি করুন ), এপিআই পরিসংখ্যান তৈরির জন্য একটি বিম PTট্রান্সফর্মও প্রকাশ করে৷
Google ক্লাউডে TFDV চালানোর জন্য, TFDV হুইল ফাইলটি ডাউনলোড করে ডেটাফ্লো কর্মীদের প্রদান করতে হবে। নিম্নরূপ বর্তমান ডিরেক্টরিতে চাকা ফাইল ডাউনলোড করুন:
pip download tensorflow_data_validation \
--no-deps \
--platform manylinux2010_x86_64 \
--only-binary=:all:
নিম্নলিখিত স্নিপেটটি Google ক্লাউডে TFDV-এর একটি উদাহরণ ব্যবহার দেখায়:
import tensorflow_data_validation as tfdv
from apache_beam.options.pipeline_options import PipelineOptions, GoogleCloudOptions, StandardOptions, SetupOptions
PROJECT_ID = ''
JOB_NAME = ''
GCS_STAGING_LOCATION = ''
GCS_TMP_LOCATION = ''
GCS_DATA_LOCATION = ''
# GCS_STATS_OUTPUT_PATH is the file path to which to output the data statistics
# result.
GCS_STATS_OUTPUT_PATH = ''
PATH_TO_WHL_FILE = ''
# Create and set your PipelineOptions.
options = PipelineOptions()
# For Cloud execution, set the Cloud Platform project, job_name,
# staging location, temp_location and specify DataflowRunner.
google_cloud_options = options.view_as(GoogleCloudOptions)
google_cloud_options.project = PROJECT_ID
google_cloud_options.job_name = JOB_NAME
google_cloud_options.staging_location = GCS_STAGING_LOCATION
google_cloud_options.temp_location = GCS_TMP_LOCATION
options.view_as(StandardOptions).runner = 'DataflowRunner'
setup_options = options.view_as(SetupOptions)
# PATH_TO_WHL_FILE should point to the downloaded tfdv wheel file.
setup_options.extra_packages = [PATH_TO_WHL_FILE]
tfdv.generate_statistics_from_tfrecord(GCS_DATA_LOCATION,
output_path=GCS_STATS_OUTPUT_PATH,
pipeline_options=options)
এই ক্ষেত্রে, জেনারেট করা পরিসংখ্যান প্রোটো GCS_STATS_OUTPUT_PATH এ লেখা একটি TFRecord ফাইলে সংরক্ষণ করা হয়।
দ্রষ্টব্য Google ক্লাউডে tfdv.generate_statistics_... ফাংশনগুলির (যেমন, tfdv.generate_statistics_from_tfrecord ) কল করার সময়, আপনাকে অবশ্যই একটি output_path প্রদান করতে হবে। কোনোটিই উল্লেখ না করলে ত্রুটি হতে পারে।
ডেটার উপর একটি স্কিমা অনুমান করা
স্কিমা ডেটার প্রত্যাশিত বৈশিষ্ট্য বর্ণনা করে। এই বৈশিষ্ট্যগুলির মধ্যে কয়েকটি হল:
- যা বৈশিষ্ট্য উপস্থিত হতে প্রত্যাশিত
- তাদের ধরন
- প্রতিটি উদাহরণে একটি বৈশিষ্ট্যের জন্য মানের সংখ্যা
- সমস্ত উদাহরণ জুড়ে প্রতিটি বৈশিষ্ট্য উপস্থিতি
- বৈশিষ্ট্যের প্রত্যাশিত ডোমেন।
সংক্ষেপে, স্কিমা "সঠিক" ডেটার জন্য প্রত্যাশাগুলি বর্ণনা করে এবং এইভাবে ডেটাতে ত্রুটি সনাক্ত করতে ব্যবহার করা যেতে পারে (নীচে বর্ণিত)। তাছাড়া, একই স্কিমা ডেটা ট্রান্সফর্মেশনের জন্য TensorFlow Transform সেট আপ করতে ব্যবহার করা যেতে পারে। মনে রাখবেন যে স্কিমাটি মোটামুটি স্থির হবে বলে আশা করা হচ্ছে, যেমন, বেশ কয়েকটি ডেটাসেট একই স্কিমার সাথে সামঞ্জস্যপূর্ণ হতে পারে, যেখানে পরিসংখ্যান (উপরে বর্ণিত) ডেটাসেটের প্রতি পরিবর্তিত হতে পারে।
যেহেতু একটি স্কিমা লেখা একটি ক্লান্তিকর কাজ হতে পারে, বিশেষ করে প্রচুর বৈশিষ্ট্য সহ ডেটাসেটের জন্য, TFDV বর্ণনামূলক পরিসংখ্যানের উপর ভিত্তি করে স্কিমার একটি প্রাথমিক সংস্করণ তৈরি করার একটি পদ্ধতি প্রদান করে:
schema = tfdv.infer_schema(stats)
সাধারণভাবে, TFDV পরিসংখ্যান থেকে স্থিতিশীল ডেটা বৈশিষ্ট্য অনুমান করতে রক্ষণশীল হিউরিস্টিক ব্যবহার করে যাতে নির্দিষ্ট ডেটাসেটে স্কিমাকে ওভারফিট না করা যায়। TFDV-এর হিউরিস্টিকস মিস করে থাকতে পারে এমন ডেটা সম্পর্কে যেকোন ডোমেন জ্ঞান ক্যাপচার করতে, অনুমানকৃত স্কিমা পর্যালোচনা করার এবং প্রয়োজন অনুসারে এটিকে পরিমার্জন করার জন্য দৃঢ়ভাবে পরামর্শ দেওয়া হচ্ছে।
ডিফল্টরূপে, tfdv.infer_schema প্রতিটি প্রয়োজনীয় বৈশিষ্ট্যের আকার অনুমান করে, যদি বৈশিষ্ট্যটির জন্য value_count.min value_count.max সমান হয়। আকৃতি অনুমান নিষ্ক্রিয় করতে infer_feature_shape আর্গুমেন্ট False এ সেট করুন।
স্কিমা নিজেই একটি স্কিমা প্রোটোকল বাফার হিসাবে সংরক্ষণ করা হয় এবং এইভাবে স্ট্যান্ডার্ড প্রোটোকল-বাফার API ব্যবহার করে আপডেট/সম্পাদনা করা যেতে পারে। TFDV এই আপডেটগুলি সহজ করার জন্য কয়েকটি ইউটিলিটি পদ্ধতিও প্রদান করে। উদাহরণস্বরূপ, ধরুন যে স্কিমাটিতে একটি প্রয়োজনীয় স্ট্রিং বৈশিষ্ট্য payment_type বর্ণনা করার জন্য নিম্নলিখিত স্তবক রয়েছে যা একটি একক মান নেয়:
feature {
name: "payment_type"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
}
বৈশিষ্ট্যটি অন্তত 50% উদাহরণে পপুলেট করা উচিত তা চিহ্নিত করতে:
tfdv.get_feature(schema, 'payment_type').presence.min_fraction = 0.5
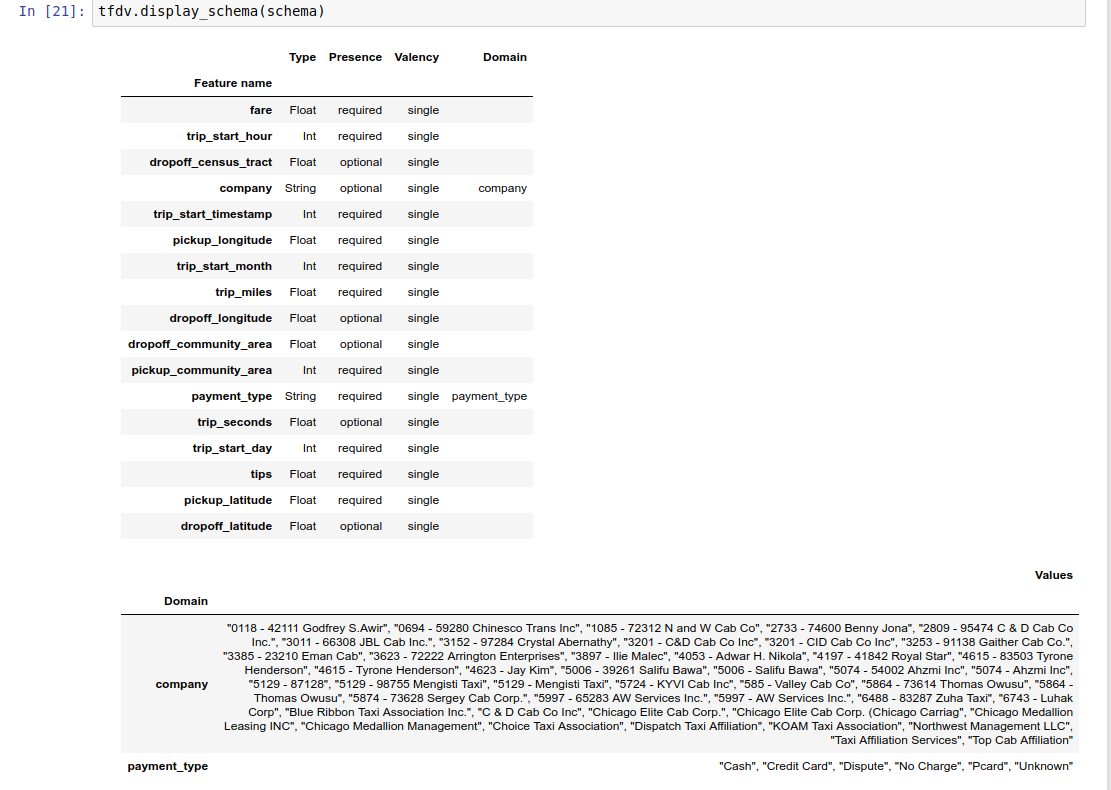
উদাহরণের নোটবুকটিতে একটি টেবিল হিসাবে স্কিমার একটি সাধারণ ভিজ্যুয়ালাইজেশন রয়েছে, প্রতিটি বৈশিষ্ট্য এবং এর প্রধান বৈশিষ্ট্যগুলিকে স্কিমাতে এনকোড করা হিসাবে তালিকাভুক্ত করে।
ত্রুটির জন্য ডেটা পরীক্ষা করা হচ্ছে
একটি স্কিমা দেওয়া হলে, একটি ডেটাসেট স্কিমাতে সেট করা প্রত্যাশার সাথে সঙ্গতিপূর্ণ কিনা বা ডেটার কোনো অসঙ্গতি আছে কিনা তা পরীক্ষা করা সম্ভব। আপনি স্কিমার বিপরীতে ডেটাসেটের পরিসংখ্যানের সাথে মিল করে একটি সম্পূর্ণ ডেটাসেট জুড়ে ত্রুটিগুলির জন্য আপনার ডেটা পরীক্ষা করতে পারেন (a) বা (b) প্রতি-উদাহরণ ভিত্তিতে ত্রুটিগুলি পরীক্ষা করে৷
একটি স্কিমার বিপরীতে ডেটাসেটের পরিসংখ্যান মেলানো
সমষ্টিতে ত্রুটিগুলি পরীক্ষা করতে, TFDV স্কিমার বিপরীতে ডেটাসেটের পরিসংখ্যানের সাথে মেলে এবং কোনো অসঙ্গতি চিহ্নিত করে। যেমন:
# Assume that other_path points to another TFRecord file
other_stats = tfdv.generate_statistics_from_tfrecord(data_location=other_path)
anomalies = tfdv.validate_statistics(statistics=other_stats, schema=schema)
ফলাফল হল অ্যানোমলিজ প্রোটোকল বাফারের একটি উদাহরণ এবং পরিসংখ্যান স্কিমার সাথে একমত নয় এমন কোনো ত্রুটি বর্ণনা করে। উদাহরণস্বরূপ, ধরুন যে other_path এর ডেটাতে স্কিমাতে নির্দিষ্ট করা ডোমেনের বাইরে অর্থ payment_type বৈশিষ্ট্যের মান সহ উদাহরণ রয়েছে।
এটি একটি অসঙ্গতি তৈরি করে
payment_type Unexpected string values Examples contain values missing from the schema: Prcard (<1%).
ইঙ্গিত করে যে পরিসংখ্যানে বৈশিষ্ট্য মানের <1%-এর মধ্যে একটি ডোমেনের বাইরের মান পাওয়া গেছে।
যদি এটি প্রত্যাশিত ছিল, তাহলে স্কিমাটি নিম্নরূপ আপডেট করা যেতে পারে:
tfdv.get_domain(schema, 'payment_type').value.append('Prcard')
যদি অসংগতি সত্যিই একটি ডেটা ত্রুটি নির্দেশ করে, তাহলে প্রশিক্ষণের জন্য এটি ব্যবহার করার আগে অন্তর্নিহিত ডেটা ঠিক করা উচিত।
এই মডিউল দ্বারা সনাক্ত করা যেতে পারে এমন বিভিন্ন ধরনের অসঙ্গতি এখানে তালিকাভুক্ত করা হয়েছে।
উদাহরণের নোটবুকটিতে একটি টেবিল হিসাবে অসামঞ্জস্যগুলির একটি সাধারণ ভিজ্যুয়ালাইজেশন রয়েছে, যেখানে ত্রুটিগুলি সনাক্ত করা হয়েছে সেগুলির তালিকা এবং প্রতিটি ত্রুটির একটি সংক্ষিপ্ত বিবরণ রয়েছে৷

প্রতি-উদাহরণ ভিত্তিতে ত্রুটির জন্য পরীক্ষা করা হচ্ছে
TFDV স্কিমার বিপরীতে ডেটাসেট-ওয়াইড পরিসংখ্যান তুলনা করার পরিবর্তে প্রতি-উদাহরণ ভিত্তিতে ডেটা যাচাই করার বিকল্পও প্রদান করে। TFDV প্রতি-উদাহরণ ভিত্তিতে ডেটা যাচাই করার জন্য ফাংশন প্রদান করে এবং তারপর পাওয়া অস্বাভাবিক উদাহরণগুলির জন্য সারাংশ পরিসংখ্যান তৈরি করে। যেমন:
options = tfdv.StatsOptions(schema=schema)
anomalous_example_stats = tfdv.validate_examples_in_tfrecord(
data_location=input, stats_options=options)
anomalous_example_stats যেটি validate_examples_in_tfrecord প্রদান করে তা হল একটি DatasetFeatureStatisticsList প্রোটোকল বাফার যেখানে প্রতিটি ডেটাসেটে উদাহরণের সেট থাকে যা একটি নির্দিষ্ট অসঙ্গতি প্রদর্শন করে। আপনার ডেটাসেটের উদাহরণের সংখ্যা নির্ধারণ করতে আপনি এটি ব্যবহার করতে পারেন যেগুলি প্রদত্ত অসঙ্গতি প্রদর্শন করে এবং সেই উদাহরণগুলির বৈশিষ্ট্যগুলি।
স্কিমা পরিবেশ
ডিফল্টরূপে, বৈধতা অনুমান করে যে একটি পাইপলাইনের সমস্ত ডেটাসেট একটি একক স্কিমা মেনে চলে। কিছু ক্ষেত্রে সামান্য স্কিমা বৈচিত্র প্রবর্তন করা প্রয়োজন, উদাহরণস্বরূপ লেবেল হিসাবে ব্যবহৃত বৈশিষ্ট্যগুলি প্রশিক্ষণের সময় প্রয়োজন (এবং যাচাই করা উচিত), কিন্তু পরিবেশন করার সময় অনুপস্থিত।
এই ধরনের প্রয়োজনীয়তা প্রকাশ করতে পরিবেশ ব্যবহার করা যেতে পারে। বিশেষ করে, স্কিমার বৈশিষ্ট্যগুলি ডিফল্ট_এনভায়রনমেন্ট, ইন_এনভায়রনমেন্ট এবং না_ইন_এনভায়রনমেন্ট ব্যবহার করে পরিবেশের একটি সেটের সাথে যুক্ত হতে পারে।
উদাহরণস্বরূপ, যদি টিপস বৈশিষ্ট্যটি প্রশিক্ষণে লেবেল হিসাবে ব্যবহৃত হয় তবে পরিবেশন ডেটাতে অনুপস্থিত। নির্দিষ্ট পরিবেশ ছাড়া, এটি একটি অসঙ্গতি হিসাবে প্রদর্শিত হবে।
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)

এটি ঠিক করার জন্য, আমাদের 'প্রশিক্ষণ' এবং 'পরিষেবা' উভয় বৈশিষ্ট্যের জন্য ডিফল্ট পরিবেশ সেট করতে হবে এবং পরিবেশন পরিবেশ থেকে 'টিপস' বৈশিষ্ট্যটি বাদ দিতে হবে।
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
ডেটা তির্যক এবং প্রবাহ পরীক্ষা করা হচ্ছে
একটি ডেটাসেট স্কিমাতে সেট করা প্রত্যাশার সাথে সামঞ্জস্যপূর্ণ কিনা তা পরীক্ষা করার পাশাপাশি, TFDV সনাক্ত করার জন্য কার্যকারিতাও প্রদান করে:
- প্রশিক্ষণ এবং পরিবেশন ডেটার মধ্যে তির্যক
- প্রশিক্ষণের বিভিন্ন দিনের ডেটার মধ্যে প্রবাহ
TFDV স্কিমাতে নির্দিষ্ট করা ড্রিফট/স্কিউ তুলনাকারীদের উপর ভিত্তি করে বিভিন্ন ডেটাসেটের পরিসংখ্যান তুলনা করে এই পরীক্ষাটি করে। উদাহরণ স্বরূপ, প্রশিক্ষণ এবং ডেটাসেট পরিবেশনের মধ্যে 'পেমেন্ট_টাইপ' বৈশিষ্ট্যের মধ্যে কোনো তির্যক আছে কিনা তা পরীক্ষা করতে:
# Assume we have already generated the statistics of training dataset, and
# inferred a schema from it.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
# Add a skew comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering skew anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').skew_comparator.infinity_norm.threshold = 0.01
skew_anomalies = tfdv.validate_statistics(
statistics=train_stats, schema=schema, serving_statistics=serving_stats)
দ্রষ্টব্য L-ইনফিনিটি আদর্শ শুধুমাত্র শ্রেণীগত বৈশিষ্ট্যগুলির জন্য তির্যক সনাক্ত করবে। একটি infinity_norm থ্রেশহোল্ড নির্দিষ্ট করার পরিবর্তে, skew_comparator এ একটি jensen_shannon_divergence থ্রেশহোল্ড নির্দিষ্ট করা হলে তা সাংখ্যিক এবং শ্রেণীগত উভয় বৈশিষ্ট্যের জন্য তির্যক সনাক্ত করবে।
একটি ডেটাসেট স্কিমাতে সেট করা প্রত্যাশাগুলির সাথে সামঞ্জস্যপূর্ণ কিনা তা পরীক্ষা করার সাথে সাথে, ফলাফলটিও অ্যানোমলিজ প্রোটোকল বাফারের একটি উদাহরণ এবং প্রশিক্ষণ এবং ডেটাসেট পরিবেশন করার মধ্যে যে কোনও তির্যক বর্ণনা করে৷ উদাহরণ স্বরূপ, ধরুন সার্ভিং ডেটাতে উল্লেখযোগ্যভাবে আরও উদাহরণ রয়েছে যার বৈশিষ্ট্য payement_type মান Cash রয়েছে, এটি একটি তির্যক অসঙ্গতি তৈরি করে
payment_type High L-infinity distance between serving and training The L-infinity distance between serving and training is 0.0435984 (up to six significant digits), above the threshold 0.01. The feature value with maximum difference is: Cash
যদি অসংগতি সত্যিই প্রশিক্ষণ এবং পরিবেশন ডেটার মধ্যে একটি তির্যক নির্দেশ করে, তাহলে আরও তদন্ত করা প্রয়োজন কারণ এটি মডেলের কর্মক্ষমতার উপর সরাসরি প্রভাব ফেলতে পারে।
উদাহরণের নোটবুকে স্কু-ভিত্তিক অসঙ্গতিগুলি পরীক্ষা করার একটি সহজ উদাহরণ রয়েছে।
প্রশিক্ষণের বিভিন্ন দিনের ডেটার মধ্যে প্রবাহ সনাক্তকরণ একইভাবে করা যেতে পারে
# Assume we have already generated the statistics of training dataset for
# day 2, and inferred a schema from it.
train_day1_stats = tfdv.generate_statistics_from_tfrecord(data_location=train_day1_data_path)
# Add a drift comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering drift anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').drift_comparator.infinity_norm.threshold = 0.01
drift_anomalies = tfdv.validate_statistics(
statistics=train_day2_stats, schema=schema, previous_statistics=train_day1_stats)
দ্রষ্টব্য L-ইনফিনিটি আদর্শ শুধুমাত্র শ্রেণীগত বৈশিষ্ট্যগুলির জন্য তির্যক সনাক্ত করবে। একটি infinity_norm থ্রেশহোল্ড নির্দিষ্ট করার পরিবর্তে, skew_comparator এ একটি jensen_shannon_divergence থ্রেশহোল্ড নির্দিষ্ট করা হলে তা সাংখ্যিক এবং শ্রেণীগত উভয় বৈশিষ্ট্যের জন্য তির্যক সনাক্ত করবে।
কাস্টম ডেটা সংযোগকারী লেখা
ডেটা পরিসংখ্যান গণনা করার জন্য, TFDV বিভিন্ন ফর্ম্যাটে ইনপুট ডেটা পরিচালনা করার জন্য বেশ কয়েকটি সুবিধাজনক পদ্ধতি সরবরাহ করে (যেমন tf.train. উদাহরণ , CSV, ইত্যাদির TFRecord )। যদি আপনার ডেটা বিন্যাস এই তালিকায় না থাকে, তাহলে ইনপুট ডেটা পড়ার জন্য আপনাকে একটি কাস্টম ডেটা সংযোগকারী লিখতে হবে এবং ডেটা পরিসংখ্যান কম্পিউট করার জন্য TFDV কোর API এর সাথে এটি সংযুক্ত করতে হবে।
ডেটা পরিসংখ্যান কম্পিউটিং করার জন্য TFDV কোর API হল একটি Beam PTransform যা ইনপুট উদাহরণগুলির ব্যাচগুলির একটি PC সংগ্রহ নেয় (ইনপুট উদাহরণগুলির একটি ব্যাচ একটি অ্যারো রেকর্ডব্যাচ হিসাবে উপস্থাপিত হয়), এবং একটি একক DatasetFeatureStatisticsList প্রোটোকল বাফার ধারণকারী একটি পিসিকলেকশন আউটপুট করে।
একবার আপনি কাস্টম ডেটা সংযোগকারীটি প্রয়োগ করেছেন যা একটি তীর রেকর্ডব্যাচ-এ আপনার ইনপুট উদাহরণগুলি ব্যাচ করে, আপনাকে ডেটা পরিসংখ্যান গণনার জন্য tfdv.GenerateStatistics API-এর সাথে সংযোগ করতে হবে। উদাহরণ স্বরূপ tf.train.Example এর TFRecord নিন। tfx_bsl TFExampleRecord ডেটা সংযোগকারী প্রদান করে, এবং কিভাবে এটি tfdv.GenerateStatistics API এর সাথে সংযোগ করতে হয় তার একটি উদাহরণ নিচে দেওয়া হল।
import tensorflow_data_validation as tfdv
from tfx_bsl.public import tfxio
import apache_beam as beam
from tensorflow_metadata.proto.v0 import statistics_pb2
DATA_LOCATION = ''
OUTPUT_LOCATION = ''
with beam.Pipeline() as p:
_ = (
p
# 1. Read and decode the data with tfx_bsl.
| 'TFXIORead' >> (
tfxio.TFExampleRecord(
file_pattern=[DATA_LOCATION],
telemetry_descriptors=['my', 'tfdv']).BeamSource())
# 2. Invoke TFDV `GenerateStatistics` API to compute the data statistics.
| 'GenerateStatistics' >> tfdv.GenerateStatistics()
# 3. Materialize the generated data statistics.
| 'WriteStatsOutput' >> WriteStatisticsToTFRecord(OUTPUT_LOCATION))
ডেটার স্লাইস ধরে পরিসংখ্যান গণনা করা
TFDV ডেটার স্লাইস দিয়ে পরিসংখ্যান গণনা করতে কনফিগার করা যেতে পারে। স্লাইসিং ফাংশন প্রদান করে সক্রিয় করা যেতে পারে যা একটি তীর RecordBatch গ্রহণ করে এবং ফর্মের টিপলের একটি ক্রম (slice key, record batch) আউটপুট করে। TFDV বৈশিষ্ট্য মান ভিত্তিক স্লাইসিং ফাংশন তৈরি করার একটি সহজ উপায় প্রদান করে যা পরিসংখ্যান গণনা করার সময় tfdv.StatsOptions এর অংশ হিসাবে প্রদান করা যেতে পারে।
যখন স্লাইসিং সক্ষম করা হয়, আউটপুট DatasetFeatureStatisticsList প্রোটোতে একাধিক DatasetFeatureStatistics প্রোটো থাকে, প্রতিটি স্লাইসের জন্য একটি। প্রতিটি স্লাইস একটি অনন্য নাম দ্বারা চিহ্নিত করা হয় যা DatasetFeatureStatistics প্রোটোতে ডেটাসেট নাম হিসাবে সেট করা হয়। ডিফল্টরূপে TFDV কনফিগার করা স্লাইসগুলি ছাড়াও সামগ্রিক ডেটাসেটের পরিসংখ্যান গণনা করে।
import tensorflow_data_validation as tfdv
from tensorflow_data_validation.utils import slicing_util
# Slice on country feature (i.e., every unique value of the feature).
slice_fn1 = slicing_util.get_feature_value_slicer(features={'country': None})
# Slice on the cross of country and state feature (i.e., every unique pair of
# values of the cross).
slice_fn2 = slicing_util.get_feature_value_slicer(
features={'country': None, 'state': None})
# Slice on specific values of a feature.
slice_fn3 = slicing_util.get_feature_value_slicer(
features={'age': [10, 50, 70]})
stats_options = tfdv.StatsOptions(
slice_functions=[slice_fn1, slice_fn2, slice_fn3])