
Wskaźniki uczciwości zaprojektowano, aby wspierać zespoły w ocenie i ulepszaniu modeli dotyczących kwestii uczciwości we współpracy z szerszym zestawem narzędzi Tensorflow. Narzędzie jest obecnie aktywnie używane wewnętrznie przez wiele naszych produktów i jest teraz dostępne w wersji BETA, aby wypróbować je we własnych przypadkach.
Co to są wskaźniki sprawiedliwości?
Fairness Indicators to biblioteka umożliwiająca łatwe obliczanie powszechnie identyfikowanych metryk sprawiedliwości dla klasyfikatorów binarnych i wieloklasowych. Wiele istniejących narzędzi do oceny obaw dotyczących uczciwości nie działa dobrze w przypadku zbiorów danych i modeli na dużą skalę. W Google ważne jest dla nas posiadanie narzędzi, które mogą działać na systemach miliardów użytkowników. Wskaźniki uczciwości pozwolą Ci ocenić przypadek użycia dowolnej wielkości.
W szczególności Wskaźniki Uczciwości obejmują możliwość:
- Oceń rozkład zbiorów danych
- Oceń wydajność modelu w podziale na określone grupy użytkowników
- Możesz mieć pewność co do swoich wyników dzięki przedziałom ufności i ocenom na wielu progach
- Zagłęb się w poszczególne wycinki, aby poznać przyczyny źródłowe i możliwości poprawy
Pobrany pakiet pip zawiera:
- Walidacja danych Tensorflow (TFDV)
- Analiza modelu Tensorflow (TFMA)
- Wskaźniki sprawiedliwości
- Narzędzie „co by było, gdyby” (WIT)
Używanie wskaźników uczciwości w modelach Tensorflow
Dane
Aby uruchomić wskaźniki sprawiedliwości za pomocą TFMA, upewnij się, że zbiór danych ewaluacyjnych jest oznaczony etykietą funkcji, według których chcesz dokonać podziału. Jeśli nie masz dokładnych funkcji wycinka spełniających Twoje obawy dotyczące uczciwości, możesz spróbować znaleźć zestaw ewaluacyjny, który je ma, lub rozważyć funkcje proxy w swoim zestawie funkcji, które mogą uwypuklić rozbieżności w wynikach. Dodatkowe wskazówki można znaleźć tutaj .
Model
Do zbudowania modelu możesz użyć klasy Tensorflow Estimator. Wkrótce w TFMA pojawi się obsługa modeli Keras. Jeśli chcesz uruchomić TFMA na modelu Keras, zapoznaj się z sekcją „TFMA niezależne od modelu” poniżej.
Po przeszkoleniu narzędzia estymatora konieczne będzie wyeksportowanie zapisanego modelu w celu oceny. Aby dowiedzieć się więcej, zobacz przewodnik TFMA .
Konfigurowanie plasterków
Następnie zdefiniuj wycinki, które chcesz poddać ocenie:
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur color’])
]
Jeśli chcesz ocenić przekroje przekrojowe (na przykład zarówno kolor futra, jak i wysokość), możesz ustawić następujące opcje:
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur_color’, ‘height’])
]`
Oblicz wskaźniki uczciwości
Dodaj wywołanie zwrotne Fairness Indicators do listy metrics_callback . W wywołaniu zwrotnym możesz zdefiniować listę progów, przy których model będzie oceniany.
from tensorflow_model_analysis.addons.fairness.post_export_metrics import fairness_indicators
# Build the fairness metrics. Besides the thresholds, you also can config the example_weight_key, labels_key here. For more details, please check the api.
metrics_callbacks = \
[tfma.post_export_metrics.fairness_indicators(thresholds=[0.1, 0.3,
0.5, 0.7, 0.9])]
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path=tfma_export_dir,
add_metrics_callbacks=metrics_callbacks)
Przed uruchomieniem konfiguracji określ, czy chcesz włączyć obliczanie przedziałów ufności. Przedziały ufności są obliczane przy użyciu metody ładowania początkowego Poissona i wymagają ponownego obliczenia dla 20 próbek.
compute_confidence_intervals = True
Uruchom potok oceny TFMA:
validate_dataset = tf.data.TFRecordDataset(filenames=[validate_tf_file])
# Run the fairness evaluation.
with beam.Pipeline() as pipeline:
_ = (
pipeline
| beam.Create([v.numpy() for v in validate_dataset])
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
slice_spec=slice_spec,
compute_confidence_intervals=compute_confidence_intervals,
output_path=tfma_eval_result_path)
)
eval_result = tfma.load_eval_result(output_path=tfma_eval_result_path)
Wskaźniki uczciwości renderowania
from tensorflow_model_analysis.addons.fairness.view import widget_view
widget_view.render_fairness_indicator(eval_result=eval_result)
Wskazówki dotyczące stosowania wskaźników sprawiedliwości:
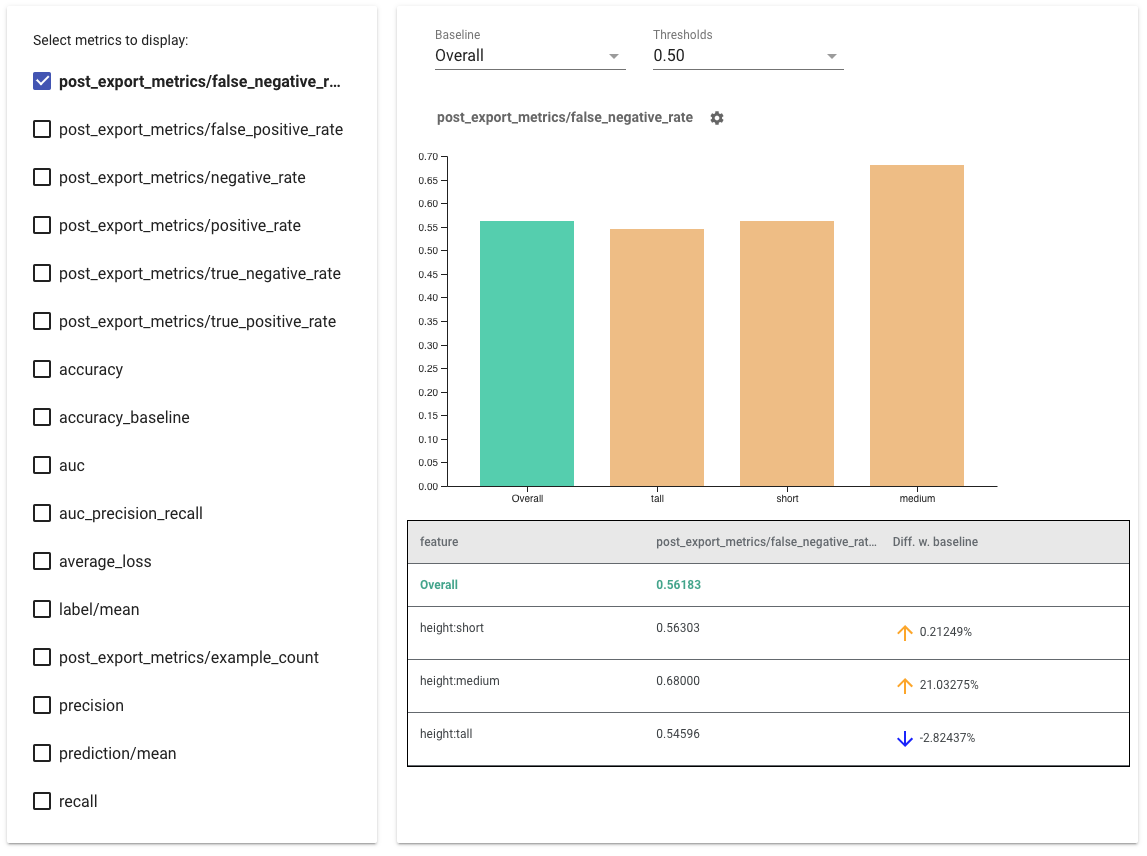
- Wybierz dane do wyświetlenia , zaznaczając pola po lewej stronie. W widgecie pojawią się indywidualne wykresy dla każdego z parametrów, w odpowiedniej kolejności.
- Zmień wycinek linii bazowej (pierwszy słupek na wykresie) za pomocą menu rozwijanego. Delta zostanie obliczona na podstawie tej wartości bazowej.
- Wybierz progi za pomocą rozwijanego selektora. Na tym samym wykresie można wyświetlić wiele progów. Wybrane progi zostaną pogrubione. Możesz kliknąć pogrubiony próg, aby odznaczyć go.
- Najedź kursorem na pasek, aby zobaczyć wskaźniki dla tego wycinka.
- Zidentyfikuj rozbieżności w stosunku do linii bazowej, korzystając z kolumny „Różnica z linią bazową”, która określa procentową różnicę między bieżącym wycinkiem a linią bazową.
- Zbadaj szczegółowo punkty danych wycinka, korzystając z narzędzia „Co jeśli” . Zobacz tutaj przykład.
Wskaźniki poprawności renderowania dla wielu modeli
Wskaźniki uczciwości można również wykorzystać do porównania modeli. Zamiast przekazywać pojedynczy obiekt eval_result, przekaż obiekt multi_eval_results, który jest słownikiem mapującym dwie nazwy modeli na obiekty eval_result.
from tensorflow_model_analysis.addons.fairness.view import widget_view
eval_result1 = tfma.load_eval_result(...)
eval_result2 = tfma.load_eval_result(...)
multi_eval_results = {"MyFirstModel": eval_result1, "MySecondModel": eval_result2}
widget_view.render_fairness_indicator(multi_eval_results=multi_eval_results)
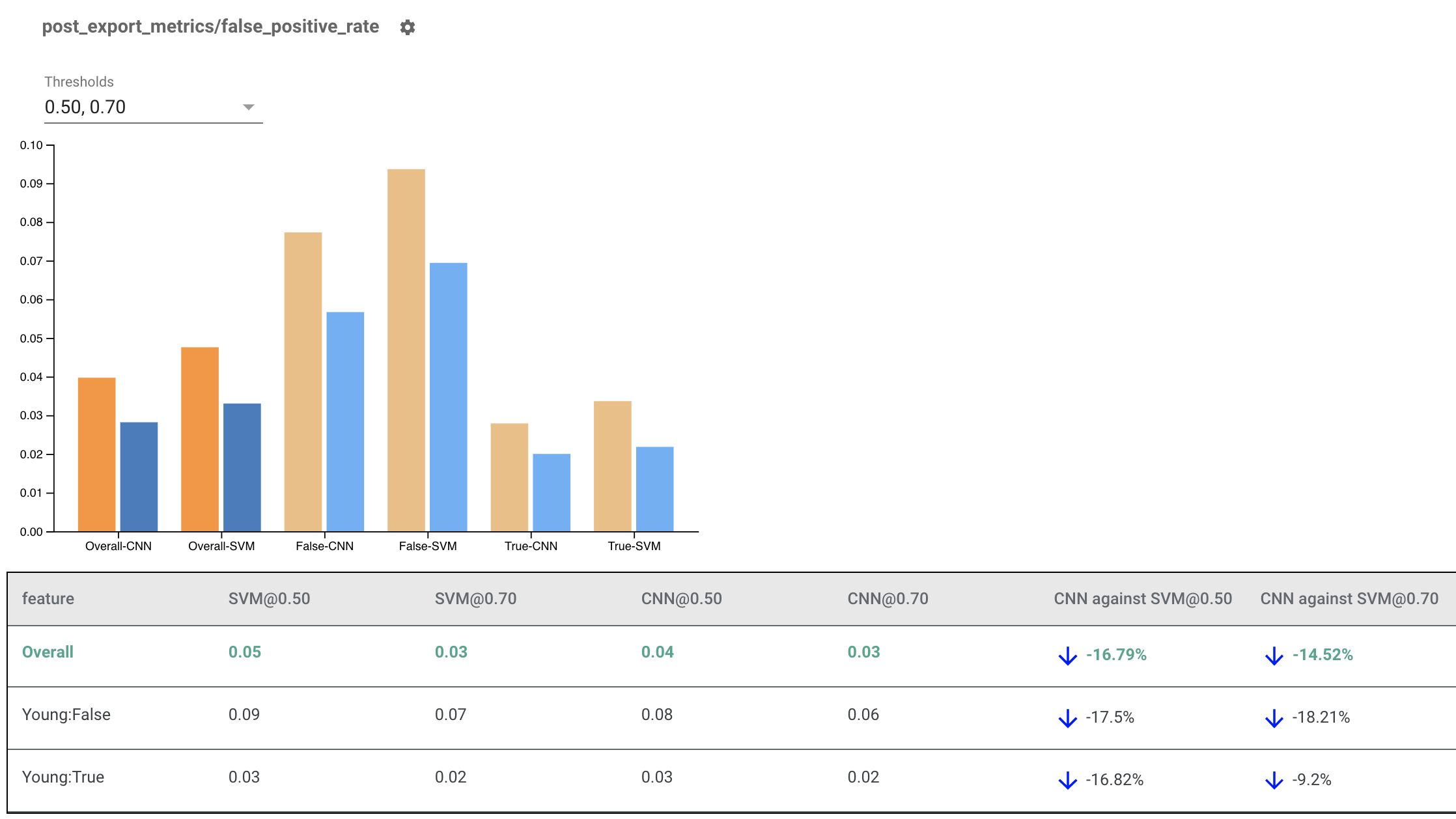
Porównanie modeli można stosować równolegle z porównaniem progowym. Można na przykład porównać dwa modele przy dwóch zestawach progów, aby znaleźć optymalną kombinację dla wskaźników uczciwości.
Używanie wskaźników uczciwości w modelach innych niż TensorFlow
Aby lepiej wspierać klientów, którzy mają różne modele i przepływy pracy, opracowaliśmy bibliotekę ewaluacyjną, która jest niezależna od ocenianego modelu.
Każdy, kto chce ocenić swój system uczenia maszynowego, może z tego skorzystać, szczególnie jeśli masz modele inne niż TensorFlow. Korzystając z zestawu SDK Apache Beam Python, możesz utworzyć samodzielny plik binarny ewaluacyjny TFMA, a następnie uruchomić go w celu analizy modelu.
Dane
Ten krok polega na dostarczeniu zestawu danych, na którym mają być uruchamiane oceny. Powinien być w formacie proto tf.Example zawierający etykiety, prognozy i inne funkcje, które warto podzielić.
tf.Example {
features {
feature {
key: "fur_color" value { bytes_list { value: "gray" } }
}
feature {
key: "height" value { bytes_list { value: "tall" } }
}
feature {
key: "prediction" value { float_list { value: 0.9 } }
}
feature {
key: "label" value { float_list { value: 1.0 } }
}
}
}
Model
Zamiast określać model, tworzysz niezależną od modelu konfigurację ewaluacyjną i ekstraktor, aby przeanalizować i dostarczyć dane potrzebne TFMA do obliczenia metryk. Specyfikacja ModelAgnosticConfig definiuje funkcje, przewidywania i etykiety, które mają być używane na podstawie przykładów wejściowych.
W tym celu utwórz mapę funkcji z kluczami reprezentującymi wszystkie funkcje, w tym kluczami etykiet i przewidywań oraz wartościami reprezentującymi typ danych obiektu.
feature_map[label_key] = tf.FixedLenFeature([], tf.float32, default_value=[0])
Utwórz konfigurację niezależną od modelu, korzystając z kluczy etykiet, kluczy przewidywania i mapy funkcji.
model_agnostic_config = model_agnostic_predict.ModelAgnosticConfig(
label_keys=list(ground_truth_labels),
prediction_keys=list(predition_labels),
feature_spec=feature_map)
Skonfiguruj ekstraktor agnostyczny modelu
Ekstraktor służy do wyodrębniania cech, etykiet i przewidywań z danych wejściowych przy użyciu konfiguracji niezależnej od modelu. A jeśli chcesz pokroić dane, musisz także zdefiniować specyfikację klucza plasterka , zawierającą informacje o kolumnach, które chcesz pokroić.
model_agnostic_extractors = [
model_agnostic_extractor.ModelAgnosticExtractor(
model_agnostic_config=model_agnostic_config, desired_batch_size=3),
slice_key_extractor.SliceKeyExtractor([
slicer.SingleSliceSpec(),
slicer.SingleSliceSpec(columns=[‘height’]),
])
]
Oblicz wskaźniki uczciwości
W ramach EvalSharedModel możesz podać wszystkie metryki, na podstawie których chcesz oceniać swój model. Metryki są dostarczane w formie wywołań zwrotnych metryk, takich jak te zdefiniowane w post_export_metrics lub fairness_indicators .
metrics_callbacks.append(
post_export_metrics.fairness_indicators(
thresholds=[0.5, 0.9],
target_prediction_keys=[prediction_key],
labels_key=label_key))
Bierze również pod uwagę construct_fn , która służy do tworzenia wykresu tensorflow w celu przeprowadzenia oceny.
eval_shared_model = types.EvalSharedModel(
add_metrics_callbacks=metrics_callbacks,
construct_fn=model_agnostic_evaluate_graph.make_construct_fn(
add_metrics_callbacks=metrics_callbacks,
fpl_feed_config=model_agnostic_extractor
.ModelAgnosticGetFPLFeedConfig(model_agnostic_config)))
Gdy wszystko zostanie skonfigurowane, użyj jednej z funkcji ExtractEvaluate lub ExtractEvaluateAndWriteResults udostępnianych przez model_eval_lib , aby ocenić model.
_ = (
examples |
'ExtractEvaluateAndWriteResults' >>
model_eval_lib.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
output_path=output_path,
extractors=model_agnostic_extractors))
eval_result = tensorflow_model_analysis.load_eval_result(output_path=tfma_eval_result_path)
Na koniec wyrenderuj wskaźniki uczciwości, korzystając z instrukcji z sekcji „Renderuj wskaźniki uczciwości” powyżej.
Więcej przykładów
Katalog przykładów wskaźników sprawiedliwości zawiera kilka przykładów:
- Fairness_Indicators_Example_Colab.ipynb zawiera przegląd wskaźników sprawiedliwości w analizie modelu TensorFlow oraz sposoby ich używania z prawdziwym zbiorem danych. W tym notatniku omówiono także weryfikację danych TensorFlow i narzędzie What-If , dwa narzędzia do analizowania modeli TensorFlow wyposażonych we wskaźniki rzetelności.
- Fairness_Indicators_on_TF_Hub.ipynb demonstruje, jak używać wskaźników Fairness do porównywania modeli wytrenowanych w oparciu o różne osadzania tekstu . W tym notesie zastosowano osadzanie tekstu z TensorFlow Hub , biblioteki TensorFlow, umożliwiającej publikowanie, odkrywanie i ponowne wykorzystywanie komponentów modelu.
- Fairness_Indicators_TensorBoard_Plugin_Example_Colab.ipynb demonstruje, jak wizualizować wskaźniki uczciwości w TensorBoard.